はじめに
本記事で紹介するテスト技法は、特定のフレームワークに依存したものではありません。これまでの経験や手法を組み合わせた、完全オリジナルのアプローチです。特殊なプロジェクトで採用した方法ではありますが、結果的に成功したと感じています。
似たようなプロジェクトは存在するかもしれません。しかし、情報にたどり着けないケースも多いため、このノウハウを共有することで、どこかのプロジェクトの役に立てばと思います。
序盤はプロジェクトの概要説明が中心です。テストに関する内容だけをご覧になりたい方はこちら、結論のみを知りたい方はこちらをご参照ください。
プロジェクトの概要
- テーマ: 発達特性検査サービスの新規開発
- 開発期間: 約4年(実装期間 約2年)
-
サービス内容:
質問群(回答時間20分程度)に基づき、検査対象のお子様に合わせた「トリセツ」を作成。困難を抱えるお子様のサポートツールとなるサービス。
サンプルイメージ: サンプル.pdf -
技術スタック:
- フロントエンド: Nuxt.js
- バックエンド: Ruby on Rails
- インフラ: AWS
プロジェクトの性質
-
センシティブな検査結果
検査結果が非常に重要なため、アルゴリズムの変更が頻繁にはできない。 -
膨大なテキスト
結果作成に使用するテキストデータが膨大。
無量大数とは
無量大数は、10の68乗(10^68)を意味します。
以下は、日本の伝統的な数の単位の一部です。
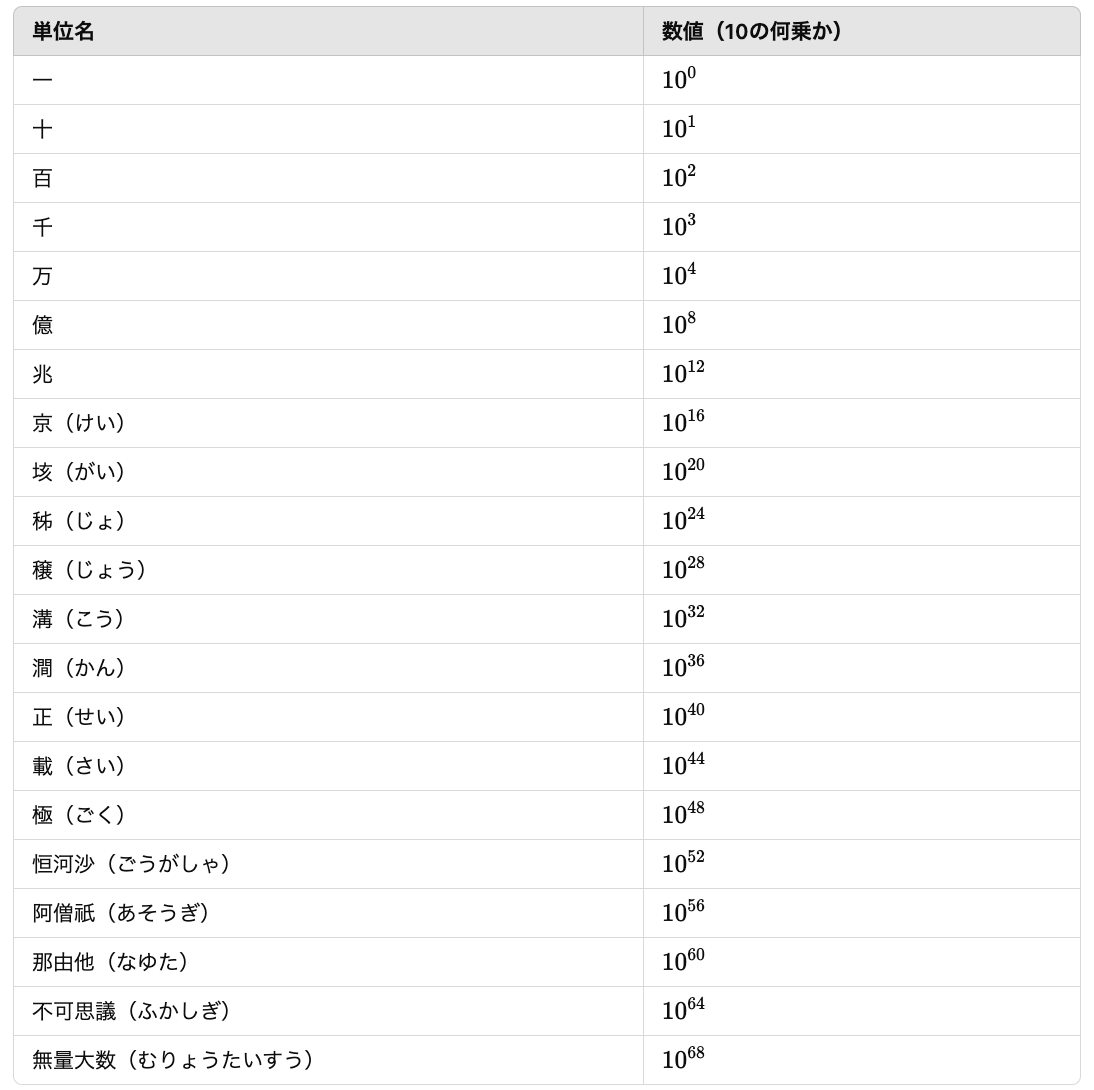
本記事はタイトル詐欺ではありません。このシステムで生成される結果パターンは、計算の結果、無量大数を超えています。
- 出力内容: 対象者の属性に応じた情報を提供し、個別最適化を実現。
- 膨大なパターン: 分岐になる変数が多いため、パターン数が膨大
- 応用可能性: 論理的に組み合わせパターンが多い、成果物間の整合性が求められる開発の検証に応用可能。
図で公開するのは難しいのでロジックは数で例えると約90個で構成されています。

※ 実装がそのままの数にはなっていません。
このロジックから生成される大分類は7分類、小分類は18分類になります。
役割分担
-
研究:
アルゴリズム開発、シミュレーターを用いた閾値調整。 -
コンテンツ:
結果に使用するテキストの作成・監修。 -
エンジニア:
実装、テキストの反映。
単体テスト
-
Rspec:
- フレームワーク外のコードを網羅的にテスト。
- Github Actionsを活用。pushやdevブランチへのマージ時に自動実行。
- ファイル生成とダウンロード機能を用いてカバレッジを確認可能。

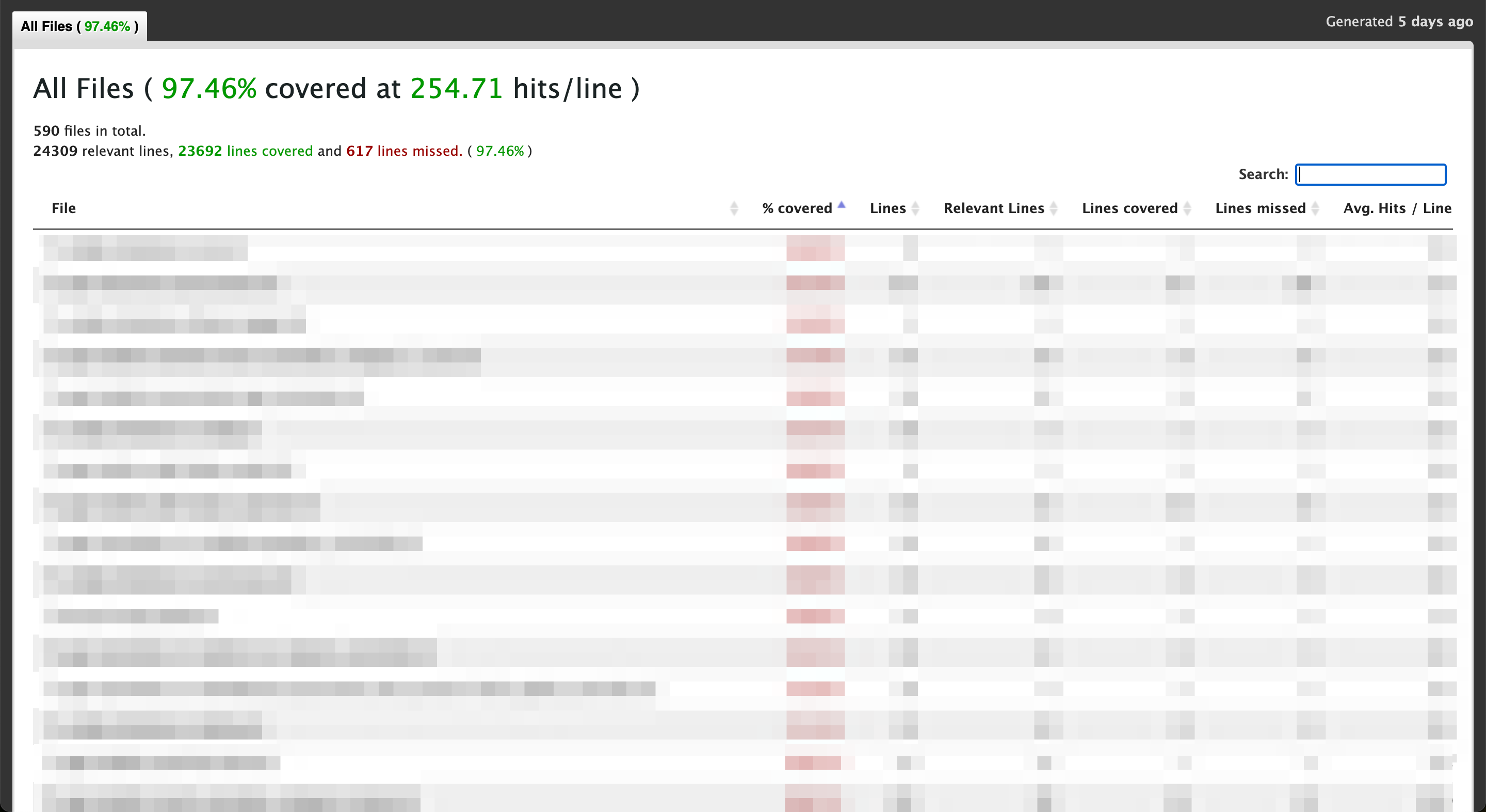
- コードの一部
- Gemfile
group :test do gem 'simplecov', require: false end- Github Actions
- name: Archive coverage artifacts uses: actions/upload-artifact@v4 with: name: coverage path: api/coverage if: always()
- コードの一部
-
入稿データ(マスターデータ):
- seedとバッチ処理でデータ投入。
- 定義書とクエリ結果を比較し、一致確認を自動化。
レコード数は様々ですが、50シートあります。 - 管理シートでバージョンごとの結果も記載。
例:

-
結果データのテスト:
- シミュレーターから生成されたCSVをフルスキャンまたはランダム実行。
アルゴリズム特化のテスト
全体図:
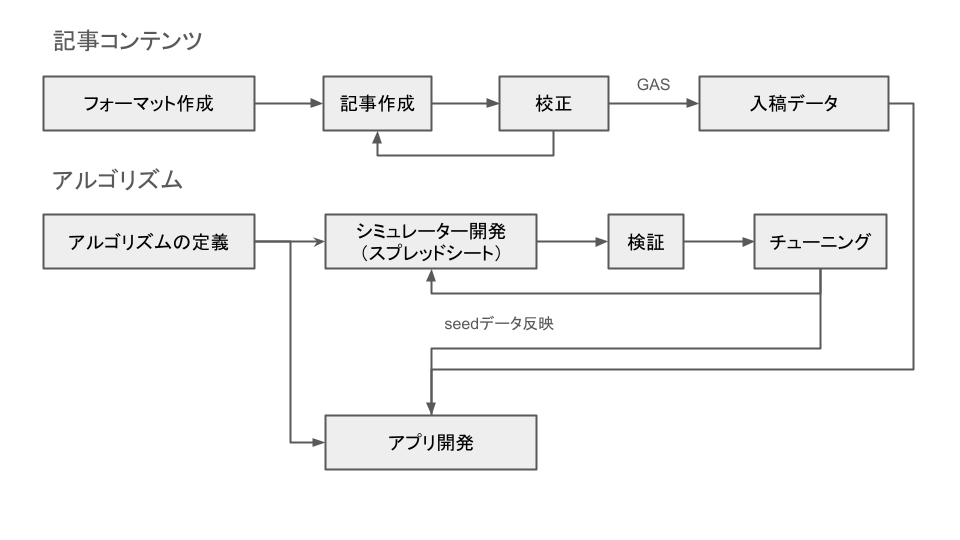
- アルゴリズムの修正時、コンテンツの修正時の動き
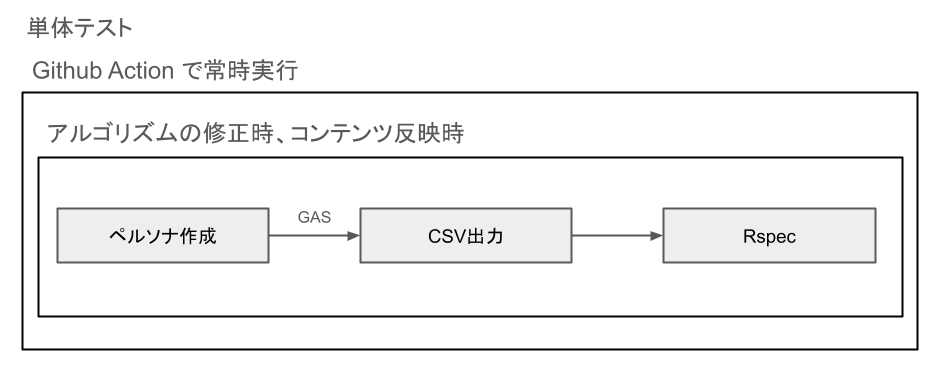
何をもってOKにするか?
- 修正時の確認基準
- シミュレーターの結果とアプリの出力が一致していること。
- コンテンツが正確にアプリとシミュレーターに反映されていること。
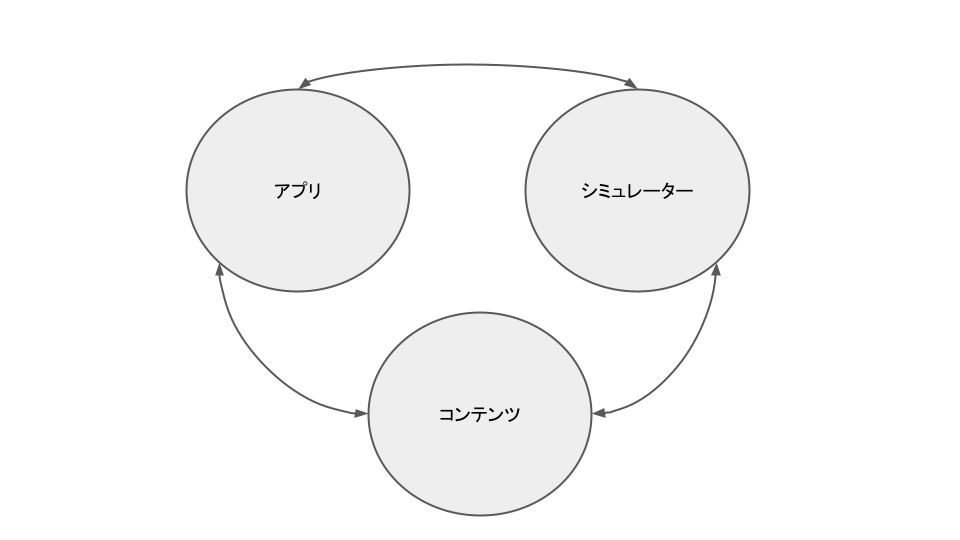
ベータテスト
- 対象: 日本全国から抽選で選ばれた150人(社内・社外問わず)。
-
実施内容: 主要機能のみ搭載したバージョンでの利用テスト。

-
結果反映:
フィードバックを基に調整を実施。調整後、新たなCSVデータを生成し、期待する結果が得られることを確認。

最後に

テストがなぜ大事なのか?
=> 開発者自らの時間を守るため