概要
Power Automate DesktopコグニティブアクションのGoogle「テキスト検出」を使った文章OCRを試しました。
少し前にWinautomationでも試したことはあるのですが、2020年12月Power Automate DesktopがGAされたので改めて手順を確認してみようと思います。
前提
2020年12月の情報になります。
Power Automate Desktop バージョン2.2.20339.22608
Windows10Pro 20H2
注意
Google Cloud Platform(以下GCP)アカウント必須です。
アカウント取得にクレジットカードが必要になります。
無料枠では90日300ドルのクレジットがついています。
https://cloud.google.com/free/
https://cloud.google.com/free/docs/gcp-free-tier
また無料枠終了後もVision APIは1000ユニットまで無料利用可能とのことです。
https://cloud.google.com/vision/pricing/?hl=JA
詳しくは公式ドキュメントを参照
GCPアカウント取得とVision APIの設定、キーの取得についてはGCPドキュメント及びWEB上に記事がたくさんありますのでここでは触れません。
今回作るフロー
Power Automate DesktopでGoogle Cloud Platform vision APIで文章OCRする。
複数画像でも処理できるようにする。
処理の終わった画像とテキストフォルダを別フォルダに移動する。
準備
- Vision APIのAPIキーを取得しておきます。
- デスクトップに任意のフォルダーを2つ作成。(処理前、処理後のフォルダーとしてPAD_GCP_OCRとOCR_Doneにしています)
Power Automate Desktopフロー作成
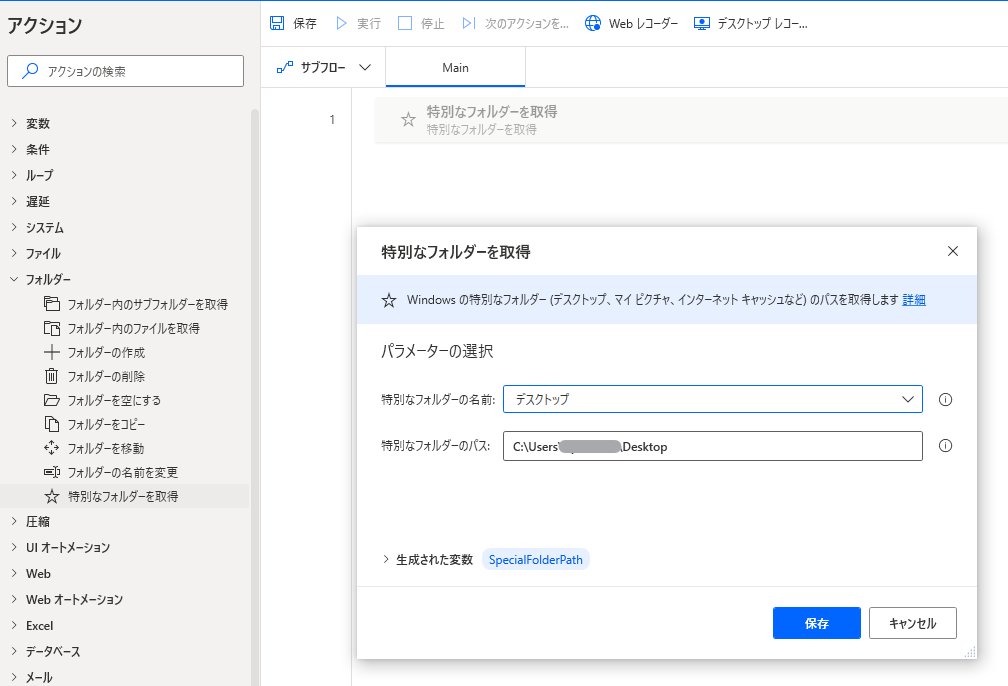
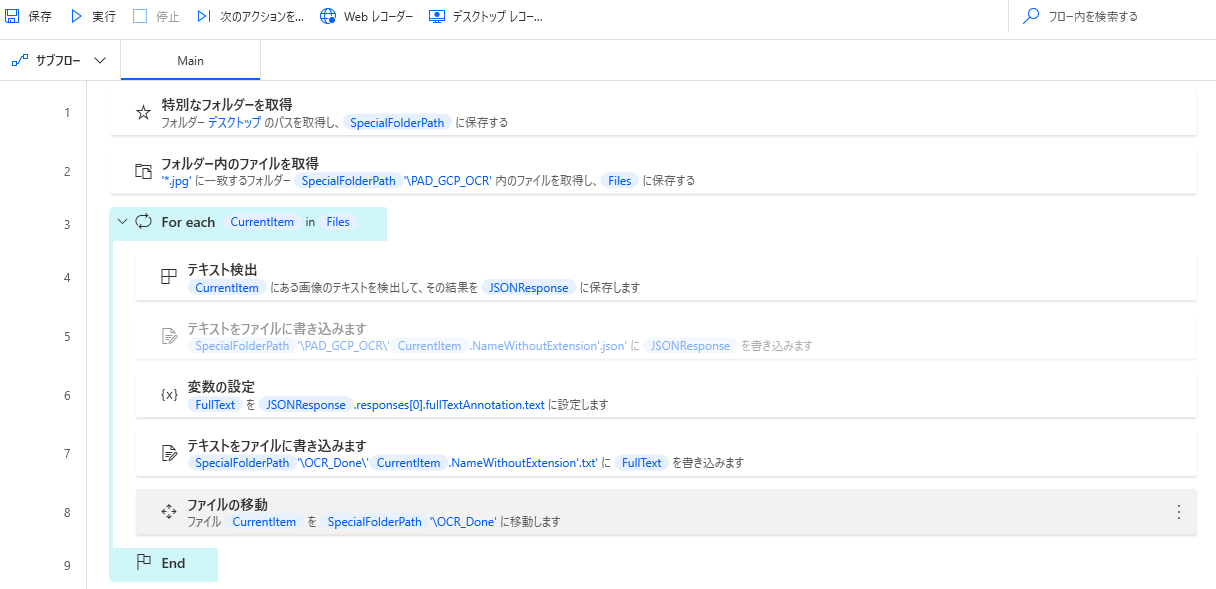
1.「特別なフォルダを取得」アクション
よく使うやつ
デスクトップを指定します。
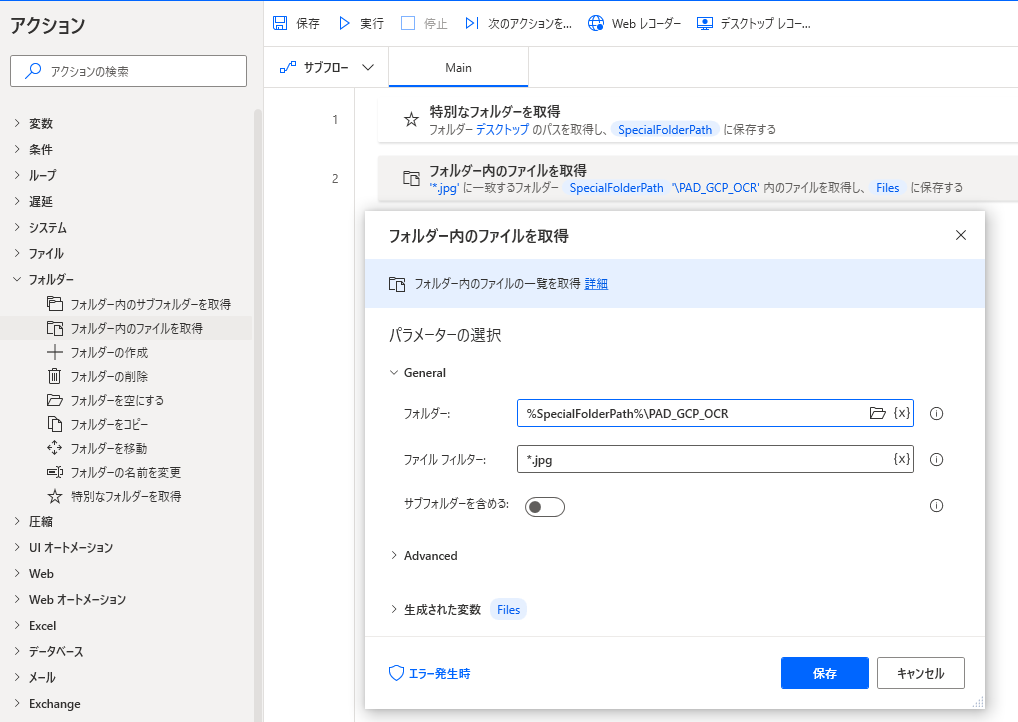
2.「フォルダー内のファイルを取得」アクション
準備した処理前フォルダーの指定
jpgファイルのみパスを取りたいのでフィルターを設定します。
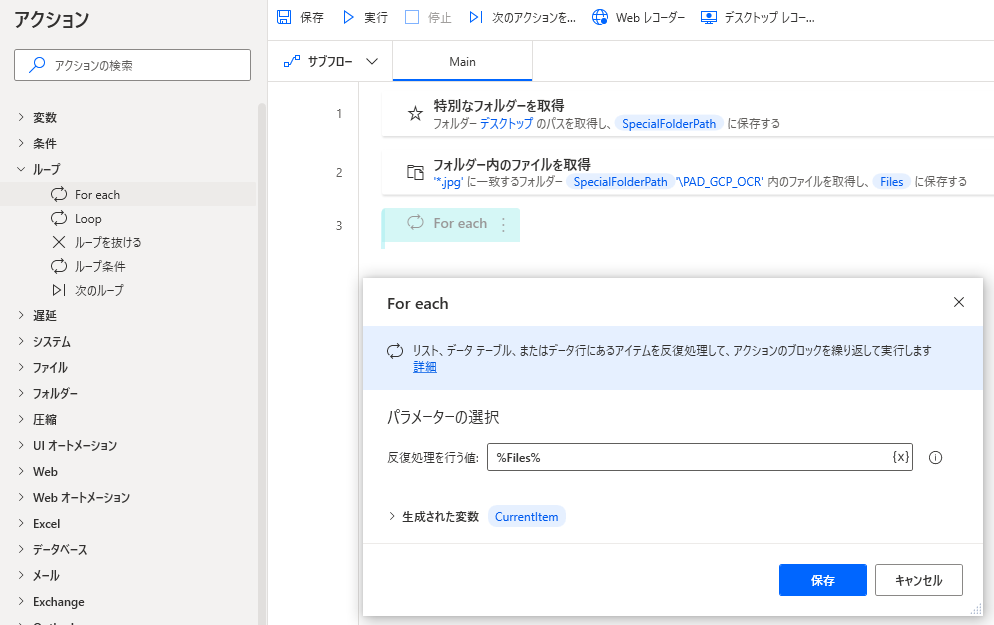
3.「For each」アクション
取得した画像ファイル全てを読み取りしたいのでFor eachを使ってループ処理。
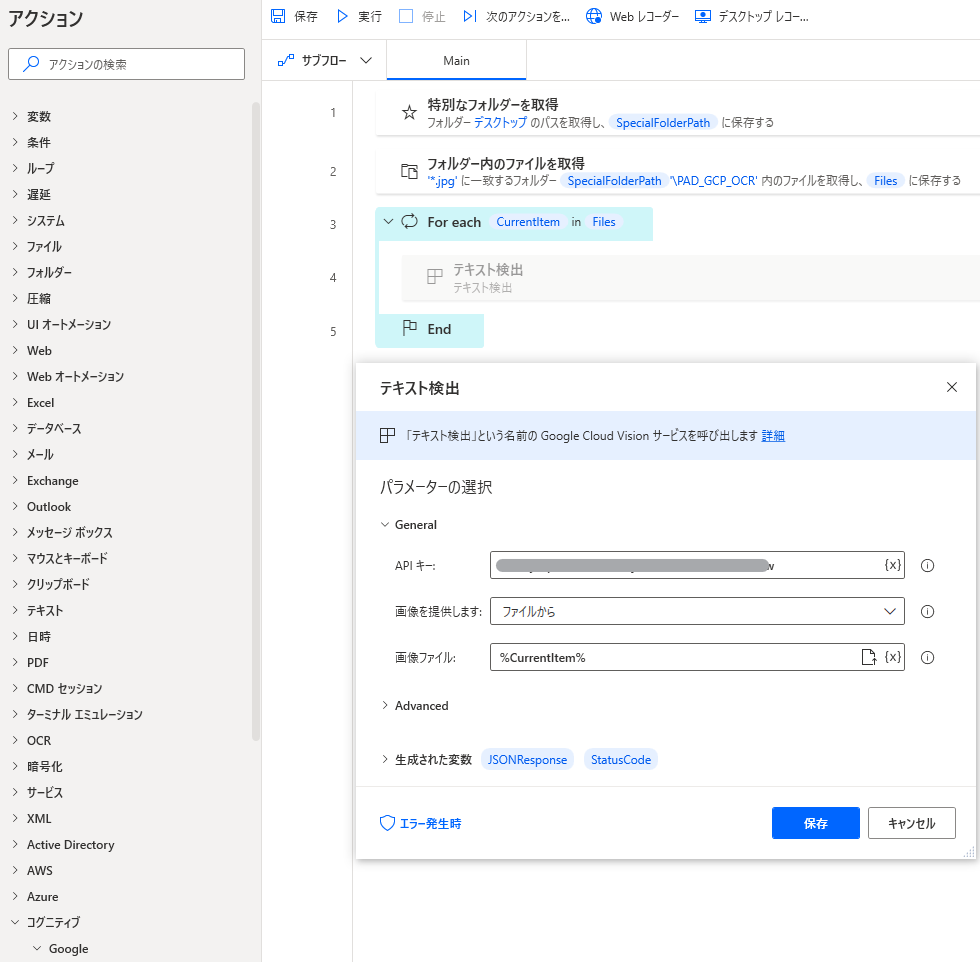
4.「テキスト検出」アクション
コグニティブ>Google>ビジョン>テキスト検出をFor eachとEndの間に入れます。
APIキー = Vision APIで発行したキー
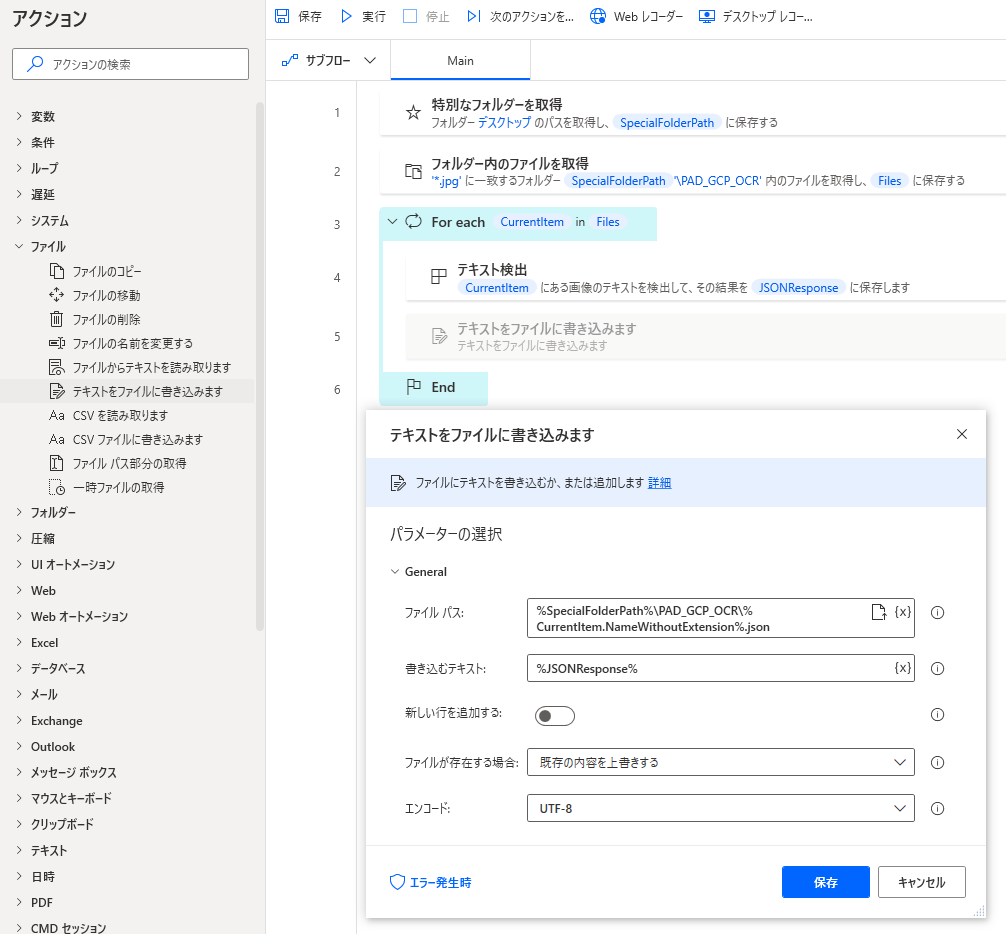
5.「テキストをファイルに書き込みます」アクション
この状態で一度返却されるJSONを確認するために、アクションを追加します。
ファイル名を%CurrentItem.NameWithoutExtension%.jsonとすることで画像と同じファイル名で拡張子だけ変えて保存できます。
6.保存>実行してjsonを取得し、エディターで構造確認
処理前(PAD_GCP_OCR)フォルダーに任意の画像を入れて実行するとJSONが取得できるので。
エディター(notepad++を使っています)で開いてJSONの構造を確認します。
使った画像

notepad++で開いてみると、
7行目のdescriptionとまたは5596行目のtextに読み取りした文章が格納されているのがわかりました。
7行目

5596行目

それぞれ文章までのパスをPower Automate Desktop内で表記すると、
7行目
JSONResponse.responses[0].textAnnotations[0].description
5596行目
JSONResponse.responses[0].fullTextAnnotation.text
となるのがわかりました。
パスの表記方法は格納された値の上位層が [ 大括弧の時は配列なのでインデックスを振ります。
今回はいずれも1番目なのでインデックスは[0]となります。
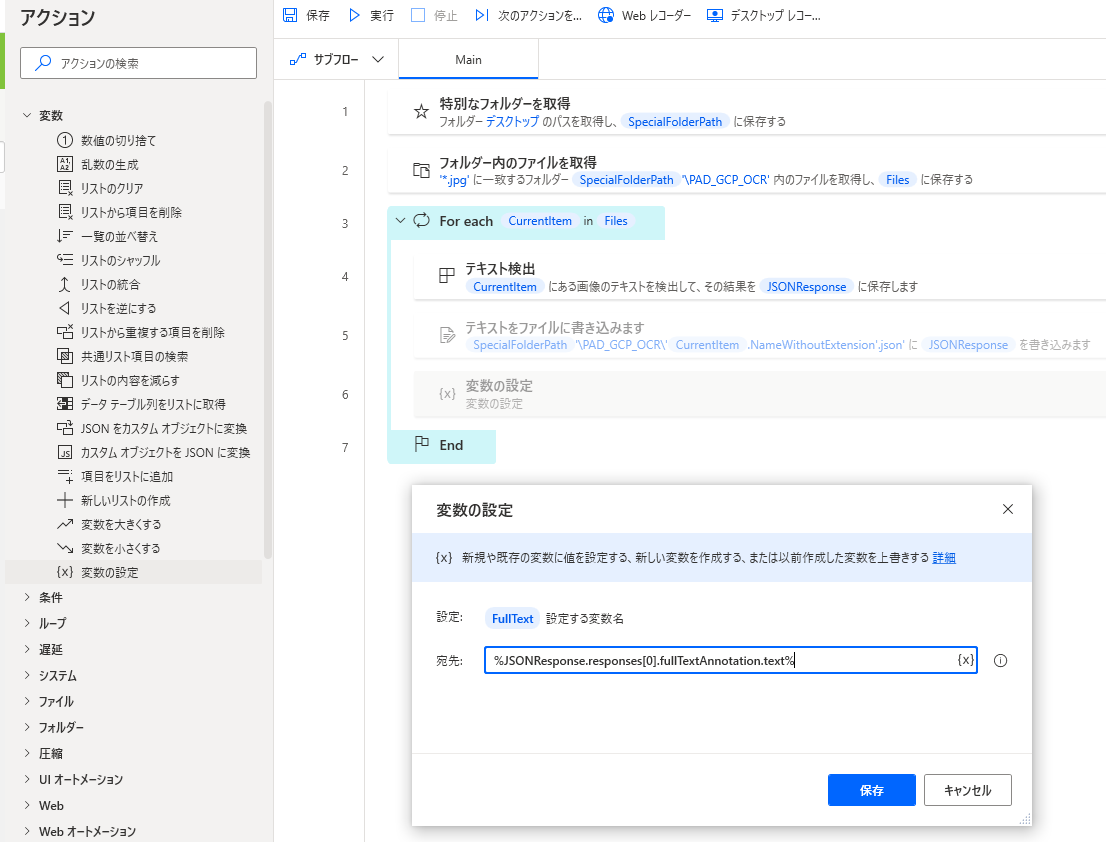
7.「変数の設定」アクション
JSONファイルはとりあえず必要ないので「テキストをファイルに書き込みます」アクションは無効にしておきます。
JSONの文章までのパスを変数にしておきます。
変数にすることで複数を処理できるようになります
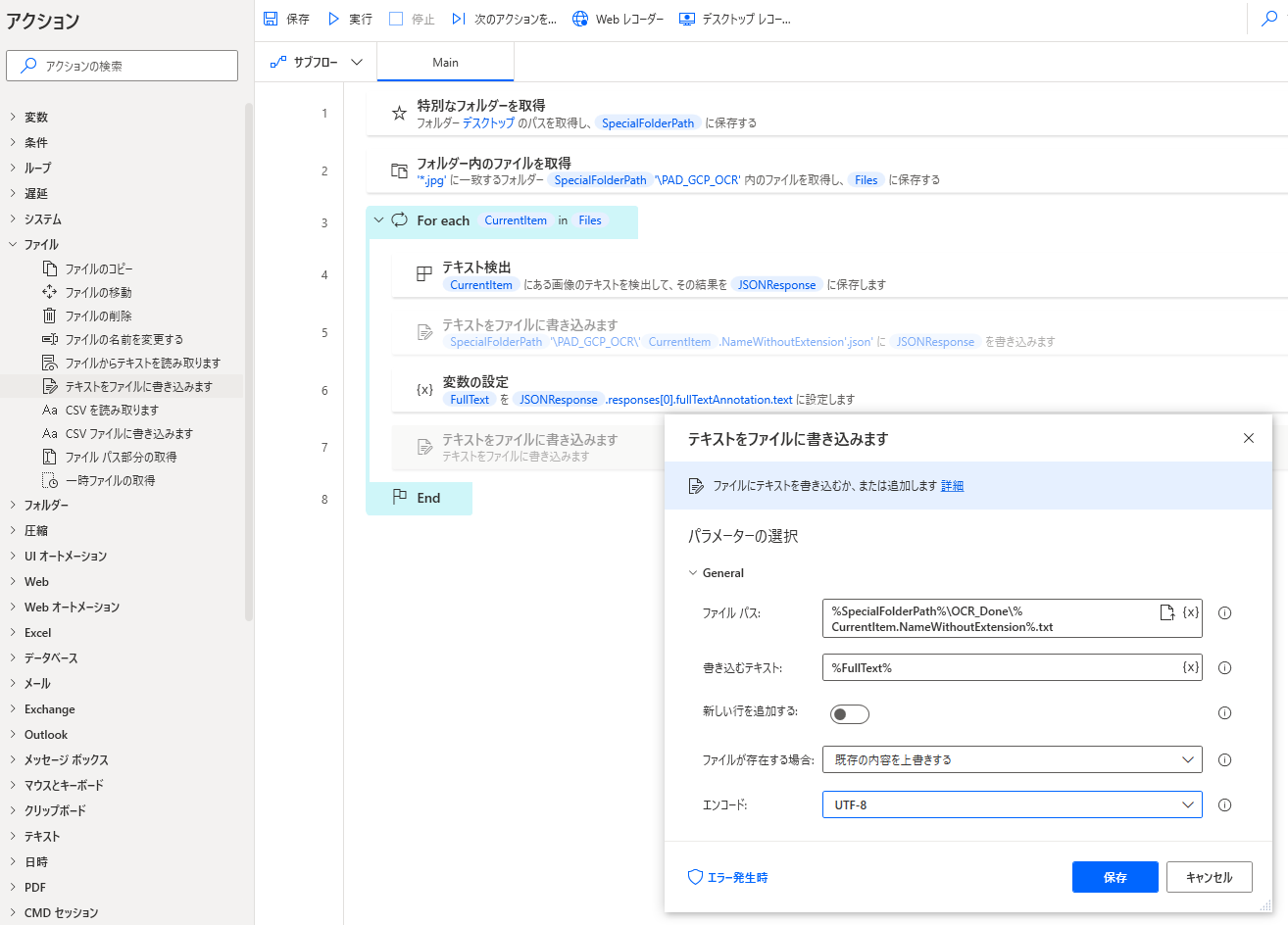
8.「テキストをファイルに書き込みます」アクション
読み取った文章は変数FullTextなので準備した処理後(OCR_Done)フォルダーに保存します
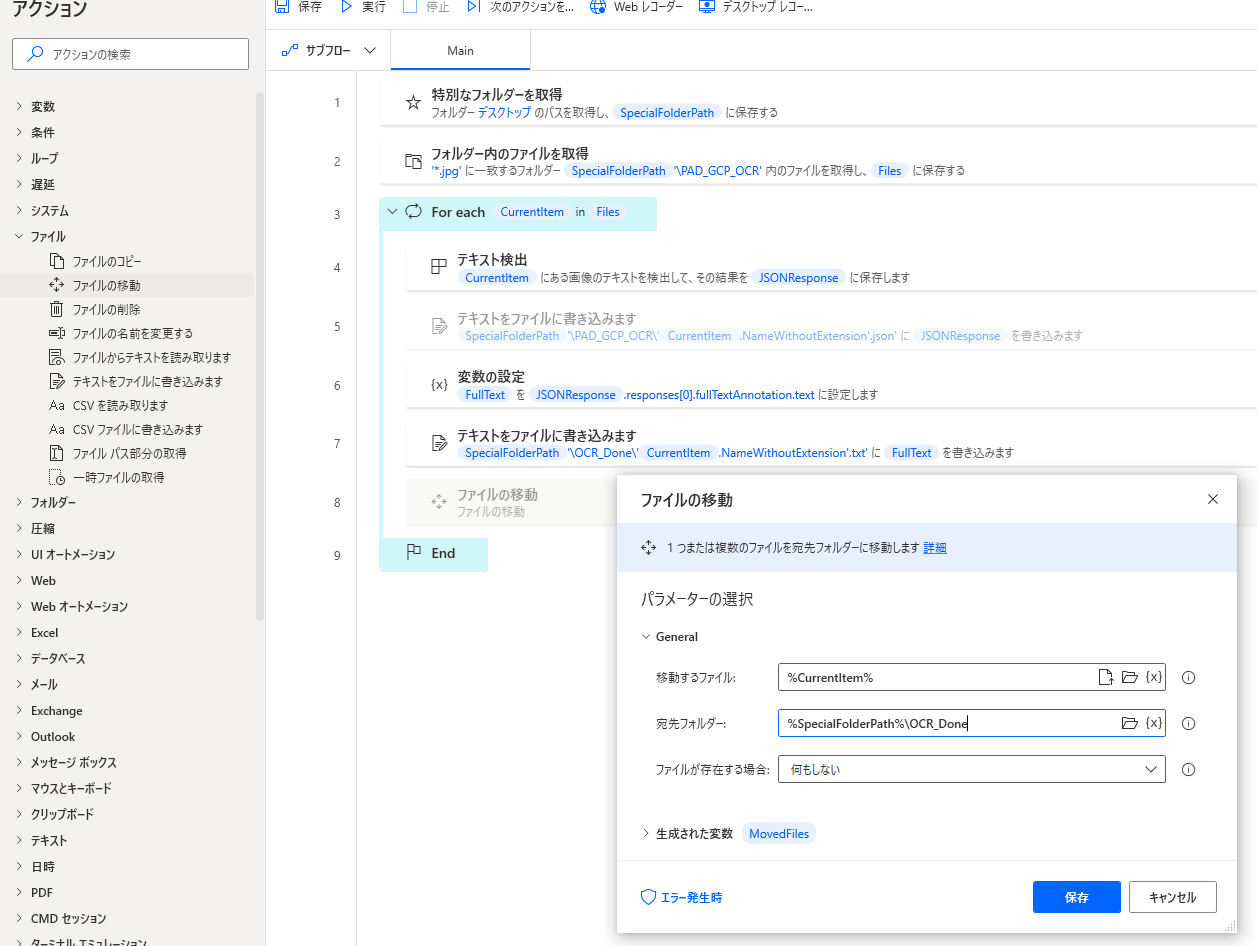
9.「ファイルの移動」アクション
処理が済んだ画像ファイルを処理後(OCR_Done)フォルダーに移動します
Power Automate Desktop完成フロー
まとめ
専門プロダクトのようにはいかないかもしれませんが、Power Automate DesktopとVision APIの組み合わせでかなり精度のよい簡易文章OCRができます。
ただしテキストの座標でコントロールしようと思うと返却されたJSONをゴニョゴニョする必要があります。
Winautomationではトリガーとしてファイルをフォルダーにドラッグドロップすると発動するようにしていました。
素早く実行できるので気に入って使っていました。
Power Automate DesktopでもPower Automateからオンプレミスファイルの操作をトリガーにすることは可能ですが、発動までが遅いので実用的かどうかはそれぞれの判断になると思います。

