はじめに
Splunkでは機械学習(Machine Learning Toolkit、以降、MLTK)を用いてデータ分析が可能です。
本記事ではMLTKを使ってTelecom(電気通信事業者)顧客の解約予測モデルを作成してみます。
環境
- Splunk Enterprise or Cloud
- MLTK
- [Python for Sceintific Computing for 各OS] (https://splunkbase.splunk.com/apps/#/search/Python%20for%20Scientific%20Computing)
MTLK
Splunk MLTKでは様々な機械学習機能を使用できます。
中身はScikit-learnやPandas、SchiPyなどを使用しておりますが、それらに対してUIが提供されておりノンコーディングで機械学習を行うことができます。
大まかに以下カテゴリがあります。
- Predict Fields:値の予測
- Detect Outliers:異常検出
- Forecast Time Series:将来予測
- Cluster Events:イベントのクラスタ化
今回は「とある顧客は解約するか」を予測したいのでPrecit Fieldsを使用します。
使用データ
KaggleのTelco Customer Churnをお借りします。
予測してみる
ファイルのアップロード
ダウンロードしたファイルをルックアップファイルとしてアップロードします。
※本番では取り込みデータに対して予測します
1.設定 > ルックアップ
2.ルックアップテーブルファイル」の [+ 新規追加] をクリック
3.ファイルを指定し、宛先ファイル名に同じファイル名を記入して保存

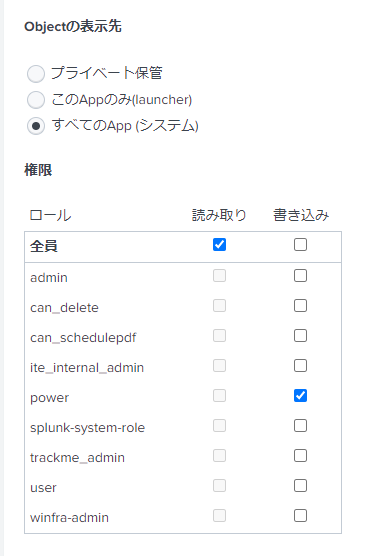
4.MLTKで使用可能にするため「共有中」の [権限] をクリック

5.「すべてのApp (システム)」を選択し、読み取りを全員にチェック、書き込みはとりあえず「power」にして保存
6.設定 > ルックアップに戻り、「ルックアップ定義」の [+ 新規追加] をクリック
7.Nameにファイル名を記入、ルックアップファイルでアップロードしたファイルを選択して保存

8.4、5と同じ操作で権限を付与
9.Searchで念のため確認しておきましょう
| inputlookup WA_Fn-UseC_-Telco-Customer-Churn.csv
このように顧客の情報と解約有無(Churn列)が含まれています。このデータを用いて、どのような顧客がChurnするかを予測できるようにしたいと思います。
Churn,Contract,Dependents,DeviceProtection,InternetService,MonthlyCharges,MultipleLines,OnlineBackup,OnlineSecurity,PaperlessBilling,Partner,PaymentMethod,PhoneService,SeniorCitizen,StreamingMovies,StreamingTV,TechSupport,TotalCharges,customerID,gender,tenure
No,"Month-to-month",No,No,DSL,"29.85","No phone service",Yes,No,Yes,Yes,"Electronic check",No,0,No,No,No,"29.85","7590-VHVEG",Female,1
No,"One year",No,Yes,DSL,"56.95",No,No,Yes,No,No,"Mailed check",Yes,0,No,No,No,"1889.5","5575-GNVDE",Male,34
Yes,"Month-to-month",No,No,DSL,"53.85",No,Yes,Yes,Yes,No,"Mailed check",Yes,0,No,No,No,"108.15","3668-QPYBK",Male,2
MLTKで予測
1.AppからMLTKを開きます。そうするとこんな画面が表示されます。
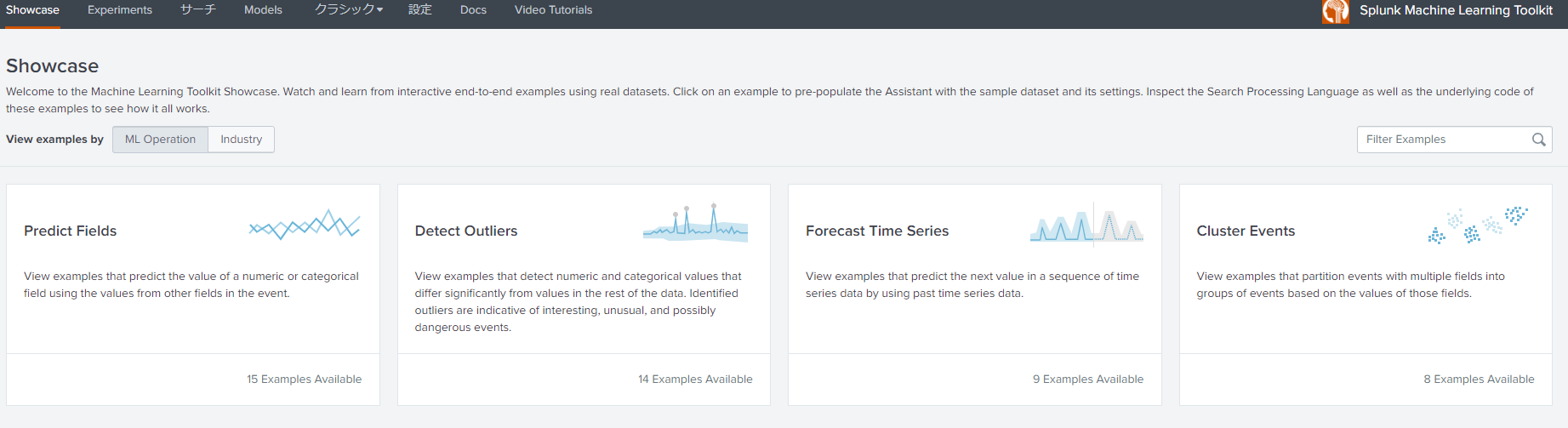
最初のタブのShowcaseでは、色々なデモデータと予測例を見ることができます。左上ぐらいの「View example by」でIndustryを選べば業界別のデモに切り替えられます。
ここから気になるものがあればデモを眺めるだけでもだいたい理解できると思います。
※ここまで書いて気づいたのですが、Predict Fields > Predict Categorical FieldsにChurnのデモがありました。。。これでいいやんと思いましたが見なかったことにして進めます。
2.モデルを作成するにはメニューのExperimentsをクリックします。
そうすると色々な予測タイプが表示されますので「Predict Categorical Fields」をクリックして [Create New Experiment] をクリックします。

Titleを適当につけてCreate。
3.諸々設定します。
・Enter a searchで先ほどアップロードしたファイルをルックアップするようにします。
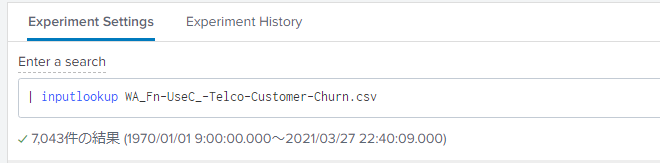
| inputlookup WA_Fn-UseC_-Telco-Customer-Churn.csv
・Reprocessing Stepsでは色々な前処理が行えます。大きい数値の正規化(StandardScaler)とかフィールドが多い場合にいい感じに減らす(KernelPCA)とか。この辺りは予測精度を高めるために使いますので最初はとりあえず無しでも大丈夫です。
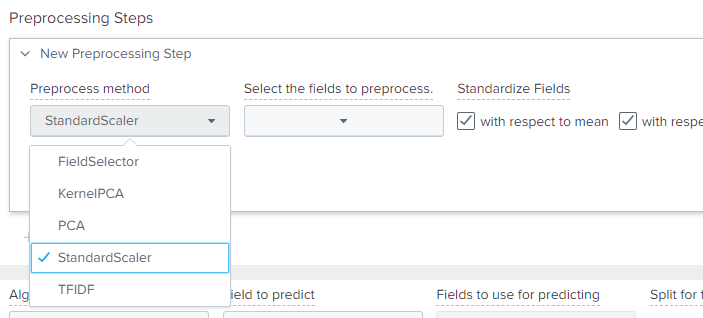
・Algorithmでは予測のためのアルゴリズムを選択します。アルゴリズムによって得意不得意なデータがありますので、それぞれ試してみて、最も予測が高いものを採用します。

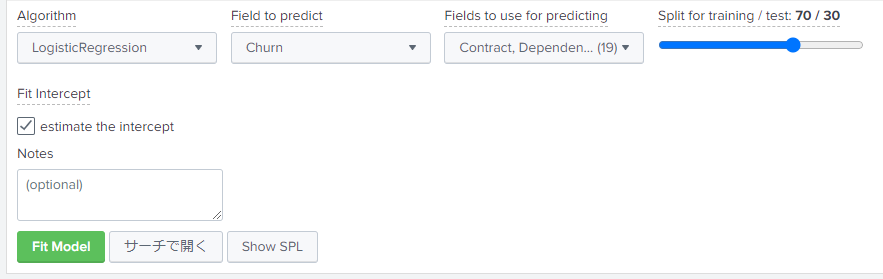
とりあえずデフォルトの「LogisticRegression(ロジスティック回帰)」で試します。
「Field to predict」は「Churn」、「Fields to use for predicting」はCustomer ID以外全部選択します。
※どのフィールドを予測に使うかはデータによって違います。今回はCustomer ID以外の情報は使えそうだったのでとりあえず試します。もしかしたら使わない方がいいフィールドがあったりするかもですので、その辺りは精度を高めるために微調整します。
「Split for training / test」はデータのトレーニングとテストの比率です。70 / 30のままでよいでしょう。
[Fit Model]をクリックすれば予測が始まります。
4.しばらくしたら下の方に結果が表示されます。

左側のPrecisionやRecallなどは予測率です。各意味については【入門者向け】機械学習の分類問題評価指標解説(正解率・適合率・再現率など)が分かりやすかったです。
右側が予測に対する結果です。Churn = Noと予測し実際Noだった割合は74.4%、Yesと予測し実際Yesだった割合は79%でした。なかなかの制度ではないでしょうか。
5.他のアルゴリズムでも試してみます。
総合的な予測精度を示すF値で比較すると以下の通りでした。
- LogisticRegression:0.77
- SVM:0.75
- RandomForestClassier:0.73
- GaussianNB:0.72
- BernouliNB:0.73
- DecisionTreeClassifier:0.73
LogisticRegressionが良い成績なので、こちらを採用したいと思います。
ちなみにアルゴリズムによって保守的(Noの予測精度が高い)だったり攻めていたり(Yesの予測精度が高い)、結果が分かれており興味深いです。
6.右上の [保存] ボタンをクリックして作成したモデルを保存します。
7.Prediction Resultの [Show SPL] をクリックします。
すると、このモデルを使用するためのSPLが出力されます。
データに対してapplyを実行するだけですね。これでpredicted(Churn)列に予測値が表示されます。
| inputlookup WA_Fn-UseC_-Telco-Customer-Churn.csv
| apply "_exp_draft_d597e333813746128a5d08526fef700e"
| table "Churn", "predicted(Churn)", "Contract" "Dependents" "DeviceProtection" "InternetService" "MonthlyCharges" "MultipleLines" "OnlineBackup" "OnlineSecurity" "PaperlessBilling" "Partner" "PaymentMethod" "PhoneService" "SeniorCitizen" "StreamingMovies" "StreamingTV" "TechSupport" "TotalCharges" "gender" "tenure"
今回は静的なデータを使用しましたが、継続的にデータを取り込むようにすればスケジュールレポートを作ることで定期的に解約しそうなユーザを予測してくれるようになります。
そして例えば対象ユーザに対して重点フォローを行うなどのアクションにつなげられます。
8.ちなみに画面で色々やっていたモデル作成もSPLでできます。
Algorithm選択あたりの [Show SPL] をクリックすると以下のようなSPLが出力されます。
モデルはintoの後に指定したモデル名に保存されるので、これをapplyで呼び出すという仕組みです。
これも定期的にスケジュールで動かせばモデルを最新にできます。
| inputlookup WA_Fn-UseC_-Telco-Customer-Churn.csv
| fit LogisticRegression fit_intercept=true "Churn" from "Contract" "Dependents" "DeviceProtection" "InternetService" "MonthlyCharges" "MultipleLines" "OnlineBackup" "OnlineSecurity" "PaperlessBilling" "Partner" "PaymentMethod" "PhoneService" "SeniorCitizen" "StreamingMovies" "StreamingTV" "TechSupport" "TotalCharges" "gender" "tenure" into "_exp_draft_d597e333813746128a5d08526fef700e"
まとめ
SplunkのMLTKを使って解約予測を試してみました。
SplunkはITデータがメインのような印象がありますがビジネス系も分析できますね。
今回は解約の予測でしたがユーザ属性のデータを元にクラスタ化してヘビーユーザの特徴なんかを調査もできそうです。