[1] はじめに
Zero-ETL統合とは?
- OLTP系DBとOLAP系DWHはそもそも役割が違うので、従来はOLTP DBに蓄積されてたデータをDWHにデータ連携するETLが必要だった
- この連携は結構大変で、要件に応じて例えばGlue、DMS、Kinesys、MWAA、StepFunctionsなどなどいろいろなサービスを組み合わせて実現する必要があった
- この煩雑な工程をなくして、ニアリアルタイムでデータ自動連携しようというAWSの構想が
Zero-ETL - Zero-ETLの範囲や実現方法はいろいろある
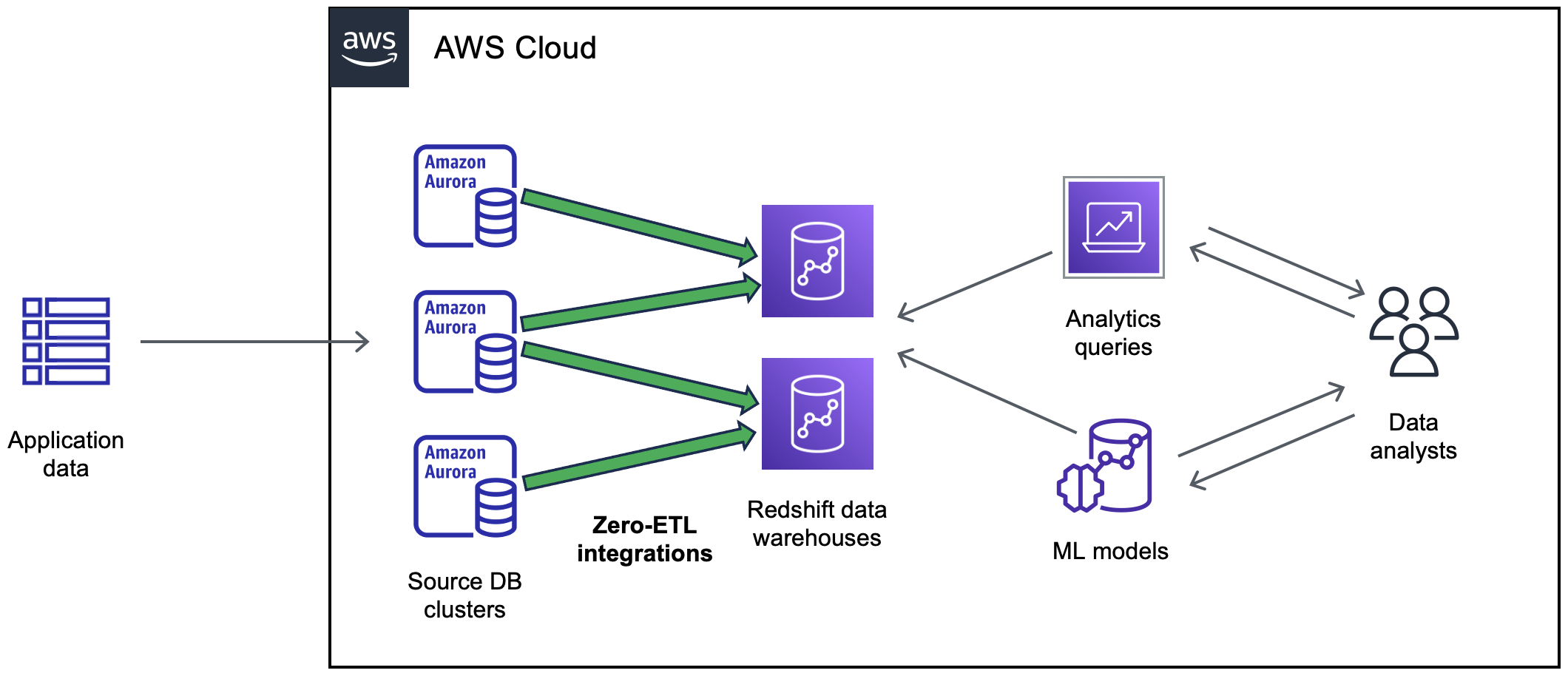
- OLTP系DB〜DWH(Redshift)に着目すると、2023年12月時点で以下のDB間のZero-ETL統合ができる。
- Aurora MySQL → Redshift(GA)
- Aurora PostgreSQL → Redshift(2023/12時点でPreview)
- RDS MySQL → Redshift(2023/12時点でPreview)
- DynamoDB → Redshift (2023/12時点でPreview)
- この統合は、従来のFedereated Queryとかとは全く異なり、HWレイヤーレベルでDB間のデータがフルマネージドで同期される仕組み(データソースへの同期に伴うパフォーマンス影響も最小限)
[2]Aurora MySQL x Redshift のZero-ETL統合の確認
Aurora MySQL serverless v2とRedshift ServerlessでZero-ETL統合で色々挙動確認してみたメモ
事前設定については [3] 参照
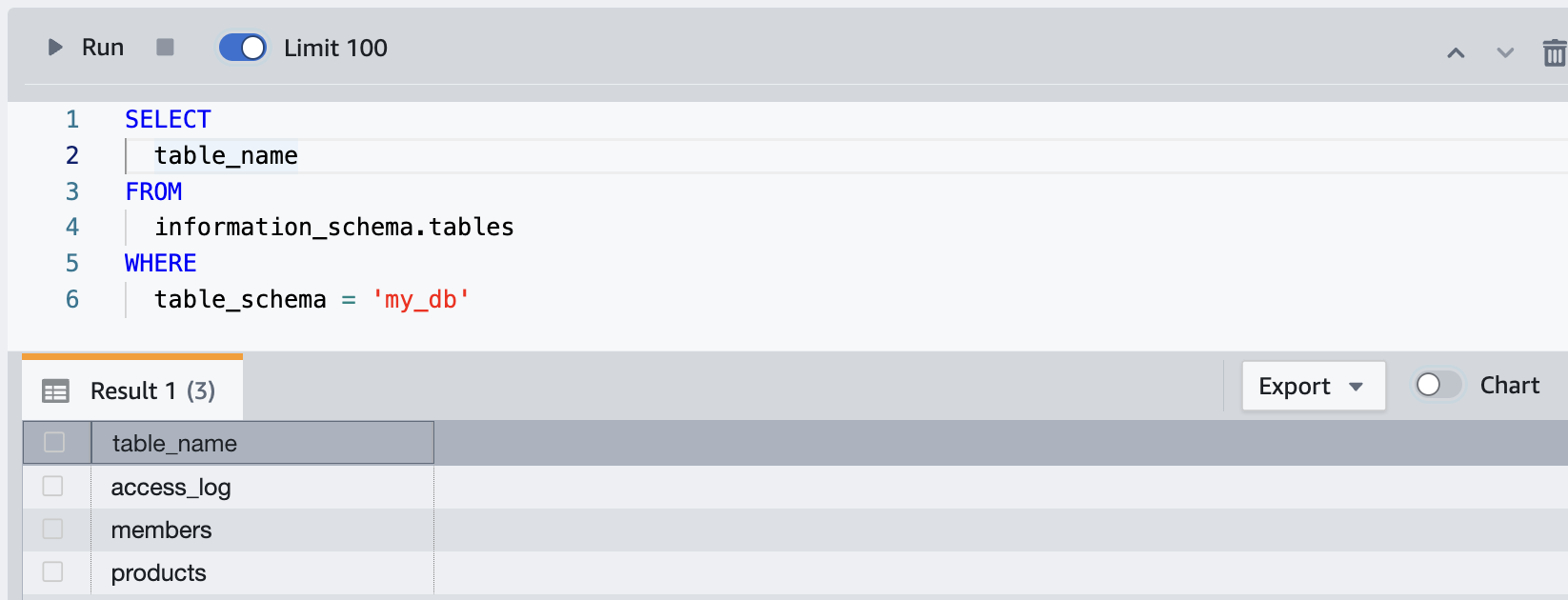
CREATE TABLE
とりあえずサンプルデータセットはAmazon Bedrock Claude Instantで生成して(作り方は割愛)、これをAurora MySQLで実行
-- アクセスログテーブル
CREATE TABLE my_db.access_log (
log_id INT PRIMARY KEY AUTO_INCREMENT,
member_id INT,
product_id INT,
accessed_at DATETIME
);
-- 会員情報テーブル
CREATE TABLE my_db.members (
member_id INT PRIMARY KEY,
name VARCHAR(50),
email VARCHAR(100)
);
-- 商品情報テーブル
CREATE TABLE my_db.products (
product_id INT PRIMARY KEY,
name VARCHAR(50),
price INT
);
-- 実行結果
MySQL [(none)]> show tables in my_db;
+-----------------+
| Tables_in_my_db |
+-----------------+
| access_log |
| members |
| products |
+-----------------+
3 rows in set (0.01 sec)
すかさずRedshift クエリエディタv2で見てみると、すぐにRedshift側で反映されてる
INSERT
同じくBedrockにダミーレコード投入SQLを作らせてAurora MySQLで実行
INSERT INTO my_db.access_log
(member_id, product_id, accessed_at)
VALUES
(1, 1, NOW()),
(2, 3, NOW() - INTERVAL 1 DAY),
(1, 2, NOW() - INTERVAL 2 DAY),
(3, 5, NOW() - INTERVAL 3 DAY),
(1, 4, NOW() - INTERVAL 4 DAY),
(2, 1, NOW() - INTERVAL 5 DAY),
(3, 2, NOW() - INTERVAL 6 DAY),
(1, 3, NOW() - INTERVAL 7 DAY),
(2, 4, NOW() - INTERVAL 8 DAY),
(3, 5, NOW() - INTERVAL 9 DAY);
-- 会員情報テーブルに10行データをINSERT
INSERT INTO my_db.members
(member_id, name, email)
VALUES
(1, 'Member1', 'member1@example.com'),
(2, 'Member2', 'member2@example.com'),
(3, 'Member3', 'member3@example.com'),
(4, 'Member4', 'member4@example.com'),
(5, 'Member5', 'member5@example.com'),
-- 商品情報テーブルに10行データをINSERT
INSERT INTO my_db.products
(product_id, name, price)
VALUES
(1, 'Product1', 1000),
(2, 'Product2', 2000),
(3, 'Product3', 3000),
(4, 'Product4', 4000),
(5, 'Product5', 5000),
すかさずRedshift クエリエディタv2で見てみると、すぐにRedshift側で反映されてる
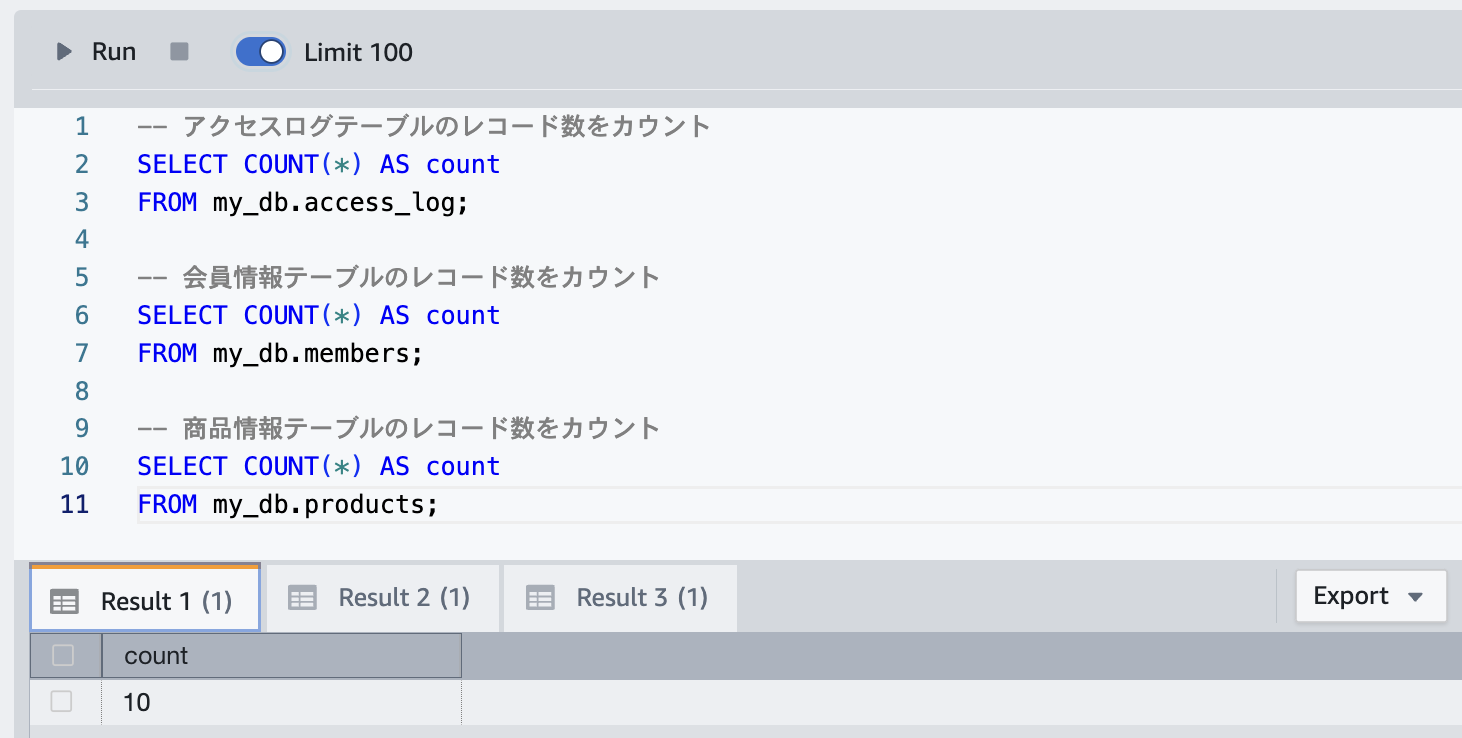
- 1000行、5000行、10000行でAuroraにINSERTしてみても、秒でRedshiftへ同期される。
DELETE / DROP TABLE
- もちろんAurora側で
DELETEしたら、秒でRedshiftへも同期される。 - もちろんAurora側で
DROP TABLEを実行すると、Redshift側でも削除される
ALTER TABLE
- Aurora側元データでカラムが追加されるパターンを想定した
ALTER TABLE ADD COLUMNしたら、秒でRedshiftへも同期される。 - 逆に、
ALTER TABLE DROP COLUMNでカラム削除しても同様に秒でRedshiftへも同期される。
CREATE TABLE my_db.product (
product_id INT PRIMARY KEY,
name VARCHAR(50),
price INT
);
ALTER TABLE my_db.product
ADD COLUMN dammy VARCHAR(20);
ALTER TABLE my_db.product
DROP COLUMN dammy;
ALTER TABLE my_db.product
ADD COLUMN dammy1 VARCHAR(20),
ADD COLUMN dammy2 VARCHAR(20);
ただし、MySQL側でADD COLUMNとDROP COLUMNを同時に実行すると、Redshift側ではサポートされていない旨のエラーが出たため、分けて実行する必要がありそう。
ALTER TABLE my_db.product
ADD COLUMN dammy VARCHAR(20),
DROP COLUMN price;
内部テーブルとの結合とマテリアライズドビュー
- 内部テーブルを管理するdatebaseのテーブルと、Zero-ETL統合したdatabaseのテーブルは自由にJOINできた
- Zero-ETL統合したdatabaseのテーブルを組み合わせてマテリアライズドビューも作成できた。
- これが結構有益で、実際に分析で利用する場合は、生データの構成のままというよりデータマート的に再加工するので、それをマテビューで実装すれば、時間とパフォーマンスとストレージの面でもETLそのものの仕組みが変わる
- ちなみにマテビューの作成は、Zero-ETL統合用のdatabaseではなく、書き込みできる通常のdatabaseで行う必要あり
モニタリング
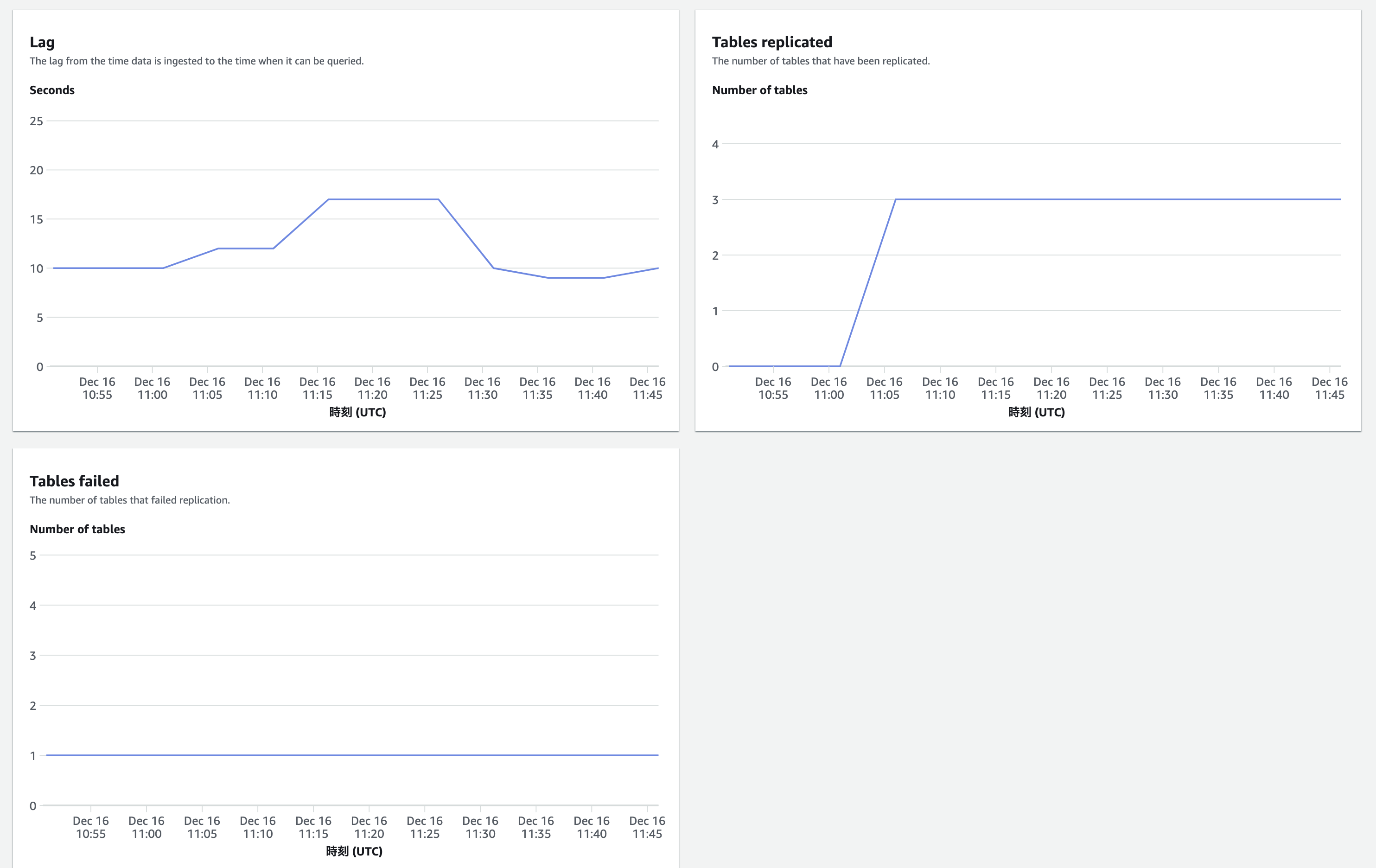
- Redshiftコンソールで、同期のラグ、同期されているテーブル数、同期失敗したテーブル数が見える
- なぜかラグが10 - 17秒と出てるが、体感的にはAuroraでクエリを実行してすぐにRedshiftにクエリ実行すると、ほんの数秒で反映されているように感じる
同期の失敗とデバッグ
同期が失敗するとどうなるか、意図的にやってみる
例として、Redshiftで対応していないデータ型を含むテーブルで試行するため、Auroraで以下を実行
CREATE TABLE my_db.unsupported (
id INT PRIMARY KEY,
bit_col BIT,
binary_col BINARY(10),
varbinary_col VARBINARY(255),
tinyblob_col TINYBLOB,
blob_col BLOB,
mediumblob_col MEDIUMBLOB,
longblob_col LONGBLOB,
tinytext_col TINYTEXT,
text_col TEXT, mediumtext_col MEDIUMTEXT,
longtext_col LONGTEXT,
enum_col ENUM('value1', 'value2'),
set_col SET('value1', 'value2'),
spatial_col POINT
);
参考)
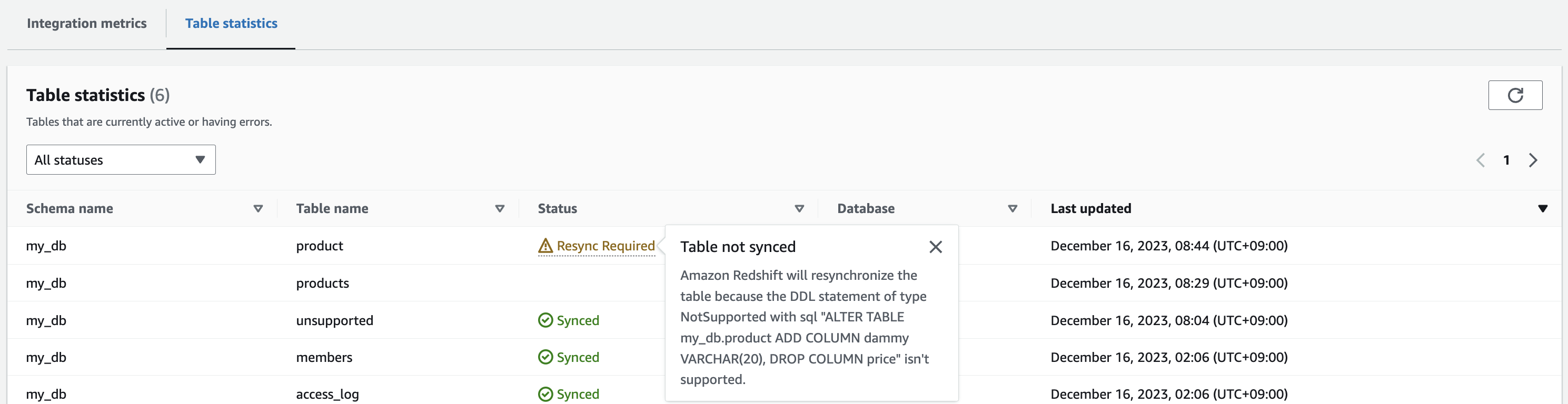
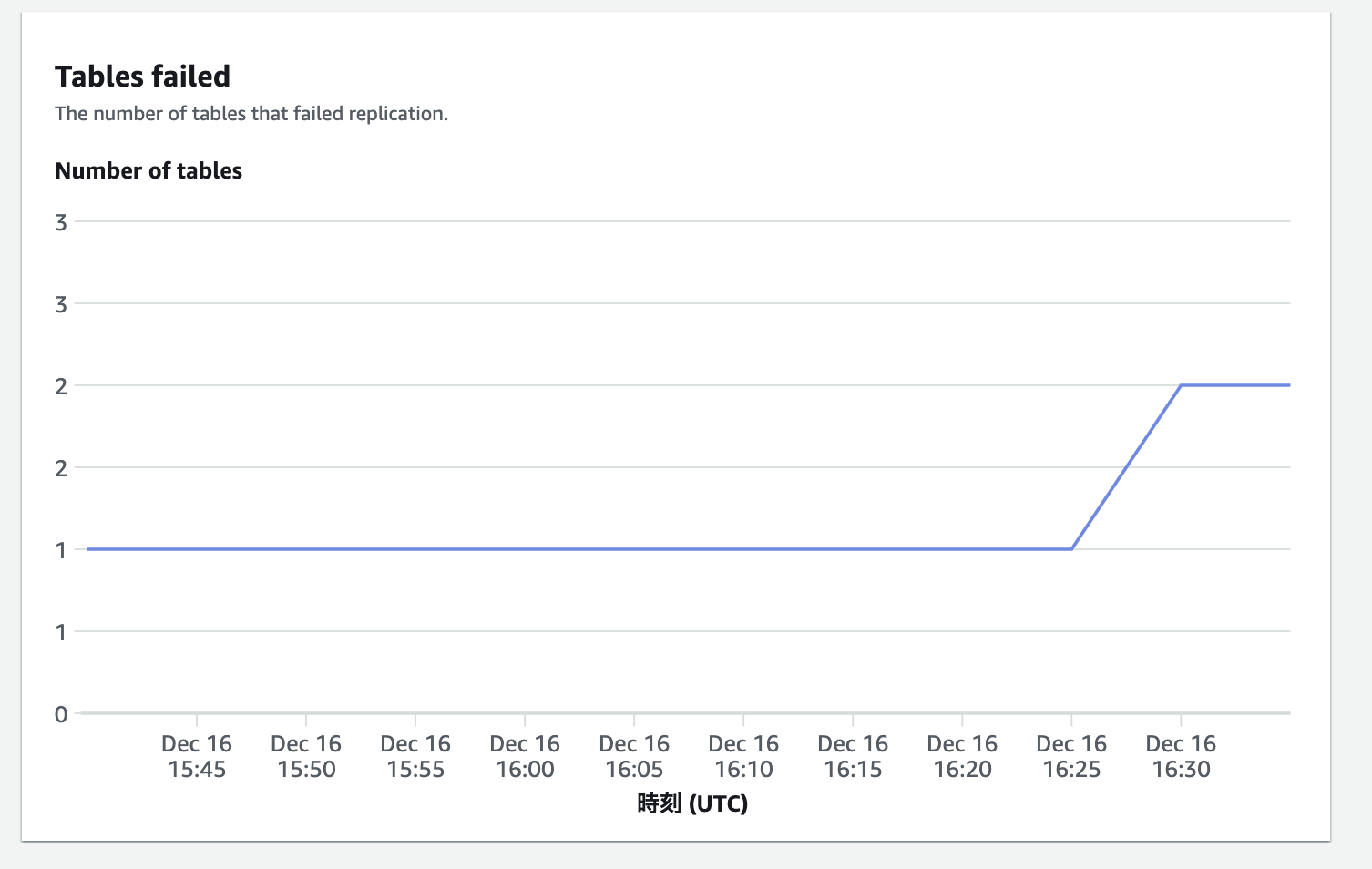
すると、Redshiftダッシュボードで以下の通りエラーとなっていることがわかる
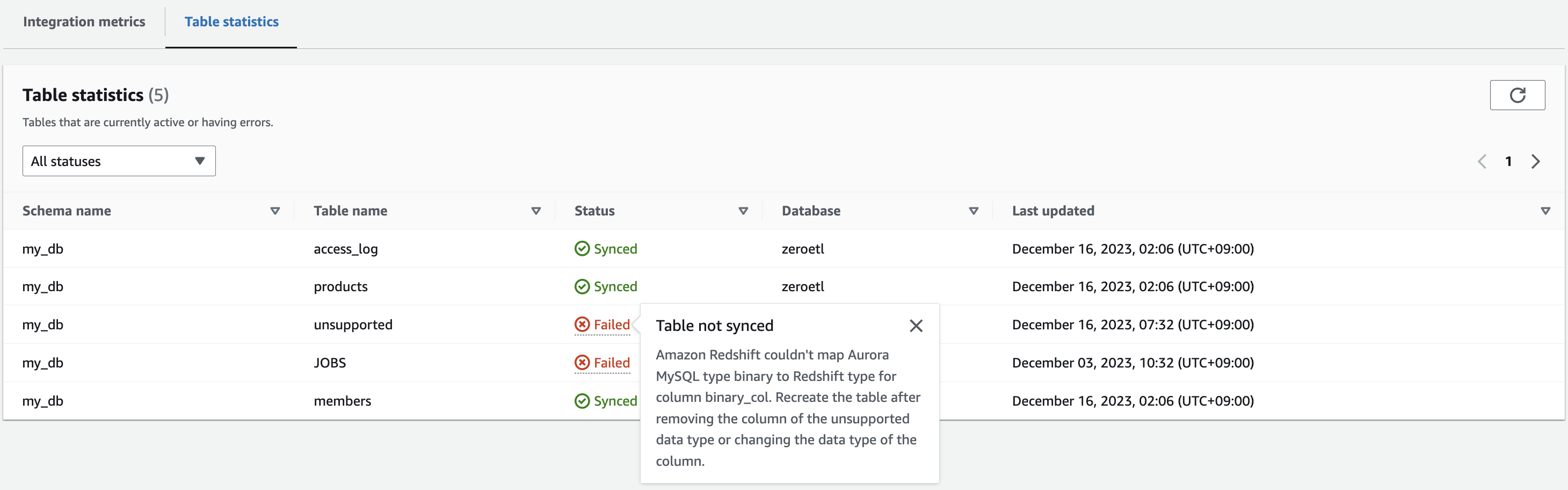
この Failed にマウスオーバーすると以下の理由だとわかる
Table not synced Amazon Redshift couldn't map Aurora MySQL type binary to Redshift type for column binary_col. Recreate the table after removing the column of the unsupported data type or changing the data type of the column.
また、以下のRedshiftシステムビューでもエラーは確認できる。
select * from SVV_INTEGRATION_TABLE_STATE
いろいろ試したところ、2023/12/16時点では以下のデータ型はZero-ETLでエラーとなって同期できなかった
- BINARY
- VARBINARY
- TINYBLOB
- BLOB
- MEDIUMBLOB
- LONGBLOB
- POINT
以下のデータ型はRedshiftでは未対応だが、自動的に型変換されて同期できた
- BIT(→ VARBYTEへ)
- TINYTEXT(→ VARCHARへ)
- MEDIUMTEXT(→ VARCHARへ)
- LONGTEXT(→ VARCHARへ)
- ENUM(→ VARCHARへ)
- SET(→ VARCHARへ)
データ型起因でエラーとなった場合のデバッグ方法は、基本的に元のAurora側のテーブルをDROPして作り直す必要がある模様。ALTER TABLEでデータ型の変換するだけでは再同期は動かなかった。
気になる制約事項
Zero-ETLには 2023/12 時点で以下を含むいくつかの制約事項がある。
-
同期はdatabase単位(テーブル指定はできない) -
AuroraとRedshiftは同じリージョンのみ
-
Zero-ETL統合は一度作成したら変更できないので、再作成が必要
-
AuroraでB/G deployする場合は、まずインテグレーションを削除し、スイッチオーバーした後に再度作成する必要あり
-
Aurora Global DatabaseのプライマリDBクラスタでフェールオーバーした場合、インテグレーションは無効になり、インテグレーションを削除して再度作成する必要がある
-
サポートされないデータ型がいくつか存在する
-
定義済みテーブル更新に関する外部キーリファレンスはサポートされていない。特にON DELETEとON UPDATEルールのCASCADE、SET NULL、SET DEFAULTアクションはサポートされていません。そのような参照を他のテーブルに設定しようとすると、テーブルは失敗状態になります。
-
オブジェクト識別子(データベース名、テーブル名、カラム名など)には
半角英数字、数字、$、アンダースコア(_)のみ使用できる -
ソースDBクラスタはAurora MySQLバージョン3.05.0(MySQL 8.0.32と互換)以降
-
Aurora MySQLのシステムテーブル、一時テーブル、ビューはAmazon Redshiftに複製されない
-
ALTER TABLEパーティション操作は表がAuroraからAmazon Redshiftにデータを再読み込みするため再同期する必要があります。再同期中はその表に対するクエリは使用できません。
コスト観点
Zero-ETL 統合設定追加そのもので追加料金が請求されることはないが、以下は追加になる
- 拡張バイナリログを有効にすることで使用される追加の I/O とストレージ
- Amazon Redshift データベースをシードする際の初期データエクスポート用のスナップショットエクスポートのコスト
- 複製されたデータを保存するための追加の Amazon Redshift ストレージ
- データをソースからターゲットに移動するための AZ 間でデータを転送するコスト
Aurora と Redshift は内部的なアーキテクチャーやデータの持ち方も異なるので、実際に挙動を確認してみても、同じデータセットであってもAurora上のストレージ利用サイズとRedshiftのものでは異なることがあった。ただしコスト観点では、東京リージョンの各サービス単価は以下となっており、ストレージ単価はRedshiftはAuroraの 1/5 〜 1/10 くらいにはなっている。増加分を相殺できるかはケースバイケースだが、ストレージ使用増加分がそのままコスト増には一概にならないとは言えそう。
- Aurora MySQL 標準 : $ 0.12/GB(ストレージ)+ $ 0.24/100万リクエスト(I/O)
- Aurora MySQL IO最適化: $ 0.27/GB(ストレージ)
- Redshift Managed Storage:$ 0.0261/GB
[3] Zero-ETL 設定メモ
Aurora MySQL serverless v2とRedshift ServerlessでZero-ETL統合設定した際のメモ
今回は同一アカウント内で実施したが、クロスアカウントでも実現できる
1. Aurora MySQLの設定
1-1. custom DB cluster parameter group を作成

次にパラメータは以下にセットする
- aurora_enhanced_binlog=1
- binlog_backup=0
- binlog_format=ROW
- binlog_replication_globaldb=0
- binlog_row_image=full
- binlog_row_metadata=full
さらに - binlog_transaction_compression parameter は ON 以外
- binlog_row_value_options parameter は PARTIAL_JSON 以外
1-2. Aurora DB クラスターを作成する
- 今回は GA 版のAUrora MySQLで、バージョンは
Aurora MySQL version 3.05.0 (compatible with MySQL 8.0.32)かそれ以上にする - 2023年10月にGAになったLTS Aurora MySQL 3.04 (MySQL 8.0.28 互換) マイナーバージョンの Amazon Aurora MySQL 互換エディション 3 (MySQL 8.0 互換) は、Zero-ETL 統合非対応な点は注意が必要
- クラスターの作成には通常数分(10〜20分以上)かかる
- Provisioned でも Serverless でもOK
2. Redshift データウェアハウスの設定
2-1. Redshift データウェアハウス を作成する
- 今回はServerless版を普通に作成する
- Provisioned でも Serverless でもOK
2-2. case sensitivity のパラメータを変更
-
enable_case_sensitive_identifierを有効化する - Serverlessではコンソールから変更できないため、AWS CLIで実行する
- コマンドは以下
aws redshift-serverless update-workgroup \
--workgroup-name target-workgroup \
--config-parameters parameterKey=enable_case_sensitive_identifier,parameterValue=true
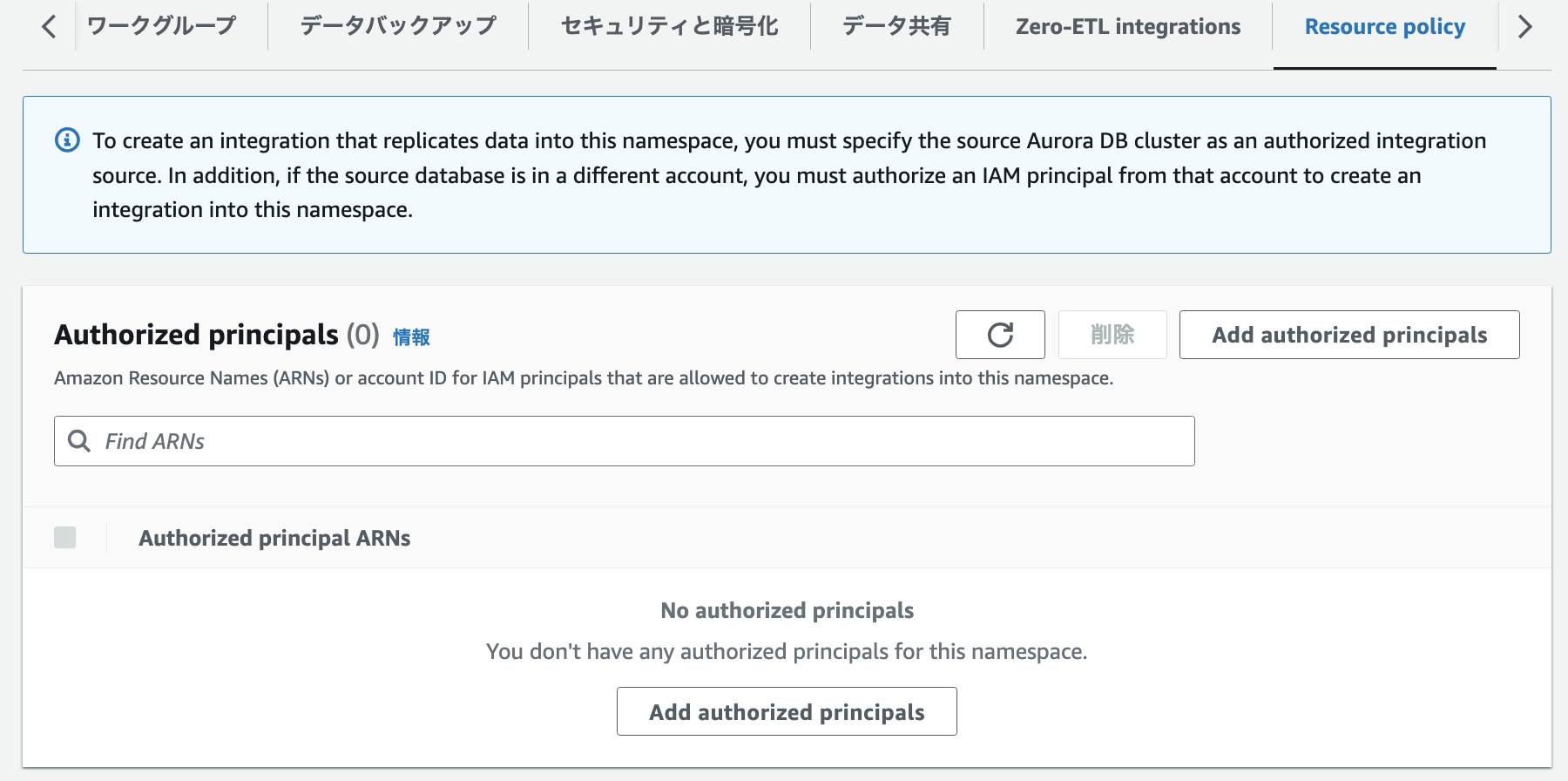
2-3. 権限設定
以下を追加する
- Authorized principal(承認されたプリンシパル)データ ウェアハウスへのゼロ ETL 統合を作成できるユーザーまたはロールを識別します。
とりあえず自身のIAM UserのARNと、自身のAccountID(rootが設定される)をセット
次に以下を追加する
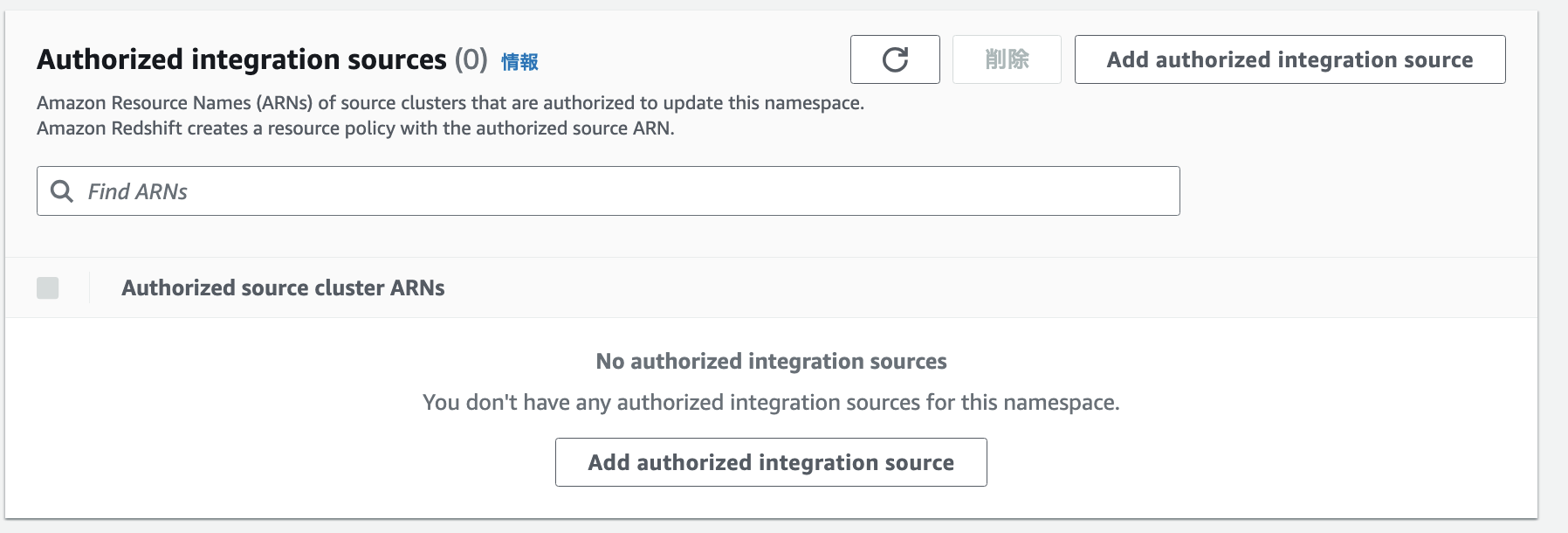
- Authorized integration source(承認された統合ソース) – データ ウェアハウスを更新できるソース データベースを識別します。
さっき作ったAuroraのARNを設定する
3. IAM Policy を設定
Zero ETL統合の設定をする作業者(IAM UserやRole)に対して、操作権限を追加する
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Action": [
"rds:CreateIntegration"
],
"Resource": [
"arn:aws:rds:{region}:{account-id}:cluster:source-db",
"arn:aws:rds:{region}:{account-id}:integration:*"
]
},
{
"Effect": "Allow",
"Action": [
"rds:DescribeIntegrations"
],
"Resource": ["*"]
},
{
"Effect": "Allow",
"Action": [
"rds:DeleteIntegration"
],
"Resource": [
"arn:aws:rds:{region}:{account-id}:integration:*"
]
},
{
"Effect": "Allow",
"Action": [
"redshift:CreateInboundIntegration"
],
"Resource": [
"arn:aws:redshift:{region}:{account-id}:namespace:namespace-uuid"
]
}]
}
4. Aurora MySQL の設定再び
4-1 ゼロETL統合の作成
- コンソールからゼロETL統合を作成する
- 作成完了には10分以上かかる
4-2. テスト用にDBとテーブルを作成する
CREATE DATABASE my_db;
USE my_db;
CREATE TABLE books_table (ID int NOT NULL, Title VARCHAR(50) NOT NULL, Author VARCHAR(50) NOT NULL,
Copyright INT NOT NULL, Genre VARCHAR(50) NOT NULL, PRIMARY KEY (ID));
INSERT INTO books_table VALUES (1, 'The Shining', 'Stephen King', 1977, 'Supernatural fiction');
5. Redshift で ゼロETL統合用のデータベースを定義する
- コンソールからやる方法と、クエリエディタでSQLで実行する方法がある
以上
参考)