サーバレスプラットフォームである GCP Cloud Run で、Transformersのモデルを動かしてみました。
Transformersの汎用言語モデルを動作させるにはそれなりのスペックが必要になりますが、サーバレスと言うとメモリ等のリソースに厳しい制限があり大きなモデルを動かすようなことは難しい印象です。ですがCloud Runは結構メモリを積める1ので、実は普通に動かせてしまいます。
環境
- Docker version 20.10.11, build dea9396
- Docker Compose version v2.2.1
- Google Cloud SDK 383.0.1
- Cloud Run 第1世代
GCPのサービス内容は2022年5月14日時点のものになっています。
全体のソースコードは下記です。細かい依存関係などはこちらを参照してください。
実装
まずはCloud Runにデプロイする前に、ローカル環境で動作するプログラムを記述していきます。Streamlitを用いて、rinna/japanese-gpt2-xsmallが動作する環境を作っていきます。
本稿ではStreamlitのアプリをCloud Runにデプロイしています。が、後から気付いたのですがStreamlitはCloud Runとあまり相性が良くなく、バージョンによっては動作しません(参考)。
本稿の本質ではないため詳細には触れませんが、実際にCloud Runで本稿のようなアプリケーションを構築したい場合はDashのようなStreamlit以外の選択肢を用いることを推奨します。(Dashによる実装の例)
なおTransformersはオフラインモードにしておき、コンテナのビルド時にモデルをダウンロードしてイメージに含めるようにしています。
ダウンロード用のプログラムは下記です。
from os import environ
from pathlib import Path
import shutil
from huggingface_hub import snapshot_download
downloaded_path = snapshot_download(repo_id=environ["DOWNLOAD_REPO_ID"])
model_path = Path(environ["DOWNLOAD_PATH"]).expanduser()
shutil.move(downloaded_path, model_path)
print('moved', downloaded_path, model_path)
ダウンロードしたモデルを利用して文章を生成するプログラムは下記です。
from os import environ
from pathlib import Path
import torch
from transformers import T5Tokenizer, AutoModelForCausalLM
class Generator():
def __init__(self) -> None:
pretrained = Path(environ["DOWNLOAD_PATH"]).expanduser()
self.tokenizer = T5Tokenizer.from_pretrained(pretrained)
self.model = AutoModelForCausalLM.from_pretrained(pretrained)
def generate(self, input_text: str, max_length: int=200):
token_ids = self.tokenizer.encode(input_text, add_special_tokens=False, return_tensors="pt")
with torch.no_grad():
output_ids = self.model.generate(
token_ids.to(self.model.device),
max_length=max_length,
do_sample=True,
top_k=500,
top_p=0.95,
pad_token_id=self.tokenizer.pad_token_id,
bos_token_id=self.tokenizer.bos_token_id,
eos_token_id=self.tokenizer.eos_token_id,
bad_word_ids=[[self.tokenizer.unk_token_id]]
)
return self.tokenizer.decode(output_ids.tolist()[0])
Streamlitで実際に入出力を扱い、モデルを呼び出すプログラムは下記です。
import streamlit
from generator import Generator
generator = Generator()
input_text = streamlit.text_input("入力してね", value="")
if len(input_text) > 0:
streamlit.text(f'入力は「{input_text}」です')
streamlit.text(f'出力は')
generated_text = generator.generate(input_text, 100)
streamlit.markdown(generated_text)
今回環境構築にはPoetryを用いました。依存関係は下記です。
[tool.poetry.dependencies]
python = "^3.9"
streamlit = "^1.9.0"
transformers = "^4.19.1"
sentencepiece = "^0.1.96"
torch = "^1.11.0"
Dockerfileは下記のようになります。実際にはマルチステージビルドを使って開発環境と本番環境を分けたほうがいいと思いますが、本稿では割愛しています。また、後にCloud Runで動作させるための設定も少し入っています。
FROM python:3.9-slim
WORKDIR /app
ENV PYTHONPATH="/app:$PYTHONPATH"
ENV TRANSFORMERS_OFFLINE=1
RUN apt-get update && apt-get install -y \
git \
curl \
build-essential \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/*
RUN pip install poetry
COPY pyproject.toml ./
COPY poetry.lock ./
RUN poetry install
# モデルのダウンロード
ENV DOWNLOAD_REPO_ID="rinna/japanese-gpt2-xsmall"
ENV DOWNLOAD_PATH="~/model"
COPY src/download.py ./
RUN poetry run python download.py
COPY src/ ./src/
# see https://cloud.google.com/run/docs/issues#home
CMD HOME=/root poetry run streamlit run src/gpt_container/streamlit.py --server.address 0.0.0.0 --server.port $PORT
Docker Composeで動作させたいため、下記のようにしておきます。
services:
app:
build: .
volumes:
- .:/app
environment:
- PORT=8000
ports:
- 8000:8000
docker compose upで立ち上げると、こんな感じで動作します。
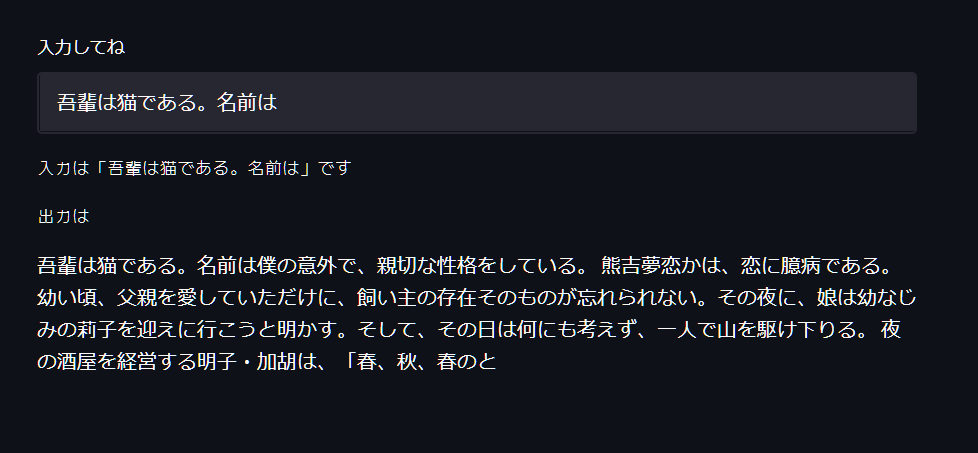
適当な入力に対して文章を生成してくれたら成功です。
Cloud Runへのデプロイ
GCP Cloud Runへデプロイします。今回はローカルでビルドしたイメージをGCP Artifact RegistryにPushして、Cloud Runへデプロイします。
GCPプロジェクトの作成とgcloudコマンドは利用できる状態になっているものとします。GCPのWebコンソールから、Artifact Registryに移動して適当な名前でレジストリを作成しておきましょう。
gcloud auth configure-dockerで、Artifact Registryにpushできるようにします。たとえばasia-northeast2-docker.pkg.devなら以下のコマンドです。
$ gcloud auth configure-docker asia-northeast2-docker.pkg.dev
ビルドします。
$ docker build --tag <イメージ名> .
Artifact Registryにpushします。
$ docker push <イメージ名>
Cloud Runにデプロイします。regionなどはお好みで適当に変えてください。
$ gcloud \
run deploy gpt-container \
--image <イメージ名> \
--platform managed \
--region=asia-northeast2 \
--allow-unauthenticated \
--max-instances=1
これで、生成されたURLにアクセスすると画面が映るはず...なのですが、これではうまく動かないと思います。
Cloud Runのログを見ると、以下のようなエラーが出ていると思います。
JSTMemory limit of 512M exceeded with 803M used. Consider increasing the memory limit, see https://cloud.google.com/run/docs/configuring/memory-limits
メモリが足りませんでした。Cloud Runのデフォルトでは512MiBですが、このモデルを動かすにはもう少しメモリが必要です。増やしてみましょう。
$ gcloud \
run deploy gpt-container \
--image <イメージ名> \
--platform managed \
--region=asia-northeast2 \
--allow-unauthenticated \
--max-instances=1 \
+ --memory=1024Mi
これで、うまく動きました。
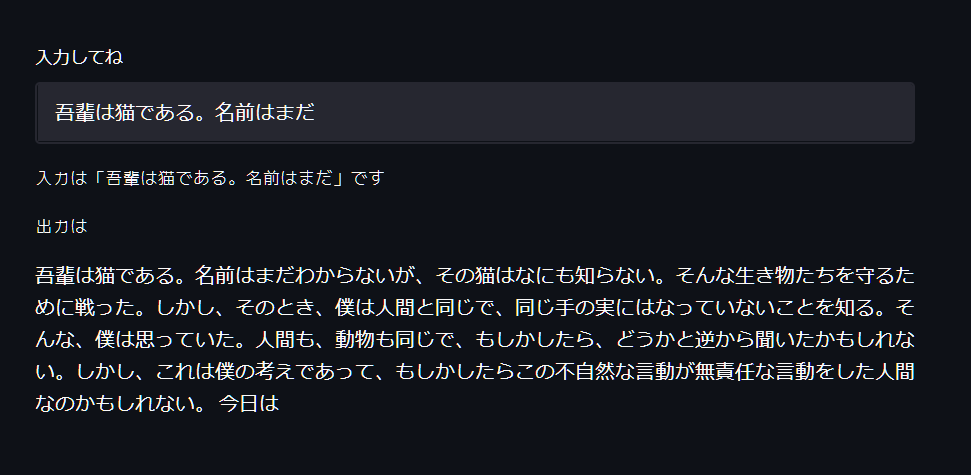
より大きなモデルを動かす
rinna/japanese-gpt2-xsmallを動かしてみましたが、より大きなrinna/japanese-gpt2-mediumを動かしてみましょう。
Dockerfile内でダウンロードするモデルを指定していたので、こちらを変更します。
# モデルのダウンロード
-ENV DOWNLOAD_REPO_ID="rinna/japanese-gpt2-xsmall"
+ENV DOWNLOAD_REPO_ID="rinna/japanese-gpt2-medium"
ENV DOWNLOAD_PATH="~/model"
COPY src/download.py ./
RUN poetry run python download.py
再度ビルド・デプロイをやり直します。先ほどと同様に少ないメモリでは動作しないのでメモリを増やしていくと、いずれ以下のようなエラーが出ると思います。
Deployment failed
ERROR: (gcloud.run.deploy) spec.template.spec.containers[0].resources.limits.memory: Invalid value specified for memory. For 1.0 CPU, memory must be between 128Mi and 4Gi inclusive.
For more troubleshooting guidance, see https://cloud.google.com/run/docs/configuring/memory-limits
1CPUのインスタンスに対して割り当てられるメモリは4GiBまでのようです。これ以上メモリを増やすにはCPUも増やす必要があります。
$ gcloud \
run deploy gpt-container \
--image <イメージ名> \
--platform managed \
--region=asia-northeast2 \
--allow-unauthenticated \
--max-instances=1 \
+ --cpu 2 \
+ --memory=5Gi
動きました。
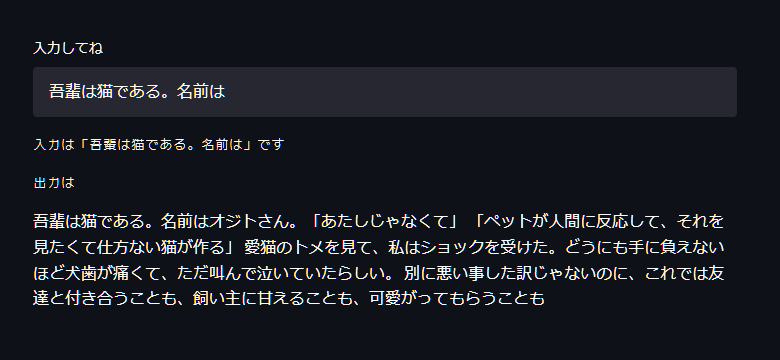
同様にして、rinna/japanese-gpt-1bのモデルも動かしてみました。
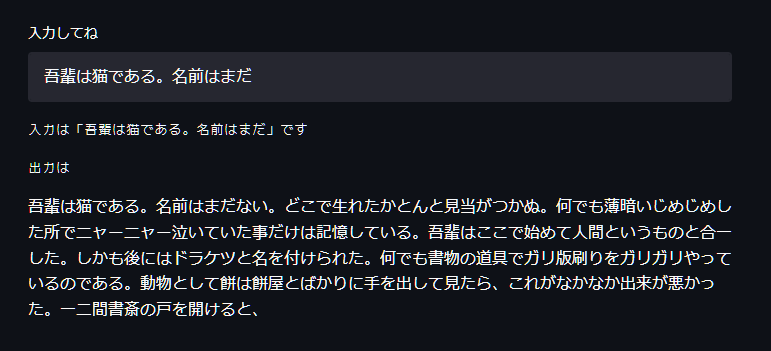
動作を確認できたメモリ・CPUの値は以下になります。
| モデル | パラメータ | メモリ | CPU |
|---|---|---|---|
| rinna/japanese-gpt2-xsmall | 0.37億2 | 1 GiB | 1 |
| rinna/japanese-gpt2-medium | 3.36億2 | 5 GiB | 2 |
| rinna/japanese-gpt-1b | 13億3 | 11 GiB | 4 |
まとめ
13億パラメータのGPT言語モデルをGCP Cloud Runで動かしてみました。このような大規模な言語モデルも、簡単にサーバレスプラットフォーム上で動作させられるようになりました。
一方でCloud RunにはまだCPUしか搭載できません。もしGPU等も選べるようになったら、より扱える幅が広がると思います。
参考
- クイックスタート: ビルドとデプロイ | Cloud Run のドキュメント | Google Cloud
- gcloud run deploy | Google Cloud CLI Documentation
- メモリ上限の構成 | Cloud Run のドキュメント | Google Cloud