最近、OSSで動作する機械学習のサンプルコード等を見ていると、PyTorch がよく出てきます。PyTorchについて正直あまり詳しくなかったので、調べてみました。
PyTorchを使ってゼロからモデルを考えて作る機会は少ないかもしれませんが、ちょっとカスタマイズしたり挙動を調べたいという時に、中身の仕組みの理解が必要になると思います。
たとえばGPTのモデルや、最近話題のStable Diffusionのサンプルコードなどを見ていても、よくimport torchと出てきて実際PyTorchが関係しています。こういったコードの雰囲気をつかめるようになる事を目指します。
PyTorchとは
PyTorch とは、Meta(Facebook)のオープンソースの深層学習フレームワークです。
「フレームワーク」を謳っているように、たとえばRuby on RailsのModel・View・Controller(MVC)のように、いくつかの枠組みがあってその上に様々な機能が用意されています。
-
Datasets & DataLoaders
- データの読み込み
- ミニバッチ(
minibatches)のような、少しずつデータを分割して学習したりするための便利機能がある
-
Transforms
- 変換。いわゆる前処理
- 画像を数値列に変換したり
-
NeuralNetwork Model(
torch.nn)- 学習
- パラメータの処理、各レイヤーの関数の扱いなど
-
Optimize
- 損失関数の最適化
PyTorchとTensorFlow
PyTorchと似た深層学習ライブラリに、GoogleのTensorFlowがあります。よく言われるのが「TensorFlowは実装しやすくビジネス方面で人気」「PyTorchはロジックの把握やカスタマイズがしやすく研究方面で人気」ということです。
また最近はTensorFlowからJAXに移行する気配のような話もあります。いろいろと動向が気になりますが、本稿ではこれらの比較は取り扱わずPyTorchのみについて述べます。
テンソル
Pytorchは テンソル(tensor) の扱いに長けていて、これを基本的なデータ型として扱います。
テンソルとは、とても雑に言うと、数字がいっぱい集まったものです。固定長の数値型多次元配列(PythonではList)だとイメージしてもらえれば、だいたい似ています。
hoge = [
[1,2,3],
[4,5,6],
[7,8,9]
]
hoge[1][1] #=> 5
import torch
hoge_tensor = torch.tensor([
[1,2,3],
[4,5,6],
[7,8,9]
])
hoge_tensor[1][1] #=> tensor(5)
上記のように、テンソルの実際の値にアクセスするときの添字の数が2個のとき 「2階のテンソル」 のように呼びます。
特に
1次元配列のような1階のテンソルを 「ベクトル」
2次元配列のような2階のテンソルを 「行列」
と呼びます。
また、配列ではなく普通の値があるだけの「0階のテンソル」を 「スカラー」 と呼びます。
たとえば縦横16pixelの画像で、色がRGBの3つの値で表現されている場合、[3,16,16]の3階テンソルとして扱うことができます。
テンソルは配列と何が違うの?
Pythonには先に示したとおりListという多次元の値を格納できるデータ型があります。テンソルは、こういった普通の配列と違ってさまざまな数学的な演算ができます。
a = torch.tensor([[1,2,3], [4,5,6]])
tensor([[1, 2, 3],
[4, 5, 6]])
たとえば、この行列の転置行列(transposed matrix)はTで求められます。プログラム的な観点からするとTとは意味の分からない命名ですが、これは数学における転置行列の表記$A^T$に対応しています。
a.T
tensor([[1, 4],
[2, 5],
[3, 6]])
テンソルにはこういった行列演算系の機能がたくさん盛り込まれています。しかし、単なる行列演算であれば、PyTorchを使わなくともNumPyというより汎用的なPythonライブラリを使って、様々な行列計算を扱えます。
実際NumPyとPyTorchのテンソルには似たような所があり、NumPyと相互に変換する機能が用意されています。しかも、変換した後もメモリ上でデータを共有しており、そのままPyTorchのテンソルを変更するとNumPy側も変更されます。それほどの互換性があるような、似たもの同士のようです。
tensor = torch.ones(5)
tensor_numpy = tensor.numpy()
tensor.add_(2)
print(f"t: {tensor}")
print(f"n: {tensor_numpy}")
t: tensor([3., 3., 3., 3., 3.])
n: [3. 3. 3. 3. 3.]
ですがPyTorchのテンソルには、さらに深層学習で使うためにいくつか便利な機能がついています。
まず GPU が使えます。GPUは、本来は3Dの座標計算とかを高速にやるためのもので、テンソルのような並列の計算を大量にたくさん処理するのに特化しています。
PyTorchのテンソルはデフォルトではCPU側に作られるため、GPUを使うにはtensor.to("cuda")のようなコードで明示的にGPUへ移動する必要があります。
if torch.cuda.is_available():
tensor = tensor.to("cuda")
さらに、PyTorchのテンソル演算は、次に述べるような 微分 機能があります。
自動微分(Autograd)
「微分」と言うと「$x^2$を微分したら$2x$」とか覚えている人がいるかもしれないです。そういうのは忘れていいです。
どちらかというと大切なのは、微分におけるこの式です。
$$
\lim_{h \to 0}\frac{f(x+h)-f(x)}{h}
$$
これは、関数$f(x)$があったときに、$x$をほんのちょーーーっとだけ動かして$x+h$にしたらどうなりますか?を調べる式。
$x$を増やしたら、$f(x)$は、増えるのか、減るのか。増えるとしたら、増える速度は$x$よりも速いのか、同じくらいなのか、遅いのか。そういうのを調べるものです。
$f(x)$を実際に当てはめて計算すると「$x^2$を微分したら$2x$」とかの話になっていきますが、こういう公式は忘れていいです。なぜならPyTorchは自動で微分してくれる機能があります。
PyTorchでは、Tensorを定義するときrequires_grad=Trueを設定しておくと、計算結果を追跡して、微分した値を自動で算出するモードになります。
x = torch.tensor([1.0], requires_grad=True)
requires_grad=Trueを設定したテンソルに対して、足し算や掛け算など色々計算していって、最後に計算した結果に対してbackward()を実行すると、微分した結果を計算します。結果はgradプロパティで参照できます。
微分した結果のベクトルを 「勾配(gradient)」 と呼びます。高校数学では「傾き」と呼ばれていたかもしれません。よくgradという語が出てくるのはgradientから取られているようです。
実際に $x^2$ (x ** 2)を微分したら $2x$ になるかを、PyTorchで計算してみます。
x = torch.tensor([1.0, 1.1, 1.2, 1.3, 1.4, 1.5, 1.6, 1.7, 1.8, 1.9, 2.0], requires_grad=True)
y = x ** 2
y_sum = y.sum() # backward() はスカラーに対してしか使えないので、総和を取る
y_sum.backward()
print(x.grad)
tensor([2.0000, 2.2000, 2.4000, 2.6000, 2.8000, 3.0000, 3.2000, 3.4000, 3.6000, 3.8000, 4.0000])
x=1のときgradientは2.0、x=2のとき2.2、...、x=2.0のとき4.0という結果になりました。gradientはxの2倍、つまり$2x$になっています。$x^2$を微分したら$2x$というのが確認できました。
これは、PyTorchが微分の公式を覚えているのではなくて、xをちょっとずつ変化させてy_sumの値がどうなるかを調査していくことで値を調べているようです。
ちなみに、関数はすべて微分できるわけではないです。超ざっくり言うと、グラフを書いた時に「なめらかに繋がっている」なら微分可能、「ギザギザしたりちぎれたりしている」なら微分不可能です。
微分を使うなら、微分可能な関数を定義しないといけないです。先ほど$x^2$を微分しましたが、こういう微分可能な演算で繋いでいくのが、微分を使う上で必要です。1
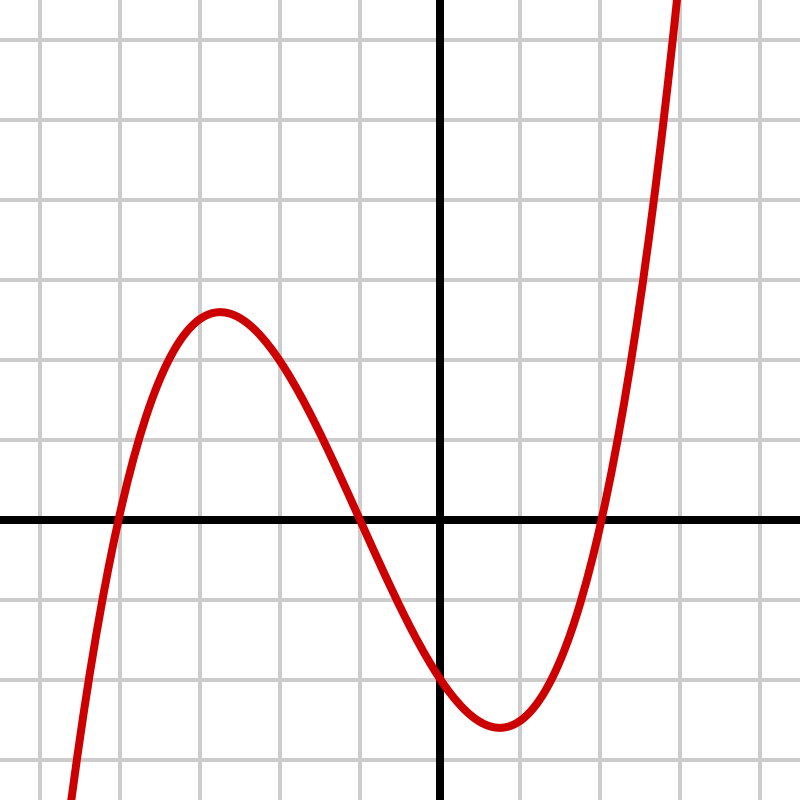
▲微分可能な関数(Wikipedia「微分可能関数」より引用)
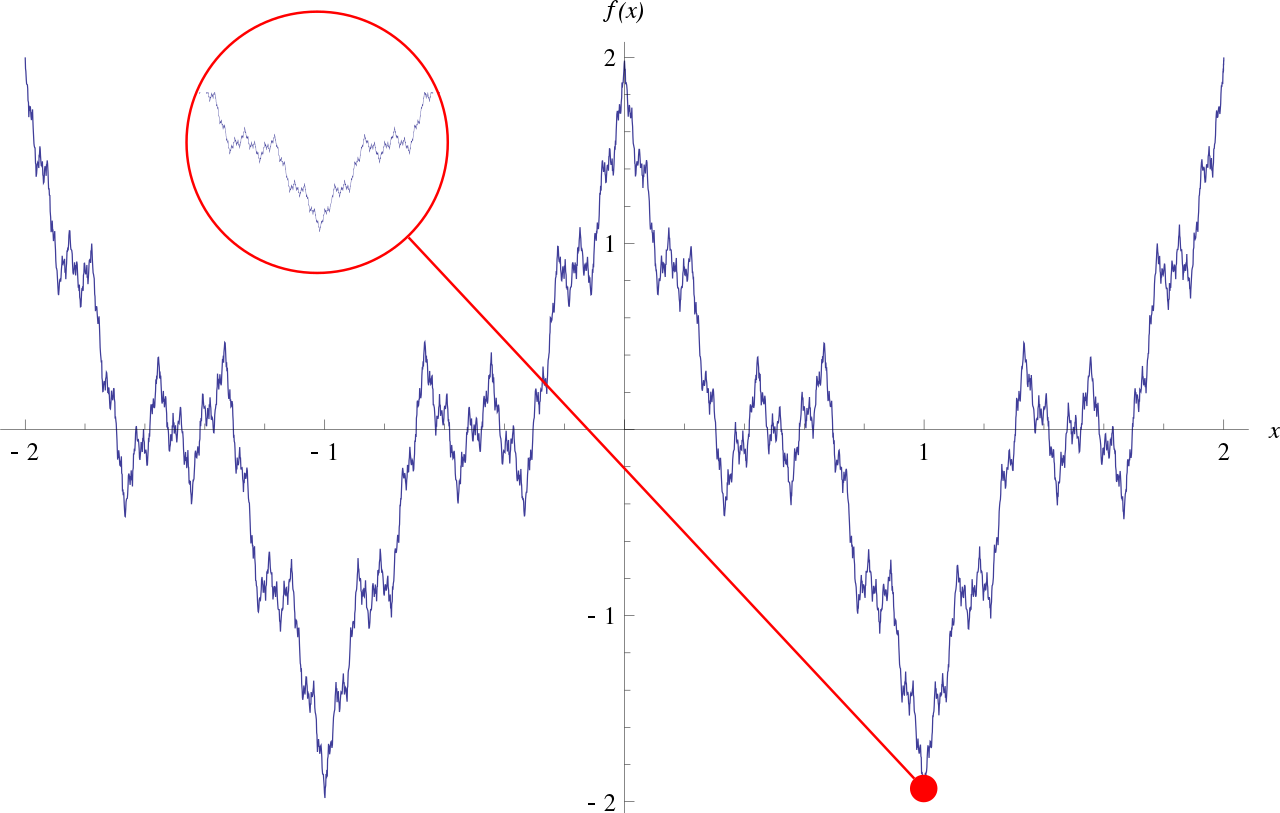
▲微分不可能な関数(Wikipedia「ワイエルシュトラス関数」より引用)
なぜ深層学習で微分を使うのか
PyTorchが自動で微分をしてくれるのは分かりました。確かに、普通の配列には無いようなすごい機能です。これがなぜ必要なのでしょうか。
教師あり機械学習においては、入力となるデータと、それに対する正解データが与えられます。入力データを使ってモデルが予測したデータと、実際の正解データとを比べて、その差ができるだけ小さくなるようなモデルにしていきます。予測と正解の違いを表したものを 損失(loss) と言います。損失が小さくなると、モデルによる予測と正解とが近づいたということなので、予測するモデルができているということになります。
微分は、損失が 最小値 となるパラメータを求めるために利用できます。最小値を求める方法として 確率的勾配降下法(Stochastic Gradient Decent、SGD) という手法を紹介します。

形のよく分からないグラフ $y=f(x)$ の最小値を見つけたいとします。
適当なxを1点取ってきて、そこからxをちょっとだけ動かしたときに、yは増えるのか、減るのか、増えるならどれくらいの速さで増えるのか、といったもの(勾配)を計算するのが微分でした。
なんか形のよくわからない関数があっても、微分さえできれば、yが減る方向に向かってxを"良い感じ"に動かしていくことができます。
勾配が正の値であれば、xが増えるとyが増えていくので、xを減らしたほうがyがより小さくなります。
勾配が負の値であれば逆に、xを増やしたほうがyが小さくなります。
勾配を見ながらxを"良い感じ"に動かして、yが最小値になるように調整していきます。
勾配がゼロになればそこが最小値の候補になるのですが、実数上で探索的にやっていくとピッタリゼロになることはなかなか無いかもしれません。
勾配がほとんどゼロになれば最小値候補はすぐ近くにあるのでxはほとんど動かさなくていいですし、逆に勾配の絶対値が大きい値のときはもっと遠くにありそうだということになります。最終的にxをちょっと動かしてもyがほとんど増減しないような点を見つけたら、そこが最小値の候補になります。2
この最小値を求めるための微分計算が便利にできるということが、深層学習をする上で大切です。PyTorchには自動微分機能がついているので、深層学習を便利にできるということのようです。
PyTorchによる機械学習の流れ
実際に、PyTorchによる簡単な機械学習を実装することで、PyTorchが何をしているのか見ていきましょう。特に、テンソルの微分機能をどう使っているのかに着目します。
PyTorchによる機械学習
ペンギンのデータセットを用いて、ジェンツーペンギンのクチバシの長さ(length)を$x$、深さ(depth)を$y$とし、$x$から$y$を予測する問題を考えます。
このペンギンのデータセットはbokehというグラフ描画ライブラリにサンプルデータとして添付されているパブリックドメインのものです。
まずデータの中をちょっと見てみるために、散布図にプロットしてみます。
from bokeh.plotting import figure, show, output_notebook
from bokeh.sampledata.penguins import data
output_notebook()
data = data.dropna()
data = data[data["species"] == "Gentoo"]
penguin_x = data["bill_length_mm"]
penguin_y = data["bill_depth_mm"]
graph = figure()
graph.circle(penguin_x, penguin_y, fill_alpha=0.2, size=10)
show(graph)
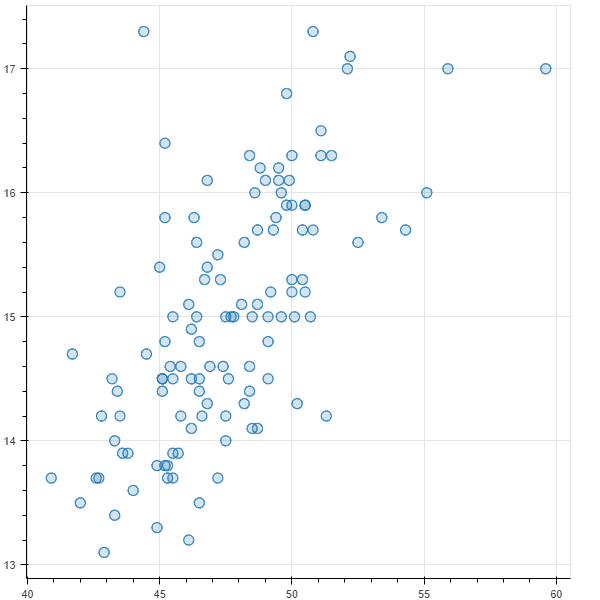
なんとなく右肩上がりになっているっぽい雰囲気があります。今回は、このデータを1次関数(直線)で近似しようとしてみます。回帰分析の各種手法が使えそうだと思う方もいるかもしれませんが、今回はここであえてPyTorchを使うことで、PyTorchによる深層学習の全体像を把握します。
1次関数は$w,b$というふたつのパラメータを用いて $wx+b$ と表現できます。$w$はweight、$b$はbiasから取っています。これら"良い感じ"の$w,b$を見つける、パラメータ2個の機械学習になります。
"良い感じ" とは何かというと、どの$x,y$を取っても、 $wx+b$ で高い精度で予測できること、予測された値と実際の値の差が小さい状態です。ここでは実際の$y$の値と、予測された $wx+b$ の差の二乗の平均値(平均二乗誤差、MSE)を 損失関数(loss) とします。
$$
\text{loss}(w,b)=\frac{1}{n}\sum_{(x,y)}\{ y - (wx+b) \}^2
$$
Pythonのプログラムで書くと以下です。こっちのほうが分かりやすいかもしれません。
# 平均二乗誤差(Mean Squared Error)
def mse(y1, y2):
return ((y1 - y2) ** 2).mean()
この数式の中身自体は自動で計算されるため重要ではありませんが、数式内の$x,y$は正解のデータが与えられていて決まっているものであって、損失関数は$w,b$のふたつのパラメータを変数とした関数になることに注意してください。
この損失関数の値が小さいほど、予測値と実際の値とのあいだのズレが小さい、つまり高い精度で予測できているモデルという事になります。
損失関数が最小値をとる $w,b$ を求めるために、先程の微分機能を用いて最適化していきます。3
先ほど紹介した確率的勾配降下法を用いて、勾配が正だったら$w,b$ を減らし、勾配が負だったら$w,b$ を増やします。
実際には、勾配に 学習率(Learning Rate) を掛けた値を引いていくことでパラメータを更新します。
こうして何回もパラメータを更新していくことで、損失関数を最小値に近づけていきます。この更新回数を エポック数 と呼びます。
これを数式で表してみます。最適化していくパラメータ $ \theta \in \{ w,b \}$, 学習率 $a$ , 損失関数の勾配 $\nabla f(\theta)$ とおくと、 $n$ 回更新したあとの次のパラメータ $\theta_{n+1}$ は以下のようになります。
$$
\theta_{n+1} = \theta_n - a \nabla f(\theta_i)
$$
Pythonで書くと以下のような感じです。結局このコードが一番分かりやすいかもしれません。
parameter -= learning_rate * parameter.grad
ところでPyTorchのテンソルの仕様上、parameterにはrequire_grad=Trueが設定されていて勾配を記録している途中の状態になっていると、そのままでは新しい値を代入できずエラーになります。
no_grad()を呼ぶと、勾配の記録を一時停止できます。これで新しい値を代入できます。
with torch.no_grad():
parameter -= learning_rate * parameter.grad
ここで登場した学習率やエポック数は ハイパーパラメータ と呼ばれるもので、「パラメータを決めるためのパラメータ」「学習によって機械が決めるパラメータではなく、人間が設定する必要があるパラメータ」というイメージです。常に最適な値があるわけではなく、良い機械学習モデルが作れるようにチューニングする必要があります。
一般的には、学習率を小さくするほど、より少しずつ最小値に近づいていくようになるため、エポック数が多く必要になりますが、そのぶん高い精度で予測ができるモデルになります。
さて、実際のPyTorchで機械学習をするコードは以下のようになります。何度もループを回しながら、損失関数が最小になるよう、パラメータを更新していることが分かると思います。
# エポック数(学習の繰り返し回数)
num_epochs = 20
# 学習率(パラメータを更新するとき、勾配の何倍で更新するか)
learning_rate = 0.0001
# 学習用データをテンソルにする
tensor_x = torch.tensor(penguin_x.values).float()
tensor_y = torch.tensor(penguin_y.values).float()
# パラメータ w, b をテンソルにする
# 初期値は適当に1.0としている(1.0に意味は無い。実際には乱数も使われたりする)
# requires_gradで勾配計算を有効にしている
tensor_weight = torch.tensor(1.0, requires_grad=True).float()
tensor_bias = torch.tensor(1.0, requires_grad=True).float()
# 平均二乗誤差(Mean Squared Error)
def mse(y1, y2):
return ((y1 - y2) ** 2).mean()
# 予測関数 wx + b
def predict(x):
return tensor_weight * x + tensor_bias
# 履歴保存用
history = []
# 学習
for epoch in range(num_epochs):
# yの値を予測
tensor_predicted_y = predict(tensor_x)
# 損失の計算
loss = mse(tensor_predicted_y, tensor_y)
# 勾配の計算
loss.backward()
# 勾配の計算を一旦無効にしないとパラメータ更新ができない
with torch.no_grad():
# パラメータの更新
tensor_weight -= learning_rate * tensor_weight.grad
tensor_bias -= learning_rate * tensor_bias.grad
# 記録された勾配をゼロに戻す(ループして再度計算される)
tensor_weight.grad.zero_()
tensor_bias.grad.zero_()
# historyの記録
history.append((epoch, loss.item()))
print(f"loss: {history[0][1]} -> {history[-1][1]}")
print(f"weight: {tensor_weight}")
print(f"bias: {tensor_bias}")
実行結果は以下のようになりました。
loss: 1133.599365234375 -> 0.6236760020256042
weight: 0.29419150948524475
bias: 0.9852942228317261
損失の値が最初1133もあったのが、20回のパラメータ更新によって0.62まで小さくなりました。
損失の推移をグラフで見てみます。
graph = figure()
graph.line(list(map(lambda r: r[0], history)), list(map(lambda r: r[1], history)))
show(graph)
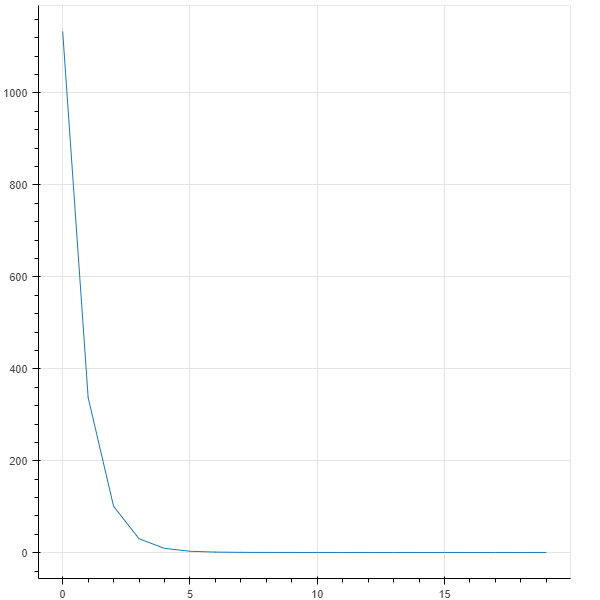
損失が順調に収束していることがわかります。
「損失が最初は大きい値だったが学習を繰り返すと小さくなった」ということは、最初はデタラメな予測だったものが、だんだん正確な予測になっていったということを示しています。
実際に予測されたモデルの一次関数のグラフを、最初の散布図に重ねて見てみます。
graph = figure()
graph.circle(penguin_x, penguin_y, fill_alpha=0.2, size=10)
graph.line(tensor_x.detach().numpy(), predict(tensor_x).detach().numpy())
show(graph)
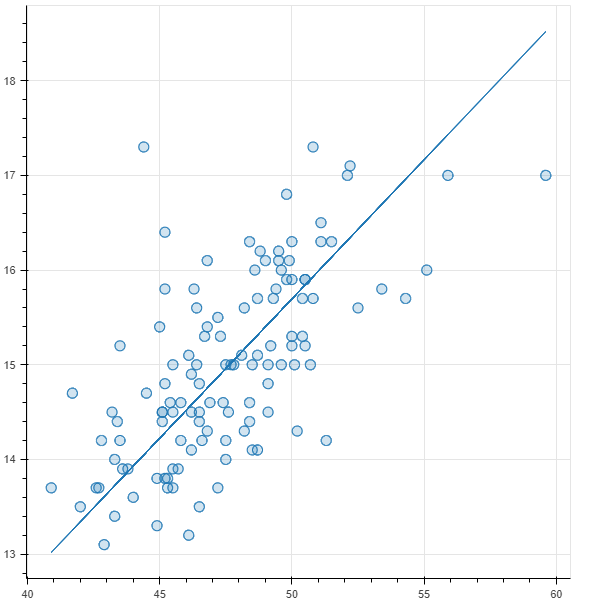
良い感じの右肩上がりの直線になっています。
この例では入力のxは1個(1次元)だけ、パラメータも$w,b$の2個だけ、というシンプルな例でした。予測対象が複雑だったりすると、数字が増えていきます。入力も単なる数値でしたが、画像を入力するために何百次元といったデータが登場したりします。
そうなると、テンソルでGPUが使えるなどPyTorchの強みが出てくると思います。
逆に言うと、今回の例のように単純な2パラメータの線形回帰モデルでさえ数十行もかかりました。今回やってみた「線形回帰」は、本来この手の機械学習問題の中でも非常に初歩的な手法であり、他のライブラリを使えば簡単に解くことができます。「プログラミングを楽にするためのフレームワーク」として見ると、正直PyTorchは貧弱に感じます。
後述するPyTorchの便利な関数などを使ってもう少し短縮することはできます。ですが個人的には、こういった機械学習における数式処理を明示的にプログラムへ落とし込むことができる表現力や、各種関数の部品としての再利用性が、研究界隈でPyTorchが好まれるポイントなのかなと思っています。すこしPythonプログラムが読めれば「ループを回して学習をしていること」「各種関数によるパラメータの更新」などの、実際の動作を簡単に読み取って、すこし改造してみたりもできると思います。
PyTorchの便利な関数
PyTorchには便利な関数が用意されており、先述のような単純なモデルであれば便利な関数に書き換えることができます。
Loss
損失としてMSEを自前で定義しましたが、こういった関数はPyTorchに用意されています。
criterion = torch.nn.MSELoss()
Optimize
パラメータを更新するときに
-
with torch.no_grad():で勾配の計算を一時停止 - パラメータを、勾配と学習率に基づいて更新
- 記録された勾配をゼロに戻す
という操作を行いましたが、これも便利な関数になっています。
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
この最適化関数のインスタンスは、step()でパラメータを更新し、zero_grad()で勾配をゼロに戻すことができます。
optimizer.step()
optimizer.zero_grad()
線形関数
今回は線形関数による予測モデルを自前で定義しましたが、こういったものはPyTorchに用意されています。入力と出力の個数を与えると、自動的に必要な分だけパラメータを定義してくれます。
# 1入力1出力の線形関数
predict = torch.nn.Linear(1, 1)
torch.nn.init.constant_(predict.weight, 1.0)
torch.nn.init.constant_(predict.bias, 1.0)
Newral Network Module
予測関数をそのままPythonの関数として定義しましたが、torch.nn.Moduleのサブクラスとしてまとめて定義できます。
今回の例では線形関数ひとつの層しかないのであまり恩恵がありませんが、実際の深層学習では、こういった関数を 層(layer) として合成してモデルを作っていきます。いくつもの関数を重ねて複雑な関数を作っていくので、こういった機能の恩恵が出てきます。
class NeuralNetwork(torch.nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.stack = torch.nn.Sequential(
torch.nn.Linear(1, 1),
)
def forward(self, x):
x = self.stack(x)
return x
実際には以下のように利用できます。
# モデル定義
model = NeuralNetwork()
# 予測
outputs = model(tensor_x)
これらの機能を使って学習用のコードを書き直してみると、次のようになります。
num_epochs = 100
learning_rate = 0.0001
class NeuralNetwork(torch.nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.stack = torch.nn.Sequential(
torch.nn.Linear(1, 1),
)
def forward(self, x):
x = self.stack(x)
return x
model = NeuralNetwork()
if torch.cuda.is_available():
model = model.to("cuda")
# 損失関数
criterion = torch.nn.MSELoss()
# 最適化関数
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
history = numpy.zeros((0, 2))
for epoch in range(num_epochs):
# 予測
outputs = model(tensor_x.view(-1, 1))
# 損失の計算
loss = criterion(outputs, tensor_y.view(-1, 1))
loss.backward()
# パラメータの更新
optimizer.step()
optimizer.zero_grad()
history = numpy.vstack((history, numpy.array([epoch, loss.item()])))
print(f"loss: {history[0][1]} -> {history[-1][1]}")
print(f"weight: {tensor_weight}")
print(f"weight: {tensor_bias}")
相変わらずすっきりしたコードとは言えませんが、各所で計算していた処理が一切無くなってPyTorch付属の物に置き換わることで、再利用性の高さを示せているのではないかと思います。
まとめ
- PyTorchは深層学習のフレームワーク
- PyTorchはテンソル扱うことができ、自動微分機能が付いている
- PyTorchにはデータローダー、最適化、損失などの関数が用意されている
ここまでの知識があれば、Stable Diffusionのサンプルコードで使われているPyTorchの機能なども、多少は読み解きやすくなると思います。Stable Diffusionのような高度なモデル自体を理解するのは大変ですが、周辺のコードを少し読み書きできるだけでも、このようにできることが広がると思います。
参考文献
- 最短コースでわかる PyTorch &深層学習プログラミング | 日経BOOKプラス
- PyTorch自然言語処理プログラミング word2vec/LSTM/seq2seq/BERTで日本語テキスト解析! - インプレスブックス