本記事について
本記事では自己教師あり学習の概要と枠組みに加えて,代表的な手法を紹介しつつ,いくつかの手法を解説する.すべての手法は解説しません.
深層学習を用いた画像認識手法(Convolutional Neural NetworkやVision Transformer)は知っているが,自己教師あり学習はあま
自己教師あり学習とは
自己教師あり学習(SSL:Self-Supervised Learning)は,正解ラベルのない大量のデータから,学習用の情報(ラベルやデータの関係性など)を自動的に生成し,学習に用いる手法.
自己教師あり学習は以下の2つに大別
本記事では,主に下流タスクに利用する事前学習を行う手法を紹介する.
特定のタスクに特化した手法
異常検知,自動運転 etc.
手法例
- CutPaste
- CutPaste: Self-Supervised Learning for Anomaly Detection and Localization
- SelfOcc
- SelfOcc: Self-Supervised Vision-Based 3D Occupancy Prediction
下流タスクに利用する事前学習を行う手法
Contrastive Learning,Masked Image Modeling etc.
手法例
- SimCLR
- A Simple Framework for Contrastive Learning of Visual Representations
- SimMIM
- SimMIM: A Simple Framework for Masked Image Modeling
大量のラベルなしデータを用いた事前学習
自己教師あり学習や半教師あり学習により様々データで学習した様々な下流タスクに適用可能な大規模なモデルを基盤モデルといいOpenAIが開発したGenerative Pretrained Transformer(GPT)やCLIP,Metaの開発したSegment Anything Model(SAM)などが該当する.
SSLで学習したモデルは事前学習モデルとして様々な下流タスク(画像分類,物体検出,セグメンテーション など)に合わせて転移学習・Fine-tuningを行う.
自己教師あり学習は主に以下の2つのステップで学習される.
1,入力データに対して疑似的なラベルを付与してPretext taskでモデルを事前学習
2,事前学習済みのモデルを下流タスクに合わせて転移学習・Fine-tuning
Pretext taskについて
Pretext taskはラベルを付与していないデータを用いてモデルに解かせる疑似的な問題を指す.
様々な手法が提案され,現在は同じ画像から得られた特徴量は近づけ,異なる画像から得られた特徴量は遠ざけるように学習するContrastive Learning(CL)とマスクされたパッチを予測するMasked Image Modeling(MIM)が主流である.
例:色予測や回転角度の予測,ジグソーパズル,色と形状変換の予測,マスクされた画素値の予測 など
主なSSLの手法
ここでは,SSLの手法としてCLベースの手法とMIMベースの手法を紹介する.
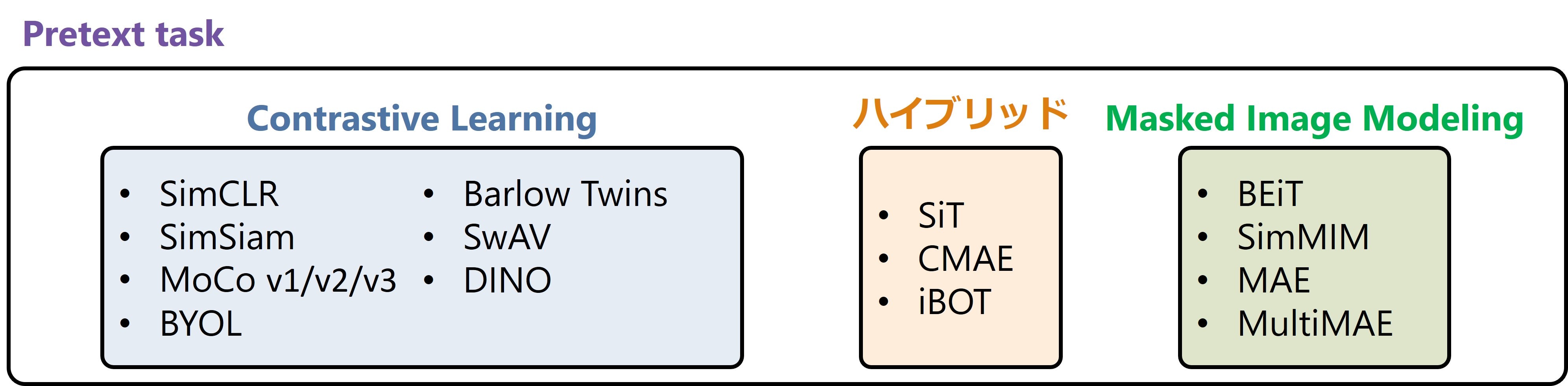
CLベースの手法
CLベースの手法ではData Augmentationにより拡張した画像をモデル(Encoder)に入力し特徴量を抽出する.そして,同じ画像から得られた特徴量は近づけ,異なる画像から得られた特徴量は遠ざけるように学習する.
CLベースの手法の代表的なものとして下記があげられる.
- MoCo v1/v2/v3
- Momentum Contrast for Unsupervised Visual Representation Learning
- Improved Baselines with Momentum Contrastive Learning
- An Empirical Study of Training Self-Supervised Vision Transformers
- SimCLR
- A Simple Framework for Contrastive Learning of Visual Representations
- BYOL
- Bootstrap your own latent: A new approach to self-supervised Learning
- Barlow Twins
- Barlow Twins: Self-Supervised Learning via Redundancy Reduction
- SwAV
- Unsupervised Learning of Visual Features by Contrasting Cluster Assignments
- SimSiam
- Exploring Simple Siamese Representation Learning
- DINO
- Emerging Properties in Self-Supervised Vision Transformers
MIMベースの手法
MIMベースの手法では入力画像を分割したパッチの内一部のパッチをマスクする.そして,マスクしていないパッチのみをモデルに入力し,マスクされたパッチを予測するように学習する.
MIMベースの手法の代表的なものとして下記があげられる.
- BEiT
- BEiT: BERT Pre-Training of Image Transformers
- SimMIM
- SimMIM: A Simple Framework for Masked Image Modeling
- MAE
- Masked Autoencoders Are Scalable Vision Learners
- MultiMAE
- MultiMAE: Multi-modal Multi-task Masked Autoencoders
CLとMIMを組み合わせた手法
CLとMIMを組み合わせた手法も提案されている.
CLとMIMを組み合わせた手法の代表的なものとして下記があげられる.
- iBOT
- iBOT: Image BERT Pre-Training with Online Tokenizer
- SiT
- SiT: Self-supervised vIsion Transformer
- CMAE
- Contrastive Masked Autoencoders are Stronger Vision Learners
解説
各学習手法からいくつかを抜粋して,紹介する.
Cntrastive Learning(CL)ベースの手法
MoCo (v1) ※ 後述するMoCo v2/v3が提案されて以降区別するためにMoCo v1と呼ばれることもある
- ポジティブペアの類似度を最大化,ネガティブペアの類似度を最小化するように学習
- queueに特徴量を保存し,ネガティブペアとして活用
- MoCoはミニバッチ内の画像を拡張するData Augmentationと特徴量を抽出するEncoder,Momentum Encoder,特徴量を保存するqueueで構成
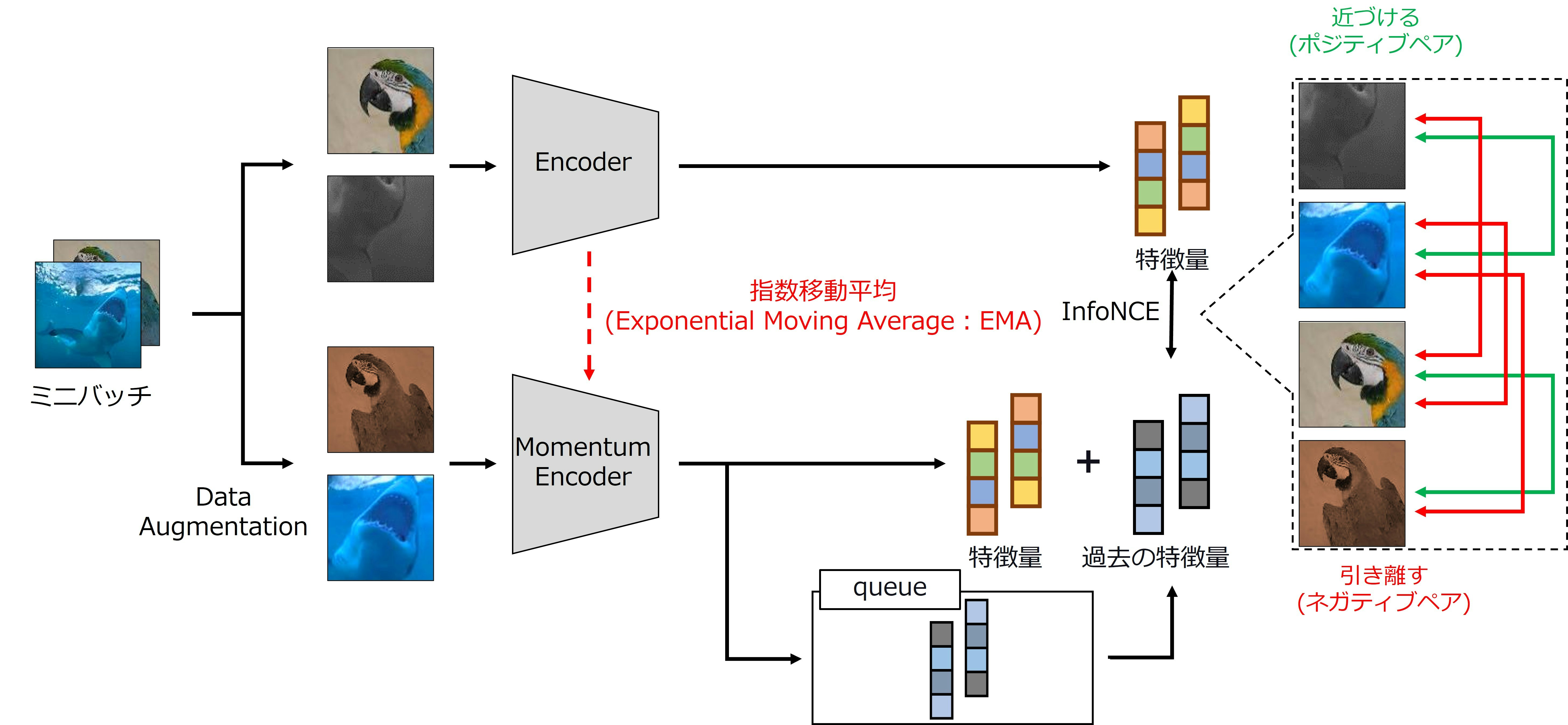
MoCoは4つのステップで学習を行う.
-
データ拡張
- ミニバッチの画像にData Augmentationを施し見えの異なる2枚の画像に拡張
- ポジティブペア:元画像が同じ画像
- ネガティブペア:元画像が異なる画像
- ミニバッチの画像にData Augmentationを施し見えの異なる2枚の画像に拡張
-
特徴量の抽出
- 拡張した画像群をEncoderとMomentum Encoderに入力し,特徴量を抽出
- Momentum Encoderの重みはEncoderの指数移動平均(EMA)で更新
- queueに保存された特徴量と分布が大きくずれることを防止するため
- Momentum Encoderの重みはEncoderの指数移動平均(EMA)で更新
- 拡張した画像群をEncoderとMomentum Encoderに入力し,特徴量を抽出
-
損失計算
- 損失関数にはInfoNCEを使用
- ポジティブペアの類似度を最大化,ネガティブペアの類似度を最小化するように学習
- ネガティブペアにはqueueに保存された過去の特徴量も使用
-
queueの更新(保存)
- Momentum Encoderから得られた特徴量でqueueを更新(保存)
- queueに保存された特徴量はネガティブペアとして活用
- Momentum Encoderから得られた特徴量でqueueを更新(保存)
MoCo v2 ※ SimCLRに触発されMoCo v1を改良した手法
- MoCo v1にProjectorとData Augmentationの種類を増やした手法
- Encoder,Momentum Encoderで抽出した特徴量をProjectorに入力して損失を計算
- MoCo v2はミニバッチ内の画像を拡張するData Augmentationと特徴量を抽出するEncoder,Momentum Encoder,特徴量を保存するqueue,特徴量を投影変換するProjectorで構成
- Projectorは2層の全結合層から構成されるMLPである
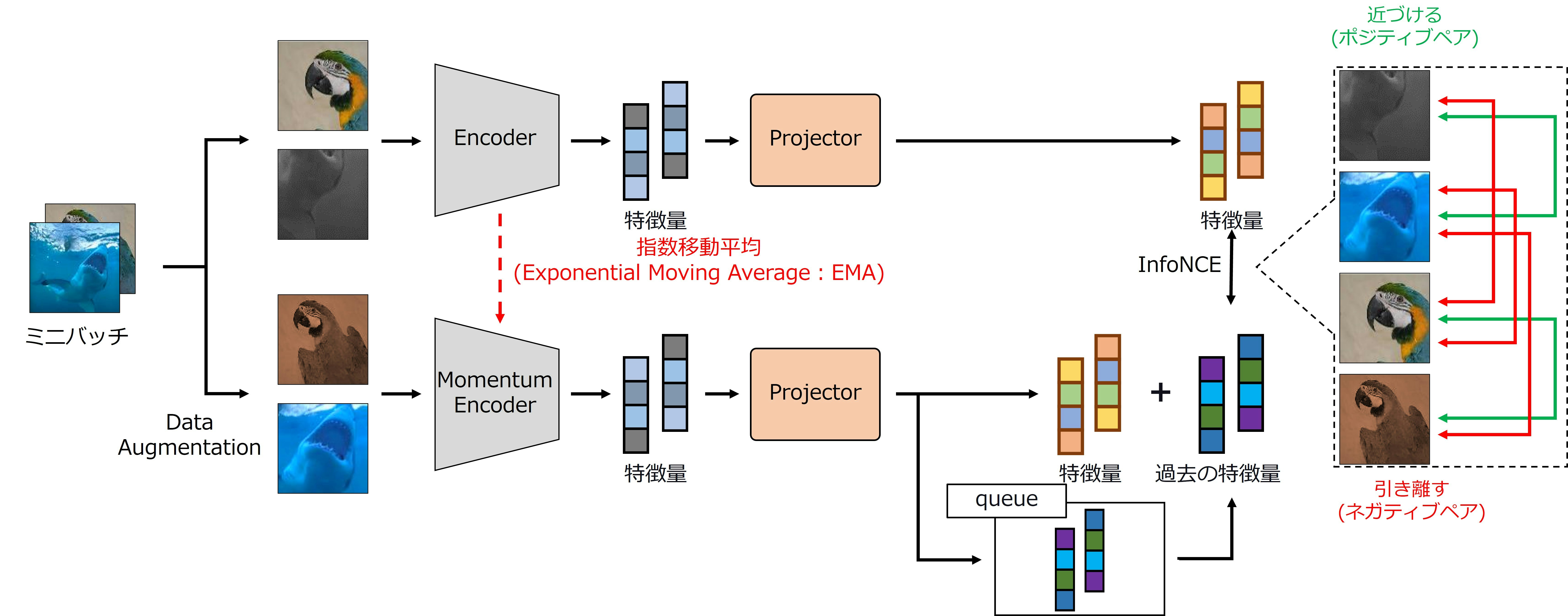
学習の流れは基本的にMoCo v1と同じであるため割愛する
MoCo v3 ※ Vision Transformer(ViT)にも適用できるようにMoCo v1/v2を改良した手法
- MoCo v3はミニバッチ内の画像を拡張するData Augmentationと特徴量を抽出するEncoder,Momentum Encoder,特徴量を投影変換するProjectorで構成
- Projectorは2層の全結合層から構成されるMLPである
- MoCo v2からqueueを削除した構成であるため,queueの更新(保存)を行わない
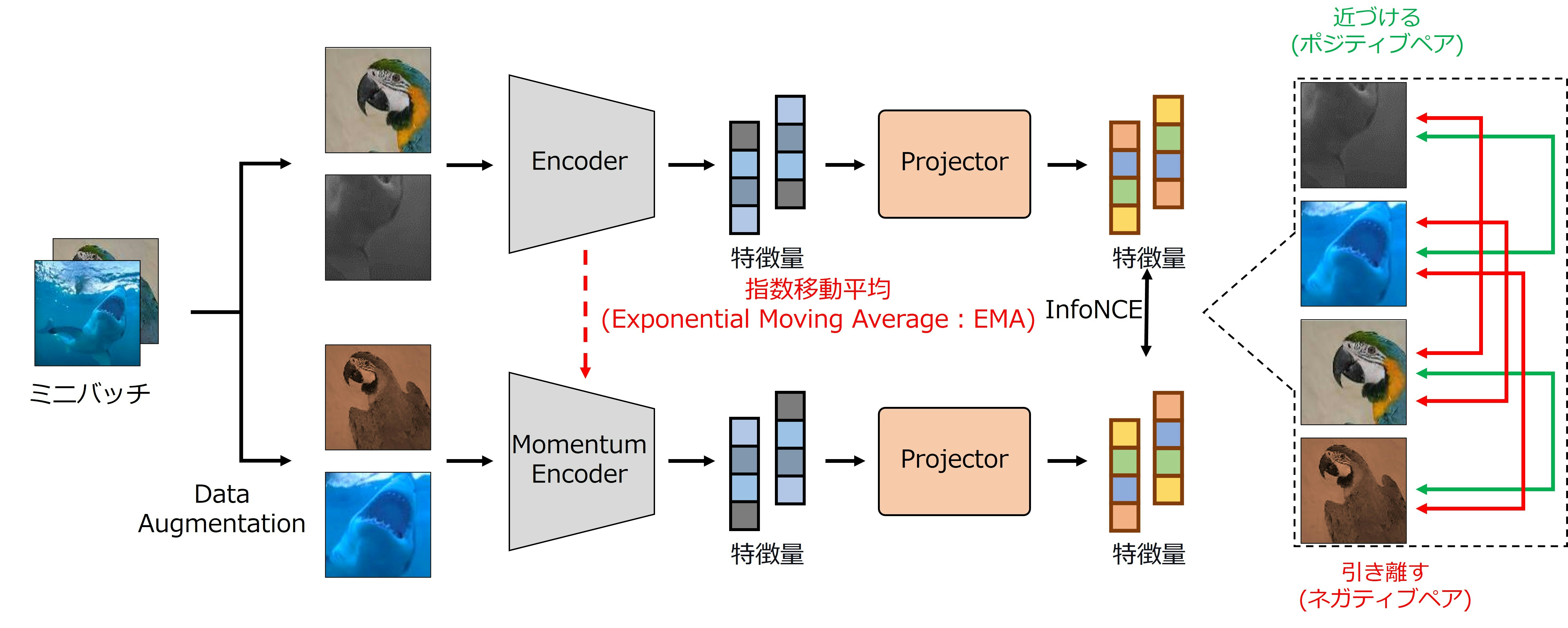
学習の流れは基本的にMoCo v1/v2と同じであるため割愛する.
SimCLR
- ポジティブペアの類似度を最大化,ネガティブペアの類似度を最小化するように学習
- Encoderで抽出した特徴量をProjectorに入力して損失を計算
- SimCLRはミニバッチ内の画像を拡張するData Augmentationと特徴量を抽出するEncoder,特徴量を投影変換するProjectorで構成
- Projectorは2層の全結合層から構成されるMLPである

SimCLRは3つのステップで学習を行う.
- データ拡張
- ミニバッチの画像にData Augmentationを施し見えの異なる2枚の画像に拡張
- ポジティブペア:元画像が同じ画像
- ネガティブペア:元画像が異なる画像
- ミニバッチの画像にData Augmentationを施し見えの異なる2枚の画像に拡張
- 特徴量の抽出
- 拡張した画像群をEncoderとProjectorに入力し,特徴量を抽出
- Encoder,Projectorの重みは共有
- Projectorを介することで,EncoderがPretext taskに特化することを防止
- 拡張した画像群をEncoderとProjectorに入力し,特徴量を抽出
- 損失計算
- 損失関数にはNormalized Temperature-scaled Cross Entropyloss(NT-Xent)を使用
- ポジティブペアの類似度を最大化,ネガティブペアの類似度を最小化するように学習
- Projectorで投影変換した特徴量で類似度を計算
SimSiam
- ポジティブペアの類似度を最大化するように学習
- ネガティブペアは使用しない
- SimCLRより計算量を削減
- Encoderで抽出した特徴量をProjector及びPredictorに入力して損失を計算
- ネガティブペアは使用しない
- SimSiamはミニバッチ内の画像を拡張するData Augmentationと特徴量を抽出するEncoder,特徴量を投影変換するProjector,特徴量を予測するPredictorで構成
- Projector,Predictorは2層の全結合層から構成されるMLPである
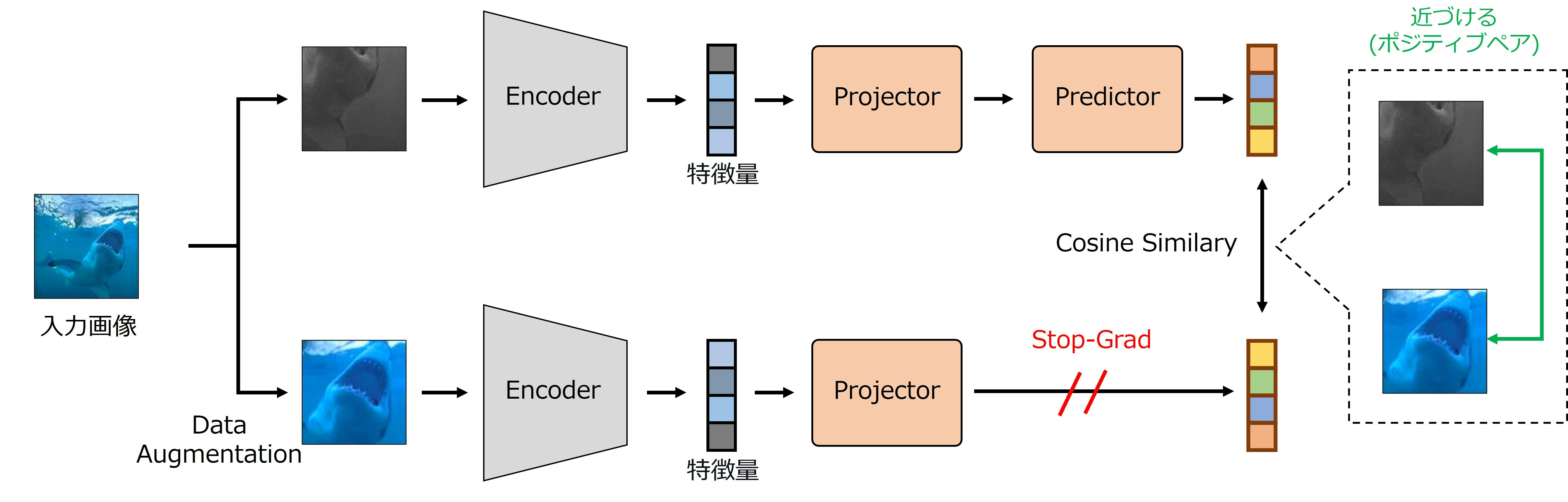
SimSiamは3つのステップで学習を行う.
- データ拡張
- ミニバッチの画像にData Augmentationを施し見えの異なる2枚の画像に拡張
- ポジティブペア:元画像が同じ画像
- ミニバッチの画像にData Augmentationを施し見えの異なる2枚の画像に拡張
- 特徴量の抽出
- 拡張した画像群をEncoder,Projector,Predictorに入力し,特徴量を抽出
- Encoder,Projector,Predictorの重みは共有
- 拡張した画像群をEncoder,Projector,Predictorに入力し,特徴量を抽出
- 損失計算
- 損失関数には負のコサイン類似度を使用
- ポジティブペアの類似度を最大化するように学習
- Projectorで投影変換した特徴量とPredictorで予測した特徴量で類似度を計算
- Predictor,Stop-Gradを用いることでモデルの崩壊を防止
- モデルの崩壊:どのような画像に対しても同じ特徴量を抽出するように学習してしまうこと
- ネガティブペアを使用せず,ポジティブペアを近づけるだけなので発生しやすい
DINO
- 自己教師あり学習に蒸留(distillation)の考えを導入した手法
- 見えの異なる画像から得られた特徴量の類似度を最大化するように学習
- 局所領域を切り出すLocalと大局領域を切り出すGlobalを適用
- StudentにはLocalを適用した画像,TeacherにはGlobalを適用した画像を入力
- 局所領域を切り出すLocalと大局領域を切り出すGlobalを適用
- ViTにも適用可能な手法
- DINOはミニバッチ内の画像を拡張するData Augmentationと特徴量を抽出するEncoder,特徴量を投影変換するProjector,特徴量を調整するCentering,Sharpeningで構成
- Encoderは重みの異なるTeacherとStudentを使用
- Projectorは4層の全結合層から構成されるMLPである
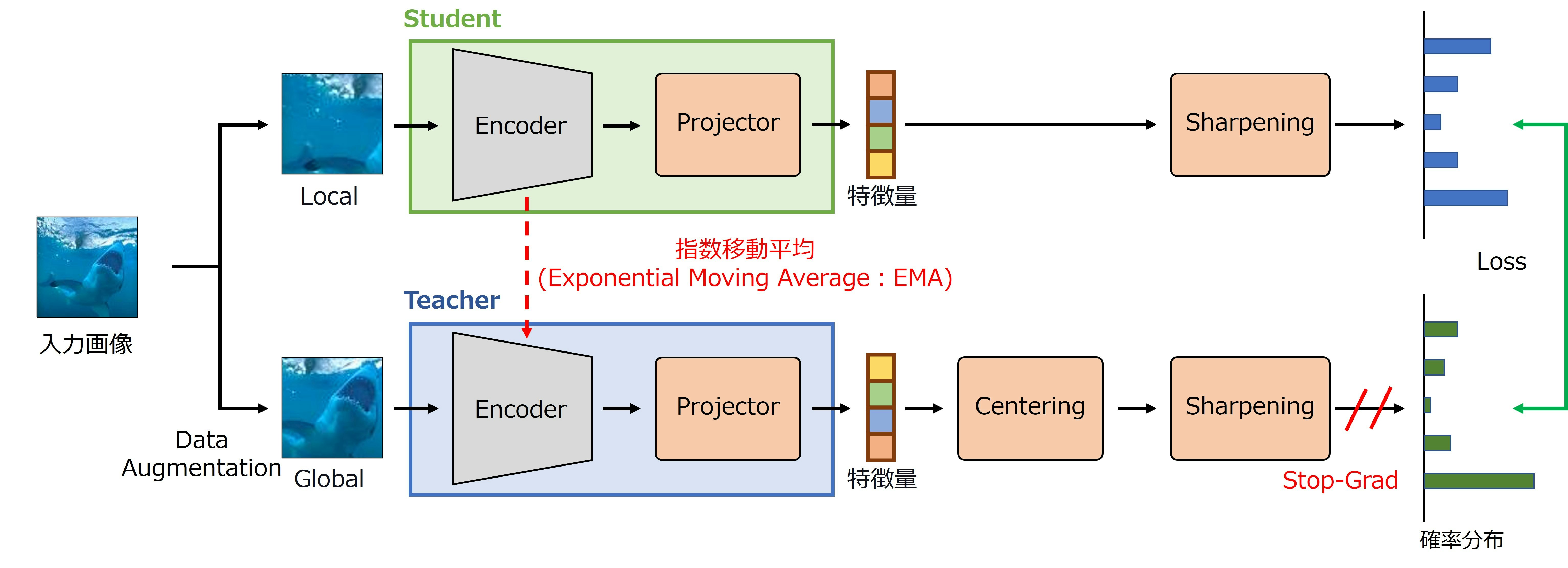
DINOは4つのステップで学習を行う.
- データ拡張
- ミニバッチの画像にデータ拡張を施し見えの異なる2枚の画像に拡張
- 局所領域を切り出すLocalと大局領域を切り出すGlobalを適用
- ポジティブペア:元画像が同じ画像
- ミニバッチの画像にデータ拡張を施し見えの異なる2枚の画像に拡張
- 特徴量の抽出
- 拡張した画像群をEncoder,Projectorに入力し,特徴量を抽出
- Teacherの重みはStudentのEMAで更新
- StudentにはLocalを適用した画像,TeacherにはGlobalを適用した画像を入力
- Studentは難易度の高い問題,Teacher難易度の低い問題を解く
- 拡張した画像群をEncoder,Projectorに入力し,特徴量を抽出
- 特徴量の調整(Centering,Sharpening)
- Teacherが出力した特徴量にCenteringを適用
- どのような画像に対しても同じ特徴量を抽出することを防止
- Teacher,Studentが出力した特徴量にSharpeningを適用
- 温度付きSoftmax関数と同じ処理
- 特徴量の分布が均一にならないように分布を強調(分布を鋭くしている)
- Teacherが出力した特徴量にCenteringを適用
- 損失計算
- Teacherが出力する特徴量とStudentが出力する特徴量を近づけるように学習
- Teacher:CenteringとSharpeningを施した特徴量
- Student: Sharpeningを施した特徴量
- Centering,Sharpening,Stop-Gradを用いることでモデルの崩壊を防止
- Teacherが出力する特徴量とStudentが出力する特徴量を近づけるように学習
Masked Image Modeling(MIM)ベースの手法
SimMIM
- Transformerベースの画像認識モデル用の自己教師あり学習の手法
- EncoderにはViTやSwin TransformerのEncoderを使用
- SimMIMはEncoderと画像を復元する全結合層で構成
- 画像の復元には,1層の全結合層を使用
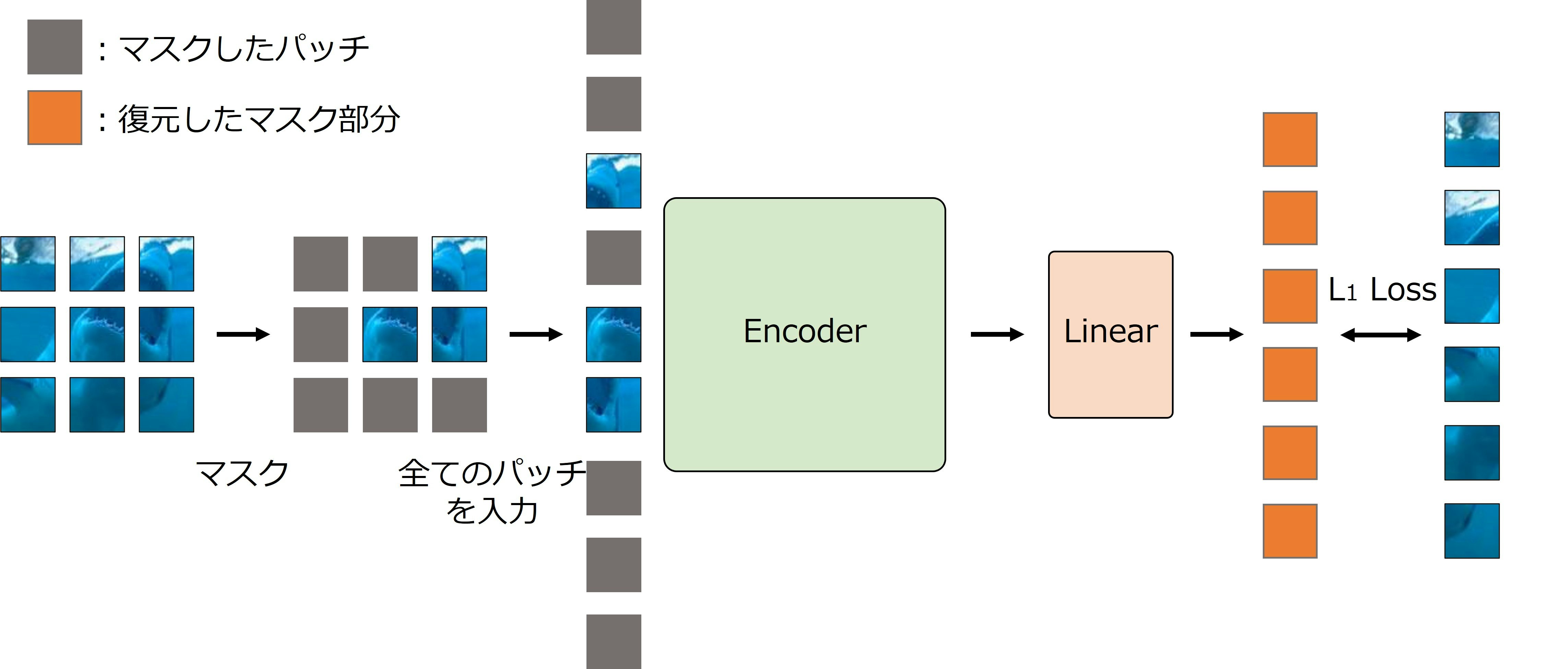
SimMIMは4つのステップで学習を行う.
-
パッチをマスク
- 入力画像をパッチに分割し,マスクを適用
- マスク率には60 %を使用
- 入力画像をパッチに分割し,マスクを適用
-
パッチトークン(特徴量)の抽出
- マスクしたパッチとマスクされていないパッチの両方をEncoderに入力し,特徴量を抽出
-
マスクしたパッチを復元
- Encoderが抽出した特徴量を基にマスクしたパッチを復元
- 復元には,1層の全結合層を使用することで軽量化
-
損失計算
- 損失関数にはL1 Lossを使用
- 復元したパッチとマスクしたパッチ(入力画像)のL1 Lossを最小化するように学習
Masked Autoencoder(MAE)
- ViT用の自己教師あり学習の手法
- EncoderとDecoderで構成
- EncoderとDecoderにはTransformer Encoderを使用
- DecoderはEncoderより小規模なTransformer Encoder
- 下流タスク適用時にはEncoderのみ使用し,Decoderは破棄
- EncoderとDecoderにはTransformer Encoderを使用

MAEは4つのステップで学習を行う.
- パッチをマスク
- 入力画像をパッチに分割し,マスクを適用
- マスク率には75 %などの高い値を使用
- 入力画像をパッチに分割し,マスクを適用
- パッチトークン(特徴量)の抽出
- マスクされていないパッチのみをEncoderに入力し,パッチトークンを抽出
- マスクされていないパッチのみを入力することで,計算量を削減
- マスクされていないパッチのみをEncoderに入力し,パッチトークンを抽出
- マスクしたパッチを復元
- パッチトークンにマスクトークンを結合し, Decoderに入力
- マスクしたパッチを復元するように学習
- マスクトークン:マスクしたパッチを意味するトークン
- 損失計算
- 損失関数には平均二乗誤差(MSE)を使用
- 復元したパッチとマスクしたパッチ(入力画像)のMSEを最小化するように学習
MultiMAE
- MAEをマルチモーダルに拡張した手法
- 下流タスク適用時は,MAEと異なりマルチモーダルに適用可能
- Encoderと各モーダル用のDecoderで構成
- EncoderとDecoderにはTransformer Encoderを使用
- DecoderはEncoderより小規模なTransformer Encoder
- 下流タスク適用時にはEncoderのみ使用し,Decoderは破棄
- EncoderとDecoderにはTransformer Encoderを使用
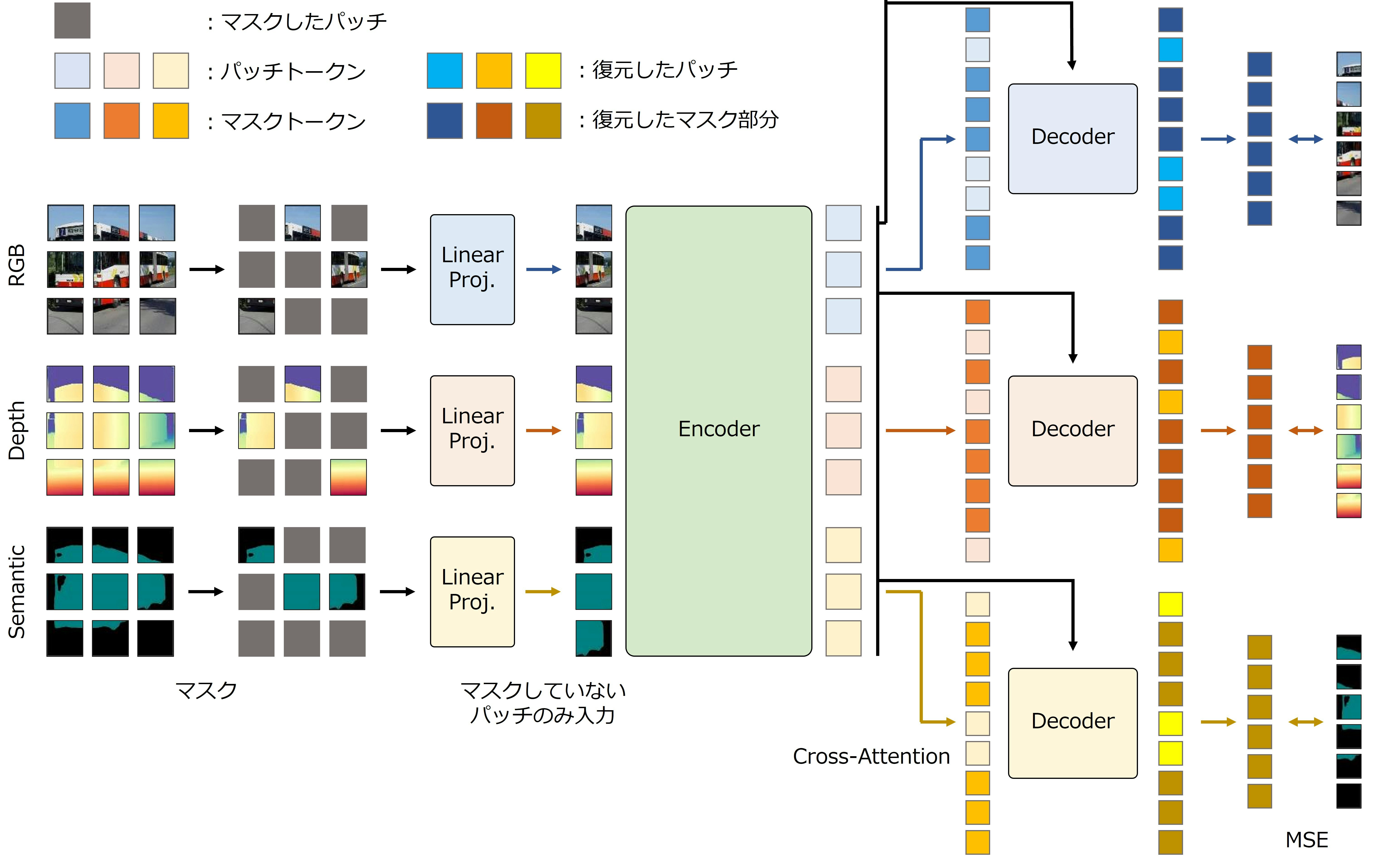
MultiMAEは4つのステップで学習を行う.
- パッチをマスク
- 入力画像(複数のモーダルの画像)をパッチに分割し,マスクを適用
- マスク率には75 %などの高い値を使用
- 入力画像(複数のモーダルの画像)をパッチに分割し,マスクを適用
- パッチトークン(特徴量)の抽出
- マスクされていないパッチのみをEncoderに入力し,パッチトークンを抽出
- マスクされていないパッチのみを入力することで,計算量を削減
- マスクされていないパッチのみをEncoderに入力し,パッチトークンを抽出
- マスクしたパッチを復元
- 各モーダルのパッチトークンにマスクトークンを結合し, 各モーダルのDecoderに入力
- マスクしたパッチを復元するように学習
- マスクトークン:マスクしたパッチを意味するトークン
- 損失計算
- 損失関数には平均二乗誤差(MSE)を使用
- 復元したパッチとマスクしたパッチ(入力画像)のMSEを最小化するように学習
CL+MIMのハイブリッド
iBOT
- Contrastive LearningとMasked Image Modelingを組み合わせた手法
- DINOと同様にTeacherとStudentを用いて蒸留(distillation)を行う
- 局所領域を切り出すLocalと大局領域を切り出すGlobalを適用
- Studentにはマスクを適用した画像,Teacherの入力にはマスクを適用しない
- 局所領域を切り出すLocalと大局領域を切り出すGlobalを適用
- iBOTはミニバッチ内の画像を拡張するData Augmentationと特徴量を抽出するEncoder,特徴量を投影変換するProjectorで構成
- Encoderは重みの異なるTeacherとStudentを使用
- Projectorは3層の全結合層から構成されるMLPである
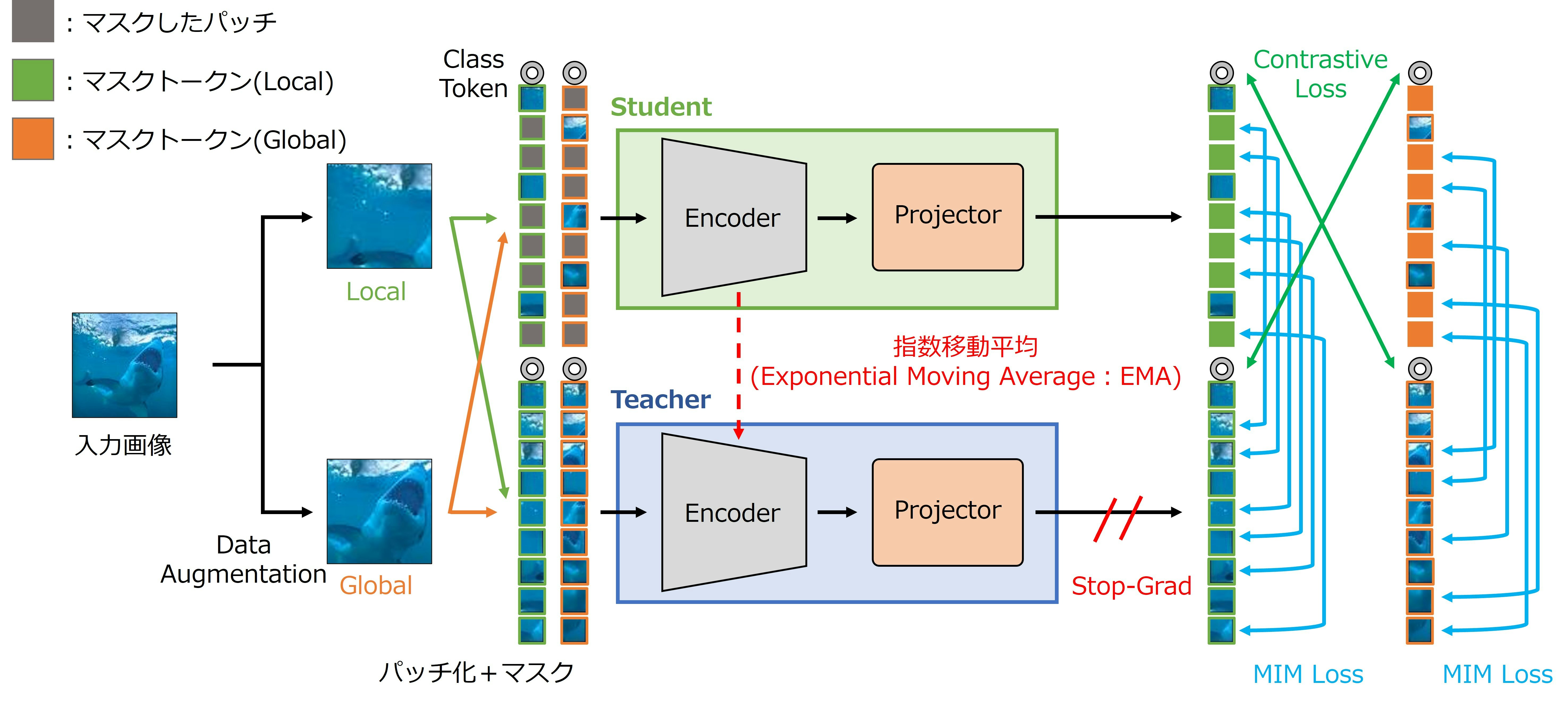
iBOTは3つのステップで学習
-
データ拡張
- ミニバッチの画像にデータ拡張を施し見えの異なる2枚の画像に拡張
- 局所領域を切り出すLocalと大局領域を切り出すGlobalを適用
- ポジティブペア:元画像が同じ画像
- ミニバッチの画像にデータ拡張を施し見えの異なる2枚の画像に拡張
-
特徴量の抽出
- 拡張した画像群をEncoder,Projectorに入力し,特徴量を抽出
- Teacherの重みはStudentのEMAで更新
- Studentにはマスクを適用した画像,Teacherの入力にはマスクを適用しない
- 拡張した画像群をEncoder,Projectorに入力し,特徴量を抽出
-
損失計算
- 2つの損失で学習
- Contrastive Loss:StudentのClass TokenとTeacherのClass Tokenの類似度を最大化
- MIM Loss:Studentが出力したマスクトークンとTeacherが出力した特徴量を最小化
- 2つの損失で学習
まとめ
近年非常に注目されている自己教師あり学習の概要とPretext task,自己教師あり学習の枠組みとしてCLベースの手法とMIMベースの手法の代表的な手法を紹介しました.
ここで,SimCLRとSimSiamのサンプルコードを公開しています.
参考文献
- CutPaste: Self-Supervised Learning for Anomaly Detection and Localization
- SelfOcc: Self-Supervised Vision-Based 3D Occupancy Prediction
- Improving Language Understanding by Generative Pre-Training
- Language Models are Unsupervised Multitask Learners
- Language Models are Few-Shot Learners
- Learning Transferable Visual Models From Natural Language Supervision
- Segment Anything
- Momentum Contrast for Unsupervised Visual Representation Learning
- Improved Baselines with Momentum Contrastive Learning
- An Empirical Study of Training Self-Supervised Vision Transformers
- A Simple Framework for Contrastive Learning of Visual Representations
- Bootstrap your own latent: A new approach to self-supervised Learning
- Barlow Twins: Self-Supervised Learning via Redundancy Reduction
- Unsupervised Learning of Visual Features by Contrasting Cluster Assignments
- Exploring Simple Siamese Representation Learning
- Emerging Properties in Self-Supervised Vision Transformers
- BEiT: BERT Pre-Training of Image Transformers
- SimMIM: A Simple Framework for Masked Image Modeling
- Masked Autoencoders Are Scalable Vision Learners
- MultiMAE: Multi-modal Multi-task Masked Autoencoders
- iBOT: Image BERT Pre-Training with Online Tokenizer
- SiT: Self-supervised vIsion Transformer
- Contrastive Masked Autoencoders are Stronger Vision Learners