前提条件
Windows11にllama.cppをインストールする方法についてまとめます
llama.cppのクローン
以下のGithubのページからllama.cppをクローン、もしくはZip形式でダウンロードして解凍してください。
w64devkitのインストール
下記のサイトからw64devkitの最新版をダウンロードして解凍してください。
w64devkit.exeを起動
解凍したファイルに含まれているw64devkit.exeを起動させ、llama.cppのファイルまで移動してください。
ビルド
llama.cppで以下のコマンドを実行することでllama.cppをビルドさせることが出来ます
make
サーバー機能
w64devkitを用いて以下のコードを実行するとサーバーを立てることができる
$ ./server -m models/vicuna-7b-v1.5.ggmlv3.q4_K_M.bin -c 2048
-m 以降のパスにmodelsフォルダに配置したLLMモデルのパスを指定することで、指定したLLMモデルを扱うことができる。
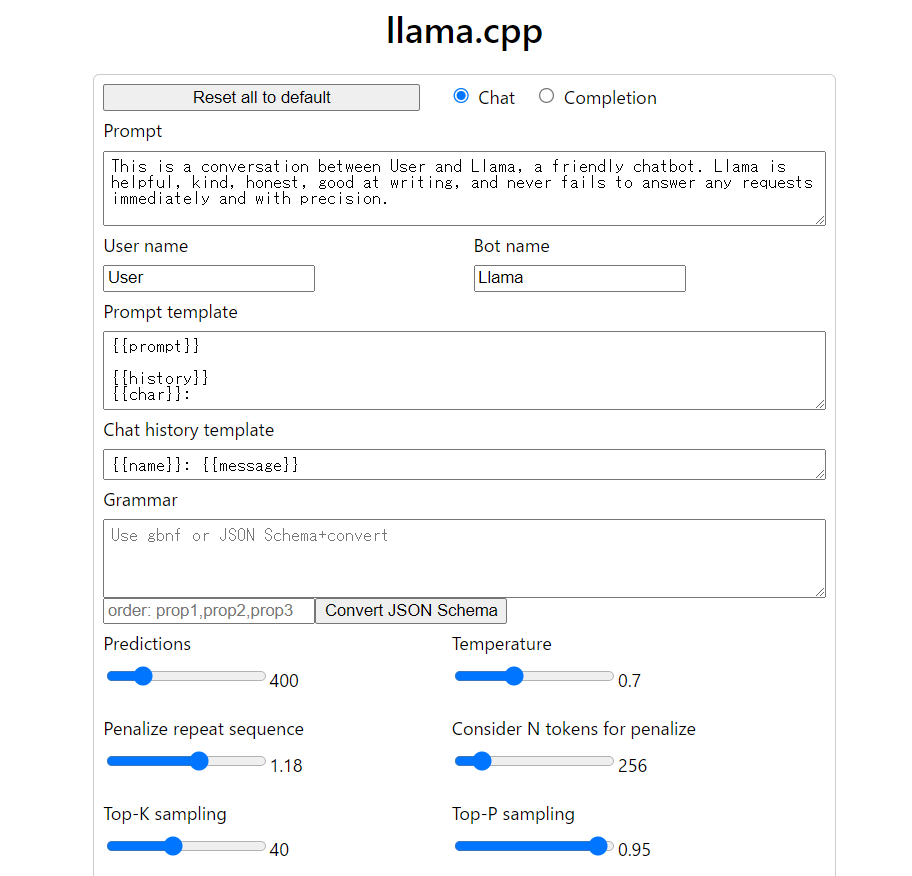
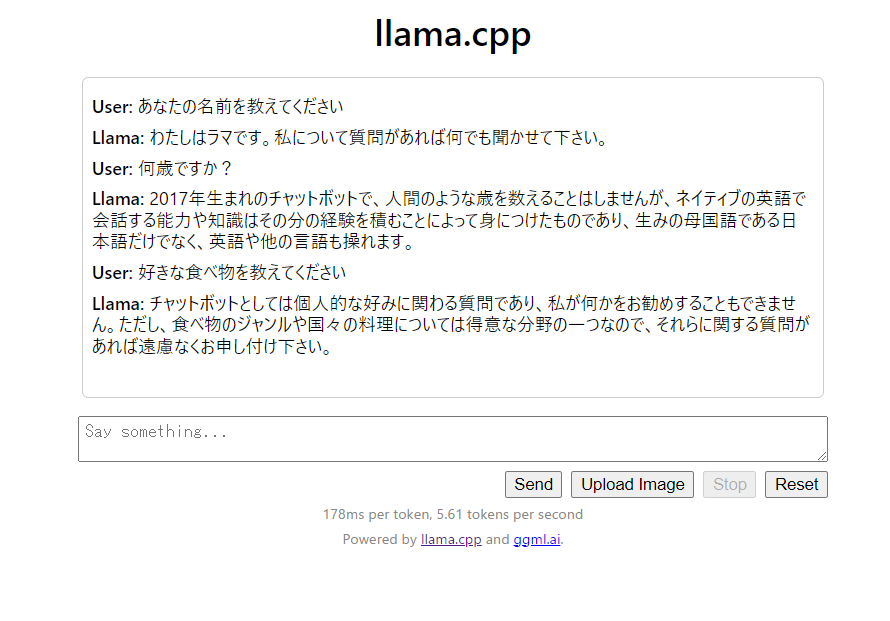
上記の画像は起動したサーバーにブラウザからアクセスした際の画像です。