お試し用にdockerでspark / spark-shellを触ってみる
全体の流れ
dockerイメージはいろいろあるが、以下を利用
https://github.com/Semantive/docker-spark
docker-composeで master x 1、worker x 2 のdockerベースのsparkクラスタを単一node上に簡単に作れる。
そしてspark-shellで以下のquick startを試す
https://spark.apache.org/docs/latest/quick-start.html
1. dockerでsparkクラスタ立ち上げ
事前にgit、docker/docker-composeがインストールされている必要があるが、その方法は割愛。
手順は、下記サイトからdockerfileをcloneして、docker-compose upするだけ。
https://github.com/Semantive/docker-spark
git clone https://github.com/Semantive/docker-spark.git
cd ./docker-spark/
docker-compose up
しばらくすると、masterとworkerのコンテナが立ち上がる
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
5b391b766cbc semantive/spark "bin/spark-class org…" 2 hours ago Up About an hour 0.0.0.0:8081->8081/tcp dockerspark_worker1_1
12a25ad7a708 semantive/spark "bin/spark-class org…" 2 hours ago Up About an hour 0.0.0.0:8082->8082/tcp dockerspark_worker2_1
ef6cf053d560 semantive/spark "bin/spark-class org…" 2 hours ago Up About an hour 0.0.0.0:4040->4040/tcp, 0.0.0.0:6066->6066/tcp, 0.0.0.0:7077->7077/tcp, 0.0.0.0:8080->8080/tcp dockerspark_master_1
2. spark-shellをたたいてみる
masterノードでspark-shellを実行するだけ
docker exec -it [masterのcontainer id] spark-shell
例)
docker exec -it ef6cf053d560 spark-shell
すると、以下のようにspark-shellが起動し、scalaでインタラクティブに処理を実行できる。
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.1.1
/_/
Using Scala version 2.11.8 (OpenJDK 64-Bit Server VM, Java 1.8.0_131)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
Quick Startを実行してみる
https://spark.apache.org/docs/latest/quick-start.html
scala> val textFile = spark.read.textFile("README.md")
textFile: org.apache.spark.sql.Dataset[String] = [value: string]
scala> textFile.count()
res0: Long = 104
scala> textFile.first()
res1: String = # Apache Spark
scala> val linesWithSpark = textFile.filter(line => line.contains("Spark"))
linesWithSpark: org.apache.spark.sql.Dataset[String] = [value: string]
scala> textFile.filter(line => line.contains("Spark")).count()
res2: Long = 20
else b)textFile.map(line => line.split(" ").size).reduce((a, b) => if (a > b) a
res3: Int = 22
とりあえず動いた。
ちなみに、AWSのt2.microのように、リソーススペックが低すぎると処理が重すぎて動かない可能性あり。
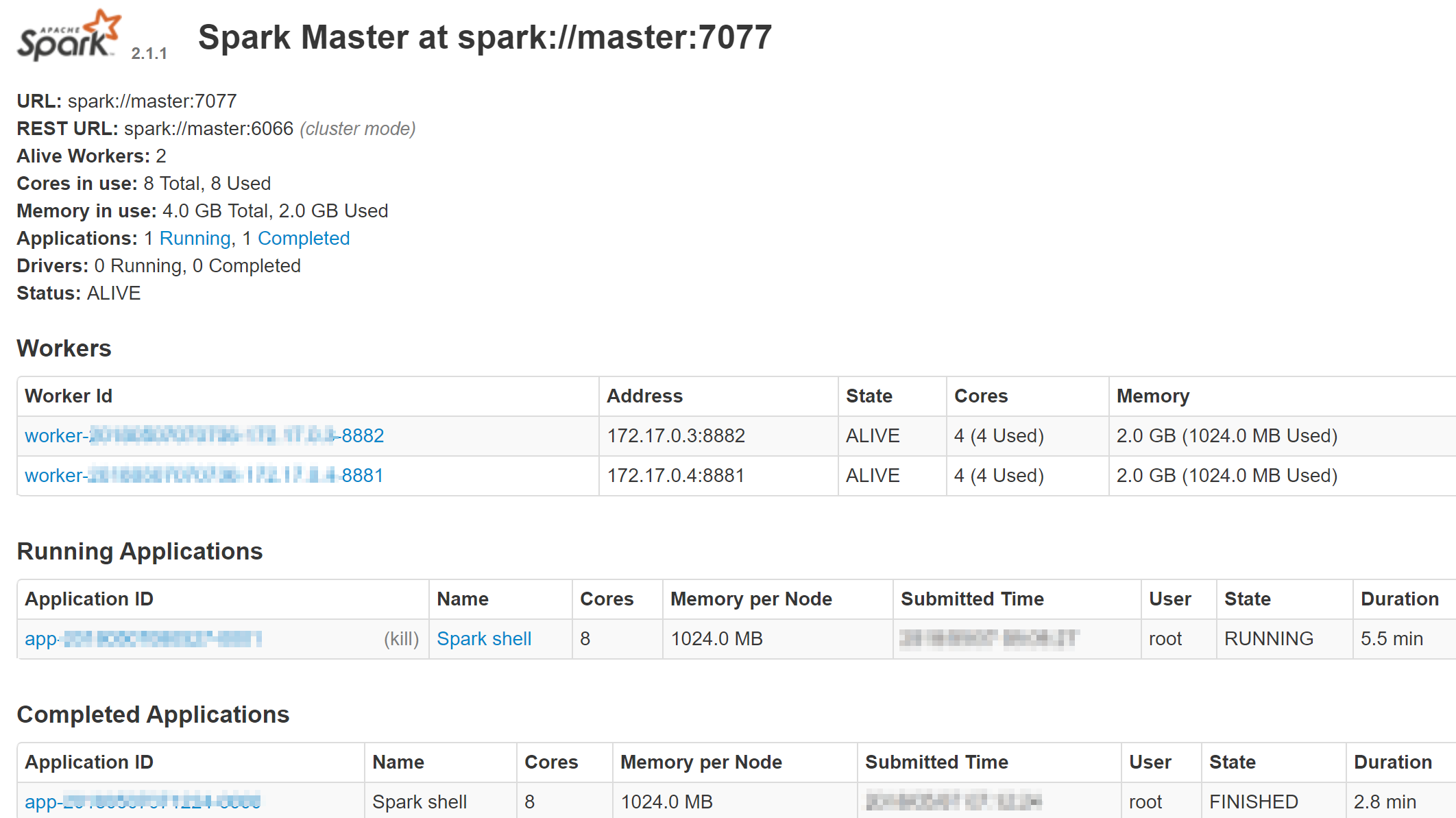
3.モニタリング
http://[host IP]:8080で、Sparkが提供するGUIにもアクセスできる。