UEアドカレ2023 21日目の記事です。
LearningAgent爆誕
LearningAgentはUE5.3から利用可能な機械学習ってやつでAIをトレーニングする仕組みです。
C++を全く使わずにBPだけで試せるのでスーパーお気軽な環境です!ミドルウェアやライブラリなどのセットアップも不要です。
興味が沸いた方は今すぐUE5.3をダウンロードして下のリンクにあるチュートリアルをパパっとやるだけで、華麗にサーキットを自動運転する車を観察しながらティータイムを楽しむことが出来たりします。
チュートリアルは想定外のトラブルさえがなければ1時間以内で完走できます。
基本的にBPをコピーしていくだけなのであまりミスりようがないのですが、自分はトップビューでスプラインの調整をしていてトラックのスプラインがコースから浮いているのに気づかず無駄な時間を過ごしました。
辛かったです。(どうでもいい感想)

↑ スプラインが浮いてる。。。
LearningAgentがあまりにも素敵だったのでこれをベースにしてちょっと遊んでみようというのが今回の記事の趣旨になります。
マネキン君をLearningAgentで華麗にジャンプできるようにしたい!
事の発端はこのAdversarial Reinforcement Learning for PCG というEA様の研究をFGDCの勉強会で紹介していただいて、あっ!これLearningAgentでできそう!!と思ったことです。(あふれ出る素人感)
ということでチャレンジしてみます
LearningAgentとか強化学習のふわっとした解説
強化学習
エージェント(=学習対象となるアクター)の周囲の環境やエージェント自身の状態とエージェントがとりうるアクションを定義し、初めはランダムに動いているエージェントの行動に対して評価を与えることで、知覚表現とアクションの関連性を深層学習ってやつで自動的に見つけ出して関連付ける仕組みです。
知覚表現とアクションはなんとなく関連性のある情報を与えてあげる必要があります。
LearningAgent
LearningAgentは以下の組み合わせで実行されます
- LearningAgentIntractor
環境に対する知覚表現とエージェントがとりうるアクションを組み合わせたブループリント - LearningAgentsTrainer
トレーニングに対する報酬と終了条件を記述するブループリント - LearningAgentsManager
トレーニングのセットアップなどを記述するブループリント - LearningAgentsNeuralNetwork
学習内容を保存するコンテナ。超巨大なアフィン変換マトリックスの配列(ふわっとした個人的な認識) - そのた設定ファイル
LearningAgentsPolicyとか
実装の紹介 (Learning to Driveとの差分)
ThirdPersonテンプレートをベースにしてLearning to Driveと同じような構成で実装します。
IntratorとTrainer以外はほとんど同じで調整等はしていません。
なおこれが一般的に良い実装というわけではなくほとんど何も考えずにつくったものです。論文や資料なども追っていないので、すでに標準的な構造などがあったりするのかもしれません。そういう情報をお持ちのつよつよマンは優しく教えてくれると嬉しいです。一緒にUEDeepLearningDeepDiveをやりましょうw
Intractor
EventSetupObservations
観測対象をセットアップします
- 周辺のレイトレース情報
- 移動速度
- ゴール方向
を今回は選択しています。
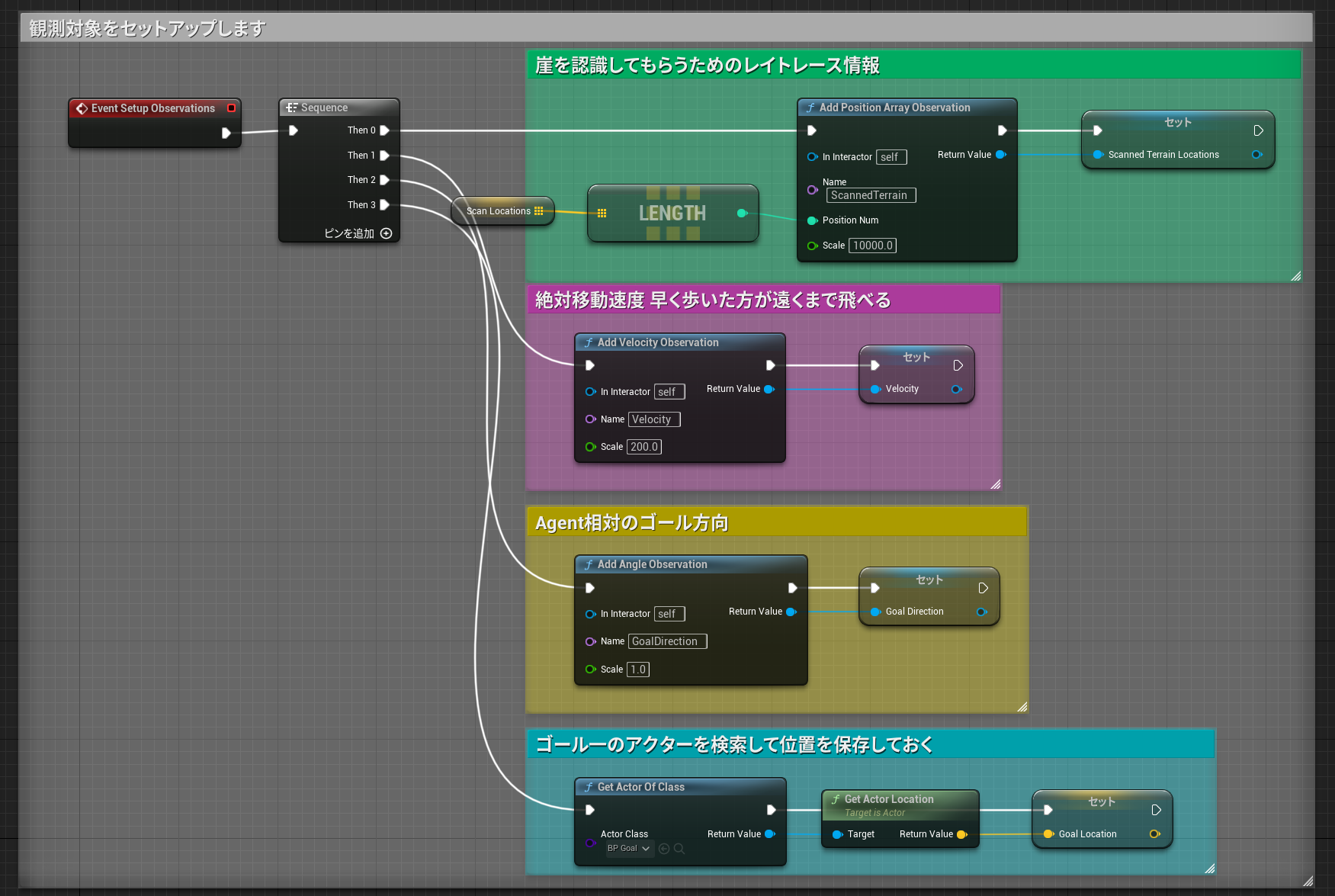
Event SetObservations
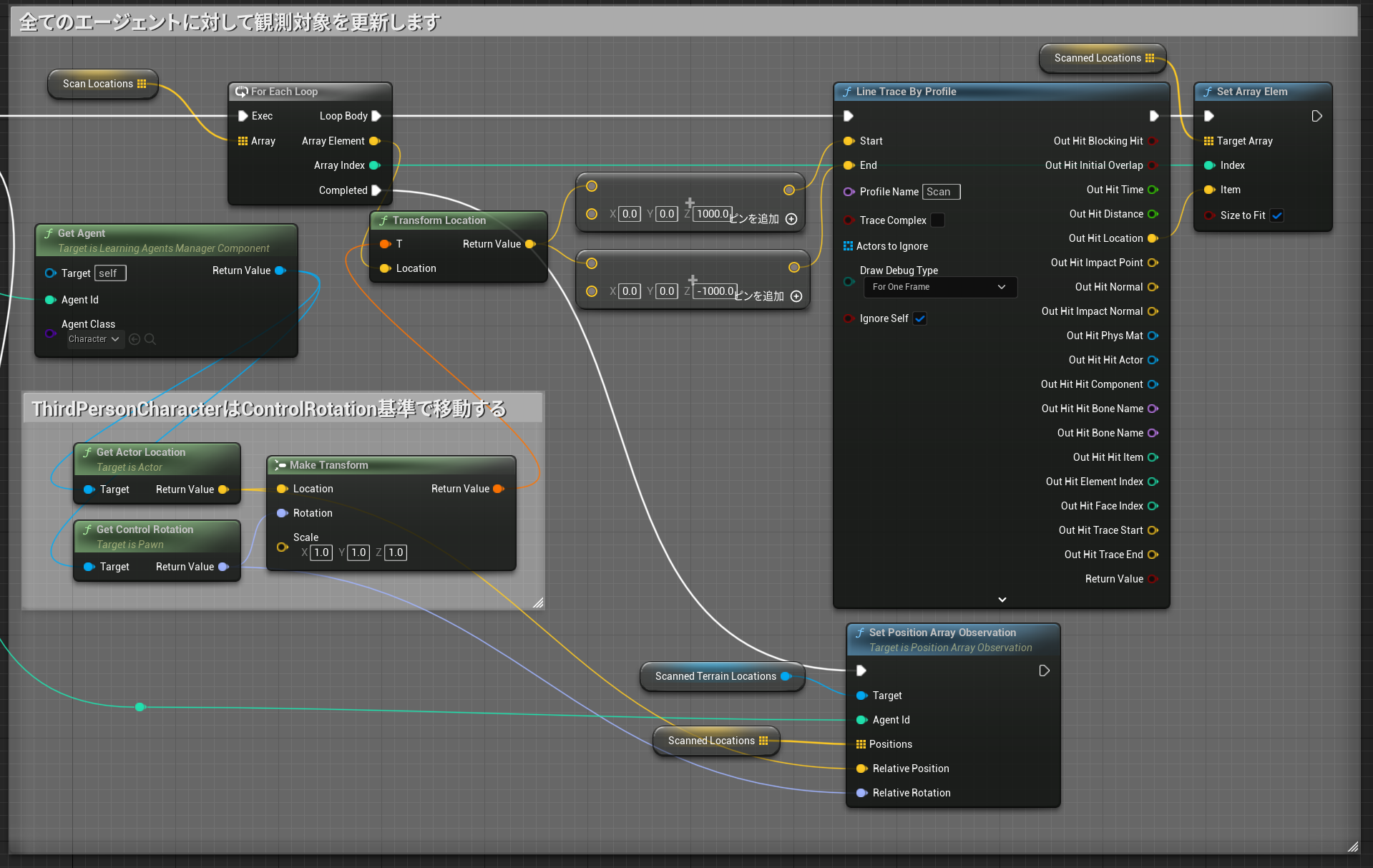
各エージェントに対して観測データを加工して渡してあげます
周辺のレイトレース情報更新
コントロールローテーション相対で固定のオフセット位置を垂直にトレースしてヒット位置を渡します。
LearningAgent君が崖や飛び越えることが出来る崖の深さを学習してくれると期待
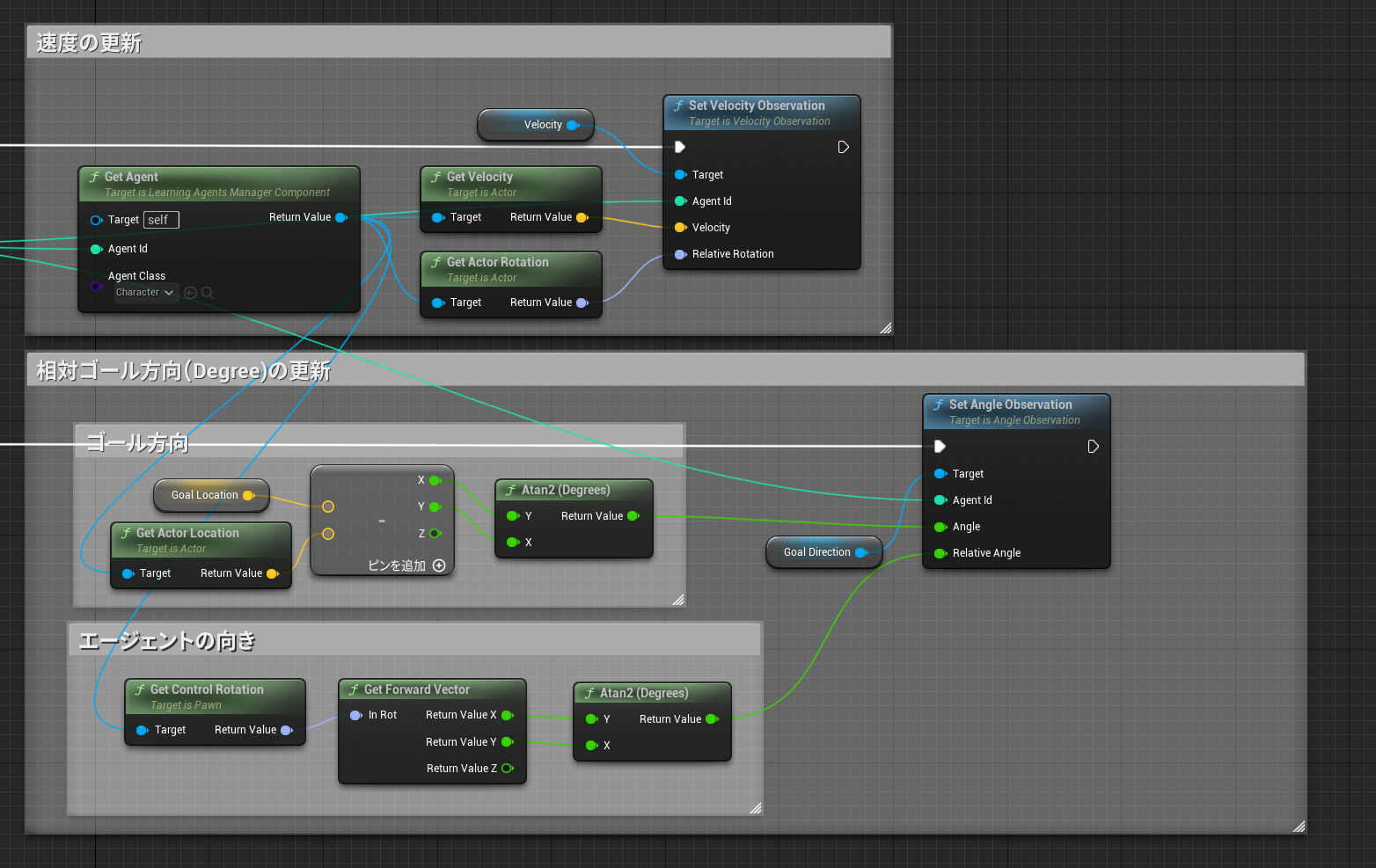
速度と相対ゴール方向
ジャンプする時の判断材料として速度を、ゴール方向にむかってくれないと話にならないので相対ゴール方向を計算して与えます。
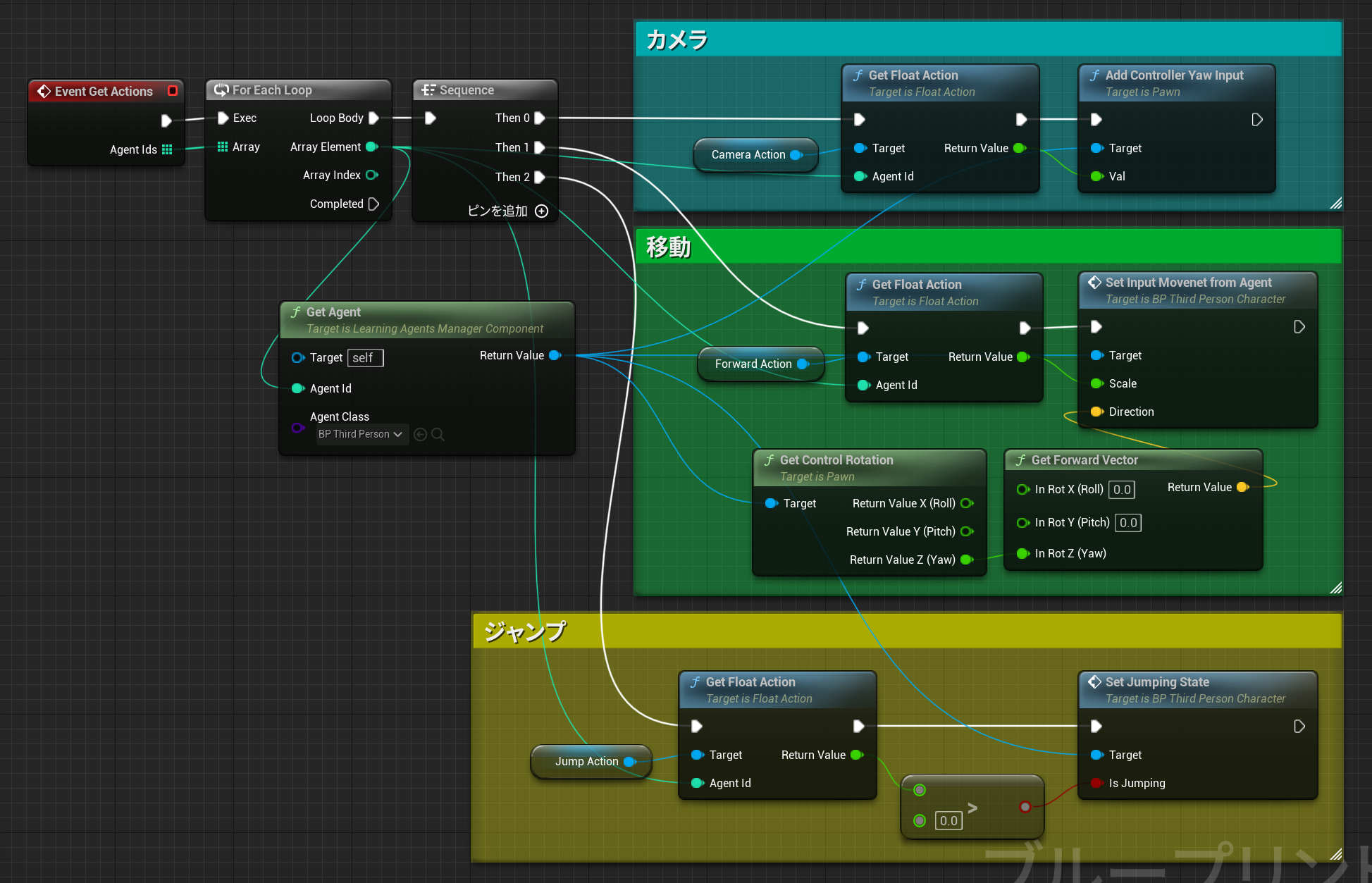
EventSetupActions
エージェントが行えるアクションを定義します。
-カメラの水平回転
エージェントの移動方向はカメラが決めています
-移動
前進後退だけです。横方向には移動しません
-ジャンプ
ジャンプするかどうかです value > 0 でジャンプします

EventGetActions
深層学習での出力となるアクションを取り出してエージェントに適用します
※BP_ThirdPersonCharacter側の改変
移動入力処理はTick毎に入力されて消費されてしまいます。
LearningAgentはAI処理にインターバルを入れることで効率よく動作するので、アクションをPawn側のTickで適用するようにする必要があります。
こうしないとPawnがぴくぴくとしか動くなくなってしまいます。
外部に公開した関数
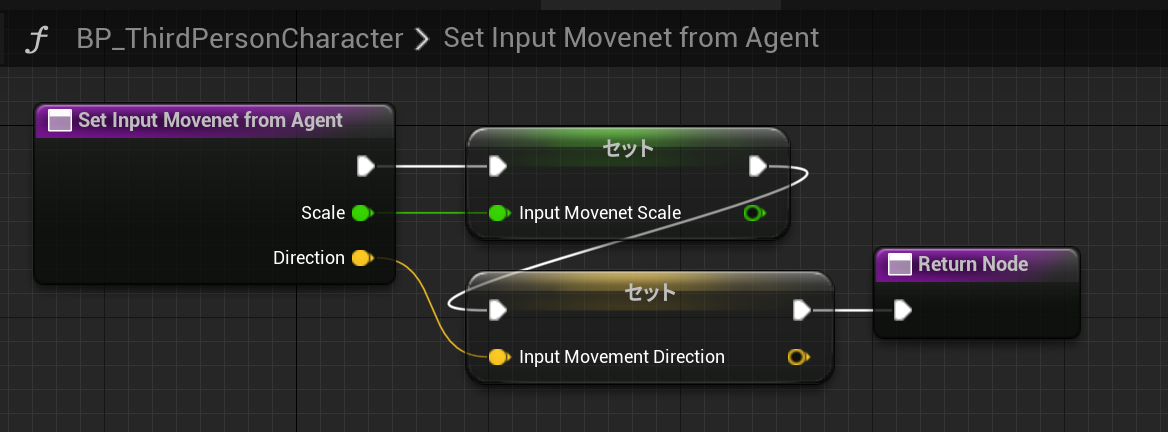
毎tick適用
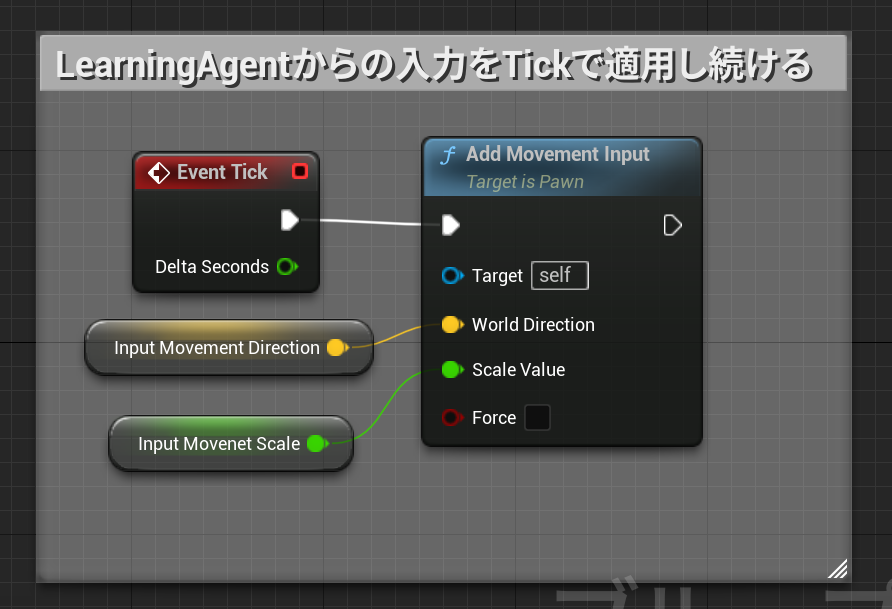
Trainer
EventSetupReward
報酬として以下を定義しています。
-ゴールへの距離
-ゴール方向を考慮した速度
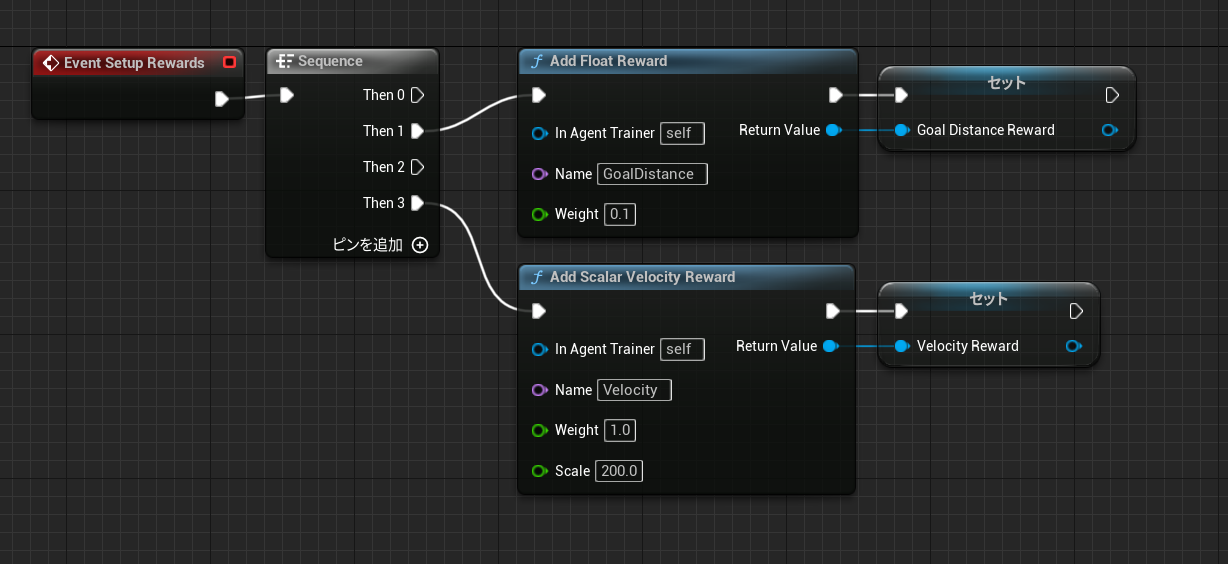
EventSetRewards
各エージェントの報酬を計算して与えます。
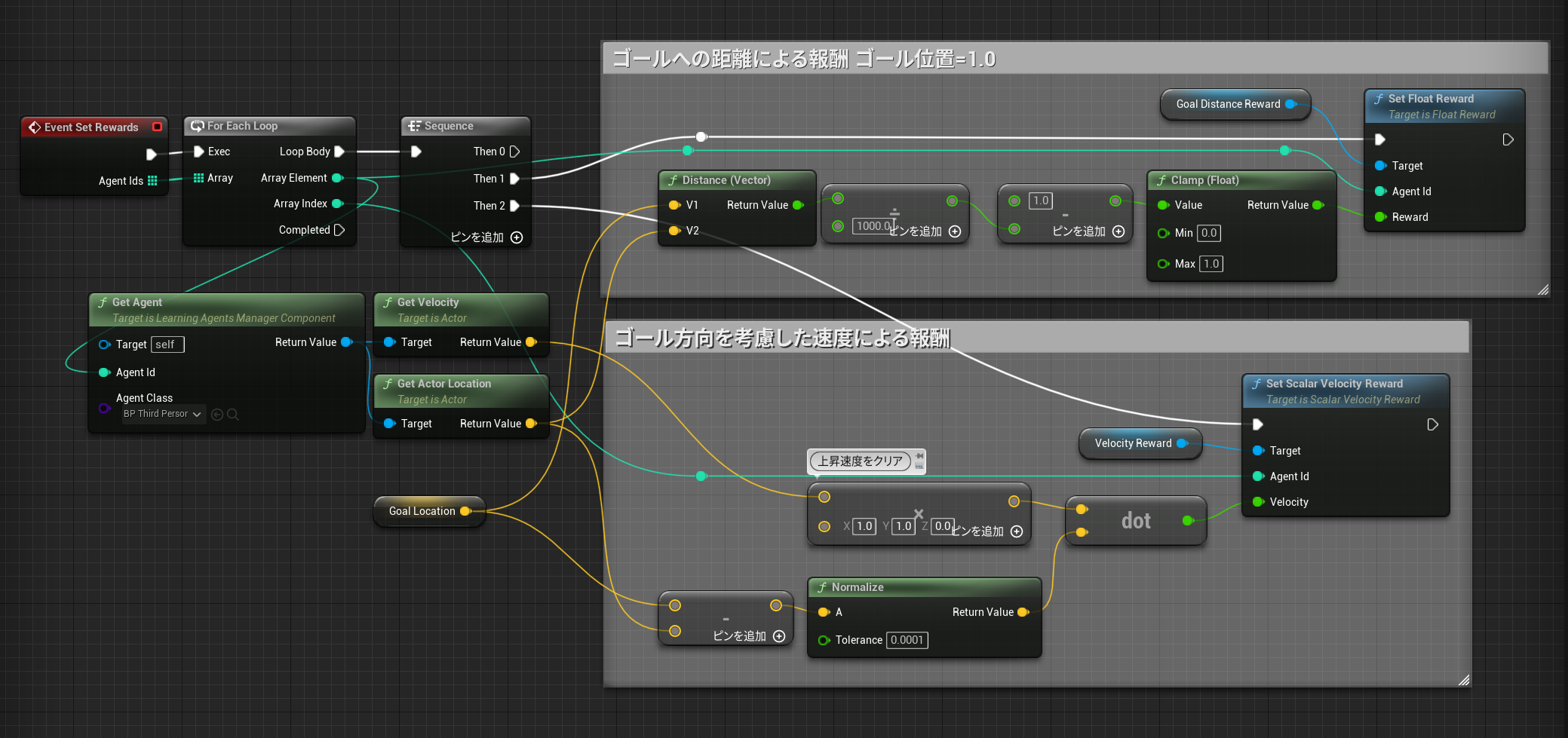
中断条件の定義
崖から落ちた場合に即座に終了してほしいので中断条件を定義しています。
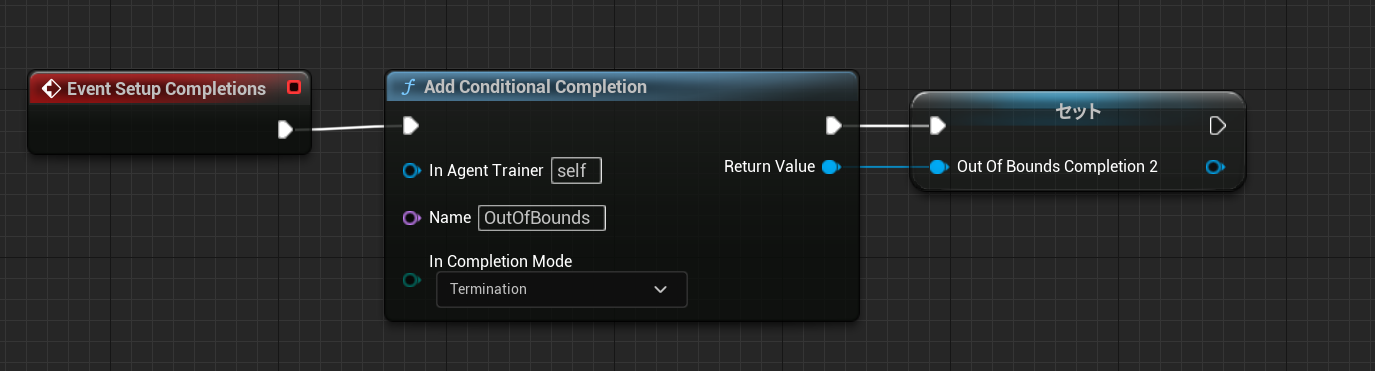
中断判定
ゴール位置から3m低い位置に移動したら学習を中断します
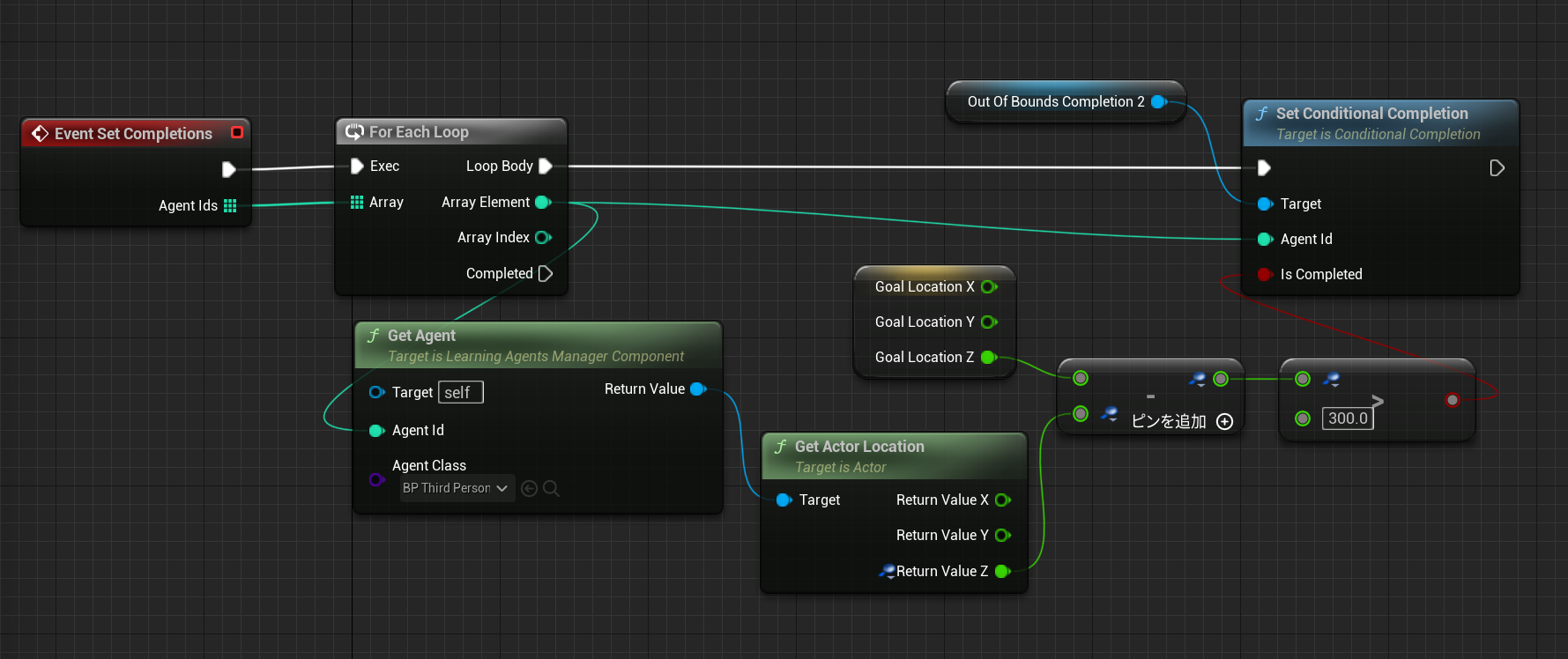
位置リセット
中断されたり位置リセットが行われた場合にエージェントの位置をリセットします
レベル中のプレイヤースタートを
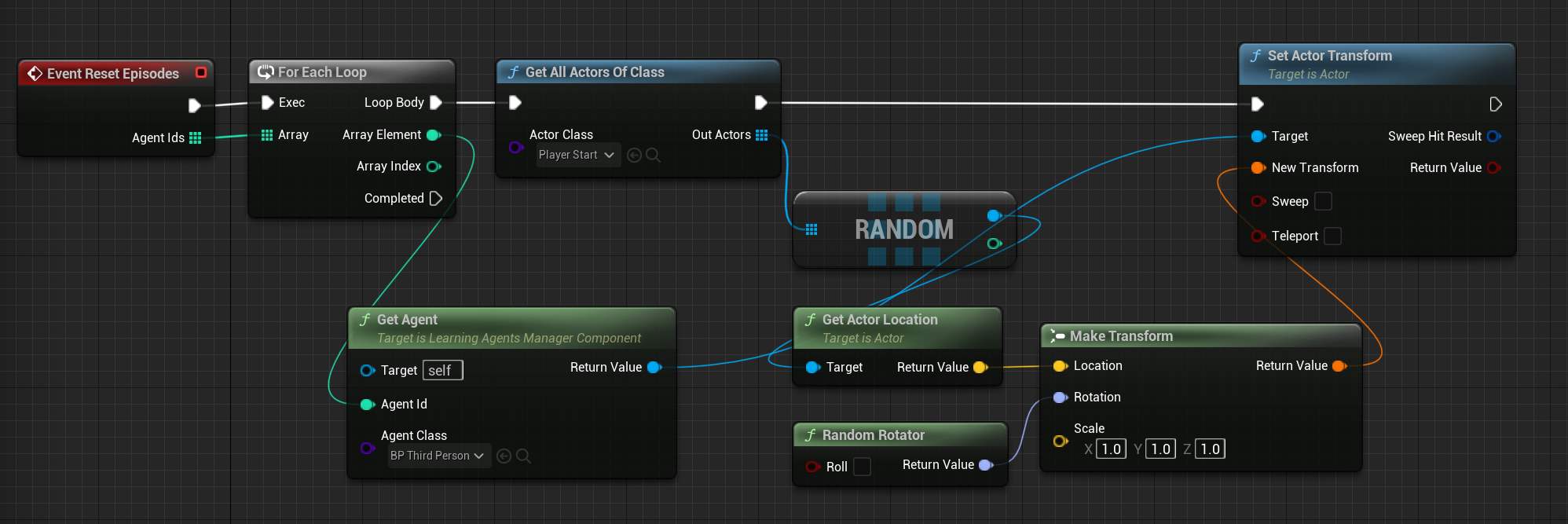
最終結果
アドカレ!チュートリアルをまねてやってみればLearningAgent君が良い感じにやってくれるだろwと激甘見積もりでやってみたけど、全然簡単じゃなくて頭抱えてる。横方向の移動量が少ないノミの観察をしている気分になってる。 pic.twitter.com/zQAkz4QXII
— Takashi.Suzuki (@wankotank) December 20, 2023
とりあえずの最終結果。改善できる点は沢山あるけど良い勢いで崖を飛び越えられるマネキン君も確認できたてきたので満足 pic.twitter.com/kRvD7ni6ng
— Takashi.Suzuki (@wankotank) December 20, 2023
バグ調査など
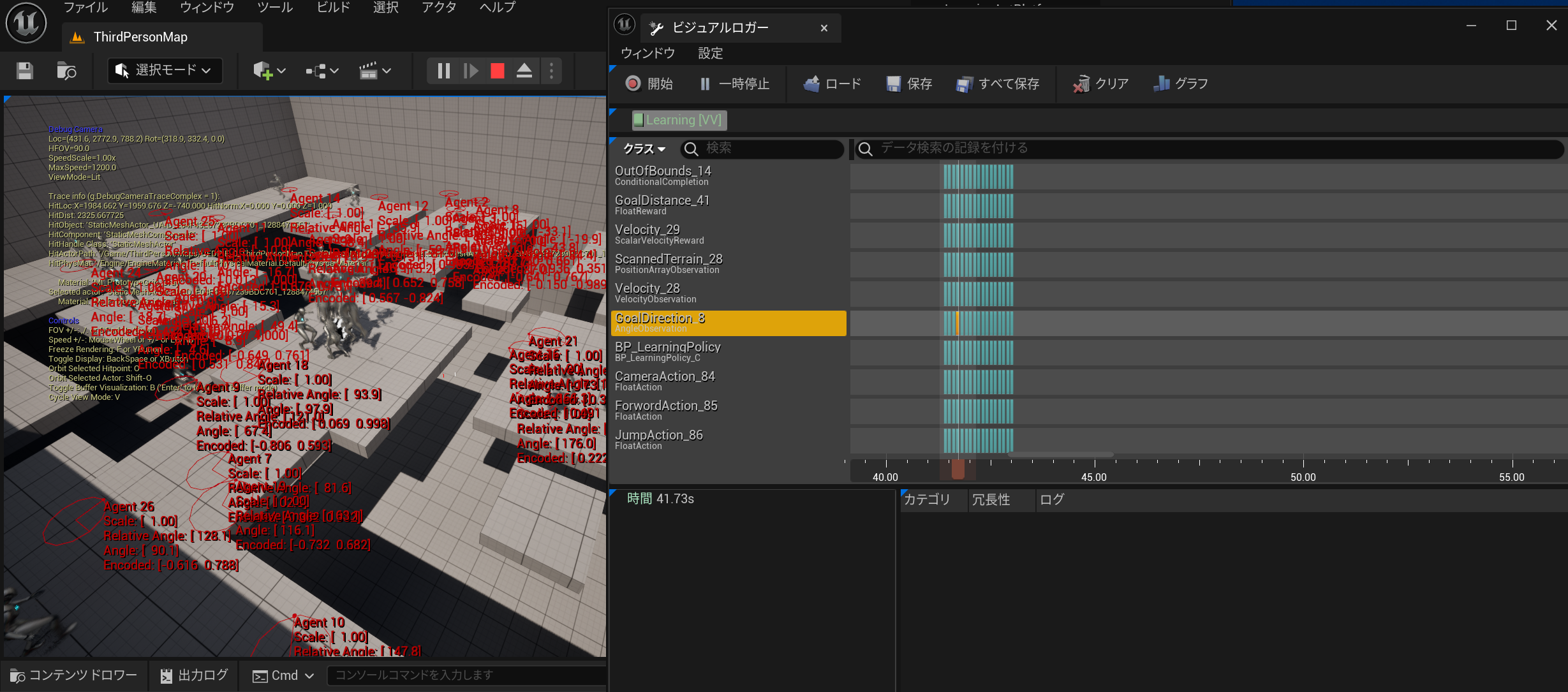
ビジュアルロガーをつかってトレースすると様々な情報のログを取って細かく確認することができます。
なんか正しく報酬が計算できてないぞ・・・?みたいな問題にそうぐうしたら一度キャプチャしてみると良いかもです。
アドカレ2023
明日はキンアジ神による
【UE5】【Python】UnrealPythonがエディタと連携する上で覚えておくとよいこと【★★★】
です!