Rancher(v2.2.3)で AWS EC2上に Kubernetes クラスタ構築のメモ。
[1] そもそもRancherとは

・Kubernetesクラスタをはじめとした各種OSSの構築・運用を一元的に行える管理ツール
・(米)Rancher Labs社が開発するOSS
・無料のOSS版は全機能利用可能らしく、別途有料のエンタープライズサポートサービスがある。
・2014年に初版リリースされ、当初複数のコンテナオーケストレーションツールをサポートしていたが、2017年のRancer2.0で、k8sベースのマルチクラウド対応特化に生まれ変わった。
・国内でもNTT Com社、LINE社、CyberAgent社、リクルートテクノロジーズ社など多くの企業で導入されてるようです
k8sクラスタ構築のサービスやツールは他にも各種出てます。
例えば本家GCPならGKE、AWSならEKS、PaaS系ならPKS、ツール系ならKubeadmやKOPSなど様々。
そんな中Rancherは、個人的な所感としては「カタログ」機能で、PrometheusやGrafana、Helmのような実運用する上で必要となる周辺のツール群もセットでかつ容易にセットアップして管理できる点が大きな魅力かと感じます。
k8sは様々なツール群のエコシステムでなりなっているので、全部個別にセットアップして管理するのはかなりタフです。
さらに、etcdやk8s masterの冗長化も簡単に組み込める点(HA構成の考慮)も大きな魅力かと思います。
Rancher公式
https://rancher.com/
GitHub
https://github.com/rancher/rancher
参考
[2] とりあえずRancherでk8sクラスタを立てる
①はじめに
RancherはGUIを有するRancherサーバと、k8sクラスタサーバがあり、今回はRancherサーバ用のEC2と、k8sクラスタ(master/worker兼用の1node構成)用のEC2の計2台で構築。

基本的にすべてのコンポーネントはdockerコンテナで構築されるので、EC2は基本dockerさえ入っていればOK。
ClusterノードのRancherは、Rancherサーバとやりとりするエージェンドが稼働する。またk8sもhyperkubeでコンテナベースで起動される。
環境情報
EC2: Amazon Linux2 m5.large
Rancher: version 2.2.3
docker: version 18.06.1-ce
②Rancherセットアップ
※dockerセットアップ方法は省略
dockerインストール済みインスタンスで下記実行するのみ
sudo docker run -d --restart=unless-stopped -p 80:80 -p 443:443 --privileged rancher/rancher
ブラウザアクセスすると、Rancher GUI画面にアクセスできる。
初回はadminアカウントが生成されており、パスワードを設定すればログインできる。

adminパスワードを忘れた場合
adminパスワードを忘れた場合はrencherサーバのホスト上で、下記を実行するとリセットされる(ランダムpwdが再発行される)
docker exec -ti <rancher server container_id> reset-password
③k8sクラスタ作成
ログイン後の画面の「Add Cluster」メニュー
Add Clusterで「Custom」を選択

クラウドサービスの選択肢もあるので、ゼロの状態からマネージドサービスを活用したクラスタの作成や、新規ノード作成も含めた構築もできるが、
今回のようにホスト(EC2)を立てた状態からのスタートの場合は「Custom」。
オンプレサーバでの構築の場合もおそらく同じ。

次にクラスタ名を入れて、k8sバージョンを選択。
さらにオーバーレイネットワークのツールを選択。ざっくり言うと、k8sノード間のコンテナ間通信で仮想ネットワークを構成する機能。
いろいろあるが、Flannelを選択。
最後のCustom ProviderはNoneを選択。

最後に、クラスタを構築するホストサーバ上で実行するためのコマンドを生成する。
Rancherは、Rancherサーバで生成するコマンドを、k8sクラスタに組み込みたいホストサーバで実行するだけで、Rancherエージェントが起動しノードをRancherサーバに登録することで、一元管理可能なk8sクラスタを構築できる便利物。
「Node Option」の「show advanced option」で詳細表示にして、k8sクラスタ用EC2のプライベートIP(Internal Address)を設定する。
Node Roleでは、「etcd」「controll plane」「Worker」すべてにチェックをつける。
各Roleを分離したい場合は、分けてコマンドを生成して実行するだけで、ホスト分散ができるイメージ。
以下のようなコマンドが生成される。
この時、--serverはデフォルトではrancherサーバのグローバルIPが指定されているが、Private IPに手動で変更することも可能。
sudo docker run -d
--privileged
--restart=unless-stopped
--net=host
-v /etc/kubernetes:/etc/kubernetes
-v /var/run:/var/run rancher/rancher-agent:v2.2.3
--server https://172.16.0.10
--token xxxxxxxx
--ca-checksum xxxxxxxx
--internal-address 172.16.0.20
--etcd
--controlplane
--worker
この画面を表示したまま、このコマンドをk8sクラスタ用EC2で実行し、Rancherサーバが認識すると、
「1 new node has registered」
と表示されるので「Done」を押して完了
クラスタ用のホストサーバ上でdocker psで確認すると以下のようなコンテナが立ち上がっている。
a1896a96de66 rancher/hyperkube:v1.13.5-rancher1 "/opt/rke-tools/entr…" About an hour ago Up About an hour kube-proxy
df7f65730a93 rancher/hyperkube:v1.13.5-rancher1 "/opt/rke-tools/entr…" About an hour ago Up About an hour kubelet
356dc597c277 rancher/hyperkube:v1.13.5-rancher1 "/opt/rke-tools/entr…" About an hour ago Up About an hour kube-scheduler
478128e7a70a rancher/hyperkube:v1.13.5-rancher1 "/opt/rke-tools/entr…" About an hour ago Up About an hour kube-controller-manager
04577fca9103 rancher/hyperkube:v1.13.5-rancher1 "/opt/rke-tools/entr…" About an hour ago Up About an hour kube-apiserver
2f0087e09a03 rancher/coreos-etcd:v3.2.24-rancher1 "/usr/local/bin/etcd…" About an hour ago Up About an hour etcd
747414e88256 rancher/rancher-agent:v2.2.3 "run.sh --server htt…" About an hour ago Up About a minute jovial_brahmagupta
5770e05cc24b rancher/rancher-agent:v2.2.3 "run.sh --server htt…" About an hour ago Up About an hour boring_clarke

StateがActiveになればOK
④k8s動作確認
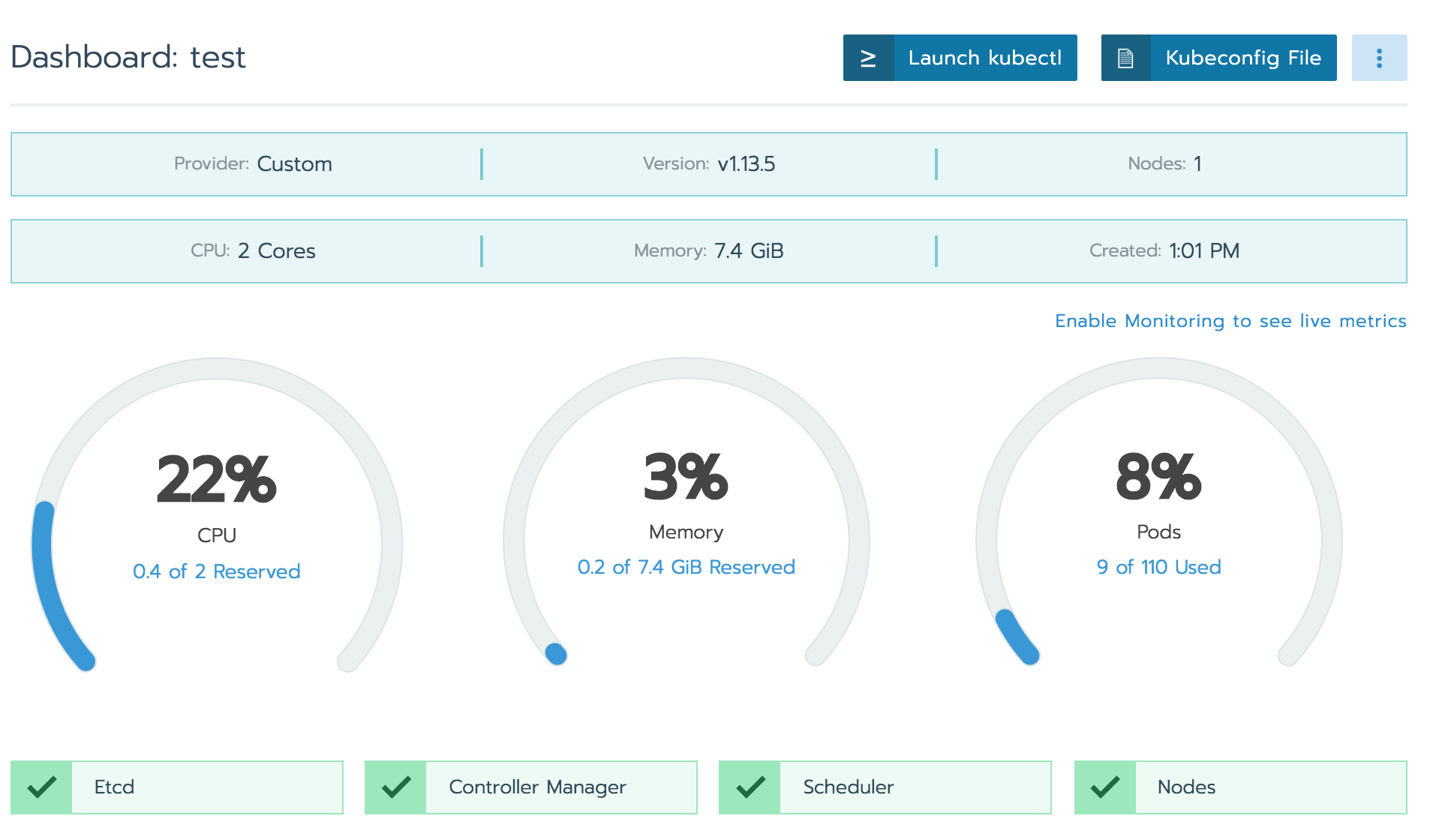
クラスタのリソースモニターも標準で確認可能。

ダッシュボードの「Launch kubectl」もしくは「Kubeconfig File」からdownloadしたconfigを設定したクライアントから、kubectlコマンドを実行できる。
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
ip-172-16-0-20 Ready controlplane,etcd,worker 96m v1.13.5
試しにnginx podを立てる
$ kubectl create deployment --image nginx my-nginx
deployment.apps/my-nginx created
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
my-nginx-6cc48cd8db-f4nd6 1/1 Running 0 9s
[3] 機能拡張とカタログ
モニタリング
煩雑な設定なしに、「Tools」 - 「Monitoring」の設定をenableにするだけで、k8sモニタリングのデファクト「grafana」が利用できる。
Rancherダッシュボードでもサマリー出力されるが、grafanaアイコンで別途grafanaが起動し、詳細モニターを閲覧可能。


GrafanaでPod単位のリソース消費量も確認できるので便利。

ロギング
Rancherが対応しているロギングツール一式。
k8sクラスタの各ノードのログを収集する仕組みを設定できる。

[4] workerノードの追加
先ほどの1node k8sクラスタにworkerノードを追加する方法。
dockerインストールしたEC2を、同じセグメントに設置して、
先ほど同様にホスト上でコマンドを実行するのみ。
差分は、
--internal-addressオプションが、該当ホストのIPであることと
node roleは、--workerオプションをつける点。
sudo docker run -d
--privileged
--restart=unless-stopped
--net=host
-v /etc/kubernetes:/etc/kubernetes
-v /var/run:/var/run rancher/rancher-agent:v2.2.3
--server https://172.16.0.10
--token xxxxxxxx
--ca-checksum xxxxxxxx
--internal-address [追加するノードのIP]
--worker
[5] はまりどころ
Case1 : Etcd Cluster is not healthy
クラスタ構築を何度か試したところ、以下のエラーが発生
[etcd] Failed to bring up Etcd Plane: [etcd] Etcd Cluster is not healthy
どうやらゴミをちゃんと掃除しないといけないらしい。
下記サイトの「Cleaning a Node Manually」の手順を実行し、再度クラスタ作成をしたところエラーは解消。
Case2 cattle-cluster-agent CrashLoopBackOff
cattle-cluster-agentとcattle-node-agentというPodが再起動を繰り返す。
NAMESPACE NAME READY STATUS RESTARTS AGE
cattle-system cattle-cluster-agent-xxxxx 0/1 CrashLoopBackOff 40 4h31m
cattle-system cattle-node-agent-xxxxx 1/1 Running 17 98m
cattle-system cattle-node-agent-xxxxx 0/1 CrashLoopBackOff 40 4h31m
logを見てみたところ、k8sのノードから、RancherサーバのグローバルIPへの通信でタイムアウトしていた模様。
デフォルトではRancherサーバのグローバルIPが、各種制御のエンドポイントになっている様で、各nodeから443(HTTPS)のアクセス制御を許可する必要がある。
$ kubectl -n cattle-system logs cattle-cluster-agent-6fbc6f6b68-68l8l
INFO: Environment: CATTLE_ADDRESS=X.X.X.X CATTLE_CA_CHECKSUM=xxxxx CATTLE_CLUSTER=true CATTLE_INTERNAL_ADDRESS= CATTLE_K8S_MANAGED=true CATTLE_NODE_NAME=cattle-cluster-agent-xxxxx CATTLE_SERVER=https://[RancherサーバのグローバルIP]
INFO: Using resolv.conf: nameserver X.X.X.X search cattle-system.svc.cluster.local svc.cluster.local cluster.local ap-northeast-1.compute.internal options ndots:5
ERROR: https://[RancherサーバのグローバルIP]/ping is not accessible (Failed to connect to [RancherサーバのグローバルIP] port 443: Connection timed out)
k8sの各workerから、RancherサーバのグローバルIP(エンドポイント)への443(HTTPS)を許可することで問題解消。
Case3 : Monitoring API is not ready
Toolsの「Cluster Monitoring Configuration」をenableにしたのに、dashboardで「Monitoring API is not ready」とアラート表示。
Case2同様の原因。同じ対処で問題解消。
Case4 : kubectl Closed Code: 1006
「Launch kubectl」でRancherのダッシュボード上からkubectlコマンドを実行しようとすると、何の反応もなく、「Closed Code: 1006」などのエラーに。
k8sノードとのコネクションに問題がある。
Case2同様の原因。同じ対処で問題解消。
Case5 adminユーザのパスワード忘れ
adminユーザパスワードは下記でリセット可能
docker exec [RancherサーバのコンテナID] reset-password
ランダム文字列のパスワードが出力される
Case6 Failed to obtain metrics.

prometheusからのメトリクス収集でエラーとなっている模様。
workerで稼働している「k8s_prometheus_prometheus-cluster-monitoring-0_XXX」という名前のコンテナの各logを確認すると、
context deadline exceededとか、
only allow maximum 512 connections with 5m0s read timeoutとか、
http: proxy error: context canceledとか
いろいろ出ていた。
クラスタ再起動や作り直しをした過程のゴミの可能性もあったので
下記手順でホストを掃除し、作り直したところ、とりあえず問題解消。