3行まとめ
- Microsoft Azure Computer Vision APIで、Instagramに投稿するための食事画像のハッシュタグを自動で生成する
- 生成されたハッシュタグと、投稿に付いたいいね!数の相関をR言語で回帰分析する
- Instagramで最も「いいね!」がもらえる女子力最強のハッシュタグが分かる

Instagramという物を以前からやっていたのですが、女子力が足りないのか私には面白さがよく分かりませんでした。
そこで、「いいね!」をたくさんもらえるように**#ハッシュタグ**について考えてみることにしました。
AIでハッシュタグを自動生成する
まずInstagramがよく分かっていない私には、投稿に付けるハッシュタグを自分で考えることが難しかったです。
なのでタグを自動生成することを考えました。
過去に『Microsoft Azureで 女子力を生成する』というふざけた題目でLTさせて頂いたのですが、おおよそこの発表内容の通りです。
Microsoft Azure Cognitive Service の Computer Vision API で、画像からタグを生成します。
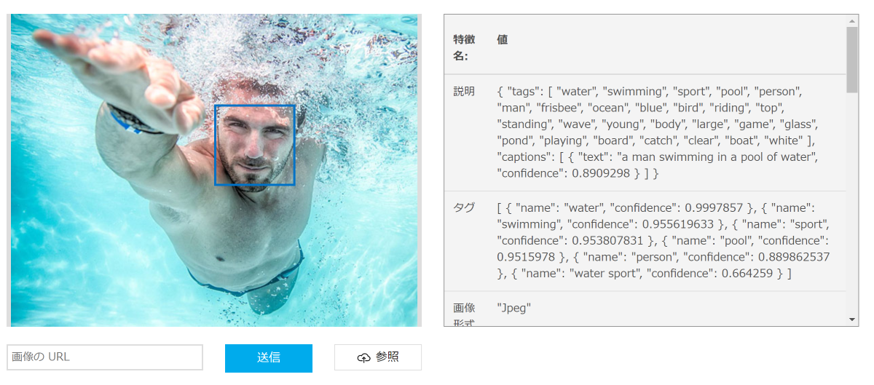
たとえば上記の画像をComputer Vision APIに投げると「a man swimming in a pool of water」のような説明文と、「water」「swimming」「sport」「pool」「person」「watersport」といったタグの情報が得られます。
このComputer Vision APIを利用して、画像に自動でハッシュタグを付けることができるRuby on Railsアプリケーションを開発しました。
https://github.com/s2terminal/azure_computer_vision_on_rails
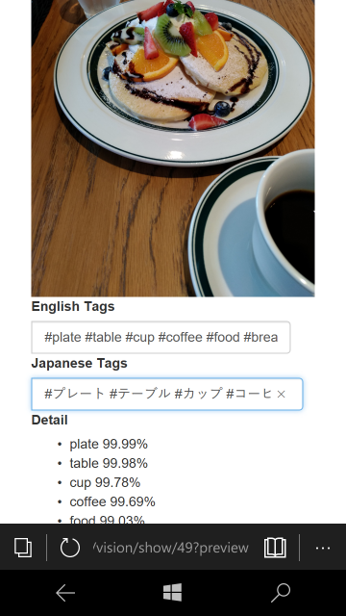
InstagramのAPI利用申請は面倒だったので、投稿は手動です。タグをコピペしてInstagramに貼り付ける男らしい仕様です。こういう所がおしゃれじゃないのが女子力欠如の所以だとかそういうのは気にしないです。
画像をサーバーにアップロードして、Computer Vision APIに投げてタグを生成し、ついでにTranslation Text APIも使って日本語の情報を取得するだけです。
upload_file = params[:image]
if upload_file != nil
# 画像のアップロード
@vision = Vision.create()
filedir = "./public/uploads/visions/#{@vision.id}"
FileUtils.mkdir_p(filedir) unless FileTest.exist?(filedir)
filepath = "uploads/visions/#{@vision.id}/#{upload_file.original_filename}"
File.open("./public/#{filepath}", 'wb') do |f|
f.write(upload_file.read)
end
@vision.url = "#{request.url}/#{filepath}"
# リクエストの生成
uri = URI('https://westus.api.cognitive.microsoft.com/vision/v1.0/analyze')
uri.query = URI.encode_www_form({
'visualFeatures' => 'Tags',
'language' => 'en'
})
http = Net::HTTP::Post.new(uri.request_uri)
http['Content-Type'] = 'application/json'
http['Ocp-Apim-Subscription-Key'] = Rails.application.secrets.azure_computer_vision_api_key
http.body = { url: @vision.url }.to_json
response = Net::HTTP.start(uri.host, uri.port, :use_ssl => uri.scheme == 'https') do |client|
client.request(http)
end
# レスポンスの加工
json = JSON.parse(response.body)
raise json["message"] if response.code != "200"
json["tags"].each{|tag|
vision_tag = @vision.vision_tags.build(name: tag["name"], confidence:tag["confidence"])
vision_tag.save
}
# 翻訳のアクセストークン取得
uri = URI('https://api.cognitive.microsoft.com/sts/v1.0/issueToken')
http = Net::HTTP::Post.new(uri.request_uri)
http['Content-Type'] = 'application/json'
http['Accept'] = 'application/jwt'
http['Ocp-Apim-Subscription-Key'] = Rails.application.secrets.azure_translator_text_api_key
response = Net::HTTP.start(uri.host, uri.port, :use_ssl => uri.scheme == 'https') do |client|
client.request(http)
end
token = response.body
# 翻訳
require 'rexml/document'
uri = URI('https://api.microsofttranslator.com/V2/Http.svc/Translate')
@vision.vision_tags.each{|tag|
uri.query = URI.encode_www_form({
'appid' => 'Bearer ' + token,
'text' => tag.name,
'to' => 'ja'
})
http = Net::HTTP::Get.new(uri.request_uri)
http['Accept'] = 'application/xml'
response = Net::HTTP.start(uri.host, uri.port, :use_ssl => uri.scheme == 'https') do |client|
client.request(http)
end
raise response.body if response.code != "200"
doc = REXML::Document.new(response.body)
tag.translated_name = doc.elements.first.text
tag.save
}
@vision.save
redirect_to :action => "show", :id => @vision.id
APIを叩くのが順番に同期処理なので遅かったり、アップロード時のファイル名そのまま保存する仕様はどうなんだとか、色々イケてないプログラムなのでもしご利用される際はお気を付けください。なお実際には私はアクセス制限をかけたWebアプリケーションとして使っています。
この方法で生成したハッシュタグを何も考えずにぺたぺた貼り付けていたところ、以前のような「いいね0件」のような事態は起こらなくなり、「いいね!」が付くようになりました。

さて、こんな仕組みで本当に「いいね!」を獲得できているのか、女子力を会得したと言って良いのか、どのタグが最も「いいね!」に貢献しているのかを調べることにしました。
「いいね!」がもらえるハッシュタグを回帰分析で探す
たとえば、5つの投稿の「いいね!」数が下記だったとします。
| 投稿 | 付いたハッシュタグ | いいね数 |
|---|---|---|
| 投稿A | #肉 #食べ物 | 21いいね |
| 投稿B | #野菜 #食べ物 | 5いいね |
| 投稿C | #肉 #野菜 | 20いいね |
| 投稿D | #食べ物 | 10いいね |
| 投稿E | #肉 #野菜 #食べ物 | 20いいね |
パッと見、なんだか**「肉」ハッシュタグが付いていると「いいね!」が増える**ように見えます。
この結果を、線形回帰分析で定量的に算出してみます。
まず、ハッシュタグといいね数の関係を足し算の数式にします。
(積の方がモデルとして適切かもしれませんが、対数を取ることで和と同様の方法で相関関係の算出ができると思います)
投稿A: (基準値)+("肉"に付くいいね数)+("食べ物"に付くいいね数)=21
投稿B: (基準値)+("野菜"に付くいいね数)+("食べ物"に付くいいね数)=5
投稿C: (基準値)+("肉"に付くいいね数)+("野菜"に付くいいね数)=20
投稿D: (基準値)+("食べ物"に付くいいね数)=10
投稿E: (基準値)+("肉"に付くいいね数)+("野菜"に付くいいね数)+("食べ物"に付くいいね数)=20
ここで
- ("肉"に付くいいね数) := $a_1$
- ("野菜"に付くいいね数) := $a_2$
- ("食べ物"に付くいいね数) := $a_3$
- (基準値) := $b$
と置くと
a_1 + a_3 + b = 21 \\
a_2 + a_3 + b = 5 \\
a_1 + a_2 + b = 20 \\
a_3 + b = 10 \\
a_1 + a_2 + a_3 + b = 20 \\
行列表記に書き換えると、投稿した結果は下記のように表現できます。
\left( \begin{array}{ccc}
1 & 0 & 1 \\
0 & 1 & 1 \\
1 & 1 & 0 \\
0 & 0 & 1 \\
1 & 1 & 1 \\
\end{array} \right)
\left( \begin{array}{c}
a_1 \\
a_2 \\
a_3 \end{array} \right)
+ b
=
\left( \begin{array}{c} 21 \\ 5 \\ 20 \\ 10 \\ 20 \end{array} \right)
このとき、ある投稿について、タグ$ a_i $を付けた時は$ x_i = 1$ 、 付けなかった時は$ x_i = 0$ となる$ x_i$を用いると
ある投稿に付くいいね!の数$ y$は
a_1x_1 + a_2x_2 + a_3x_3 + b = y
と表現できます。
つまり、 $ a_i$の値が最も大きいタグこそが、もっとも「いいね!」の付くタグ、最強のタグ と言えます。
この$ a_i$の値を、 重回帰分析 を用いて推定します。
「ハッシュタグ」と「いいね!」のように「因」と「果」があるものについて、「因」から「果」を予測するための回帰式を求めるのが、回帰分析です。
| 用語 | 説明 |
|---|---|
| 説明変数 | ハッシュタグの有無を表す$x_i$ |
| 目的変数 (被説明変数) | 「いいね数」である$y$ |
| 回帰係数 | ハッシュタグと「いいね数」の関係を示す $a_i$ |
回帰分析の計算手順は長くて複雑なのですが、Rを使うことで簡単に算出できます。
本稿では解説しませんが、この計算で実際に何が行われているのか中身を知っておくと回帰分析の理解が進むと思います。
R環境構築
まずは試してみましょう。
R実行環境のRStudio ServerはrockerというDockerImageがあるので、Dockerがあれば簡単に構築できます。良い時代になりました。
> docker run --rm -p 8787:8787 rocker/rstudio
http://localhost:8787 にアクセスし、UserとPassにrstudioと入力すると、RStudio使うことができます。
回帰式の算出
まずはデータを登録します。
> likelist <- data.frame(tag1 = c(1,0,1,0,1),tag2 = c(0,1,1,0,1),tag3 = c(1,1,0,1,1),like = c(21,5,20,10,20))
> likelist
tag1 tag2 tag3 like
1 1 0 1 21
2 0 1 1 5
3 1 1 0 20
4 0 0 1 10
5 1 1 1 20
lm()関数に、目的変数とデータを渡してあげることで回帰係数を求めることができます。
(lmはLinear Modellingの略でしょうか?)
> result = lm(like~., data=likelist)
> result
Call:
lm(formula = like ~ ., data = likelist)
Coefficients:
(Intercept) tag1 tag2 tag3
10 13 -3 -1
$a_1 = 13, a_2 = -3, a_3=-1, b = 10$であることが、簡単に分かりました。
つまり、この例の場合「肉」タグと「いいね数」にはプラス13の正の線形関係、「肉」タグで13いいね獲得できるということが分かります。
実際に獲得できる「いいね!」数を求める回帰式は
13x_1 -3x_2 -x_3 + 10 = y
となります。
回帰分析の精度
回帰式はあくまで目的変数(いいね数)を予測するための式であり、実際の値とは一致しません。
回帰式で推定されるいいね数を、実際のいいね数と比べてみましょう。
| 投稿 | 付いたハッシュタグ | いいね数 | 推定値 |
|---|---|---|---|
| 投稿A | #肉 #食べ物 | 21いいね | 22いいね |
| 投稿B | #野菜 #食べ物 | 5いいね | 6いいね |
| 投稿C | #肉 #野菜 | 20いいね | 20いいね |
| 投稿D | #食べ物 | 10いいね | 9いいね |
| 投稿E | #肉 #野菜 #食べ物 | 20いいね | 19いいね |
いかがでしょうか。
完全一致とはいかないものの、結構いい感じの精度だと思います。
この精度は、lm()関数の出力結果をsummary()関数に渡すことで定量的に確認できます。
> summary(result)
Call:
lm(formula = like ~ ., data = likelist)
Residuals:
1 2 3 4 5
-1.00e+00 -1.00e+00 1.11e-16 1.00e+00 1.00e+00
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 10.000 3.464 2.887 0.2123
tag1 13.000 2.000 6.500 0.0972 .
tag2 -3.000 2.000 -1.500 0.3743
tag3 -1.000 2.646 -0.378 0.7699
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2 on 1 degrees of freedom
Multiple R-squared: 0.981, Adjusted R-squared: 0.9241
F-statistic: 17.23 on 3 and 1 DF, p-value: 0.1748
なんか色々出てきました。
| 用語 | 名前 | 説明 |
|---|---|---|
| Coefficients (Estimate) | 回帰係数 (推定値) | 説明変数と目的変数とのあいだの、線形関係の係数。大きければ大きいほど、説明変数が増えると目的変数も増えると言える |
| Pr(>|t|) | p値 | 回帰係数がゼロであるという帰無仮説の仮説検定結果のp値。0に近いほど、線形関係がある可能性が高い |
| Adjusted R-squared | 調整済み決定係数$R^2$ | 目的変数について、推定値の分散を実測値の分散で割ったようなもの。1に近いほど、回帰式は実測値を正確に言い表している |
超ざっくり言うとp値が小さくて$R^2$が大きいほどハッピーな感じです。
この場合、
- $R^2$は0.92と大きいので、回帰式の精度は高い
- tag1のp値は0.10と小さいので、「#肉」と「いいね!」数には線形関係がありそう
- tag2、tag3のp値はそれぞれ0.37、0.77と大きいので、「#野菜」「#食べ物」と「いいね!」数には線形関係が無いかもしれない
という感じになります。
実際にInstagramのハッシュタグを解析
実際に、先ほどのWebアプリケーションのデータベース上には55個のハッシュタグと100件の画像投稿データがありました。そこからデータ数の少ないタグやInstagramに投稿していない画像などを削除し、「beer」「beverage」「bowl」など25個のハッシュタグと、27件分の投稿の「いいね!」数データを使いました。
本当はInstagramのAPIから取ってきたいのですが、たかが27件分なので「いいね!」数のデータは手動で集めました。
なお実際には生成されたタグを日本語に翻訳して使う時と英語のまま使った時があります。
今回はデータ数を確保するため、言語による差異は無いと仮定して英語に統一します。
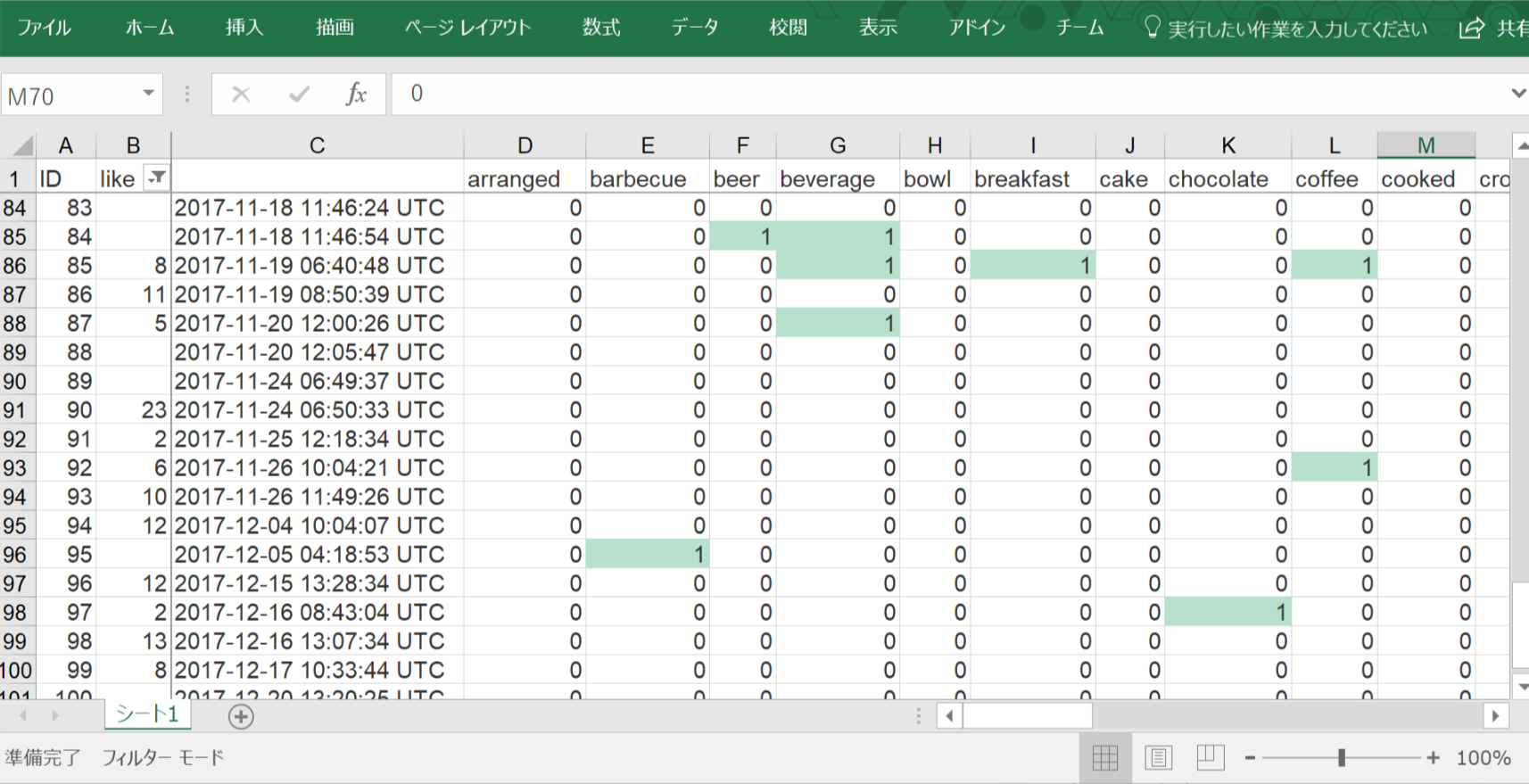
このようなCSVを作ってRStudioにアップロードして、読み込んでみます。
> likelist <- read.csv("likelist.csv")
> result <- lm(like~., data=likelist[,2:length(likelist)])
> summary(result)
(中略)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.000e+00 1.375e+01 0.218 0.863
beer 2.100e+01 1.775e+01 1.183 0.447
beverage -5.000e+00 1.039e+01 -0.481 0.715
bowl -8.000e+00 8.485e+00 -0.943 0.519
(後略)
係数は算出されましたが、全体的にp値が高くなっています。
「meal」「indoor」などほとんどの投稿に付いているタグや、「drink」「glass」のように付いている投稿がほとんど重複しているタグがあるせいか、分析の精度が下がっているようです。
相関のありそうなタグに絞って計算してみます。
変数の選択
手動で変数を減らしたり増やしたりしていってp値を調整してもいいのですが、Rのstep()関数を使うことでp値の低い変数を自動的に除去し、適切な結果を得る事ができます。便利ですね。
> filteredResult <- step(result)
> summary(filteredResult)
(中略)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.4099 2.1554 -0.190 0.855459
beer 17.3469 3.0896 5.615 0.001362 **
beverage -4.6003 1.7870 -2.574 0.042088 *
bowl -7.8359 1.9863 -3.945 0.007582 **
chocolate -7.7976 2.7099 -2.877 0.028151 *
coffee -3.3189 1.9659 -1.688 0.142339
croquette -3.0000 2.6036 -1.152 0.293048
cup 9.6148 3.0993 3.102 0.021057 *
dessert 5.3844 2.3621 2.279 0.062848 .
dish 8.9158 3.0374 2.935 0.026103 *
eaten 9.5451 2.6632 3.584 0.011587 *
food -3.6327 1.9327 -1.880 0.109213
fresh 10.5570 3.1619 3.339 0.015636 *
meat 1.7338 1.6328 1.062 0.329139
pan 7.8231 2.9833 2.622 0.039462 *
pasta 5.1395 2.5589 2.008 0.091351 .
person 16.8350 2.2953 7.335 0.000328 ***
piece.de.resistance -2.4303 2.2419 -1.084 0.319990
plate 4.8231 1.4564 3.312 0.016173 *
rice 9.4855 4.0364 2.350 0.057057 .
stew 3.8231 2.9833 1.282 0.247303
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 1.841 on 6 degrees of freedom
Multiple R-squared: 0.9651, Adjusted R-squared: 0.8488
F-statistic: 8.296 on 20 and 6 DF, p-value: 0.00738
出ました!
| ハッシュタグ | 回帰係数 |
|---|---|
| beer | 17.3469 |
| person | 16.835 |
| fresh | 10.557 |
| cup | 9.6148 |
| eaten | 9.5451 |
| rice | 9.4855 |
| dish | 8.9158 |
| pan | 7.8231 |
| dessert | 5.3844 |
| pasta | 5.1395 |
| plate | 4.8231 |
| stew | 3.8231 |
| meat | 1.7338 |
| piece.de.resistance | -2.4303 |
| croquette | -3 |
| coffee | -3.3189 |
| food | -3.6327 |
| beverage | -4.6003 |
| chocolate | -7.7976 |
| bowl | -7.8359 |
#beer と #person というハッシュタグが、いずれも回帰係数が約17、つまり付けると17いいね!もらえる女子力の強いハッシュタグだということが分かりました。
逆に、#chocolate や #coffee などは「いいね!」数と負の相関関係という興味深いデータも算出されていますね。
つまり、例えばこのような「ビール」と「人物」の映った画像が、Instagramで最も「いいね!」がもらえる最強に女子力の高い画像という事になります。

結論
- 何を食べるかよりも、ヒトと食べる写真を上げた方が「いいね!」がもらえる
- コーヒーは「いいね!」が減る。ビールは「いいね!」が増える
- さやかちゃんはかわいい
クリスマスの夜はぜひ大切なパートナーとお酒を飲む風景を写真に撮り、#personや**#beer**タグを付けてInstagramに投稿するのは如何でしょうか。私は家で一人でスプラトゥーンでもしてますが。
参考文献
- 統計の本
- Rの本
- ウェブサイト
以上、Cogbot!Advent Calendar 2017 の24日目でした。
それではみなさま、良いクリスマスをお過ごし下さいませ。