はじめに
※この記事はRICORA Advent Calendar 12/25 の記事になります。
本記事ではUnityの深層強化学習パッケージのML-Agentsによる4足歩行モデルの実装を行います。
ML-Agents完全初心者の方はML-Agents入門から読むことをおススメします。ML-Agentsのインストールから簡単なモデル作成まで行っています。
ここではモデルと環境の作成方法を紹介した後に、4足歩行モデルを実現するための報酬設計の考え方やトレーニングの高速化について主に紹介します。
モデルと環境の準備
モデルと環境をどのように作成したかについて説明します。
モデルの作成
以下のような4足2関節のモデルを作成しました。

今回はこのモデルに歩行を学習させるのがメインタスクとなります。具体的にはエージェントが目標に到達するというタスクを立てて、これを学習させていきます。
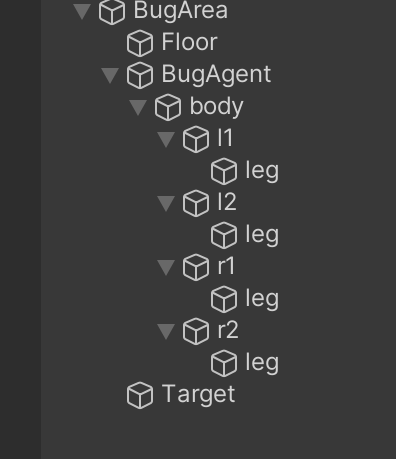
このモデルは次のような親子関係の3Dオブジェクトからなっています。

ここでBugAgentは空の3Dオブジェクトであり、Behavior ParametersとDecision RequesterをComponentとして付けます。
bodyは緑色のCapsule、l1,l2,r1,r2は赤色のSphere、各legは青色のCapsuleになります。このように親子関係を組むことで各部位が上位のパーツの動きを反映できるようになります。親子関係が無いと体が動いているのに足がついていかない、といった関連性のない挙動になってしまいます。
l1,l2,r1,r2と各legにはHinge Jointという動きに制限を掛けるComponentを付けています。今回は強化学習にこのComponentを操作させてモデルに歩行を学習させます。Connected Bodyに一つ上のオブジェクトを選択しましょう。またHingeの方向にも注意です。
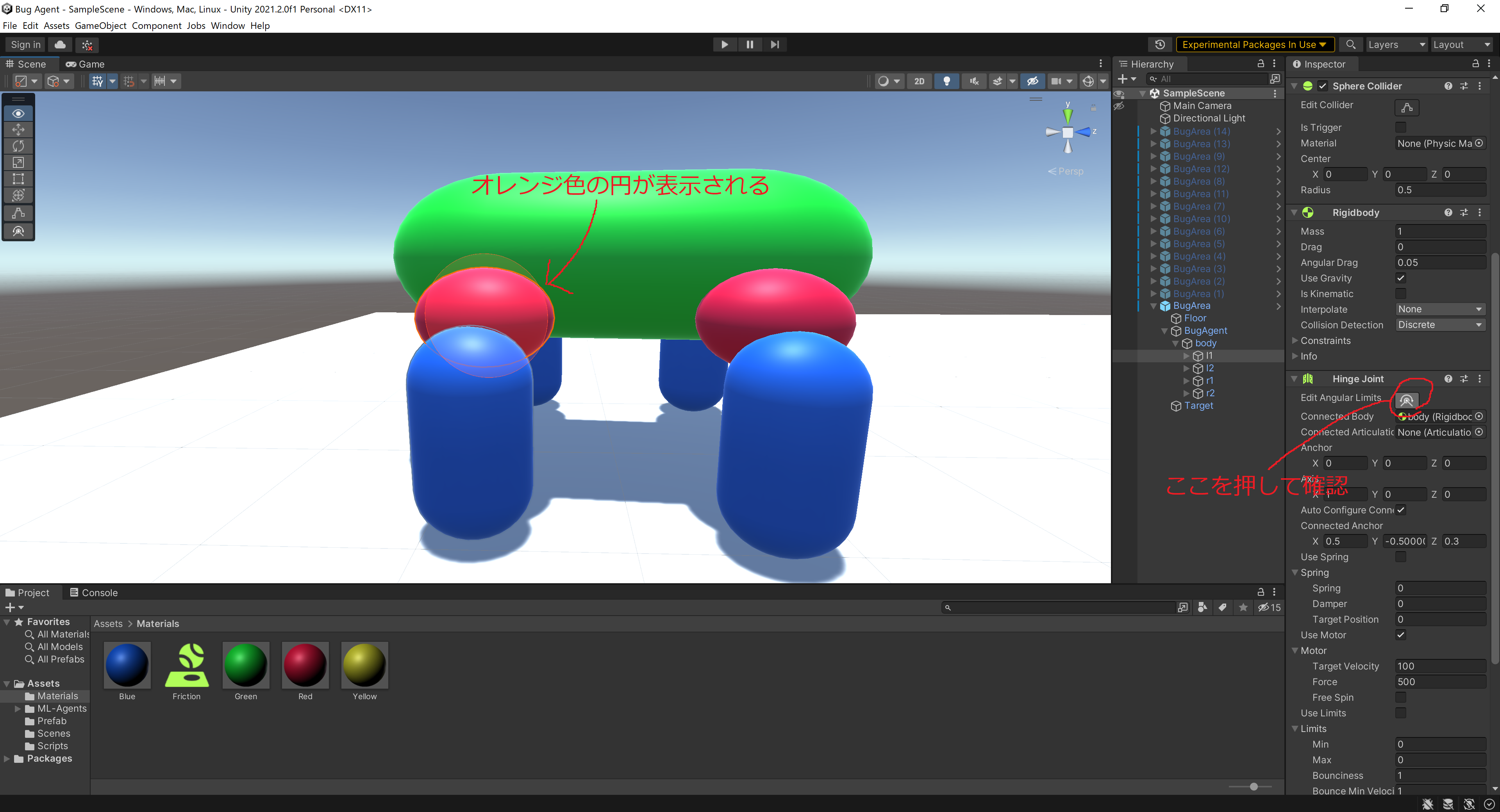
色々なものが見えてますが今は気にしないでください(笑)
Hinge JointのLimitsのmin maxはともに0にしておきましょう。上の写真のような操作を行うとオブジェクトがどの方向に回転できるかを示す円が出てきます。今回は回転方向が地面に垂直になるように調整しました。角度の調整はAxisの値を調整することでできます。
またBugAgentを除くオブジェクトはRigidBodyを持っています。基本的な重さは1ですが飛び跳ね防止のためbodyのみ重さを2.5にしています。単純に体積の大きい部位ほど重さを増やすといった仕様にしても面白いと思います。時間がある人は色々試してみましょう。
環境の作成
加えて地面に接地している各legと地面のPlaneに摩擦を設定しました。Projectウィンドを右クリックしてCreateからPhysic Materialを選択すると摩擦に使えるマテリアルを取得することができます。
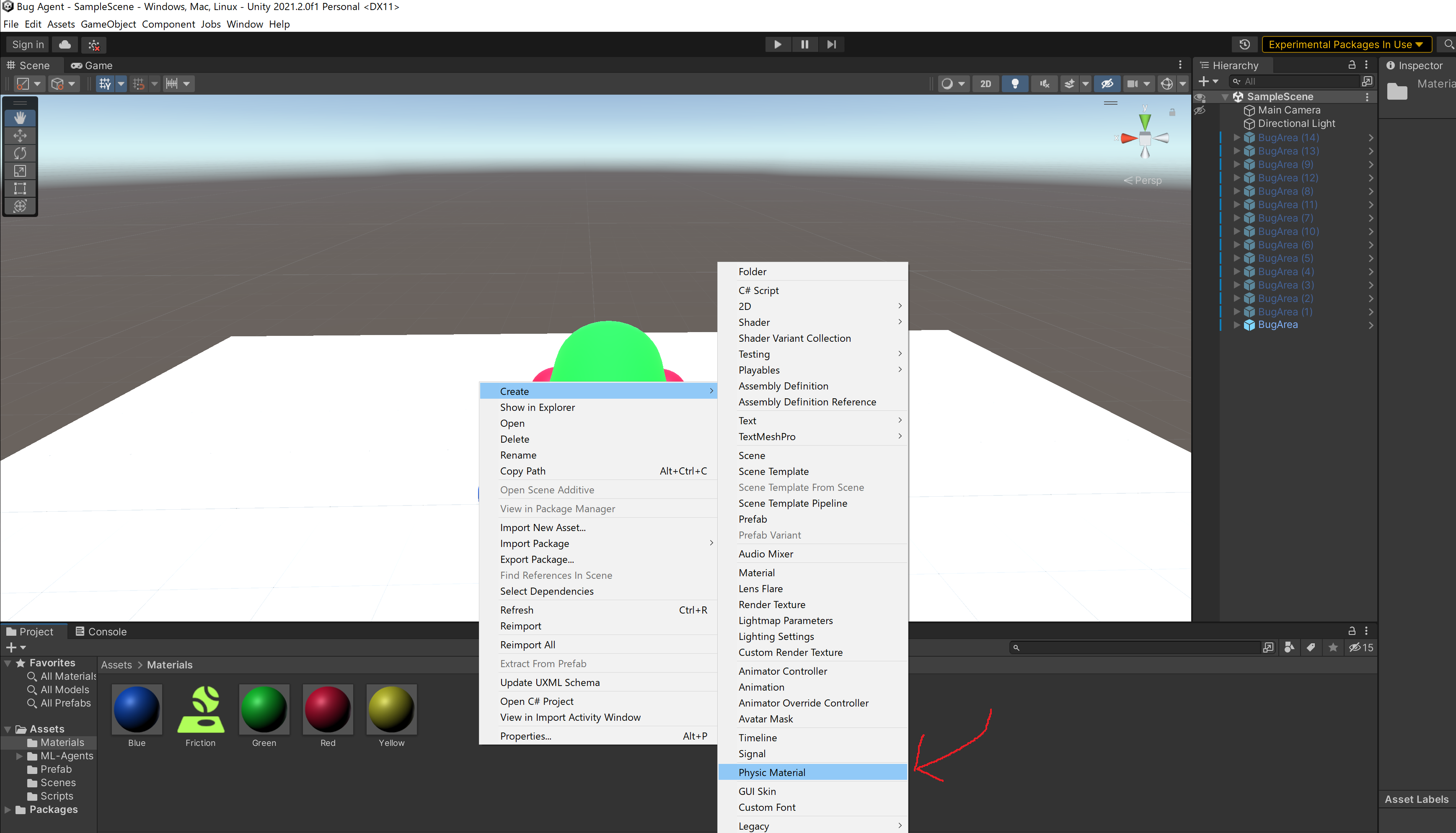
マテリアルを選択してDynamic Friction(動摩擦)とStatic Friction(静止摩擦)をそれぞれ1に設定しましょう。
物体にこれを適用するためにはデフォルトでついているMesh ColliderというComponentにこれを付与します。Mesh CollierのMaterialのところにドラッグ&ドロップしてください。上で説明したように4本のlegとfloor(床のplane)にそれぞれ同じ操作を行います。
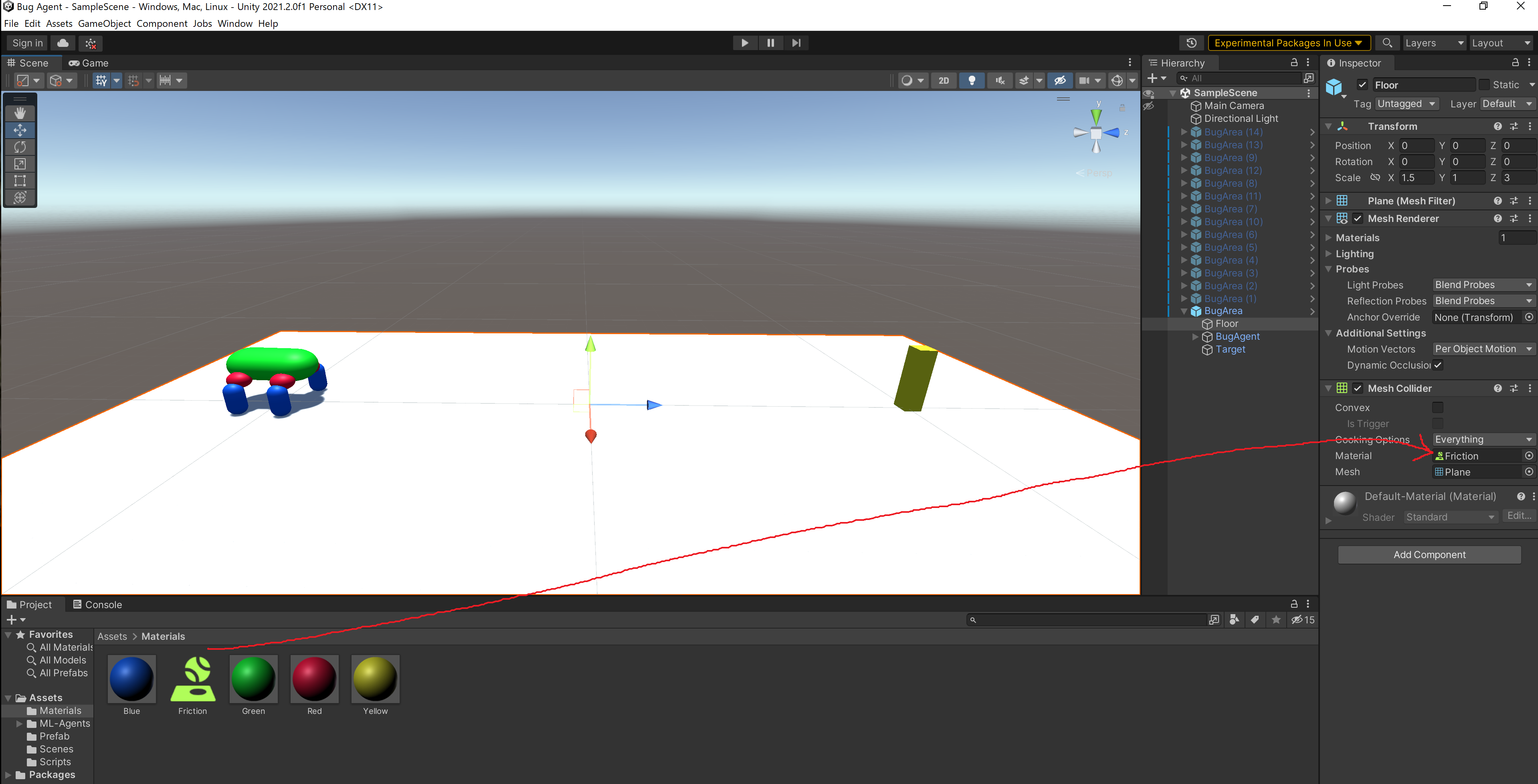
歩行の目標にするTragetをfloor上に配置します。今回はBugAgentとTargetの距離を20mにしてあります。
空のGame Objectを生成してそこにBugAreaという名前を付けました。次の階層構造になるように作ったオブジェクトが配置されるようにしましょう。
環境のプレハブ化
ここまでに作成した環境のプレハブ化というものを行います。プレハブ化を利用することで環境の量産と同時変更を行うことができるようになります。後に高速化を行うためのステップとなります。
今作成したBugAgentをProjectウィンドにドラッグ&ドロップします。画像ではBugAgentや諸々が水色の文字で表示されていますが、プレハブ化前は白色になっているはずです。プレハブ化ができると名前が水色になります。
Projectウィンド内にプレハブ化されたBugAreaが表示されているのでダブルクリックしてプレハブの作業エリアに移動してみましょう。
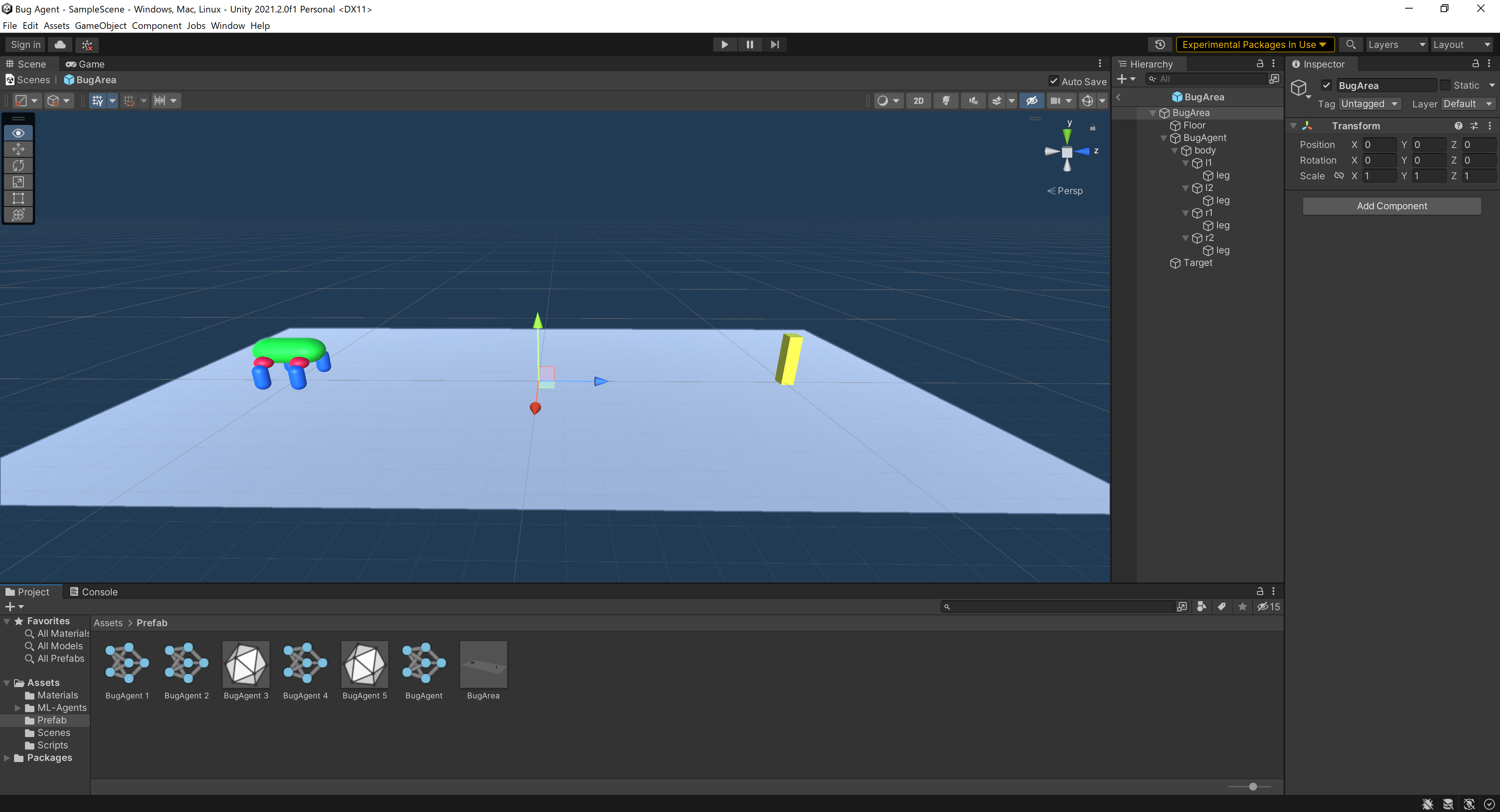
画像のような背景が青い空間に移動したと思います。ここでプレハブの編集を行うことができます。モデルや環境を変更したいときは個別のオブジェクトではなく、このプレハブから編集するようにしましょう。プレハブでコピーしたオブジェクト全体に同様の変更を適用することができます。
ML-Agent用コンポネントの設定
環境の最後の設定としてML-Agentsに必要なComponentの設定を行いましょう。
BugAgentにBehavior ParametersとScriptとDecision Requesterを付けます。スクリプトの名前はBugAgentとしました。
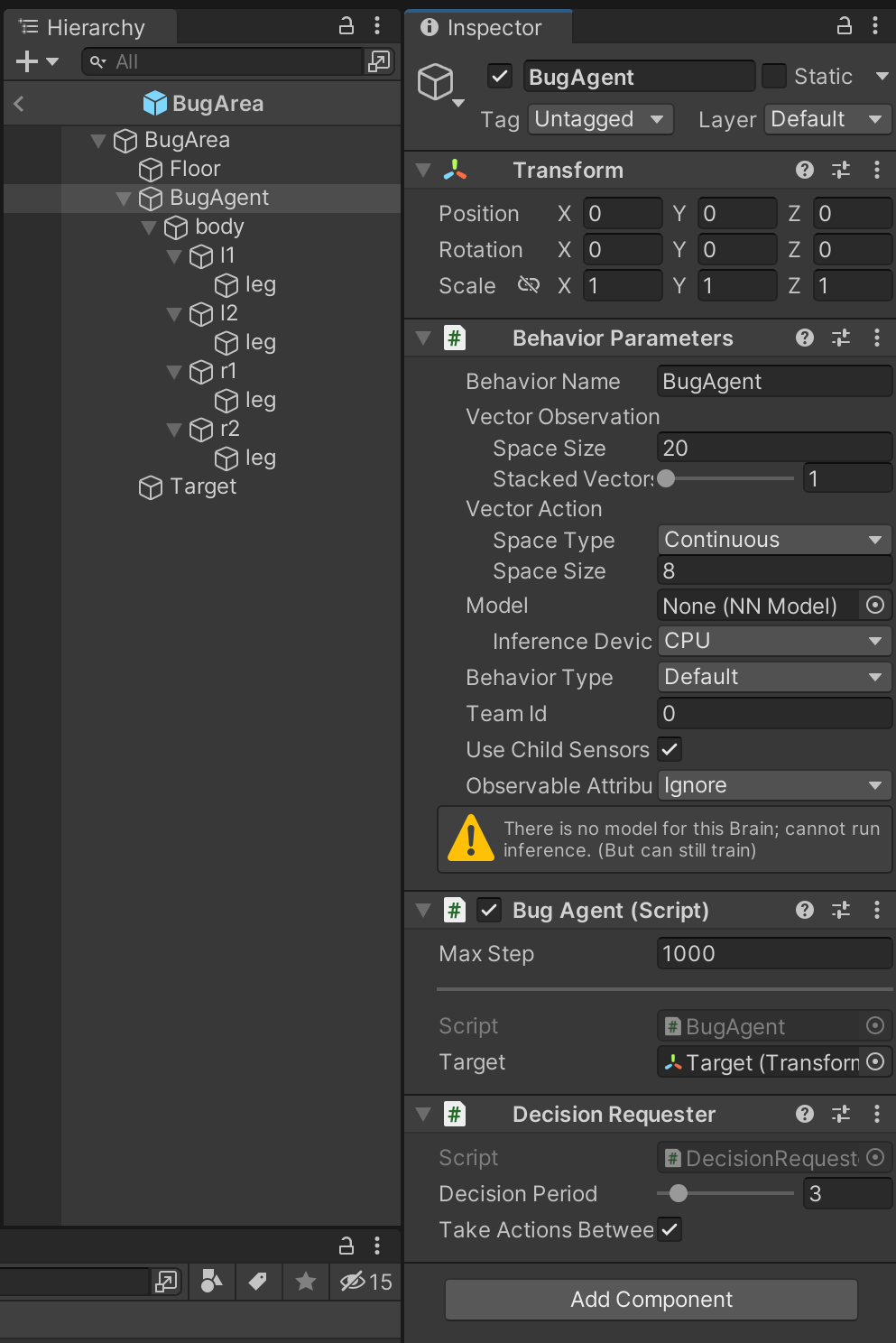
Bug Agent(Script)のTargetの部分は実際にプログラムを書くと出てくるので今は気にしないでください。プログラムを書いたらTargetのところに設置しているtargetオブジェクトをドラッグ&ドロップしてください。それぞれのComponentの数値は画像と同じ値にセットしましょう。
これで環境の準備が整いました。次はプログラムです。
スクリプトと報酬設計の考え方
BugAgent.csの中身を見ながらどのように報酬設計を行ったか解説します。
using System.Collections.Generic;
using System;
using UnityEngine;
using Unity.MLAgents;
using Unity.MLAgents.Sensors;
public class BugAgent : Agent
{
public Transform target;
private GameObject body;
private GameObject[] thighs = new GameObject[4];
private GameObject[] legs = new GameObject[4];
private HingeJoint[] thighs_hinge = new HingeJoint[4];
private HingeJoint[] legs_hinge = new HingeJoint[4];
private JointMotor[] thighs_motor = new JointMotor[4];
private JointMotor[] legs_motor = new JointMotor[4];
private int phase = 0;
private float rotate_phase = 1.0f;
public override void Initialize(){
this.body = this.transform.Find("body").gameObject;
this.thighs[0] = this.body.transform.Find("l1").gameObject;
this.thighs[1] = this.body.transform.Find("l2").gameObject;
this.thighs[2] = this.body.transform.Find("r1").gameObject;
this.thighs[3] = this.body.transform.Find("r2").gameObject;
int limit = 30;
for(int i=0;i<4;i++){
this.legs[i] = this.thighs[i].transform.Find("leg").gameObject;
this.thighs_hinge[i] = thighs[i].GetComponent<HingeJoint>();
this.legs_hinge[i] = legs[i].GetComponent<HingeJoint>();
this.thighs_motor[i] = this.thighs_hinge[i].motor;
this.legs_motor[i] = this.legs_hinge[i].motor;
JointLimits thigh_limits = thighs_hinge[i].limits;
JointLimits leg_limits = legs_hinge[i].limits;
thigh_limits.min = -limit;
thigh_limits.max = limit;
thigh_limits.bounciness = 0;
thigh_limits.bounceMinVelocity = 0;
thighs_hinge[i].limits = thigh_limits;
thighs_hinge[i].useLimits = true;
leg_limits.min = -limit;
leg_limits.max = limit;
leg_limits.bounciness = 0;
leg_limits.bounceMinVelocity = 0;
legs_hinge[i].limits = leg_limits;
legs_hinge[i].useLimits = true;
}
}
public override void OnEpisodeBegin(){
this.body.transform.localPosition = new Vector3(0,1.3f,-10);
this.body.transform.localRotation = Quaternion.Euler(90, 0, 0);
for(int i=0;i<4;i++){
this.thighs[i].transform.localRotation = Quaternion.Euler(-90, 0, 0);
this.legs[i].transform.localRotation = Quaternion.Euler(0,0,0);
this.thighs_motor[i].targetVelocity = 0;
this.thighs_hinge[i].motor = this.thighs_motor[i];
this.legs_motor[i].targetVelocity = 0;
this.legs_hinge[i].motor = this.legs_motor[i];
}
this.phase = 0;
this.rotate_phase = 1.0f;
target.localPosition = new Vector3(0, 1.0f, 10.0f);
}
public override void CollectObservations(VectorSensor sensor){
sensor.AddObservation(target.localPosition);
sensor.AddObservation(this.body.transform.localPosition);
sensor.AddObservation(this.body.transform.localRotation);
sensor.AddObservation(this.body.transform.up.z);
sensor.AddObservation(this.body.transform.forward.y);
for(int i=0;i<4;i++){
sensor.AddObservation(this.thighs[i].transform.localRotation.x);
sensor.AddObservation(this.legs[i].transform.localRotation.x);
}
}
public override void OnActionReceived(float[] vectorAction){
float force = 1500.0f;
for(int i=0;i<4;i++){
this.thighs_motor[i].targetVelocity = vectorAction[i]*force;
this.legs_motor[i].targetVelocity = vectorAction[i+4]*force;
this.thighs_hinge[i].motor = this.thighs_motor[i];
this.legs_hinge[i].motor = this.legs_motor[i];
}
AddReward(-0.001f);
float distanceToTarget = Vector3.Distance(this.body.transform.localPosition, target.localPosition);
if (distanceToTarget < 18.0f - this.phase && this.phase < 15){
AddReward(0.05f);
this.phase += 1;
}
if (distanceToTarget < 2.0f){
AddReward(2.0f);
EndEpisode();
}
Vector3 rotate_angle = this.body.transform.localRotation.eulerAngles;
float rotation = this.body.transform.up.z;
bool is_rotate = rotation < Math.Cos(Math.PI/6.0f * rotate_phase);
bool is_flip_z = this.body.transform.forward.y > 0;
if (this.body.transform.localPosition.y < 0.0f || is_flip_z || rotation < Math.Cos(Math.PI/6.0f * 3.0f)){
EndEpisode();
}
if(is_rotate && rotate_phase < 2){
AddReward(-0.1f);
rotate_phase += 1.0f;
}
}
public override void Heuristic(float[] actionsOut){
actionsOut[0] = Input.GetAxis("Horizontal");
actionsOut[1] = Input.GetAxis("Vertical");
}
public void Update(){
}
}
UnityとML-Agentのスクリプトの書き方については長くなるので省略させてもらいます。
ここではOnActionRecived関数について説明していきます。この関数内では主に報酬の設定をAddReward関数の呼び出しで行っていて、全部で4か所あることが分かると思います。
それぞれのAddRewardの意味
-
最初の報酬は微量のマイナス報酬で、エージェントが行動をするたびに発生します。これはエージェントにできるだけ早くゴールすることを促すための報酬で、早くゴールした個体の方がマイナス報酬の累積が少なくなるのでより高い評価を受けることになります。これによって最適な移動を学習することができます。
-
次の報酬は少量のプラス報酬で、エージェントがターゲットと一定距離近づく度に発生します。具体的にはアメフトのフィールドを想像すると分かりやすいと思います。ここではターゲットに1m近づく度にプラス報酬をもらえるようにしました。これはエージェントのスムーズな学習を促すためのものです。
-
次にメインのゴールに対するプラス報酬です。これはエージェントがターゲットに到着した際に発生する報酬でそれと同時に環境のリセットが入ります。
-
最後は回転に対する少量のマイナス報酬です。これはエージェントが上から見て15度回転するたびに発生するマイナス報酬で15度と30度の2回発生します。方式は1つ目の距離報酬と同じです。これによってエージェントの不要な回転を抑制し真っすぐ歩くことを促します。
報酬設計の推移
4つの報酬について上で説明しました。なぜこのようになったのか詳細について説明します。
-
まず最初は3のエージェントがターゲットにゴールすることのみに報酬を設けていました。しかしこれだけでとそもそもゴールすることがなかなかできないので学習の進みが非常に悪くなります。そこで2の報酬を設定しました。
-
次に発生した問題はエージェントの移動経路です。2の報酬によってゴールができるようになりましたがこれだとどのような経路でもゴールすれば同じ報酬がもらえるため、最適でない経路や行動が発生していました。そこで1の微量なマイナス報酬を設定することでこれの最適化を試みました。マイナス報酬は設計が難しく値をあまり大きくしてしまうと、すぐにひっくり返って終了させるなどのマイナスを避ける望ましくない動きが発生してしまいます。この報酬によってかなりゴールまでの時間が短縮されました。
-
最後に発生していたのがエージェントが途中で180度旋回しながらゴールを目指していたというものです。4足歩行のエージェントにとって最も困難な問題は左右のバランスを取ることだったようで、実験を通して先ほどの微量なマイナス報酬の調整だけではこの問題を解決できないと気づきました。そこで直接的に旋回に対してマイナス報酬を設けることにしましたがこれがとても難しかったです。マイナスが大きいと旋回を避けるのがよほど難しいのか、スタート地点から一切動かないといった結果に何回もたどり着いてしまいました。最終的に4の形に落ち着いてこれによってできるだけ真っすぐとゴールを目指す最適な動きを生成することができました。
トレーニングの設定
トレーニングの設定は以下のようになっています。詳しくは前回の記事を参照してください。
behaviors:
BugAgent:
trainer_type: ppo
hyperparameters:
batch_size: 10
buffer_size: 100
learning_rate: 0.0003
beta: 0.005
epsilon: 0.2
lambd: 0.95
num_epoch: 3
learning_rate_schedule: linear
network_settings:
normalize: true
hidden_units: 128
num_leyers: 3
vis_encode_type: simple
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
keep_checkpoints: 5
checkpoint_interval: 100000
max_steps: 30000000
time_horizon: 64
summary_freq: 5000
threaded: true
トレーニングの高速化
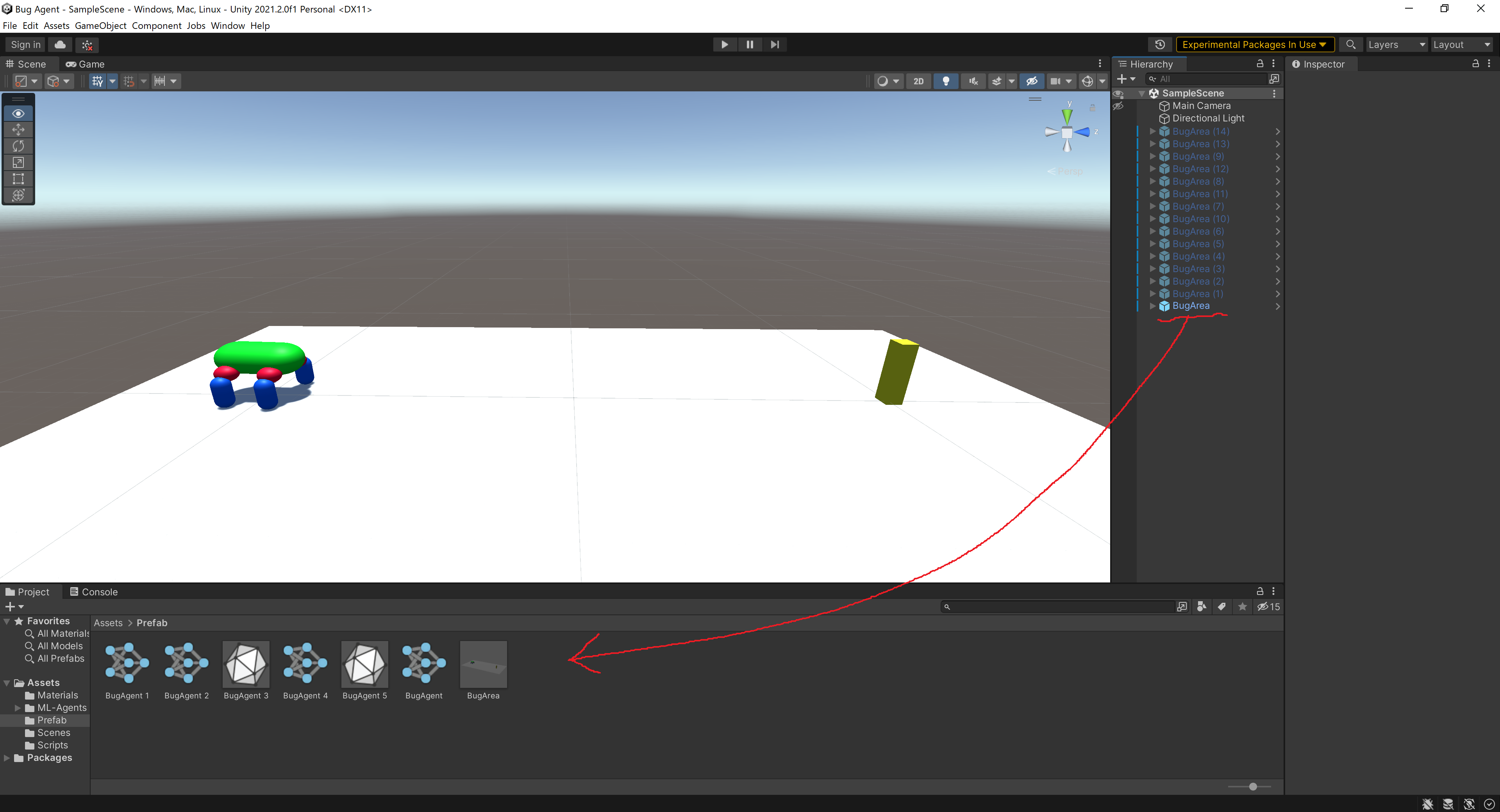
今回のタスクは前回のタスクと比べると格段に内容が難しくなっています。そのためある程度トレーニングを高速化する必要があります。ここでは最も簡単なプレハブから環境を量産する方法を紹介します。
環境の作成の際にプレハブ化を行いました。プレハブ化されたオブジェクトはSceneウィンドにドラッグ&ドロップすることでコピーすることができます。

自分は画像のように15個の環境をコピーして同時に学習をさせました。これによってモデルの収束を早めることができます。
特に操作はなくトレーニングを実行すればすべての環境で並列して学習が行われます。これ以外にもビルドしてアプリ化することでトレーニングを高速化することもできますが今回は使わなかったので紹介しません。気になる人は公式のドキュメントを参照してみてください。
トレーニング結果
以下がトレーニング結果になります。そこそこ4足歩行と言える動きを作れていると思います!
足の動かす順番が少しおかしかったり若干跳ねたりしているのでまだ少し改良の余地がありそうです。
自分は力尽きたのでやる気のある人は是非トライしてみてください!
まとめ
この記事では4足歩行のモデルをUnity ML-Agents上で学習する方法を紹介してみました。強化学習を3Dモデルで行いたいと考えている人の役に少しでもたてたら嬉しいです。
気づいていたかもしれませんが、この記事はすべての作業が完了してから書いたものなのでどこかで手順が抜け落ちていたりするかもしれません。そのようなことがあればコメントなどで教えていただけると幸いです。
ここまで読んでいただきありがとうございました。楽しいML-Agentsライフをお送りください!