はじめに
平成28年4月、ISLispのことを知りました。それまで名前だけは知っていたものの、その詳細は知りませんでした。湯浅先生など日本人研究者の方々が関わっているということから興味がわき、規格書を読んでみることにしました。読み進めるうちに、ISLispはコンパクトで一貫性のある優れた設計であることがわかってきました。第一人者である五味先生の助言を受けつつ、8月頃には自作のEasy-ISLisp(略称EISL)が完成しました。
また、この頃、深層学習のことを独学しており、岡谷先生の本を読みつつ自分でも深層学習の仕組みを実装したいと思っていました。深層学習においては大量の行列計算が必要であり、GPUが必要でした。CUDAを使うとして、C言語による記述には手間がかかり、試行錯誤のためにコードを修正することが億劫でした。そこでちょうど完成したEISLにGPUを使う独自機能を追加、ISLispで深層学習の実験コードを書くことにしました。
ISLispの特長
Common Lispをベースにしつつも、SchemeやEULispの良さも取り込んでいます。サイズが小さく学習用、研究用に向いています。CLOSのサブセットであるオブジェクト指向システムILOSを含みます。設計が比較的新しいためエラー処理が充実しています。全体としてコンパクトで一貫性があるLisp国際標準規格です。
CUDAの導入
ゲーム用GTX960GPUを搭載したWindowsマシンを導入しました。CUDAはWindowsとLinuxで利用可能ですが、Windowsで使うことにしました。Windowsで使う場合、GCCには対応しておらず、マイクロソフトのVCが必要となります。2013版のVisualStudioをインストールする必要があります。CUDAは最新版のVisualStudioには対応していません。その後に、NVIDIA社のページよりCUDAをダウンロード、インストールしました。
EISLへのCUDAの組み込み
自作のISLisp処理系(以下「EISL])は標準的なC言語の機能しか使っていません。いくつかの修正をしてVCでもコンパイル可能としました。さらに、CUDAに含まれるCUBLASライブラリを取り込みます。
独自拡張関数を記述したCファイルのヘッダに
#include <cublas.h>
を追加します。これをコンパイルするにはNVIDIAの提供しているNVCCコンパイラを使う必要があります。次のようにしてオプションを与えます。
nvcc extension.c -c -lcublas
EISLはいくつかのファイルから成っており、それらをリンクする必要がありました。試行錯誤してみるとNVCCはリンカの機能も含んでいることがわかってきました。CUBLASを使用しない他のファイルもNVCCでコンパイルしてリンクすればいいことがわかりました。次のバッチファイルにしました。
nvcc -O2 -c main.c
nvcc -O2 -c function.c
nvcc -O2 -c data.c
nvcc -O2 -c gbc.c
nvcc -O2 -c cell.c
nvcc -O2 -c syntax.c
nvcc -O2 -c bignum.c
nvcc -O2 -c compute.c
nvcc -O2 -c error.c
nvcc extension.c -c -lcublas
nvcc main.obj function.obj data.obj gbc.obj cell.obj syntax.obj bignum.obj compute.obj error.obj extension.obj -lcublas -o eisl.exe
これによりCUBLASによる独自拡張関数を含んだEISLが起動するようになりました。
eisl
Easy-ISLisp Ver0.42
>
独自拡張関数
まずは単純な行列と行列の積を計算するものを作って試してみました。 (set-matmat c a b)という関数でa,b,cには浮動小数点数を要素とする2次元配列をとります。2次元配列を行列とみてa*bの結果をCに破壊的代入します。Lispでは基本的に値を生成して返し、破壊的代入はしないのですが、大きな行列はセルを大量に消費することから省メモリのために、そうしました。
C言語コードは長いので、巻末に掲載しました。使い方は以下の通りです。
Easy-ISLisp Ver0.42
> (defglobal a #2a((1.0 2.0)(3.0 4.0)))
A
> (defglobal b #2a((3.0 2.0)(1.0 4.0)))
B
> (defglobal c (create-array '(2 2)))
C
> (set-matmat c a b)
NIL
> c
# 2a((5.0 10.0) (13.0 22.0))
>
順伝播計算
GPUを利用した行列計算まではできるようになりました。ISLispからCUDAを呼び出すとタイムロスが発生します。また、計算結果をその都度セルに書き込むのでは省メモリの点でも不利です。そこで、深層学習の入力層から出力層へかけての順伝播計算を一気にGPUを使ってやってしまう独自拡張関数を用意することとしました。(forward w u fn) という形式で、wは重み行列、uは入力層及び各層の出力(つまり次の層への入力)を記憶する行列、fnは活性化関数です。コードは巻末に掲載しています。
データ構造
深層学習の教科書ではwは行列、uはベクトルで表されています。前述したようにforwardを組み込み関数にして計算速度を稼ぎたいと思いました。一気に計算するために各層のw行列をひとまとめにして、3次元配列、テンソルのようなものにしました。同様に各層のuベクトルもひとまとめにして行列にすることにしました。
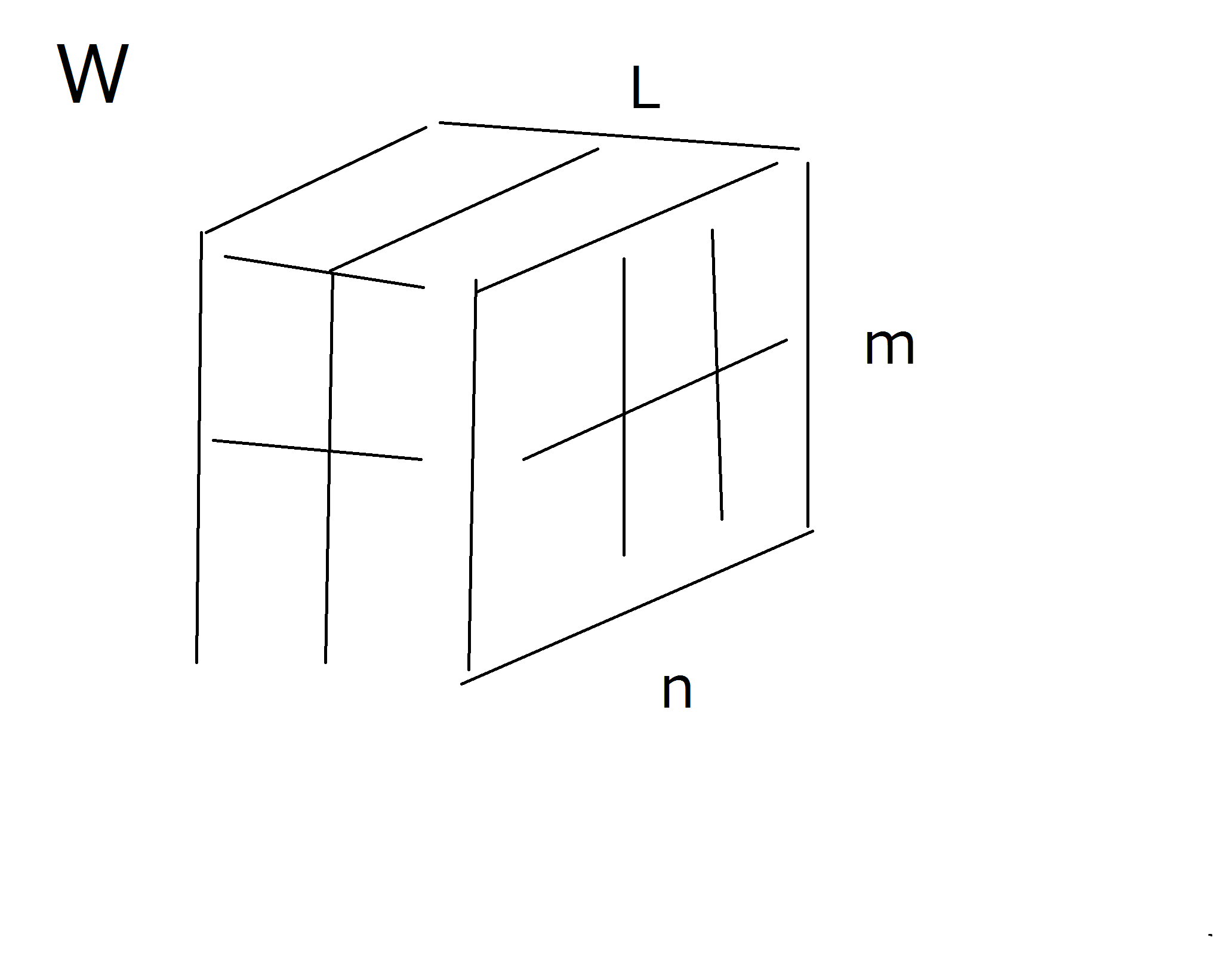
wはm*n行列をl層分重ねたものとしてます。
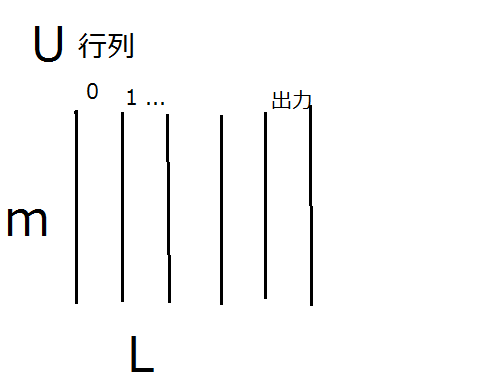
u行列はベクトルをl層分、寄せ集めた行列です。第0列が入力層です。
誤差逆伝達法 デルタ計算
今度は学習により重み行列を更新していくことを考えます。誤差逆伝播法が計算量の節約のために有効です。これをISLispでどのように実装するかについて考えました。この計算ではδ(デルタ)が重要な役割を果たします。
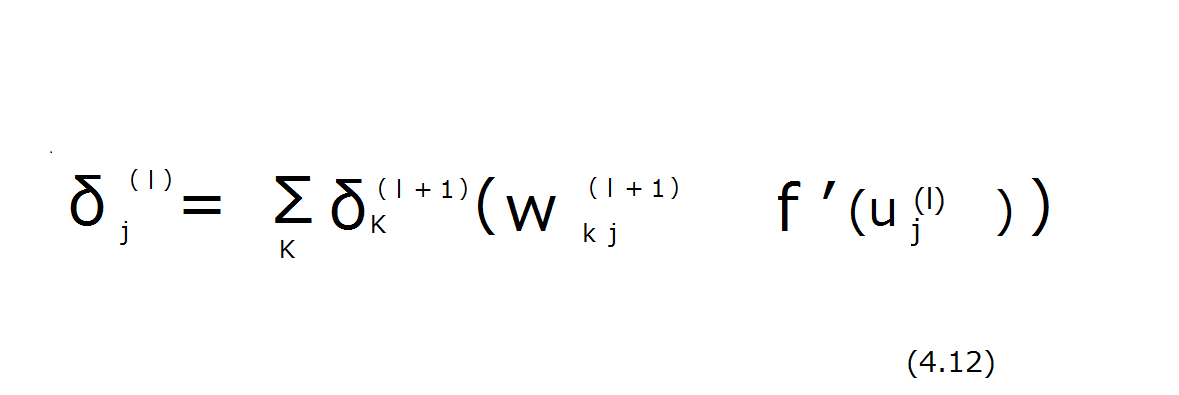
岡谷先生の本の47ページにあるδの数式です。各層を表す l(エル)を眺めていると再帰構造になっていることがわかります。出力層を起点にしてそのひとつ前の層を求める、さらにそれを基にしてもうひとつ前の層を求める。この再帰をISLispに書き直しました。
(defun calc-delta()
(for ((i 0 (+ i 1)))
((> i m1))
(set-aref (- (aref U i (+ l1 1)) (aref d i)) delta i l1))
(for ((l (- l1 1) (- l 1)))
((< l 0))
(for ((j 0 (+ j 1)))
((> j n1))
(set-aref (* (funcall #'fdash (aref U j l))
(for ((k 0 (+ k 1))
(s 0 (+ s (* (aref delta k (+ l 1))
(aref w (+ l 1) k j)))))
((> k m1) s)))
delta j l))))
(defun fdash(x)
(* (logistic x)(- 1 (logistic x))))
ISLispは繰り返しにforという構文を用意しています。Schemeのdoと同様の仕組みです。活性化関数にとりあえずロジスティック関数を与えました。
このδ計算ができれば重み行列を更新していく関数を書くことができます。
(defun backward()
(calc-delta)
(for ((l 0 (+ l 1)))
((> l l1))
(for ((i 0 (+ i 1)))
((> i m1))
(for ((j 0 (+ j 1)))
((> j n1))
(set-aref (- (aref W l i j)
(* (aref W l i j) larning-rate (aref delta j l)(aref U i l)))
W l i j)))))
(defglobal larning-rate 0.15)
larning-rateは学習係数を表す大域定義変数です。試行錯誤しながらいじります。
実験
さあ、うまく動くものでしょうか。ともかくやってみましょう。ISLispのコードは最後に掲載しました。
3*3行列の3層のおもちゃニューラルネットワークです。どうでしょう? ワクワク
Easy-ISLisp Ver0.42
> T
> (init)
NIL
> (test0 300)
T
> (test1 300)
T
> (res0)
0.794126377371483
0.6994092773060174
0.8406864839267559
T
> (res1)
0.7945477320524553
0.699789306814949
0.841136369619266
T
>
ん~む? 実験失敗?
2つの異なる入力に対して教師データを(0.5、0.8、0.7)にしたつもりなのですが。果たして少しはうまくいったのでしょうか? はたまたバグ、考え間違い? とりあえずは一歩前進。
へそ曲がり
Pythonには優秀な定番の深層学習ライブラリがあり、それを使えばいいのはわかっているのですが、それを利用して結果を得るだけでは単なるブラックボックスのままではないのか? そんな気持ちから自分で数式からプログラムを書こうと試行錯誤しています。ひとつだけ言えるのはISLispはこういった試行錯誤するのにちょうどよいLispだということ、これは自信を持って言えます。深層学習の理解、プログラムはまだまだ先は遠いようです。
謝辞
ISLispの仕様理解、実装にあたっては五味先生にたいへんお世話になりました。私のつまらない疑問に対して迅速、かつ、真摯にお答えくださった五味先生に感謝申し上げます。
コマーシャル
自作のISLisp処理系EISLについては電子書籍にまとめてコードつきでKindleにて販売しております。よかったら立ち読みしていってください。

参考文献
「GPUプログラミング入門」 伊藤智義 著 講談社
「深層学習」 岡谷貴之 著 講談社
「ISLISP規格仕様書」 http://islisp.org/jp/ISLisp-spec-jp.html
コード set-matmat
# define IDX2C(i,j,ld) (((j)*(ld))+(i))
int f_set_matmat(int arglist){
int i,j,k,k1,m,m1,n,n1,arg1,arg2,arg3;
cublasStatus stat;
float* devPtrA;
float* devPtrB;
float* devPtrC;
float* a = 0;
float* b = 0;
float* c = 0;
arg1 = car(arglist);
arg2 = cadr(arglist);
arg3 = caddr(arglist);
m = GET_INT(car(GET_CDR(arg2)));
k = GET_INT(cadr(GET_CDR(arg2)));
k1 = GET_INT(car(GET_CDR(arg3)));
n = GET_INT(cadr(GET_CDR(arg3)));
m1 = GET_INT(car(GET_CDR(arg1)));
n1 = GET_INT(cadr(GET_CDR(arg1)));
if(m != m1 || k != k1 || n != n1)
error(ILLEGAL_ARGS,"set-matmat",NIL);
// Memory Allocation
a = (float *)malloc (m * k * sizeof (*a));
if (!a)
error(ILLEGAL_ARGS,"set-matmat",NIL);
b = (float *)malloc (m * k * sizeof (*b));
if (!b)
error(ILLEGAL_ARGS,"set-matmat",NIL);
c = (float *)malloc (m * k * sizeof (*c));
if (!c)
error(ILLEGAL_ARGS,"set-matmat",NIL);
// Initalize
for(j=0;j<k;j++)
for(i=0;i<m;i++)
a[IDX2C(i,j,m)] = GET_FLT(vector_ref(arg2,i*k+j));
for (j=0;j<n;j++)
for (i=0;i<k;i++)
b[IDX2C(i,j,k)] = GET_FLT(vector_ref(arg3,i*n+j));
for(j=0;j<n;j++)
for(i=0;i<m;i++)
c[IDX2C(i,j,m)] = 0.0;
// Initialize CUBLAS
cublasInit();
stat = cublasAlloc (m*k, sizeof(*a), (void**)&devPtrA);
if(stat != CUBLAS_STATUS_SUCCESS)
error(ILLEGAL_ARGS,"set-matmat",NIL);
stat = cublasAlloc (k*n, sizeof(*b), (void**)&devPtrB);
if(stat != CUBLAS_STATUS_SUCCESS)
error(ILLEGAL_ARGS,"set-matmat",NIL);
stat = cublasAlloc (m*n, sizeof(*c), (void**)&devPtrC);
if(stat != CUBLAS_STATUS_SUCCESS)
error(ILLEGAL_ARGS,"set-matmat",NIL);
stat = cublasSetMatrix (m, k, sizeof(*a), a, m, devPtrA, m);
if(stat != CUBLAS_STATUS_SUCCESS)
error(ILLEGAL_ARGS,"set-matmat",NIL);
stat = cublasSetMatrix (k, n, sizeof(*b), b, k, devPtrB, k);
if(stat != CUBLAS_STATUS_SUCCESS)
error(ILLEGAL_ARGS,"set-matmat",NIL);
stat = cublasSetMatrix (m, n, sizeof(*c), c, m, devPtrC, m);
if(stat != CUBLAS_STATUS_SUCCESS)
error(ILLEGAL_ARGS,"set-matmat",NIL);
//Sgemm
cublasSgemm('N', 'N', m, n, k, 1.0, devPtrA, m, devPtrB, k, 0.0, devPtrC, m);
stat = cublasGetMatrix (m, n, sizeof(*c), devPtrC, m, c, m);
if(stat != CUBLAS_STATUS_SUCCESS){
cublasFree(devPtrA);
cublasFree(devPtrB);
cublasFree(devPtrC);
cublasShutdown();
error(ILLEGAL_ARGS,"set-matmat",NIL);
}
// Shutdown CUBLAS
cublasFree(devPtrA);
cublasFree(devPtrB);
cublasFree(devPtrC);
cublasShutdown();
// Set matrix After sgemm
for(j=0;j<n;j++)
for (i=0;i<m;i++){
SET_TAG(vector_ref(arg1,i*n+j),FLTN);
SET_FLT(vector_ref(arg1,i*n+j),c[IDX2C(i,j,m)]);
}
free(a);
free(b);
free(c);
return(NIL);
}
コード forward
//for deep larning forward process
//W 3 dimension
//U 2 dimension
//U(l+1) = W(l)*U(l)
int f_forward(int arglist){
int d1,d2,i,j,k,l,m,n,arg1,arg2,arg3;
double r;
cublasStatus stat;
float* devPtrA;
float* devPtrB;
float* devPtrC;
float* a = 0;
float* b = 0;
float* c = 0;
arg1 = car(arglist); //W
arg2 = cadr(arglist); //U
arg3 = caddr(arglist); //f
d1 = GET_CDR(arg1); //dimensions
d2 = GET_CDR(arg2); //dimensions
if(length(d1) != 3)
error(ILLEGAL_ARGS,"forward",d1);
if(length(d2) != 2)
error(ILLEGAL_ARGS,"forward",d2);
if(GET_INT(cadr(d1)) != GET_INT(car(d2))) // W(m,n,l) U(n,l+1) check n
error(ILLEGAL_ARGS,"forward",list2(d1,d2));
if(GET_INT(caddr(d1))+1 != GET_INT(cadr(d2)))// W(m,n,l) U(n,l+1) check l
error(ILLEGAL_ARGS,"forward",list2(d1,d2));
if(!(IS_SUBR(arg3)))
error(ILLEGAL_ARGS,"forward",arg3);
m = GET_INT(car(d1));
n = GET_INT(cadr(d1));
l = GET_INT(caddr(d1));
// Memory Allocation
a = (float *)malloc (m * n * sizeof (*a));
if (!a)
error(ILLEGAL_ARGS,"forward",NIL);
b = (float *)malloc (n * sizeof (*b));
if (!b)
error(ILLEGAL_ARGS,"forward",NIL);
c = (float *)malloc (n * sizeof (*c));
if (!c)
error(ILLEGAL_ARGS,"forward",NIL);
k = 0;
while(k<l){
// Initalize
for (j=0;j<n;j++)
for (i=0;i<m;i++){
a[IDX2C(i,j,m)] = GET_FLT(vector_ref(arg1,i*n+j+k*m*n));
}
for(i=0;i<n;i++){
b[i] = GET_FLT(vector_ref(arg2,i*(l+1)+k));
}
for(i=0;i<n;i++)
c[i] = 0.0;
// Initialize CUBLAS
cublasInit();
stat = cublasAlloc (m*n, sizeof(*a), (void**)&devPtrA);
if(stat != CUBLAS_STATUS_SUCCESS)
error(ILLEGAL_ARGS,"forward",NIL);
stat = cublasAlloc (n, sizeof(*b), (void**)&devPtrB);
if(stat != CUBLAS_STATUS_SUCCESS)
error(ILLEGAL_ARGS,"forward",NIL);
stat = cublasAlloc (n, sizeof(*c), (void**)&devPtrC);
if(stat != CUBLAS_STATUS_SUCCESS)
error(ILLEGAL_ARGS,"forward",NIL);
stat = cublasSetMatrix (m, n, sizeof(*a), a, m, devPtrA, m);
if(stat != CUBLAS_STATUS_SUCCESS)
error(ILLEGAL_ARGS,"forward",NIL);
stat = cublasSetVector (n, sizeof(*b), b, 1, devPtrB, 1);
if(stat != CUBLAS_STATUS_SUCCESS)
error(ILLEGAL_ARGS,"forward",NIL);
stat = cublasSetVector (n, sizeof(*c), c, 1, devPtrC, 1);
if(stat != CUBLAS_STATUS_SUCCESS)
error(ILLEGAL_ARGS,"forward",NIL);
//Sgemv
cublasSgemv('N', m, n, 1.0, devPtrA, m, devPtrB, 1, 0.0, devPtrC, 1);
stat = cublasGetVector(n, sizeof(*c), devPtrC, 1, c, 1);
if(stat != CUBLAS_STATUS_SUCCESS){
cublasFree(devPtrA);
cublasFree(devPtrB);
cublasFree(devPtrC);
cublasShutdown();
error(ILLEGAL_ARGS,"forward",NIL);
}
// Set vector After sgemv
for (i=0;i<n;i++){
r = (GET_SUBR(arg3))(list1(makeflt(c[i])));
vector_set(arg2,i*(l+1)+k+1,r);
}
k++;
}
// Shutdown CUBLAS
cublasFree(devPtrA);
cublasFree(devPtrB);
cublasFree(devPtrC);
cublasShutdown();
free(a);
free(b);
free(c);
return(NIL);
}
実験コード
# |
メモ
Uは入力テンソル。0次元は各層のユニット、1次元は層を表す。
Wは重みテンソル。0次元1次元は各層の係数行列、2次元は層を表す。
|#
(defglobal W (create-array '(3 3 3) 0.5))
(defglobal U #2a((0.5 0.0 0.0 0.0)
(0.6 0.0 0.0 0.0)
(0.5 0.0 0.0 0.0)))
(defglobal delta (create-array '(3 3)))
(defglobal d #(0.5 0.7 0.8))
(defglobal l1 (- (elt (array-dimensions W) 0) 1))
(defglobal n1 (- (elt (array-dimensions W) 2) 1))
(defglobal m1 (- (elt (array-dimensions W) 1) 1))
(defglobal larning-rate 0.15)
(defun init ()
(for ((k 0 (+ k 1)))
((> k l1))
(for ((i 0 (+ i 1)))
((> i m1))
(for ((j 0 (+ j 1)))
((> j n1))
(set-aref (random-real) w k i j)))))
(defun test0 (n)
(set-aref 0.5 U 0 0)
(set-aref 0.6 U 1 0)
(set-aref 0.7 U 2 0)
(for ((i 0 (+ i 1)))
((> i n) t)
(forward W U #'logistic)
(backward)))
(defun test1(n)
(set-aref 0.5 U 0 0)
(set-aref 0.7 U 1 0)
(set-aref 0.6 U 2 0)
(for ((i 0 (+ i 1)))
((> i n) t)
(forward W U #'logistic)
(backward)))
(defun res0()
(set-aref 0.5 U 0 0)
(set-aref 0.6 U 1 0)
(set-aref 0.7 U 2 0)
(forward W U #'logistic)
(for ((i 0 (+ i 1)))
((> i n1) t)
(print (aref u i (+ l1 1)))))
(defun res1()
(set-aref 0.5 U 0 0)
(set-aref 0.7 U 1 0)
(set-aref 0.6 U 2 0)
(forward W U #'logistic)
(for ((i 0 (+ i 1)))
((> i n1) t)
(print (aref u i (+ l1 1)))))
(defun calc-delta()
(for ((i 0 (+ i 1)))
((> i m1))
(set-aref (- (aref U i (+ l1 1)) (aref d i)) delta i l1))
(for ((l (- l1 1) (- l 1)))
((< l 0))
(for ((j 0 (+ j 1)))
((> j n1))
(set-aref (* (funcall #'fdash (aref U j l))
(for ((k 0 (+ k 1))
(s 0 (+ s (* (aref delta k (+ l 1))
(aref w (+ l 1) k j)))))
((> k m1) s)))
delta j l))))
(defun backward()
(calc-delta)
(for ((l 0 (+ l 1)))
((> l l1))
(for ((i 0 (+ i 1)))
((> i m1))
(for ((j 0 (+ j 1)))
((> j n1))
(set-aref (- (aref W l i j)
(* (aref W l i j) larning-rate (aref delta j l)(aref U i l)))
W l i j)))))
(defun fdash(x)
(* (logistic x)(- 1 (logistic x))))