前回、大規模言語モデルと知識グラフの相互補完性について記事を書きましたが、1回の記事で説明しきれるものではないため、補足をします。
私が興味を持ち読み、日本語で解説をしているarxivで公開されている査読前論文の原文は次のリンクで見ることが出来ます。
Unifying Large Language Models and Knowledge Graphs: A Roadmap
前回の記事では大規模言語モデルの持つ欠点と知識グラフの持つ欠点を相互に挙げ、それらを相互補完的に使用する事で、内容に関する正確性と柔軟な言語表現による説明を行う事の出来る、フォワードルッキングなロードマップの説明をしました。
前回の説明で不足した部分について、補う形で説明を付け加えます。
知識グラフについて
知識グラフの説明について、不足していた部分が多かったため今回の記事ではその点を補強します。
前回の記事による論文の内容の説明で、知識グラフは
事実や概念といった「ノード」と呼ばれるものと、それらの間の関連を示す「エッジ」により構成される。
と説明しました。
ただ、これはあまりにも抽象的すぎる説明なので具体的な例を挙げます。
知識グラフには以下のような種類があります。
百科辞典型知識グラフ
百科事典型知識グラフは最も一般的な知識グラフの一種で、その情報源として百科事典のように様々な分野の情報を含む、信頼性の高い情報が用いられます。
これらの知識グラフは、多くの異なるテーマに関する情報を含んでおり、その情報は通常、「エンティティ(人・場所・事柄など)」とそれらの「エンティティ」の間の関係(エンティティがどのように相互に関連しているか)を記述するために使用されます。
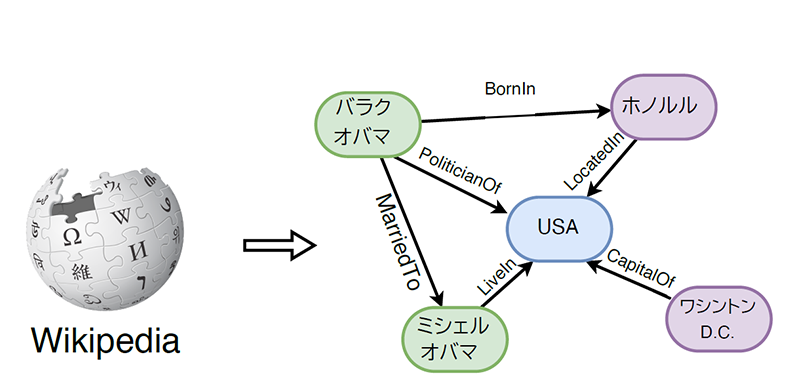
代表的な百科辞典型知識グラフには Wikidata があります。
Wikidata はWikipedia以外にも Wiktionary や Wikiquote も情報源にしつつ知識グラフを構築しています。
また、より広範な情報をデータベースとして網羅した DBpedia という知識グラフもあります。
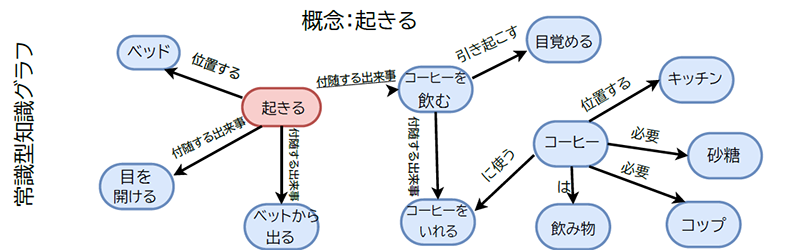
常識型知識グラフ
一般常識型知識グラフは、百科辞典型知識グラフに比べより人間の生活や自然界の法則などに焦点をあてているところが特徴です。
実際同様の取り組み自体は非常に歴史の深いもので、人間の持つ知識を全て構造化したデータの形にして、コンピューターに記号操作的な方法で推論を行わせ、汎用人工知能の実現を目指した歴史がありました。
しかし、この手法は人間の持つ暗黙知があまりに莫大な事や、時間と共に移り変わる性質や暗黙知全てを人間自身が理解していないのではないかという問題から、第二次AIブームと共に下火になった経緯があります。
百科事典型の知識グラフと比べて常識型の知識グラフは、テキストから抽出される暗黙の知識(例:(車, 用途, 運転))をモデル化します。
ドメイン固有型知識グラフ
ドメイン固有型知識グラフは医療、生物学、金融などの特定の領域の知識を表現するために構築されます。
百科事典型の知識グラフと比較して、特定領域の知識グラフは通常サイズが小さくより正確で信頼性があるものです。
例えば Unified Medical Language System は医療領域の特定領域の知識グラフであり、生物医学的な概念とその関係を含んでいます。
マルチモーダルな知識グラフ
マルチモーダルな知識グラフは、テキストだけでなく画像、音声、ビデオなどの多様なメディアから情報を抽出します。これにより、より豊かで直感的な情報表現が可能になります。 IMGpedia などがこのタイプの知識グラフの例です。
マルチモーダル知識グラフは、テキストと画像情報の両方を知識グラフに組み込んでおり、これらの知識グラフは、画像とテキストのマッチング、視覚-質問応答(VQA)、レコメンデーションなどさまざまなマルチモーダルタスクに使用することができます。
どのように言語モデルと知識グラフを相互補完的に利用するか
これらの知識グラフを大規模言語モデルと相互補完的に使用する方法として、前回の記事で次のような方法を挙げました。
それぞれの項目についてもう少し詳細を説明します。
"KG-enhanced LLMs" 「知識グラフにより強化された大規模言語モデル」
KG-enhanced LLMの事前学習: このアプローチでは、LLMsの事前学習段階で知識グラフを適用し、LLMsの知識表現を改善します。
KG-enhanced LLMの推論: 研究では、LLMsの推論段階で知識グラフを利用し、再学習せずに最新の知識にアクセスすることを可能にしています。
KG-enhanced LLMの解釈可能性: このアプローチでは、LLMsが学んだ知識を理解し、LLMsの推論プロセスを解釈するために知識グラフを使用します。
LLM-augmented KGs(LLMs拡張型知識グラフ)
LLM-augmented KGの埋め込み: このアプローチでは、LLMsを利用して知識グラフの表現を豊かにします。具体的には、エンティティと関係のテキスト説明をエンコードするためにLLMsを使用します。
LLM-augmented KGの補完: このアプローチでは、LLMsを利用してテキストをエンコードしたり、事実を生成したりすることで、知識グラフ補完(KGC)のパフォーマンスを向上させます。KGCは、与えられた知識グラフの欠落している事実を推論するタスクを指します。
LLM-augmented KGの構築: このアプローチでは、エンティティの発見、共参照解決、関係抽出タスクを対処するためにLLMsを適用します。
LLM-augmented KGからテキストへの生成: このアプローチでは、知識グラフからの事実を説明する自然言語を生成するためにLLMsを利用します。
LLM-augmented KGの質問応答: このアプローチでは、自然言語の質問と回答を取得するギャップを埋めるためにLLMsを適用します。
Synergized LLMs + KGs(相互強化型LLMsと知識グラフ)
このフレームワークでは、LLMsと知識グラフは互いに補完し合う二つの技術として扱われます。これらは、一般的なフレームワークに統合され、相互に強化することが目指されています。
この統合フレームワークは、4つのレイヤーで構成されています:1) データ、2) 相互強化モデル、3) 技術、4) アプリケーション。
データレイヤーでは、テキストと構造的なデータを処理するためにLLMsと知識グラフが使用されます。
相互強化モデルレイヤーでは、LLMsと知識グラフが統合され、パフォーマンスを向上させるために互いに補完し合います。
技術レイヤーでは、LLMsと知識グラフがさまざまな技術的な課題を解決するために使用されます。
アプリケーションレイヤーでは、LLMsと知識グラフが統合され、検索エンジン、推奨システム、AIアシスタントなどの実世界のアプリケーションを対処するために使用されます。
このフレームワークの目的は、LLMsと知識グラフの両方の強みを活用し、それぞれの個々の限界を克服することです。
しかし、現在のところ、相互強化型LLMsと知識グラフはまだ十分に探求されていません。
この分野はこれから研究や応用が進む分野と言えるでしょう。