ご注意
以下の話はあくまで仮説です。実証できたわけではありません。推測が含まれていますのでご注意ください。
発端
自作のEasy-ISLispに並列機能をもたせるということをこの数ヶ月やってきました。スレッドセーフやコンカレントGCの問題を解決し、インタプリタ及びコンパイラにおいて並列動作をするようになりました。しかし、ラズパイ400のARMだと並列で性能を発揮するのに対し、インテルのicoreやAMDのRyzenでは並列処理の方が遅くなる場合があります。この理由をずっと考えていました。ようやく理解に達したような気がしましたので記録に留めることとしました。
並列で遅くなる場合
Easy-ISLispはインタプリタとコンパイラを持っています。さらにコンパイラには型推論を応用した最適化により高速コンパクトなコードを生成する機能があります。インテルとAMDにおいてはそれぞれにおいて並列の性能が異なるのです。
○インタプリタ ☓ 並列の方が遅くなる
○コンパイラ ☓ 並列の方が遅くなる
○最適化コンパイル ○ 並列の方が速くなる
テストに使用したコードはベンチマークでよく使われる再帰計算によるフィボナッチ数です。
L3キャッシュ
調べていますとラズパイに搭載されているARMのCPUにはL1,L2キャッシュのみがありL3キャッシュはないことがわかりました。一方でインテル、AMDのCPUにはL3キャッシュがあり、それは近年大容量化する傾向にあります。
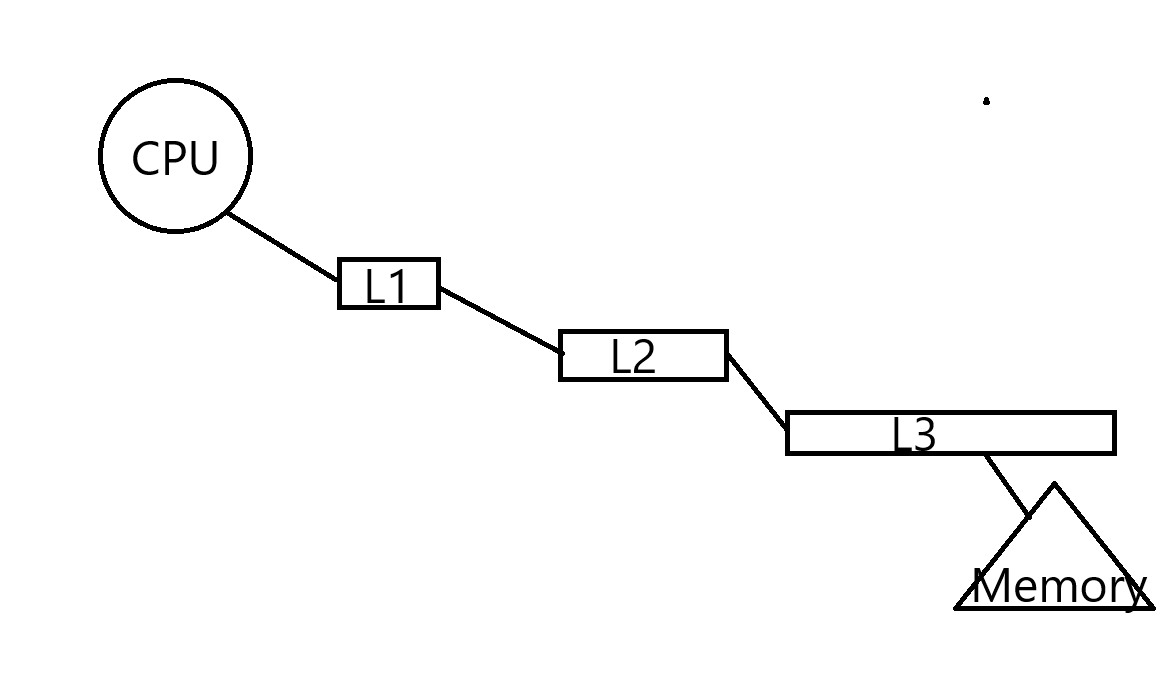
L1キャッシュはCPUからもっとも近く、速度も高速です。L1キャッシュで見つからない場合には2番めに高速なL2キャッシュを探しに行きます。さらになければL3キャッシュを探し、最終的に見つからなければメモリを探しにいきます。近年のCPUはこのキャッシュを高速化、大容量化することにより高速化を図っているものと思います。
共有キャッシュのマルチコアでの問題点
L1、L2キャッシュは各コアが独立に保有します。しかしL3キャッシュは各コアで共有で保有します。L3キャッシュは禁煙、大容量化してお普及型のRyzenでも16MBあります。シングルコアの場合にはこれによりヒット率が高くなり高速化が期待されます。しかし、メモリ共有で各コアが並列で動作すると状況は変わってきます。各コアがみているメモリの範囲が異なるからです。L3キャッシュで見つからなければメモリから再ロードすることになります。また、共通のメモリからロードしますので競合の問題が起きやすくなります。Pthreadライブラリを利用したメモリ共有型の並列ではこれが問題となるはずです。
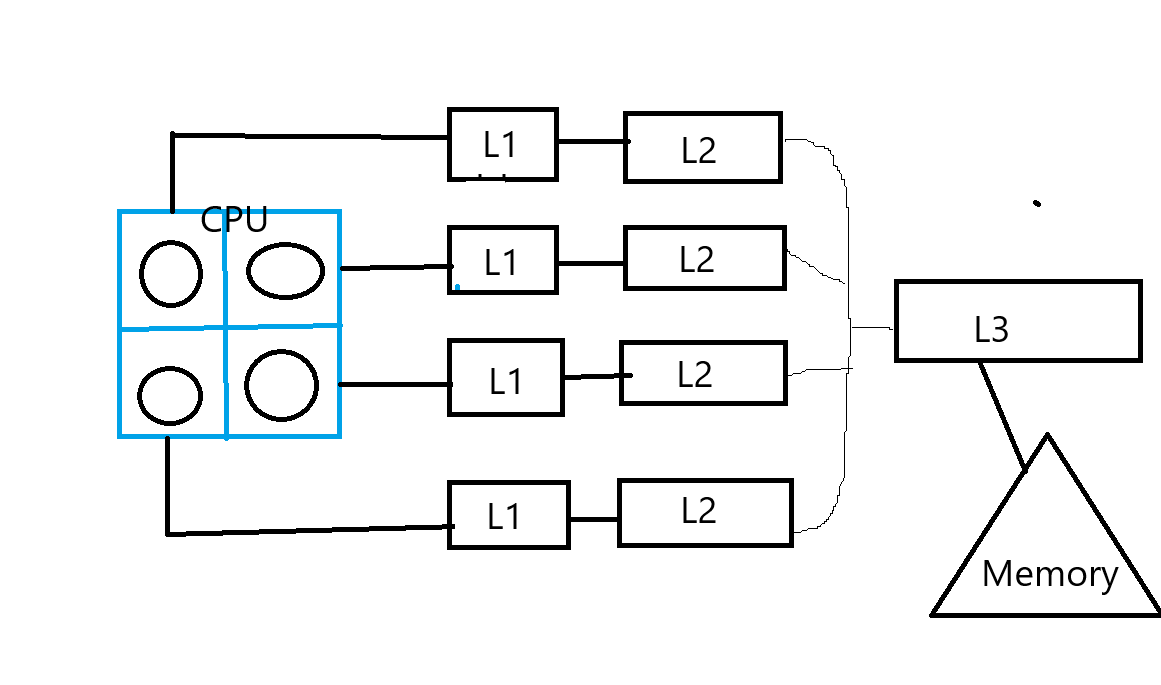
一方、マルチプロセスでは影響はありませんでした。下の図は2つのプロセスで独立してフィボナッチ数を計算している様子です。他のコアが計算中であっても速度には影響を受けていません。マルチプロセスの場合にはメモリ空間が独立しておりキャッシュの更新の際の競合の問題が起きにくいです。
今のところの結論
Easy-ISLispの並列機能はPthreadライブラリ(POSIX)を利用したマルチスレッドによるマルチコア並列です。これをマルチプロセス方式にすれば並列の性能向上が見込まれる一方でLispのもつ大域変数のアクセスを実装するには複雑なことをしないといけません。プログラムも全プロセスで共有する仕組みが必要になります。
いずれインテルもAMDもこの並列の問題を解決するに違いない、とのんびり構えてその時を待つことにしました。
私はCPUの詳細にういて専門知識を有しません。上述の仮設についてのご意見をいただければ幸いです。コメント欄にてご教示ください。よろしくお願いします。