Whisper で音声認識 + 単語(word)単位でのアラインメント(単語がどの時刻に出てくるか)までやってくれます!
音声のアラインメントについてのメモ
https://qiita.com/syoyo/items/e43d9d5d564fded3a2b6
インストールは特に難しいものではありません.
中身的には Whisper + word2vec の wrapper という感じでしょうか.
README.md には書かれていないのですが, 日本語対応がされています.
(単語単位でアラインメントしてくれます)
https://github.com/m-bain/whisperX/pull/8
https://github.com/m-bain/whisperX/blob/main/EXAMPLES.md
--language ja 指定すると wav2vec にjonatasgrosman/wav2vec2-large-xlsr-53-japanese を使うようになっています
実行
最高性能でやります. wav2vec2-large-xlsr-53-japanese は model 1.2 GB くらいでした. Whisper large (5 GB くらい)より少ないので, 12 GB のメモリある GPU なら動くと思われます(3090 では動作確認).
$ whisperx --model large-v2 input.wav --language ja

input.wav.word.srt に, ワード(日本語の場合は単語)ごとのアラインメント結果が得られます.
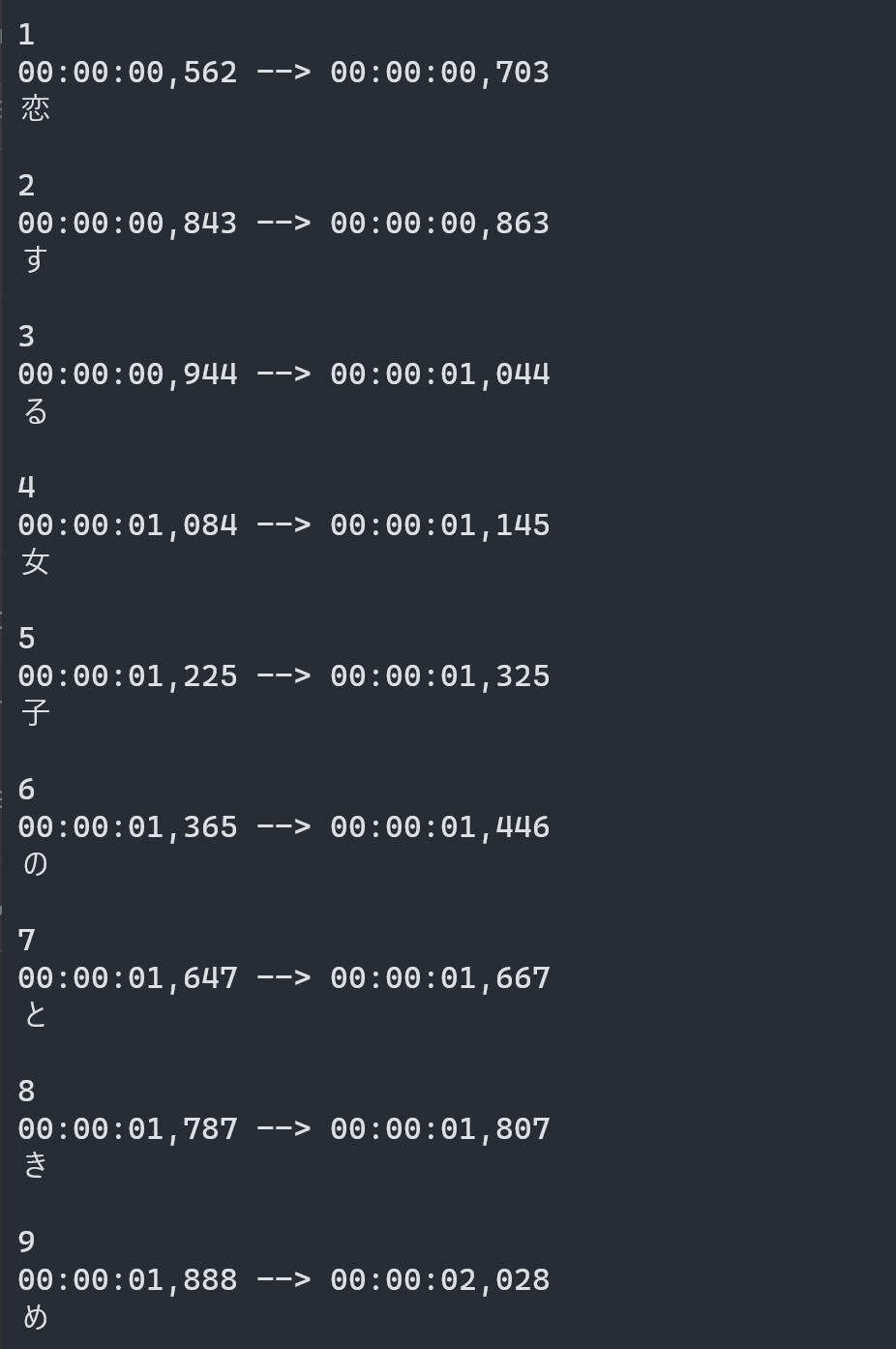
Voiala!
日本語で音素単位とかでアラインしたい...
このあと text-to-speech させたり, 顔認識してそれぞれの発音時点での顔表情を取得したいなどで, 音素(phoneme)単位でのアラインメントがほしいときがあります.
音素とか取り出したい場合はここから mecab か openjtalk あたりで変換するのがよいでしょうか(文節も解析して無声音とかも扱えたりするじゃろか?)
tdmelodic と合わせてアクセント推定するのもできそうです!
そのうち transformer あたりで音声あたえたら音素やアクセント推定など一式ぺろっと推定してくれるモデルがでてきそうですネ.