はじめに
この記事は株式会社アイスタイルアドベントカレンダーの16日目の記事です。
DBAの@toshifusaがお送りする今日のお話は、RDBMSのインデックスのお話。
今までとは打って変わって地味で基本的な話ですがお付き合い下さい。
アイスタイルのデータベース環境
SQL Server、MySQL、PostgreSQLが使われていますが、メインのデータベースはSQL Serverです。
SQL Serverが使われているのって、Web業界では珍しいと思うのですが、創業当時に採用されたデータベースがSQL Serverでした。性能面での問題がほとんど発生しないので、そのまま使い続けています。
こんな疑問がわいた経験ないですか?
LIKE検索で先頭に%を指定して後方一致検索をした時や、検索対象カラムに関数を使ったときに、インデックスを使ってくれないのはなぜなのか疑問に思った事無いでしょうか?
複合インデックスを定義したテーブルで、インデックス定義の第2カラムを指定したクエリではインデックスを使わないのはなぜなんだろうとか、複合インデックスを定義するとき、どのカラムを第一列にしたら良いんだろうとか。
それらはB-Treeインデックスの構造を知れば納得がいくと思います。
B-Treeインデックスの基本構造
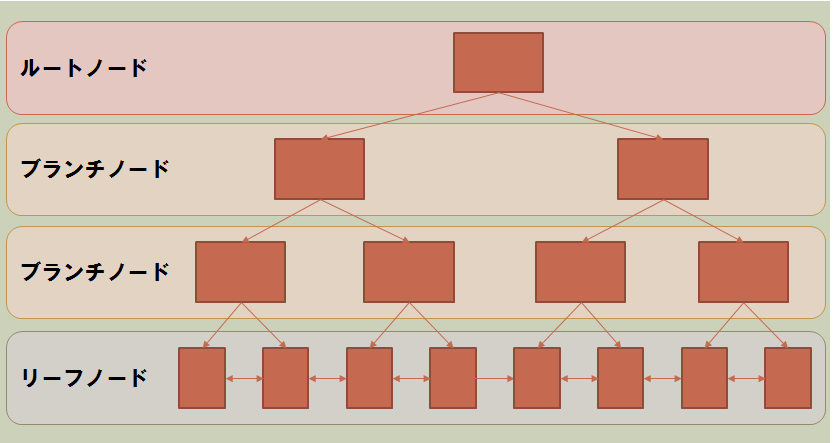
こんな感じのツリー構造になっています。
インデックスを作成すると、定義の第一カラムをもとに、検索木を作成し、リーフノードにはテーブルの行へのポインタを格納します。
単一カラムのインデックス
簡略化して図にしましたが、一つのカラムを指定してB-Treeインデックスを作ると、こんな感じのツリー構造をが作られます。
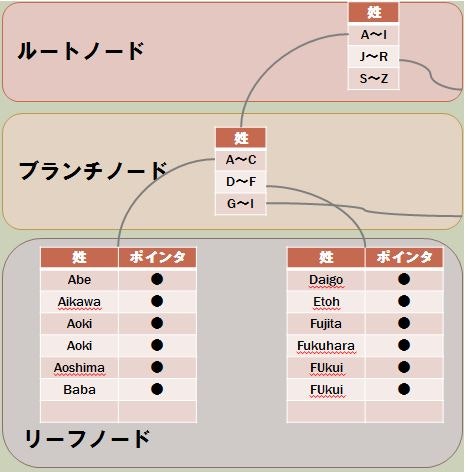
これを見ると、以下の疑問に納得がいくと思います。
Q. Like検索で先頭に"%"を指定すると、なぜインデックスを使わないんだろう
A. 先頭文字が分からないと、検索木をたどることが出来なくなるから、使えないんです
Q. 検索対象カラムに関数を使うと、なぜインデックスを使わないんだろう
A. 関数適用前の値で検索木が形成されているので、検索木をたどることが出来なくなるから、使えないんです
複合インデックス
簡略化して図にしましたが、複数のカラムを指定してB-Treeインデックスを作ると、こんな感じのツリー構造をが作られます。
複数のカラムを指定してインデックスを作成しても、定義の第一カラムをもとに、検索木を作成します。
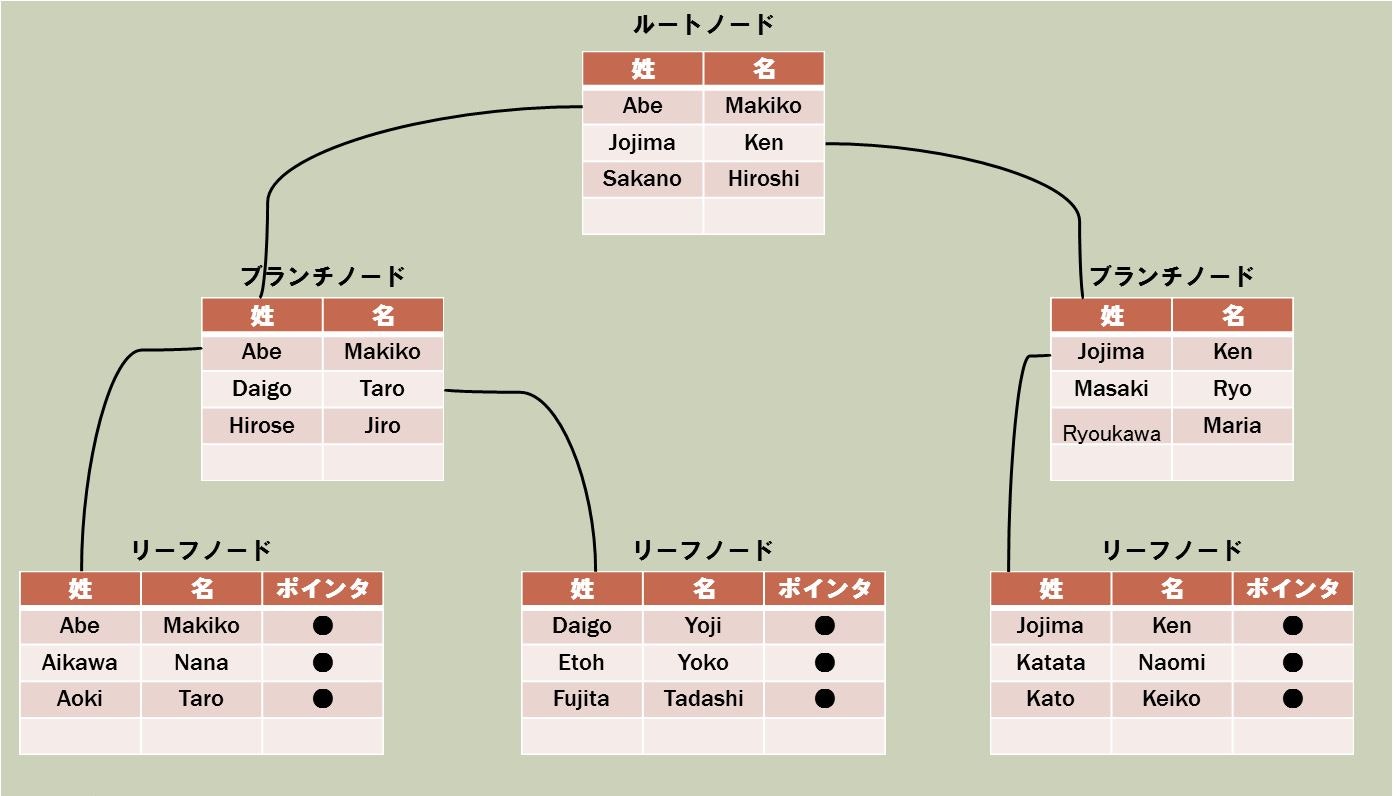
これを見ると、以下の疑問に納得がいくと思います。
Q. インデックス定義の第2カラムを指定したクエリではインデックスを使わないのはなぜなんだろう
A. 検索木は第一カラムで作られているので、使えないんです
Q. 複合インデックスを定義するとき、どのカラムを第一列にしたら良いんだろう
A. 検索木が枝分かれするよう、カーディナリティが高いカラムを指定した方がいいよね
第一カラムに何を指定するかで、形成される検索木はまったく変わります。
カーディナリティの少ないカラムを指定すると、一つの枝のリーフノード多すぎて、ぜんぜん絞り込めませんよね。
複合インデックスを作成するときは、よく指定するカラムを第一カラムに指定した方が汎用性が上がるのですが、論理削除を使っていて、必ず指定するからって理由で削除フラグを第一カラムに指定したりすると、検索木は二つにしか枝分かれしないですよ。
まとめ
ルールやノウハウとして覚えるのではなく、内部構造を知ることで確かな知識を身につけたいですね。