python2.7でwordcloudを作成する方法のメモ
AWS Summit 2018 の講演タイトルの頻出単語から、トレンド分析(風)なことをやってみた。
結果はこちら

キーワード的には
・セキュリティ
・機械学習
・IoT
・データ
あたりが上位。
金融やエッジというキーワードも気になるところ。
※結果はややチューニング次第なので、あくまで今回の試行結果です。
Word Cloudの作り方
参考)
https://qiita.com/kenmatsu4/items/9b6ac74f831443d29074
https://qiita.com/nekoumei/items/b1afca7cfb9e54303ab4
試した環境
・OS:Windows 10
・anaconda
・jupyter notebook
・python 2.7
全体の流れ
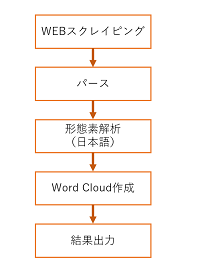
AWSのWEBサイトからセッション情報をGETして、タイトル文のみパースする。
その後日本語文を形態素解析して単語で分離し、それを入力値としてWordCloudを作成する。
最後はその結果を出力する流れ。
使うツール/ライブラリ
・WordCloud(Python用WordCloud作成ライブラリ)
https://amueller.github.io/word_cloud/generated/wordcloud.WordCloud.html
・BeautifulSoup(Python用HTML/XMLパースライブラリ)
https://www.crummy.com/software/BeautifulSoup/bs4/doc/
・MeCab(オープンソース形態素解析エンジン)
http://taku910.github.io/mecab/
・Matplotlib(可視化ライブラリ)
https://matplotlib.org/
ソース
# coding: utf-8
import urllib2
from bs4 import BeautifulSoup
from wordcloud import WordCloud
import MeCab as mc
import matplotlib.pyplot as plt
%matplotlib inline
## WEBスクレイピング + Parse ############
# アクセスURL(AWSのセッションサイト)
url = "https://www.awssummit.tokyo/tokyo_session/session/"
# html取得
html = urllib2.urlopen(url)
# BeautifulSoupで扱う
soup = BeautifulSoup(html, "html.parser")
# タイトルを取得
text = ','.join([e.string for e in soup.find_all("h3")
if e.string!=None and e.name not in ('script','style')])
## 形態素解析 ###########################
# 形態素解析 実行関数
def mecab_analysis(text):
t = mc.Tagger()
enc_text = text.encode('utf-8')
node = t.parseToNode(enc_text)
output = []
while(node):
word_type = node.feature.split(",")[0]
if word_type in ["名詞"]:
output.append(node.surface)
node = node.next
return output
## Word Cloud作成 #######################
# 除外キーワード規定(トレンドと関係なさげな単語を指定。適宜チューニング)
stop_words = [ u'登壇', u'再演', u'同時', u'通訳', u'AWS', u'実現', u'クラウド', \
u'ため', u'Amazon', u'on', u'事例', u'活用', \
u'Tech', u'入門', u'最新', u'利用', u'サービス', u'ベストプラクティス', \
u'パネルディスカッション', u'管理', u'紹介', u'化', u'こと', u'技術', u'株式会社']
# Word Cloud生成
wordcloud = WordCloud(background_color="white",
font_path="msgothic.ttc",
width=1000,height=1000,
max_words=200,
min_font_size=15,
relative_scaling=0.9,
stopwords=set(stop_words)).generate(",".join(mecab_analysis(text)).decode('utf-8'))
# 結果出力1(Matplotlib)
plt.figure(figsize=[20,20])
plt.imshow(wordcloud,interpolation='bilinear')
plt.axis("off")
# 結果出力2(ファイル)
wordcloud.to_file("./wordcloud_sample2_title.png")
Word Cloudに入力する単語の件数を見たい場合は
from collections import Counter
list = mecab_analysis(text)
ctlist = Counter(list).most_common()
for word in ctlist:
print str(word).decode("string-escape")
を加えると、以下のように確認できる。
('事例', 68)
('登壇', 44)
('様', 44)
('活用', 36)
('クラウド', 30)
('入門', 28)
:
はまりどころ
主に、形態素解析(MeCab)で色々はまったメモ
[1] MeCabのインストール/環境設定
anaconda navigatorからターミナルを起動してpipで入れようとしても下記のエラーに。
>pip install mecab
Collecting mecab
Could not find a version that satisfies the requirement mecab (from versions: )
No matching distribution found for mecab
>pip install mecab-python
Collecting mecab-python
Using cached https://files.pythonhosted.org/packages/86/e7/bfeba61fb1c5d1ddcd92bc9b9502f99f80bf71a03429a2b31218fc2d4da2/mecab-python-0.996.tar.gz
Complete output from command python setup.py egg_info:
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "c:\users\optim\appdata\local\temp\pip-install-hmqt9j\mecab-python\setup.py", line 13, in <module>
version = cmd1("mecab-config --version"),
File "c:\users\optim\appdata\local\temp\pip-install-hmqt9j\mecab-python\setup.py", line 7, in cmd1
return os.popen(str).readlines()[0][:-1]
IndexError: list index out of range
----------------------------------------
Command "python setup.py egg_info" failed with error code 1 in c:\users\optim\appdata\local\temp\pip-install-hmqt9j\mecab-python\
色々試行錯誤し、以下の辞書データを含むインストーラ実行で成功した(気がする)
https://github.com/ikegami-yukino/mecab/releases/tag/v0.996
また、Windows側の環境変数でPathの設定も必要
例)
C:\Program Files\MeCab\bin
[2] ユーザ辞書の追加
「EC2」が ECと2で別れたり、IoTを名詞として含めなかったりしたので、ユーザ辞書を追加して補完。
参考)
http://fqz7c3.hatenablog.jp/entry/2013/07/27/193232
手順)
①C:\Program Files\MeCab\dic\ipadic\user.csv を作成
例えばこんな感じ
データサイエンティスト,-1,-1,1000,名詞,一般,*,*,*,*,データサイエンティスト,データサイエンティスト,データサイエンティスト
機械学習,-1,-1,1000,名詞,一般,*,*,*,*,機械学習,キカイガクシュウ,キカイガクシュウ
EC2,-1,-1,1000,名詞,一般,*,*,*,*,EC2,イーシーツー,イーシーツー
可視化,-1,-1,1000,名詞,一般,*,*,*,*,可視化,カシカ,カシカ
クラウド,-1,-1,1000,名詞,一般,*,*,*,*,クラウド,クラウド,クラウド
ベストプラクティス,-1,-1,1000,名詞,一般,*,*,*,*,ベストプラクティス,ベストプラクティス,ベストプラクティス
パネルディスカッション,-1,-1,1000,名詞,一般,*,*,*,*,パネルディスカッション,パネルディスカッション,パネルディスカッション
Deep Dive,-1,-1,1000,名詞,一般,*,*,*,*,Deep Dive,ディープダイブ,ディープダイブ
生産性,-1,-1,1000,名詞,一般,*,*,*,*,生産性,クラウド,クラウド
バックエンド,-1,-1,1000,名詞,一般,*,*,*,*,バックエンド,バックエンド,バックエンド
コンタクトセンター,-1,-1,1000,名詞,一般,*,*,*,*,コンタクトセンター,コンタクトセンター,コンタクトセンター
コンサル,-1,-1,1000,名詞,一般,*,*,*,*,コンサル,コンサル,コンサル
IoT,-1,-1,1000,名詞,一般,*,*,*,*,IoT,アイオーティー,アイオーティー
Alexa,-1,-1,1000,名詞,一般,*,*,*,*,Alexa,アレクサ,アレクサ
Serverless,-1,-1,1000,名詞,一般,*,*,*,*,Serverless,サーバーレス,サーバーレス
DevOps,-1,-1,1000,名詞,一般,*,*,*,*,DevOps,デブオプス,デブオプス
ワークロード,-1,-1,1000,名詞,一般,*,*,*,*,ワークロード,ワークロード,ワークロード
②コマンドプロンプトで以下実行
>cd C:\Program Files\MeCab\dic\ipadic
>mecab-dict-index -f utf-8 -t utf-8 -u user.dic user.csv
以下となればOK
reading user.csv ... 17
emitting double-array: 100% |###########################################|
done!
[3] 記号が名詞扱いに(ゴミを除去)
「【 」とか記号が名詞としてカウントされてしまう問題対策
参考)
http://nymemo.com/mecab/564/
C:\Program Files\MeCab\dic\ipadic\unk.def
を以下の通り編集する。
before)
SYMBOL,1283,1283,17585,名詞,サ変接続,*,*,*,*,*
after)
SYMBOL,1283,1283,17585,記号,一般,*,*,*,*,*
最後に辞書を再読み込み
>cd C:\Program Files\MeCab\dic\ipadic
>mecab-dict-index
[4] python文字エンコード
utf-8 と string などのエンコードで出力が文字化けするケースが多い。
標準出力する際は、ケースバイケースだが以下対処で解消。
str(word).decode("string-escape")