Google Cloudの大人気サーバレスサービスであるCloud RunがGPUに対応しました!
さっそく言語モデルを動かしてみます。
なおGPUを使わずCPUで言語モデル動かす記事は過去に書いていますので、必要に応じて参照ください。Cloud Runは結構たくさんメモリを載せられるので、今までも意外と言語モデルを動かせました。もちろんCPUだと処理速度は遅いのですが。
今回動かすモデルは私の好み1で、ストックマークが公開しているGPT-NeoX 1.4Bを選びました。これをCloud Run上のGPUで動かしてみます。このモデルはそのまま動かすには14GB程度のメモリが必要です。
stockmark/gpt-neox-japanese-1.4b · Hugging Face
準備
Cloud RunのGPUサポートは現状プレビューであり、フォームから申請する必要があります。私の場合は申請してから2週間程度で許可されたという返信が届いて使えるようになりました。
GPUが使えるようになると、Google Cloudコンソール上でもGPUの項目が有効化されます。

▲GPUが使えない状態

▲GPUが使える状態
ローカルで実装
まず、今回デプロイする言語モデルを動かすアプリケーションを開発します。本筋とはあまり関係ありませんが、Windows 11にRTX 3600が乗ったマシンのWSL2上で開発しています。
ソースコードの全体は下記のようになっています。
ここから抜粋して説明します。
今回構築するアプリケーションの依存関係はこうなっています。
[tool.poetry.dependencies]
python = "^3.11"
streamlit = "^1.37.1"
transformers = "^4.44.2"
sentencepiece = "^0.2.0"
torch = {version = "^2.4.0+cu124", source = "torch_cu124"}
Dockerfileはこんな感じ。開発用の設定(apt-getとか)とデプロイ設定を混ぜてしまっていますが、本来はmulti stage build使ったほうが良いと思います。
また、ここではモデルをあらかじめダウンロードするスクリプトを使ってコンテナ内にモデルを含めています。Google Cloud公式ドキュメントでもコンテナ イメージに直接保存することをおすすめしていたりCloud Storageからの読み込みをおすすめしていたりするので、都度判断ください。
FROM python:3.11-slim
WORKDIR /app
ENV PYTHONPATH="/app:$PYTHONPATH"
RUN apt-get update && apt-get install -y \
git \
curl \
build-essential \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/*
RUN pip install poetry
COPY pyproject.toml ./
COPY poetry.lock ./
RUN poetry install
# モデルのダウンロード
ENV DOWNLOAD_REPO_ID="stockmark/gpt-neox-japanese-1.4b"
ENV DOWNLOAD_PATH="~/model"
COPY src/download.py ./
RUN poetry run python download.py
COPY src/ ./src/
ENV TRANSFORMERS_OFFLINE=1
ENV HF_HUB_OFFLINE=1
# see https://cloud.google.com/run/docs/configuring/services/gpu?hl=ja#libraries
ENV LD_LIBRARY_PATH /usr/local/nvidia/lib64:${LD_LIBRARY_PATH}
# see https://cloud.google.com/run/docs/issues#home
CMD HOME=/root poetry run streamlit run src/gpt_container/streamlit.py --server.address 0.0.0.0 --server.port $PORT
compose.ymlはこんな感じ。WSL2 + Docker Composeの構成なので、本稿の趣旨であるCloud Runでの動作とはあまり関係ありません。
services:
app:
build: .
volumes:
- .:/app
environment:
- PORT=8000
ports:
- 8000:8000
deploy:
resources:
reservations:
devices:
- driver: nvidia
device_ids: ['0']
capabilities: [gpu]
Streamlitで、こんな感じのアプリを作ります。Generatorは、時間を測りながらモデルを実行するだけのクラスですね
import streamlit
from generator import Generator
import torch
generator_cpu = Generator()
generator_cuda = None
with streamlit.expander("cuda device"):
if torch.cuda.is_available():
streamlit.text(f'cuda.get_device_name: {torch.cuda.get_device_name()}')
streamlit.text(f'cuda.get_device_capability: {torch.cuda.get_device_capability()}')
streamlit.text(f'cuda.device_count: {torch.cuda.device_count()}')
streamlit.text(f'cuda.current_device: {torch.cuda.current_device()}')
cuda_device = f'cuda:{torch.cuda.current_device()}'
generator_cuda = Generator(device=cuda_device)
else:
streamlit.text('no cuda device')
input_text = streamlit.text_input("入力してね", value="")
if len(input_text) > 0:
streamlit.text(f'入力は「{input_text}」です')
streamlit.text('CPU:')
result = generator_cpu.generate(input_text)
streamlit.markdown(result["output"])
streamlit.text(f'実行時間: {result["time"]:.3f}秒')
if generator_cuda is not None:
streamlit.text('GPU:')
result = generator_cuda.generate(input_text)
streamlit.markdown(result["output"])
streamlit.text(f'実行時間: {result["time"]:.3f}秒')
動かしてみます。

こんな感じになりました。こちらは私のデスクトップPCで動かしてみた結果です。
CPUとGPUの両方を使って動かしていて、GPUの方が速くなっているのが分かりますね。
Cloud Runへのデプロイ
ここから本題です。このアプリケーションをCloud Runで動かしてみましょう。
ビルドしたイメージをArtifact Registryにプッシュします。予めArtifact Registryを作っておいて、タグ名を適当に決めておきます。なお、サービスのデプロイ先(現状us-central1のみ)と同じリージョンにArtifact Registryを作らないと「 Revision 'リビジョン名' is not ready and cannot serve traffic. Container import failed: 」という謎のエラーが出てデプロイができませんでした。
$ docker tag <Composeイメージ名> <タグ名>
$ docker push <タグ名>
Cloud Runにデプロイします。
$ gcloud beta \
run deploy <サービス名> \
--image <タグ名> \
--platform managed \
--region=us-central1 \
--memory=16GiB \
--cpu=4 \
--gpu=1 \
--gpu-type=nvidia-l4 \
--no-cpu-throttling \
--max-instances=1
しかし、gcloud cliでデプロイしようとしても「Internal error encountered.」という謎のエラーで動きませんでした。Google Cloudコンソール上からならデプロイができました。
現状Cloud RunでGPUをデプロイするにはメモリ16GiB以上・vCPU4個以上・「CPUを常に割り当てる」が必要などいくつか制限があります。詳細はドキュメントを読んでください。

デプロイできたらアクセスしてみます。
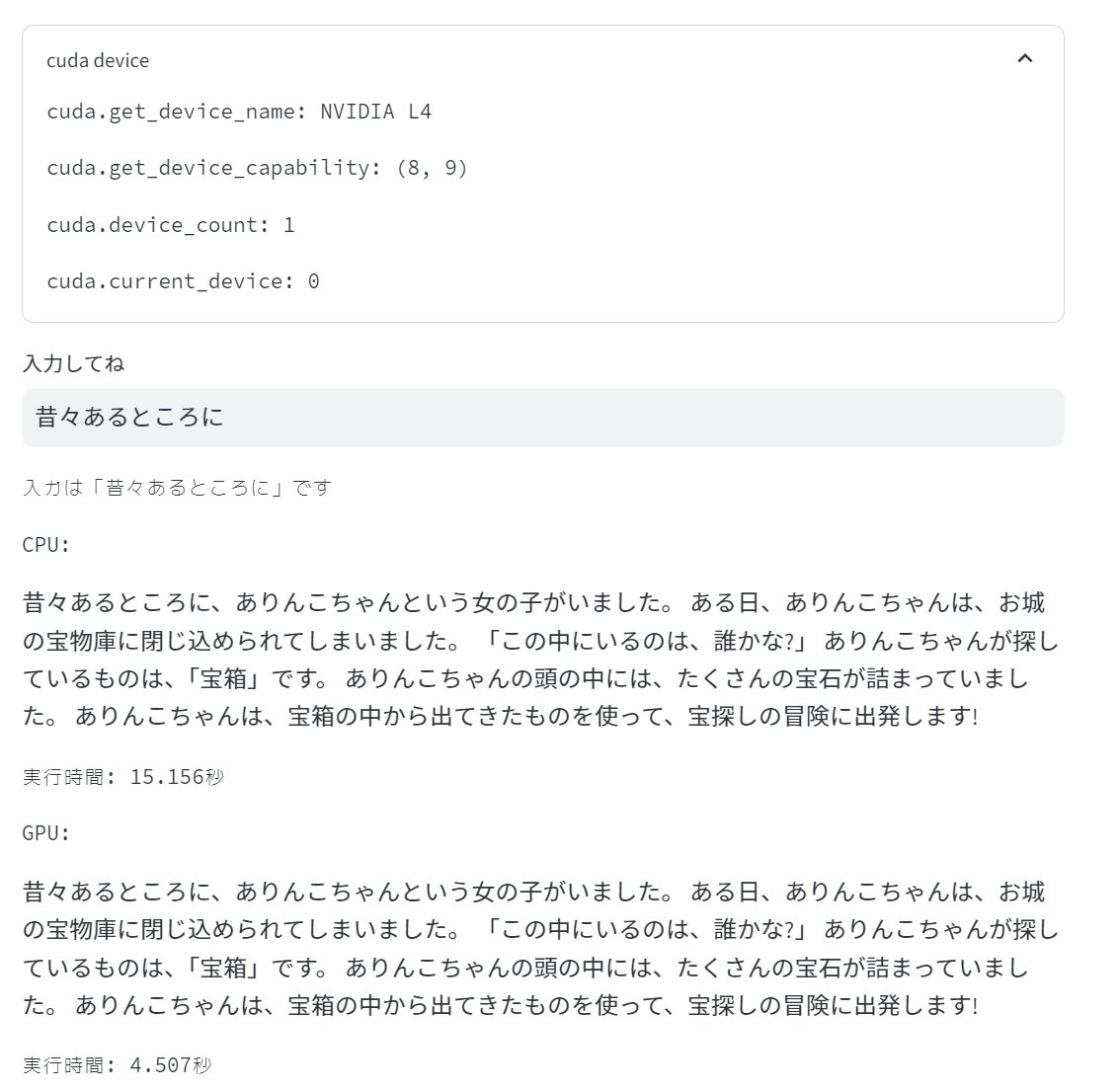
NVIDIA L4を認識しており、CPUよりも高速に生成できていることがわかりました!
まとめ
Google Cloudのサーバレス開発サービスCloud Runで、GPUを使った開発が可能になりました。まだリージョンの制限があったり謎のエラーがあったりして実サービスへの投入は難しいかもしれませんが、実験的なプライベートプロジェクトなどでは使えると思います。これが安定してくると、機械学習や言語モデルを使ったアプリケーションの構築がやりやすくなると思います。
個人的には、CPUを常に割り当てるが必須でなくても動くようになると良いなと思いますが、現状でも15分経てばインスタンス数がゼロにスケールするので扱いやすいですね。