はじめに
最近、プライベートでデータ分析のツールを作成している関係でpandasというpython外部ライブラリを活用している。が、いざ使って見ると、「pandas?なにそれかわいいの?」と動物のパンダ🐼を連想させるヤバい思考に行きつつある状況になる。
これはまずいと感じ、投稿者はpandasを探し求める旅に出る。
この記事は、pandasを飼いならすためにpandasをSQLっぽく考えるというデータサイエンス初学者に向けた記事となります。
そもそもpandasとは何か
pandasとは、構造化された(表形式、多次元、潜在的に不均質)データと時系列データを簡単かつ直感的に操作できるように設計された高速で柔軟な表現力のあるデータ構造を提供するPythonパッケージで、実際的な実世界のデータ分析を行うための基本的な高レベルのビルドを行う事が可能なツールです。
要は、表データをpythonを使っていい感じに処理して目的のデータ抽出するツールです。
実践
準備
今回は下記の表データ【receipt】を用いてpandas攻略を行います。(表データはCSV形式)
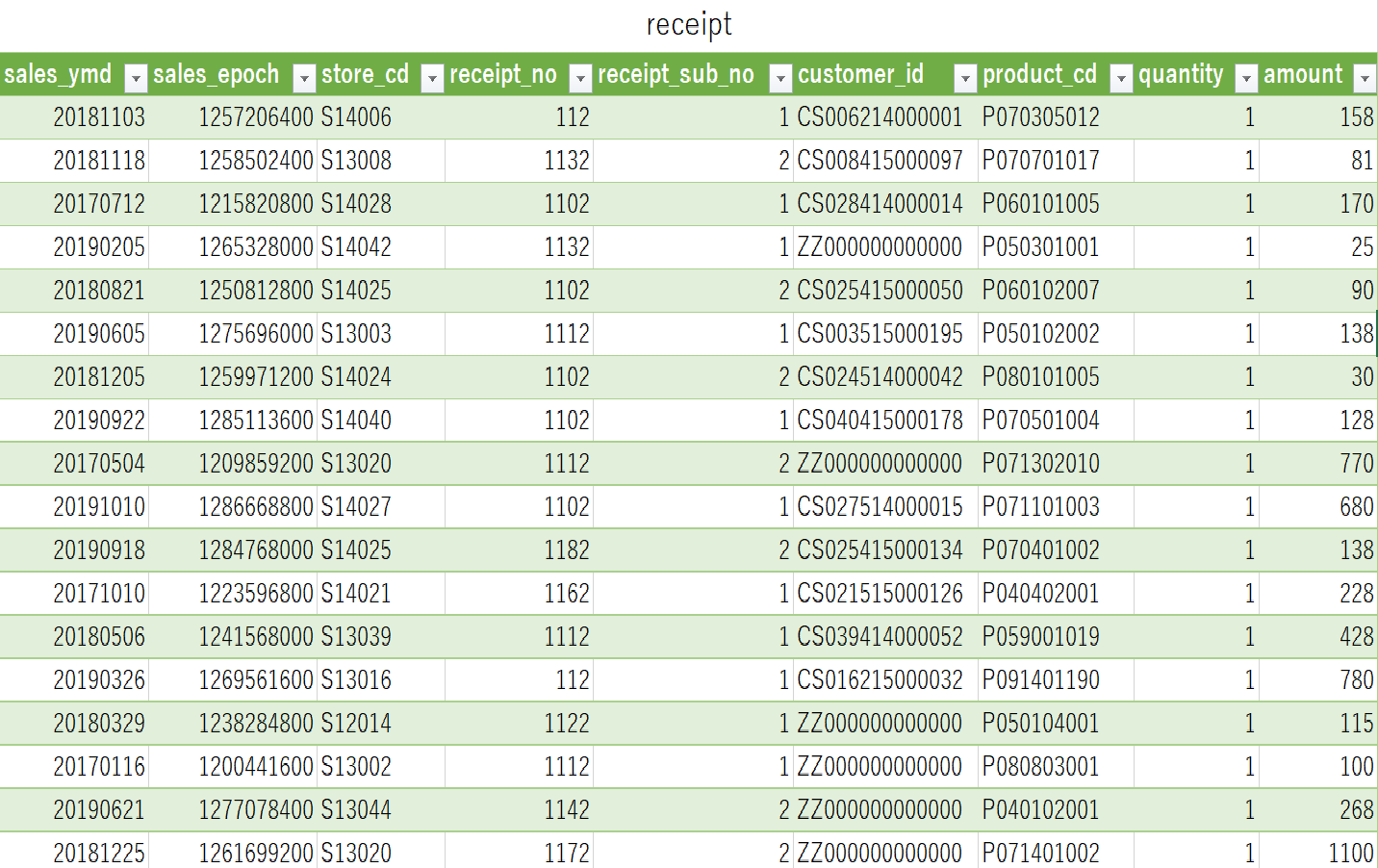
※データは長いので冒頭部分のみ表示
参考データ:データサイエンス100本ノック
https://github.com/The-Japan-DataScientist-Society/100knocks-preprocess
また、今回はpandasを使用するため、コードは下記のように予め準備しておきます。
import pandas as pd
df_receipt = pd.read_csv('receiptのCSVファイルのパス', sep=',')
本題
タイトルにある通り、今回はSQLのSELECT文をpandasを使って再現します
問題:レシート明細のデータフレーム(df_receipt)から売上日(sales_ymd)、顧客ID(customer_id)、商品コード(product_cd)、売上金額(amount)の順に列を指定し、10件表示させよ。
目的:表から特定の行を抜き出す事
解答
まず、解答を記述するとこんな感じになります。
df_receipt[['sales_ymd', 'customer_id', 'product_cd', 'amount']].head(10)
そして、図に表すとこんな感じになります。
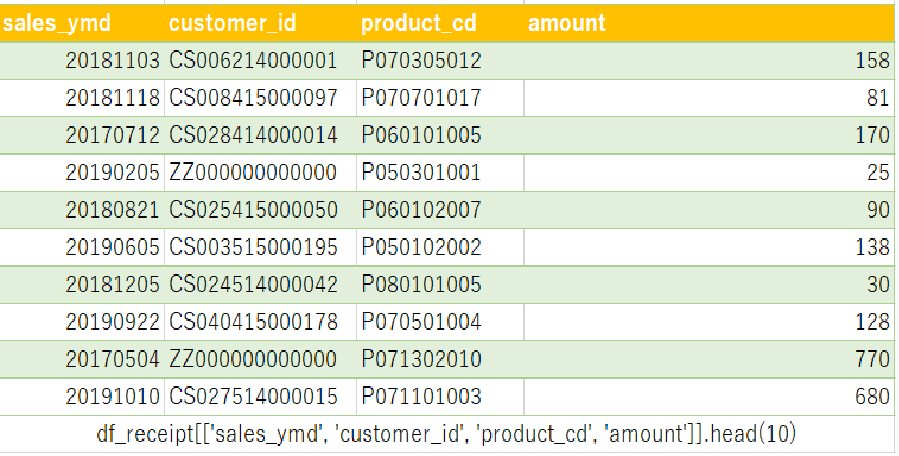
これをSQL文で表すとこんな感じになります。
SELECT sales_ymd,customer_id,product_cd,amount FROM receipt LIMIT 10;
解説
それでは、ここから1つ1つ解説していきます。
- SQLのSELECT文を、pandasでは[ ](リスト)を用いて表現する
SQLのSELECT文は、pandasでは[ ](リスト)を用いて表現する事が可能です。
例えば、今回の対象の表であるreceipt(df_receipt)の全体の最初の10行をpandasで表現すると、
df_receipt.head(10)
となりますが、これは暗黙的な表現であり実際は、
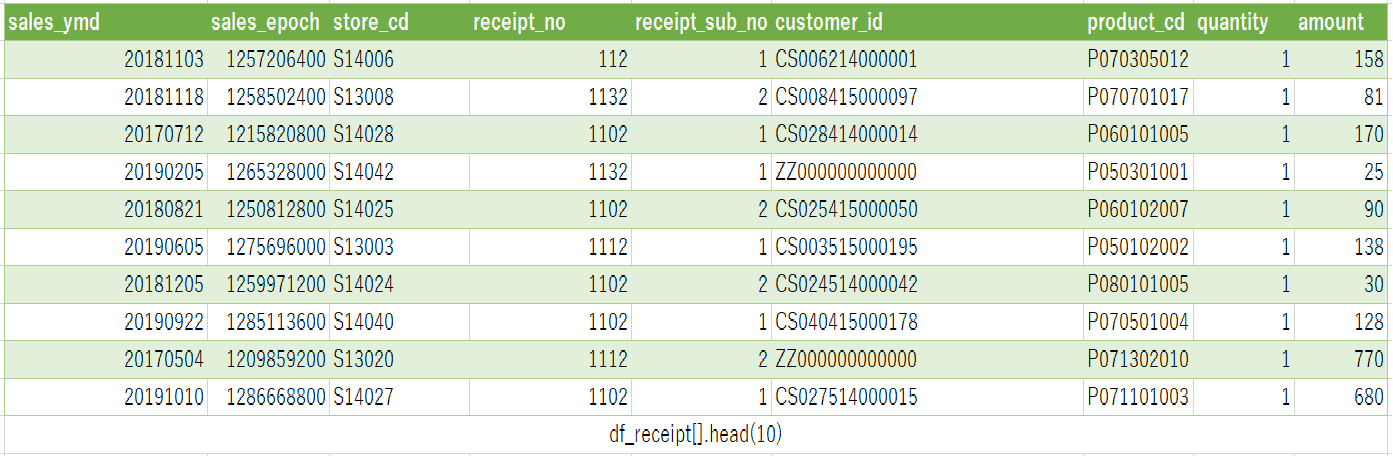
df_receipt[].head(10)
となって、これをSQLで考えるとこんな感じになります。
SELECT * FROM receipt LIMIT 10;
FROM句:データベース内の指定する表を選択する
SELECT文:指定した表から抽出すべき列を選択する
LIMIT句:抽出する行数を指定する
ここで重要なのは「pandasの[ ](リスト)」が「SELECT *」と同義の役割を持つ事です。これは[ ](リスト)の部分がSQLのSELECT文全体を包括している事を意味します。図で表すとこんな感じです。
※補足:head()に関する記事は下記の記事を参考にしてみて下さい。
https://qiita.com/syuki-read/items/a5d52086334a0c4d3ac6
- 二重リストを用いて対象の行を選択する
先ほどは[ ](リスト)を用いて表の全体を選択しました。しかしこれでは対象外の列も出力してしまうため、列の選択(スクリーニング)を行う必要があります。そこで使用するのが二重リストの活用です。まず、外側の[ ](リスト)で表全体の列を選択し、その後更に内側に[ ](リスト)をもう一つ作り、その中に対象行の列名を入力します。
実際に書いてみると、
df_receipt[['sales_ymd', 'customer_id', 'product_cd', 'amount']].head(10)
そして、これをSQLで表現すると
SELECT sales_ymd,customer_id,product_cd,amount FROM receipt LIMIT 10;
となります。
そして、図に表すとこんな感じになります。
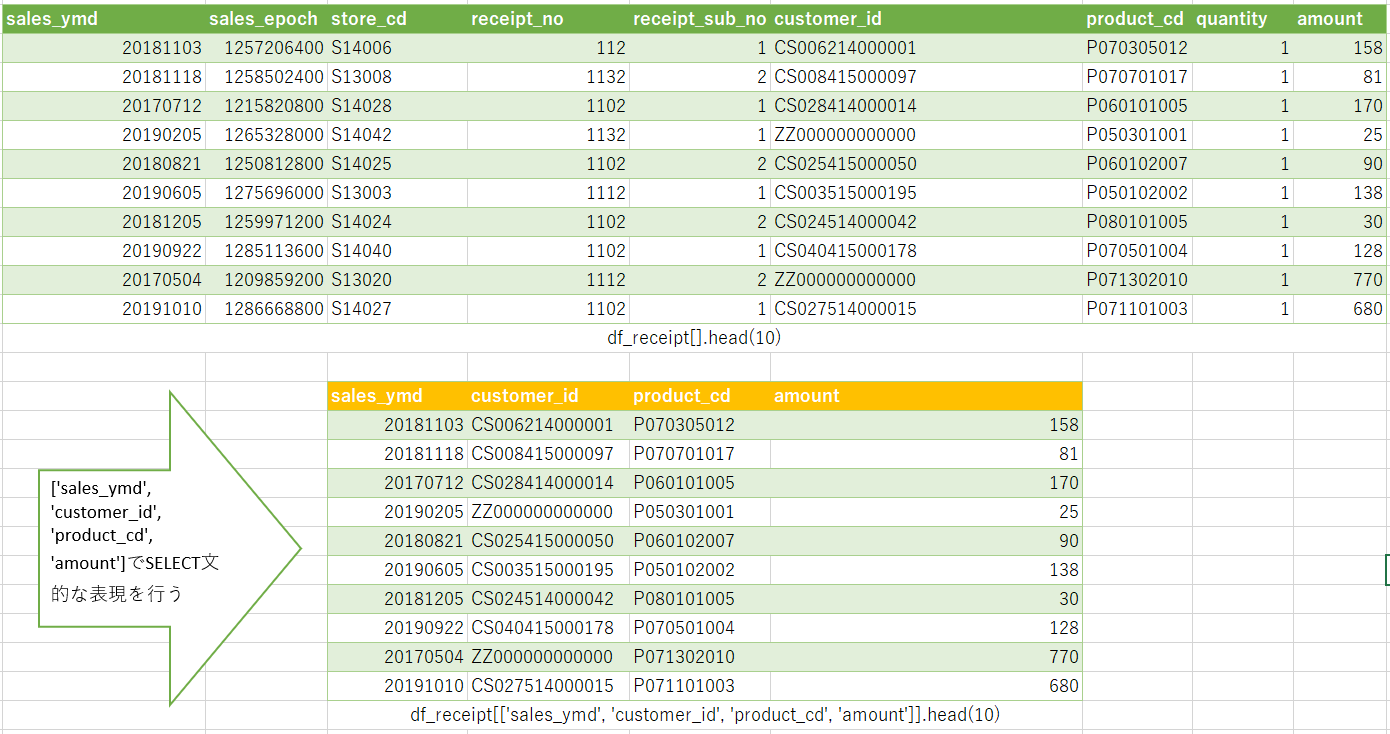
- 全体図
全体をまとめると、こんな感じになります。
まとめ
pandasを使って、SQLのSELECT文の表現を行いました。pandasはデータベース及びSQLを意識したpythonライブラリなため、普段からSQLを意識するとかなり使いやすいツールだと改めて感じます。
終わりに
今回、利活用したデータはデータサイエンス協会(DS協会)の「データサイエンス100本ノック」を参考にしております。こちらはJupyter notebookを使用しているので、より見やすいデータが抽出されます。
この記事を読んで、「実際に実装してみたい!!」という方がおりましたら、下記にその実装に関する記事を上げているので、良かったそちらの記事を参考に是非実装してみて下さい。
データサイエンス初学者にむけた、データサイエンス100本ノックを実装する方法:
https://qiita.com/syuki-read/items/714fe66bf5c16b8a7407