この記事はmohikanz Advent Calendar 2018 #2の15日目です。
昨日はAQUAさんの転職動機とその時の心理状態を振り返るでした。
転職よりも先に就職をしなければならない僕ですが、就活する上でも考え方を参考にしていきたいなと思います。
今回は、僕が大学でやっている研究について簡単に触れようかと思います。
昨日まで論文書いていたので、書くの追い付かなくて遅れてすみません!
はじめに
僕の所属している研究室では、デジタルサイネージシステムの設置販売を行っています。それ絡み今年色々あってベンチャー企業が一つ設立されたりしました。
ちなみに、都内だと銀座の結構立地のいい店に設置してあったりします。
さて、このデジタルサイネージなんですが、いくつかある機能の中にtwitterの投稿を掲載するというものがあります。この機能実は掲載するツイートを選ぶのが手動なので、それをうまい具合に自動で処理できるようにしようというのが、僕の研究になります。
今回やること
研究の一環でWMD(Word Mover's Distance)を扱ったので、WMDでニュース記事の本文とタイトルの類似度を測ってみようかと思います。
WMD(Word Mover's Distance)
WMDは、2つの文書があったときにその文書間の距離を計算しようと提案された手法です。
元の論文がこちらになります。
From Word Embeddings To Document Distances
このWMDは、Word2Vecで得られる分散表現を利用しているので、まずはWord2Vecについて簡単に触れていきます。
Word2Vec
Word2Vecは、単語をベクトル表現化することで、単語の意味をとらえようとする手法で有名なものです。基本的に同じような意味や使われ方の単語は、同じような文章または文脈に出てくるはずであるという考え方で計算を行っています。
その実態は、単層ニューラルネットワークによる学習と次元圧縮になります。
単語を演算処理まで行えるように、各要素ごとではなく単語の定義によってベクトル化を行うため、以下のような演算ができるようになります。
- 「王様」-「男」+「女」=「女王」
このWord2VecはCBoWモデルとSkip-gramモデルで実装されます。
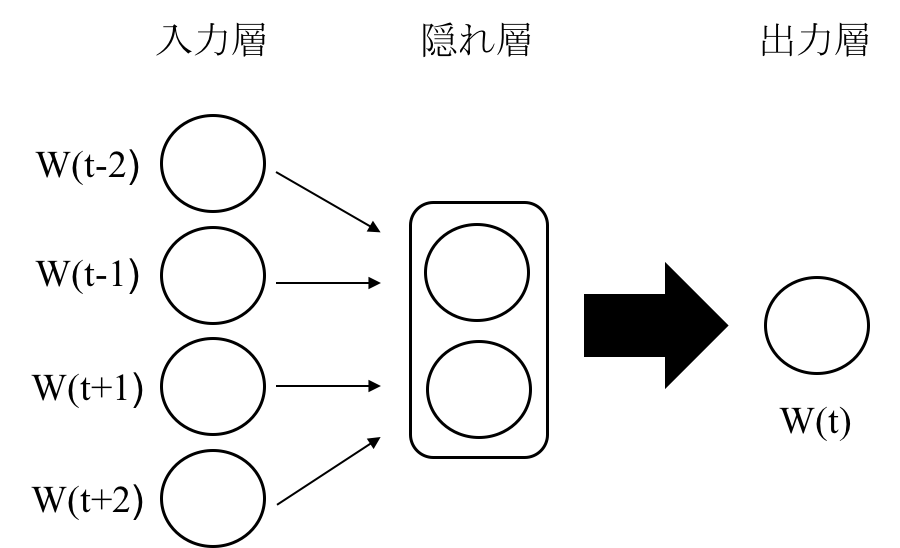
CBoW
CBoWモデルでは、文法と意味を学習することは文脈中の単語から対象単語が現れる条件付き確立を最大化するということになります。
つまりこれは、前後の単語から対象単語を推測するということです。
モデルのイメージは次のようになります。
Skip-gram
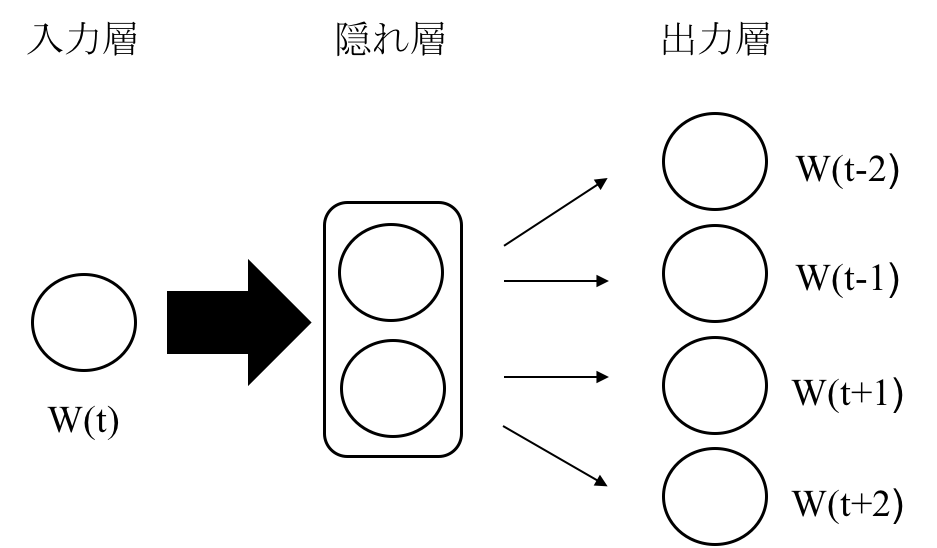
Skip-gramモデルはCBoWの逆で、対象の単語からその周辺単語を予測します。
意味的な精度ではSkip-gramの方が上になります。
Skip-gramにとっての意味・文法の学習は、出力層における周辺単語予測のエラー率の合計を最小化するということになります。
モデルのイメージは次のようなものです。
細かな理論や数式については、こちらでわかりやすくまとめてくれてあります。
WMD
文書A, Bが存在したとき、A、Bの語同士を対応付けることで、文書Aを文書Bに変換するときの対応付けの変換コストが最も低い場合の、変換コストの和を文書間距離と考えます。
Word2Vecの計算によって、次のような意味類似度を捉えた分散表現ベクトルを獲得します。
$$ X_{w} = (x_{w1}, x_{w2}, ... , x_{wn}) $$
これをもとに、単語$i$を単語$j$に対応づけるコスト$c(i, j)$を次のように定義できます。
$$ c(i,j) = | x_{i} - x_{j} |_{2} $$
この和を求めれば文書間距離が求められますが、このような計算は意味語の数が同じで、各単語の意味的にもほぼ1対1で結び付けられるものに対して行えることです。
そこで一般化して次のような最適化問題の式が得られます。
$$ \min_{T \geq 0} \sum_{i,j =0}^{n} T_{i, j}c(i, j) $$
この式を解くことで文書間距離の計算が可能となります。
ざっくり書いたので、間違っているところがあるかもしれません。
技術的な部分に関してはこちらで詳しくまとめられているので、参照ください。
実装
さっそく実装してみます。
本当はtwitterのデータとか用意したかったですが、その時間がなかったので何故か手元にあったYahoo!ニュースの2014年1月の記事を利用していきます。
データの用意
domestic、economy、enter、life、local、science、sports、worldの分野ごとに分かれているのでとりあえず今回はscienceの記事3006個の記事を使いました。
ファイル名がタイトル、中身が記事になっているので、それぞれ一つにまとめていきます。
記事のほうはshellでファイルを一つにまとめました。
タイトルをファイル名で取ってくると色々いらないものも入っているので、ついでに落とします。
import os
import re
path = "./2014/science"
files = os.listdir(path)
files_file = [f for f in files if os.path.isfile(os.path.join(path, f))]
titles = []
for i in files_file:
i = re.sub(r".txt", "", i)
i = re.sub(r"(.+?)", "", i)
i = re.sub(r"<.+?>", "", i)
i = re.sub(r"【.+?】", "", i)
i = re.sub(r"[0-9]", "", i)
titles.append(i)
本文のデータも読み込んで整形しておきます。
text_path = path + "/science.txt"
with open(text_path) as f:
text = f.readlines()
texts = []
for i in text:
i = re.sub(r"[0-9]", "", i)
i = re.sub(r"●", "", i)
i = re.sub(r"○", "", i)
texts.append(i)
形態素解析
データの用意はできたので、これを学習するように形態素解析して分かち書きにしていきます。
今回は名詞だけ扱うことにしました。
形態素解析用の関数を作って、タイトルと本文をそれぞれ解析、分かち書きの形に変更していきます。
import MeCab as mc
import unicodedata
def mecab_analysis(text):
text = unicodedata.normalize("NFKC", text)
tagger = mc.Tagger("Ochasen")
tagger.parse("")
node = tagger.parseToNode(text)
out = []
while node:
if node.surface != "":
word_type = node.feature.split(",")[0]
if word_type in "名詞":
out.append(node.surface)
node = node.next
if node is None:
break
return out
a_titles = [mecab_analysis(i) for i in titles]
a_titles = [' '.join(d) for d in a_titles]
a_texts = [mecab_analysis(i) for i in texts]
a_texts = [' '.join(d) for d in a_texts]
これで下のようなタイトルと本文のデータがそれぞれ出来上がりました。
# title
年 人 逸材 アイドル 橋本 環 奈 U - NEXT ライブ 映像 独占 配信
# text
U - NEXT 月日 橋本 環 奈 さん 所属 アイドル グループ Rev . from DVL ライブ インタビュー 映像 独占 配信 発表 橋本 環 奈 さん ファン 撮影 奇跡 写真 きっかけ ネット 上 天使 年 人 逸材 話題 人 U - NEXT 映像 配信 サービス Rev . from DVL ライブ 映像 メンバー インタビュー 映像 放題 配信 どちら DVD 販売 同社 独占 映像 配信 同社 配信 記念 期間 限定 新規 加入 者 特典 橋本 環 奈 さん 写真 当選 者 名前 入り サイン セット 名 プレゼント 受付 期間 同日 月日 登録 ページ 日 無料 トライアル 登録 人 対象
ちょっと気になった点もありましたが、今回はこれでいきます。
モデルの作成
Word2Vecで学習させてモデルを作っていきます。
Word2Vecで取り込めるように先ほど分かち書きにした本文をファイル出力しておきます。
from gensim.models import word2vec
wakachi_file = "texts.wakachi"
with open(wakachi_file, "w", encoding = "utf-8") as fp:
fp.write("\n".join(a_texts))
今回はサクッとやっていくので、あまりパラメータについてはだいたいで合わせて学習させます。
パラメータの詳細に興味がある方はこちらを参照してみてください。
データ量は少ないので、すぐに学習が終わりました。
data = word2vec.LineSentence(wakachi_file)
model = word2vec.Word2Vec(data, size = 200, window=10, hs= 1, min_count=2, sg=1)
model.save("science.model")
どんな感じか見るとこんな感じでした。
model.most_similar(positive=["Snapchat"])
[('Find', 0.792327880859375),
('Friends', 0.7732328176498413),
('セキュリティー', 0.6965417861938477),
('Gibson', 0.6648616790771484),
('過失', 0.6561192274093628),
('Constine', 0.6440823674201965),
('SnapchatDB', 0.6177372932434082),
('謝罪', 0.6017171144485474),
('濫用', 0.5946273803710938),
('オプトアウト', 0.5836793184280396)]
model.most_similar(positive=["細胞"])
[('幹', 0.8481700420379639),
('iPS', 0.8427421450614929),
('分化', 0.8364800214767456),
('胎盤', 0.8327063918113708),
('STAP', 0.8285166621208191),
('受精卵', 0.8142461180686951),
('Oct', 0.8024594783782959),
('Lgr', 0.802199125289917),
('キメラマウス', 0.7996840476989746),
('生殖', 0.7965140342712402)]
Snapchatが情報流出やらかしたり、STAP細胞が発表された時期だったりしたようですね。
「STAP」と入れると「あります」が返ってくると面白かったかもしれません
類似度の値的に微妙な部分もありますが、進めていきます。
記号を取り除くのを忘れていたのは完全なミスでした。
WMDで文書間距離を測る
モデルもできたので、タイトルと本文の文書間距離を測ってみます。
与えたデータの1件目の本文とタイトルを入れてみます。
distance = model.wmdistance(a_texts[0], a_titles[0])
print(distance)
3.1279835534715015
値が1に近ければ近いほど比較した文書は近いということになります。
名詞だけにしたのもあるかもしれませんが、うまくいっているのか自信がなくなってきましたね。
一番文書間距離が近い組み合わせを出そうとすると、2分探索するにしても一度すべての組み合わせの文書間距離を出す必要があるため、計算が終わり次第追記したいと思います。
この計算量の多さがWMDの弱点になります。
おわりに
今回はWMDでYahoo!ニュースの記事とタイトルの文書間距離を測ってみようということでサクッとやってみました。
サイネージに実装することも考えて、計算時間なども考慮する必要があるためこの手法はあまりむいていませんでしたが、うまいことできるように色々な手法を試したり、組み合わせたりするようなことを研究しています。
明日はgodan09さんのAdobe Rushはいいぞです。
参考
From Word Embeddings To Document Distances
Word Mover's Distance: word2vecの文書間距離への応用
Word Mover's Distance を使って文の距離を計算する
Word2Vec のニューラルネットワーク学習過程を理解する
Word2Vec:発明した本人も驚く単語ベクトルの驚異的な力