本記事について
FXの1分足データを任意の時間足(1時間足など)に変更するプログラムを作成します。
成果物
1分足のデータを・・・
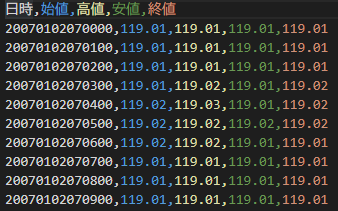
任意の時間氏に変更してCSVに出力します↓(下記画像は1時間足)
データの準備
1分足のデータはGMOクリック証券さんからダウンロードしました。
口座さえあれば入金額が0でもダウンロード出来るという太っ腹な対応。非常にありがたいです。
(※他の業者さんだと、入金金額が一定金額無いとダメだったり、日足レベルのデータまでしか無かったりします。)
今回は米ドル/円のデータを2007年1月から2020年9月までダウンロードしました。
フォルダ構成
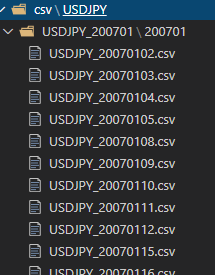
ダウンロードしたデータを解凍すると以下のようなフォルダ構造になっています。
/通貨名_yyyymm/yyyymm/
※USDJPYの2020年8月のフォルダだと、/USDJPY_202008/202008
そのフォルダに、各日(通貨名_yyyymmdd.csv)のCSVが保存されています。
今回ダウンロードしたCSVデータは、
今後作成するプログラムでも流用する予定なので、
以下のようなツリー構造にして保存することにします。
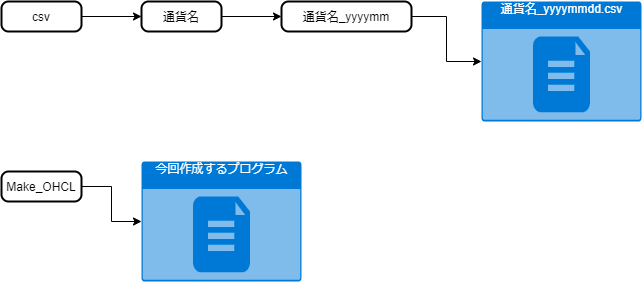
このようなツリー構造しておけば、今後ダウンロードする通貨の種類が増えても対応しやすいです。
また、今回作成するプログラムはcsvフォルダと同じ階層に、
「Make_OHCL」というフォルダを作成してそこに保存することにします。
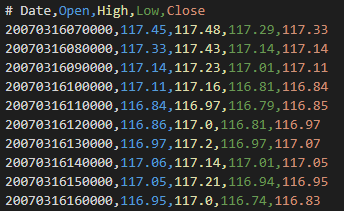
CSVの中身について
csvは、2007年は以下のようなフィールド構造になっています。
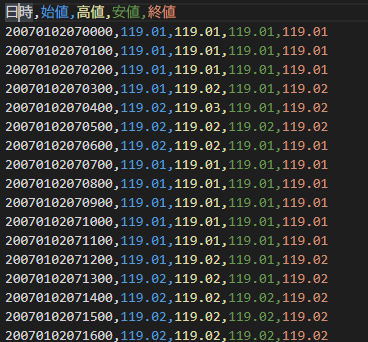
しかし、2016年頃から以下のようにフィールド数が増えています。
スプレッド(売買手数料)が考慮されているんですね。

ちょっと面倒ですが、2種類のCSVに対応する必要があります。
コード
今回作成するプログラムはcsvフォルダと同じ階層に、
「Make_OHCL」というフォルダを作成し、その直下に作成します。
データの加工処理はpandasではなく、速度を高めるためにnumpyを利用します。
from copy import copy
import glob
import numpy as np
import pandas as pd
def make_ohlc(ashi, arr=None):
"""
関数の説明:指定の時間足のOHLCを作成し、arrayを返す。
ashi:変更後の時間足。60なら1時間足。
arr:1分足のcsvファイルをarrayに変換したもの。
"""
#読み込んだCSVファイルが6列以上あったら、1~5列目だけ読み込む。
if arr.shape[1] > 5:
arr = arr[:,0:5]
arr = np.c_[arr, np.zeros((len(arr),4))] # 4列追加
for i in range(0, len(arr), ashi):
try:
arr[i,5] = arr[i,1] #始値
max_tmp = arr[i:i+ashi,2].astype(np.float) #指定期間の高値一覧を取得
arr[i,6] = max_tmp.max() #高値
min_tmp = arr[i:i+ashi,3].astype(np.float) #指定期間の安値一覧を取得
arr[i,7] = min_tmp.min() #安値
arr[i,8] = arr[i+ashi-1,4] #終値
except IndexError:
pass
arr = np.delete(arr, [1,2,3,4], axis=1) #2~5列目はもう不要なので削除
arr = arr[arr[:,4] != 0] #0の行を削除
return arr
currency = 'USDJPY' #通貨ペア名
ashi = 60 #取得したい足の長さ(60なら60分足)
arr = None #arrを初期化
csv_dir = '../csv/' + currency + '/' # /csv/通貨名フォルダ
dir_list = glob.glob(csv_dir + '*') # csv/通貨名/通貨名_yyyymm のフォルダ一覧を取得
for i in range(len(dir_list)):
file_list = glob.glob(dir_list[i] + '/' + dir_list[i][-6:] + '/*') #csvファイルのパス一覧を取得
for j in range(len(file_list)):
pre_arr = copy(arr) #前のarrをpre_arrに退避
csv_arr = np.loadtxt(file_list[j], delimiter=",", skiprows=1, dtype='object') #csvをarrayに読み込む
arr = make_ohlc(ashi, csv_arr) #足の長さを変更
if pre_arr is not None:
#前のarrと変換したarrを連結する
arr = np.vstack([pre_arr,arr])
filename = currency + '_ashi=' + str(ashi) + '.csv'
np.savetxt(filename, arr , delimiter="," , header="Date,Open,High,Low,Close" ,fmt="%s") #CSVに保存する
今回は複数のディレクトリに複数のCSVファイルが入っていたので、
連結処理などでちょっとコードが長くなりましたが、
すでにCSVが1つのファイルにまとまっているよという場合は、以下のコードだけで大丈夫です。
def make_ohlc(ashi, arr=None):
"""
関数の説明:指定の時間足のOHLCを作成し、arrayを返す。
ashi:変更後の時間足。60なら1時間足。
arr:1分足のcsvファイルをarrayに変換したもの。
"""
#読み込んだCSVファイルが6列以上あったら、1~5列目だけ読み込む。
if arr.shape[1] > 5:
arr = arr[:,0:5]
arr = np.c_[arr, np.zeros((len(arr),4))] # 4列追加
for i in range(0, len(arr), ashi):
try:
arr[i,5] = arr[i,1] #始値
max_tmp = arr[i:i+ashi,2].astype(np.float) #指定期間の高値一覧を取得
arr[i,6] = max_tmp.max() #高値
min_tmp = arr[i:i+ashi,3].astype(np.float) #指定期間の安値一覧を取得
arr[i,7] = min_tmp.min() #安値
arr[i,8] = arr[i+ashi-1,4] #終値
except IndexError:
pass
arr = np.delete(arr, [1,2,3,4], axis=1) #2~5列目はもう不要なので削除
arr = arr[arr[:,4] != 0] #0の行を削除
return arr
currency = 'USDJPY' #通貨ペア名
ashi = 60 #取得したい足の長さ(60なら60分足)
csv_arr = np.loadtxt(<csvファイルのパス>, delimiter=",", skiprows=1, dtype='object') #csvをarrayに読み込む
arr = make_ohlc(ashi, csv_arr) #足の長さを変更
filename = currency + '_ashi=' + str(ashi) + '.csv'
np.savetxt(filename, arr , delimiter="," , header="Date,Open,High,Low,Close" ,fmt="%s") #CSVに保存する
確認
1時間足に変更されたCSVファイルが出力されたことを確認します。
CSVファイルからチャート画像を作る方法は以下の記事で紹介しています。
https://qiita.com/sw1394/items/b2a86cfc663d89915e28