本記事の目的と構成について
本記事は、最近発表された論文
「DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning」 ( GitHub )
の包括的な解説を目的としています。
DeepSeek-R1 は、強化学習(Reinforcement Learning; RL)を用いて 大規模言語モデル(LLM)の推論能力を大幅に高める という革新的なアプローチを取っており、さらに小規模モデルへの 「蒸留(distillation)」 にも成功している点が注目されています。
多くの読者の方にとって、有益で分かりやすい情報提供となるよう、本記事は「2層構造による解説」を特徴としています。
具体的には、各セクションにおいて
-
【詳細・専門的な解説】
- 研究者や技術者向け
- 数式やアルゴリズムなどの技術的側面を深掘り
- 実装や評価方法など実務に役立つ知識を網羅
-
▼ 噛み砕き解説
- 一般的な読者向け
- 難解な専門用語を極力避け、概念をわかりやすく説明
- 要点を簡潔にまとめ、研究の全体像を把握できる
という2種類の解説を用意し、専門家から一般読者まで幅広く理解できる構成を目指しています。
✨ポイント
本記事の下部ではさらに踏み込んだ解説を用意していますが、まずは要点のみを知りたい方向けに、次のようなポイントを中心にお話ししていきます。
-
純粋な強化学習の活用
- 従来の多くのモデルは、大量の教師データに依存して性能向上を図っていましたが、DeepSeek-R1-Zeroは事前の教師付き微調整(SFT)を行わず、純粋な強化学習(RL)のみで推論能力を大幅に向上させました。
- このアプローチにより、モデルは自律的な学習プロセスで、自己検証や反省、長いChain-of-Thought(CoT)生成といった高度な推論行動を自然に獲得しました。
-
Cold Startの導入による改善
- DeepSeek-R1では、小規模で高品質なCoTデータを用いたCold Startを導入し、推論能力の向上を加速させました。
- このステップにより、モデルの出力の可読性が向上し、従来のRLプロセスでの初期不安定性を克服しました。
-
多段階トレーニングの採用
- DeepSeek-R1は、2回のRLステージと2回のSFTステージを組み合わせた多段階トレーニングを採用しています。
- このアプローチにより、モデルは推論能力と非推論能力の両方で性能を向上させ、より幅広いタスクに対応可能となりました。
-
高性能な知識蒸留の実現
- 大型モデル(DeepSeek-R1)の推論パターンを小型の密モデルに蒸留することで、小型モデルであっても大幅な性能向上を実現しました。
- これにより、計算資源が限られた環境でも高い推論能力を発揮できるようになっています。
-
新たなベンチマーク記録の樹立
- DeepSeek-R1は、数学(MATH-500)、推論(GPQA Diamond)、およびコーディング(LiveCodeBench)などの主要ベンチマークで、従来モデルや他のオープンソースモデルを大幅に上回る成績を収めました。
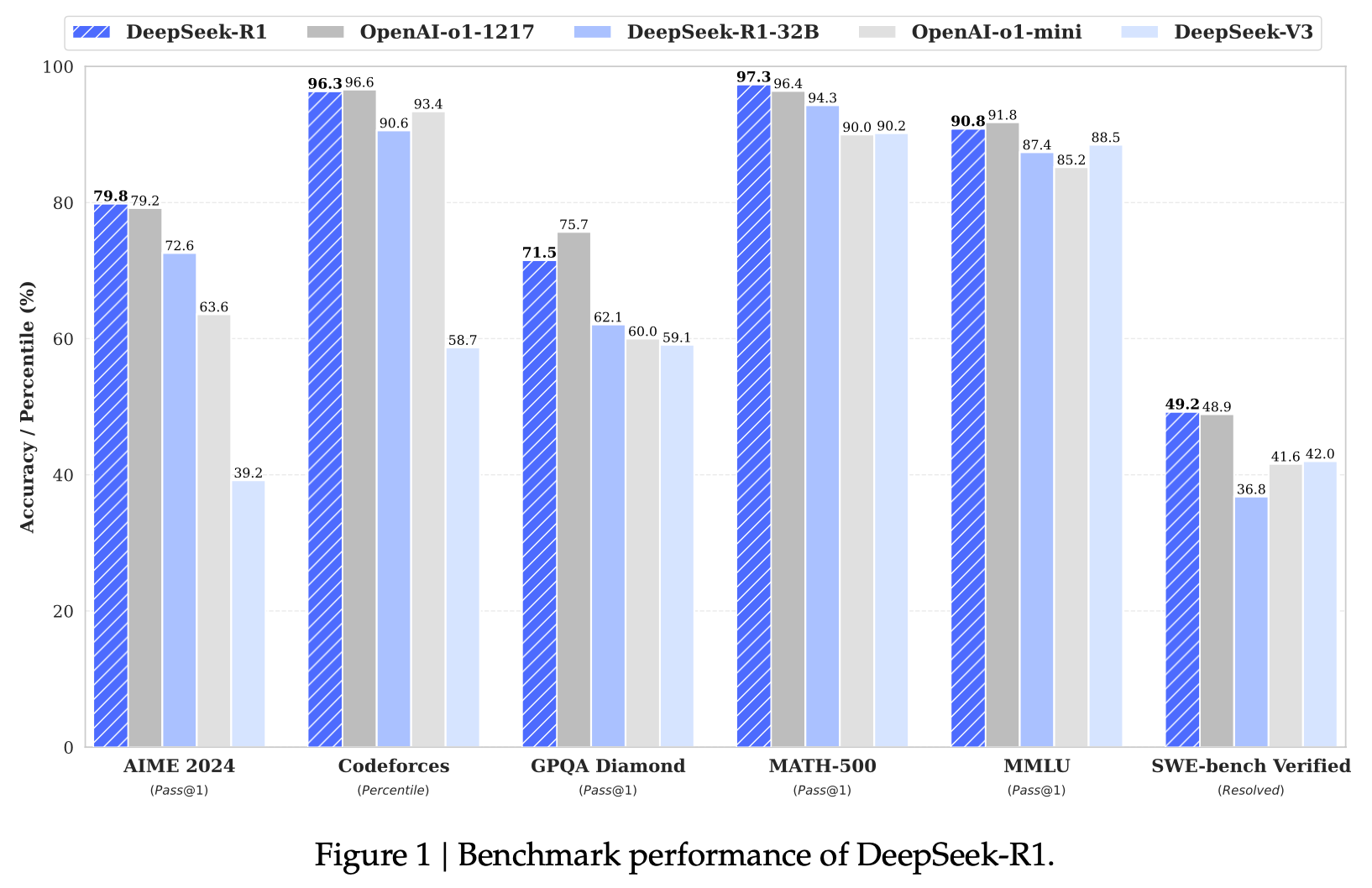
- 特にMATH-500では97.3%の正解率を記録しています。
-
課題解決能力の向上
- 長文の文脈理解やコード生成といったタスクにおいて、DeepSeek-R1は卓越したパフォーマンスを示し、より複雑な課題にも対応可能であることが示されています。
-
「Ahaモーメント」の観測
- DeepSeek-R1-Zeroの自己進化プロセスでは、モデルが初期の間違いを再評価し、新たな問題解決アプローチを自発的に発見する「Ahaモーメント」が観測され、強化学習の可能性を実証しました。
これらのポイントを通じて、本研究は従来の手法を超える革新的な推論モデル開発を達成しており、特に教師データ依存の削減と小型モデルの高性能化という面で顕著です。
次章以降では詳細を順番に解説していきます。
特徴的な2層構造による解説
既述の通り、本記事は読者層に合わせて
- 【詳細・専門的な解説】
- ▼ 噛み砕き解説
の2種類の解説を行います。
「理論や数式の裏付けまで知りたい」という方も、「専門的な知識なしで要点を把握したい」という方も、それぞれのパートを活用して理解を深めていただければと思います。
それでは、解説をはじめていきましょう。
注意: 個人の解釈で解説しているため、正確な内容については論文をご確認ください。
1. はじめに
【詳細・専門的な解説】
近年の大規模言語モデル(LLM)は、事前学習(Pre-training)を通じて膨大なテキストデータから言語表現を獲得し、追加学習(Fine-tuning)やプロンプトエンジニアリングによって特定のタスク性能を向上させる手法が主流でした。
一方で、論理的思考力や多ステップ推論を要するタスクでは、事前学習だけでは不十分な場合が多く、Chain-of-Thought のように思考プロセスをテキスト化する手法や、検索を組み合わせる手法などが盛んに研究されています。
DeepSeek-R1は、これら推論力向上の文脈において、強化学習(RL) を用いてモデルが自律的に推論戦略を学習できるようにしたアプローチです。
さらに、推論力を維持したままより小さいパラメータのモデルに知識を蒸留する技術まで網羅しており、計算資源の面でも効率的です。
以下にDeepSeek-R1のベンチマーク性能を示します。
▼ 噛み砕き解説
- 普通のLLM: たくさんの文章を読み込んで言語のルールを覚えた状態。しかし、複雑な問題解決(数学や論理問題)が苦手なこともある。
- 強化学習を導入: 「どう考えれば正解に近づけるか?」を試行錯誤で学習させる。
- DeepSeek-R1のすごいところ: 強化学習だけで推論力が大きく伸び、しかも その賢さを小さいモデルにも引き継げる(蒸留)点。
2. DeepSeek-R1 概要
2.1 深い推論能力を生む仕組み
【詳細・専門的な解説】
DeepSeek-R1は、大きく2つの段階を踏んでモデルを構築しています。
-
DeepSeek-R1-Zero
- Supervised Fine-Tuning(SFT)なし で、いきなり強化学習を適用したモデル。
- Group Relative Policy Optimization(GRPO)というコスト効率の高いRLアルゴリズムを使用し、モデルの推論力を高める。
- ただし、初期段階では文章が読みづらかったり、言語が混在(英語と中国語など)したりする問題があった。
-
DeepSeek-R1
- DeepSeek-R1-Zeroをベースに、少量のコールドスタートデータ(人間が丁寧に書いたChain-of-Thoughtなど)を使ってSFTを施す。
- 言語混在を防ぎ、可読性を高めるために、言語一貫性の報酬(Language Consistency Reward)を導入。
- Rejection Samplingを用いて品質の高いデータを再収集し、さらにSFTで仕上げを行うことで、総合的に性能を向上。
▼ 噛み砕き解説
-
ステップ1: DeepSeek-R1-Zero
強化学習で推論力を鍛えた最初のモデル。勉強は得意になったけど、ちょっと言葉遣いが混ざってしまったり、読みづらいところがある。 -
ステップ2: DeepSeek-R1
少しだけ人間が書いたお手本(コールドスタートデータ)を見せて、文章を整理できるようにした。さらにデータの質を上げる工夫(リジェクションサンプリング)で、理解しやすさと推論力が両立するモデルに。
3. 手法の詳細
3.1 Reinforcement Learningによる推論最適化
【詳細・専門的な解説】
DeepSeek-R1の最大の特徴は、Supervised Fine-Tuningを省略しても深い推論能力が得られるという点です。具体的には、
-
GRPO (Group Relative Policy Optimization)
- 通常のPPO(Proximal Policy Optimization)とは異なり、同一入力に対する複数候補(グループ) を生成し、その中で相対評価する形で報酬を計算する。
- スカラー報酬を扱うよりも安定した学習が可能で、コスト効率が良い。
-
報酬設計
- 正答率ベース報酬: 数学問題などで正解したかどうか。
-
フォーマット報酬:
<think>タグや<answer>タグなど、整った出力フォーマットになっているか。 - 言語一貫性報酬: 英語と中国語が混ざらないようペナルティを与える、など。
これらを組み合わせることで、RLによる多ステップ推論を自然に強化しているのがポイントです。
▼ 噛み砕き解説
-
強化学習で何をしているの?
→ 「答えが正しいか?」「出力がちゃんとした形式か?」などを報酬にして、モデルが上手に考えるようにトレーニング。 - メリット: 「人間による解答例をたくさん与えなくても」、モデル自身が自力で試行錯誤して成長できる。
3.2 Distillationで小規模モデルへ継承
【詳細・専門的な解説】
DeepSeek-R1のもう一つの大きな貢献は、蒸留(Distillation)によるモデルの軽量化です。具体的には、
- 巨大モデル(DeepSeek-R1) から大量の推論サンプル(Chain-of-Thoughtや回答など)を生成。
- 小規模モデル(QwenやLlamaなど) をこの生成データで学習。
- 小さいモデルでも大きなモデルに近い推論能力を獲得可能。
この蒸留手法では、推論力を要する問題(数学・プログラミングなど)を重点的に含むデータを使うため、小規模モデルでも多段階推論がある程度再現されます。
▼ 噛み砕き解説
-
蒸留って何?
→ 大きなモデルが出した解答や途中経過を「先生のノート」として、小さいモデルに教えてあげるイメージ。 - 結果: 普通なら大きな計算リソースが必要なモデルの知識を、コンパクトなモデルでもある程度再現できる。
4. 実験と評価
4.1 数学・コーディングタスクでの性能
【詳細・専門的な解説】
論文では、主に以下のベンチマークが用いられています。
- AIME 2024: 数学系の難問セット。
- MMLU: 多領域の知識を問う100科目クイズ。
- Codeforces・LiveCodeBench: プログラミング問題の正答率・実行結果評価。
DeepSeek-R1は、上記のベンチマークで、既存のオープンソースモデルを大きく上回る成績を示しました。
特に、AIME 2024 では Pass@1が 79.8% に達し、さらに多数決(majority voting)をすると 86%超を叩き出しています。
これは既存の多くのモデルが 50~60% 台に留まる中で、画期的な数字です。
▼ 噛み砕き解説
- 数学テスト(AIME) で、DeepSeek-R1はほぼ8割以上も正解!
- プログラミング問題(Codeforces) でも、人間の上位数%並みのスコアを達成している。
- 他のモデルとの比較: 普通のLLMが苦手な「手順が多い問題」や「論理が複雑な問題」に強いのが特徴。
4.2 小規模モデルへの蒸留効果
【詳細・専門的な解説】
Distillation によって生成されたモデル(例: DeepSeek-R1-Distill-Qwen-7Bなど)は、パラメータ数を大幅に削減しながらも、
- AIME や MMLU などのテストで、大型モデルと比較して 5~10% 程度のスコア差に収まる。
- ランタイムやメモリ使用量ははるかに少ない。
したがって、環境制約がある現場(オンプレミスやエッジデバイスでの推論など)でも、高度な推論能力を活かしやすい点がメリットです。
▼ 噛み砕き解説
-
蒸留版は軽い!
→ たとえばパソコンや小規模サーバでも動かせるサイズに。 -
でも結構頭がいい!
→ 大きいモデルと比べて大差ないレベルの正答率を出せる。
4.3 学習曲線の可視化
学習中におけるAIME正答率の推移は、以下のように段階的に向上していることが確認できます。
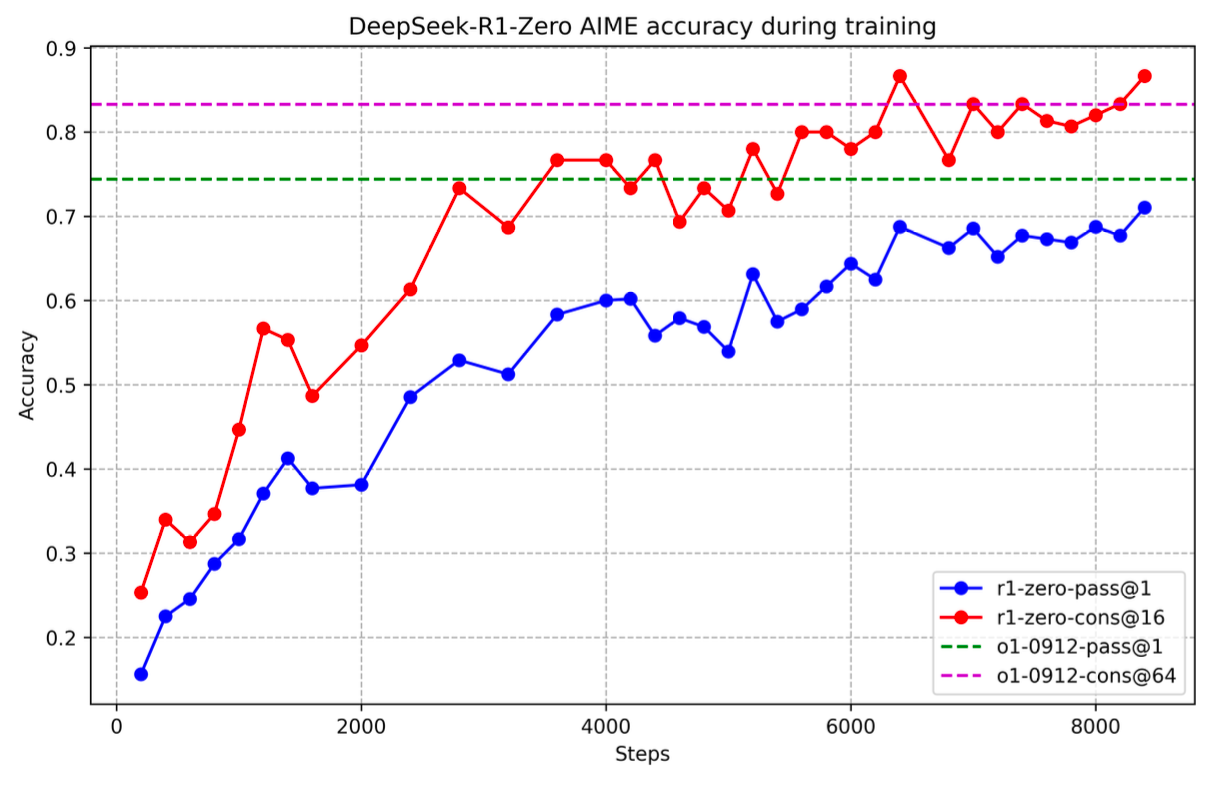
また、応答の平均長(トークン数)についても、学習ステップの増加とともに明確に伸びている様子がうかがえます。

このように、学習が進むにつれてChain-of-Thoughtの長さ・内容が洗練され、正答率が向上していく傾向が見て取れます。
5. 考察
5.1 Distillation vs. 直接RL
【詳細・専門的な解説】
論文中では、小規模モデルに直接強化学習を適用するよりも、まず大規模モデルでRL学習 → その後に蒸留 のほうが効率が良いと報告されています。
小規模モデルが直接RLを行う場合、
- 報酬信号が十分に学習を導けず、探索がうまく進まない
- パラメータが少ないぶん表現力が限られる
などの理由により、大きな性能向上が得られないケースが多いとのことです。
▼ 噛み砕き解説
-
どっちがいいの?
→ 小さいモデルにいきなり強化学習は大変。まず大きいモデルにやらせて、成功例(模範解答)をいっぱい作って、それを小さいモデルに教えるほうが確実。
5.2 失敗事例: PRMやMCTS
【詳細・専門的な解説】
DeepSeek-R1の開発過程で検討されたものの、上手くいかなかったアプローチとして、以下が挙げられています。
-
Process Reward Model(PRM)
- 推論途中に細かく報酬を与える手法。
- 報酬設計が複雑で、かえって「報酬ハック」を招きやすかった。
-
Monte Carlo Tree Search(MCTS)
- 囲碁などのゲームで有用だが、言語トークン生成では探索空間が膨大。
- Valueモデルの学習が難しく、性能向上に繋がらなかった。
▼ 噛み砕き解説
- 「小刻みに報酬を与える」とか「木構造探索」 みたいなアイデアは試したけれど、言語モデルではうまくいかなかった。
- 原因: 言葉を生成するタスクは、ゲームのように状態がはっきりしない部分が多く、報酬設計も難しかった。
6. 結論と今後の展望
6.1 総括
DeepSeek-R1は、
- 強化学習のみでも大幅な推論力向上を実現する(DeepSeek-R1-Zero)。
- 少量の追加データ(SFT)や報酬設計で言語混在や可読性の問題を解決(DeepSeek-R1)。
- 蒸留によって小規模モデルへも高い推論能力を継承できる。
という点で、大規模言語モデルの新たな可能性を切り拓きました。
論文でも示されているように、数学・プログラミング問わず、多岐にわたるベンチマークで既存オープンソースモデルより優れた性能を発揮しています。
6.2 今後の研究・応用
-
マルチモーダル・多言語対応
- DeepSeek-R1のアーキテクチャを拡張し、画像や音声など他のモードもRLで最適化できるか。
- 言語混在報酬をさらに発展させて、より多くの言語を扱う。
-
プロンプトエンジニアリング
- RLによる自己学習を促進するため、プロンプトの与え方やテンプレート選択が鍵となる。
-
ソフトウェアエンジニアリングへの応用
- 大規模なコードベースへの対応や、エラー修正タスクに特化した報酬設計など、発展の余地が大きい。
7. まとめ
本記事では、DeepSeek-R1 の構造とトレーニング手法、実験結果、そして今後の発展可能性について解説してきました。
大規模言語モデルの「思考力」を高めるうえで、強化学習が有効であること、さらにその成果を小規模モデルへも蒸留できる実証は、今後のLLM研究において大きな意味を持ちます。
- DeepSeek-R1-Zero: RLだけで推論能力を高めたベースモデル
- DeepSeek-R1: 可読性と一貫性を大幅に改善
- Distillation: 小さいモデルへの知識継承を実現し、実用性アップ
これらの革新的アプローチは、幅広いタスクや環境で高度な推論を行う未来のLLM像に近づくための重要なステップといえるでしょう。
参考資料
-
DeepSeek-R1: Reinforcement Learning for Advanced Reasoning
GitHub: DeepSeek-R1 -
その他関連研究
- Chain-of-Thought: 推論過程の可視化手法
- PPO / RLHF: OpenAIなどが採用する学習手法
- 多言語LLM: XGLMやmT5など
おわりに
以上、DeepSeek-R1 に関する解説をお届けしました。
強化学習がもたらす大規模言語モデルの高い推論力と、その能力を小さなモデルにも引き継ぐ蒸留技術の可能性は、今後のAI研究・実装に大きなインパクトを与えるはずです。
より詳しく知りたい方は、ぜひ論文本体や提供されているオープンソースリソースを参照してみてください。
ご意見・ご質問などがございましたら、ぜひコメント欄でお知らせください!
会社紹介
株式会社 Mosaica
最先端テクノロジーで社会課題を解決し、持続可能な未来を創造する IT カンパニー。
AI ソリューション、クラウド統合、DX 推進、経営コンサルティングなど包括的なサービスでビジネス変革を支援しています。
詳しくは 公式サイト までお気軽にご相談ください。
公式サイト: https://mosaica.co.jp/