はじめに
ECS は CPU 使用率などのメトリクスを条件にコンテナ(タスク)の数を自動的に増減することができます。適切なスケーリング条件を設定することで、コンテナの負荷分散や不要なリソースの削除を行えます。
本記事では CDK で構築した ECS で CPU 負荷の高い処理を実行し、実際にスケーリングが行われることを確認します。
構成
クライアントから HTTP リクエストを受信する ALB と、アプリケーションの処理を行う ECS で構成します。

実行環境
CDK と Docker を実行できる環境で検証しています。
> node -v
v20.10.0
> cdk --version
2.113.0 (build ccd534a)
> tsc --version
Version 5.2.2
> docker --version
Docker version 24.0.7, build afdd53b
ソースコード
CDK スタックと ECS で実行するアプリのソースコードを記載します。
スタック
import * as cdk from 'aws-cdk-lib';
import { Construct } from 'constructs';
import * as path from 'path';
import {
aws_ec2 as ec2,
aws_ecs as ecs,
aws_logs as logs,
aws_elasticloadbalancingv2 as elbv2,
} from 'aws-cdk-lib';
const APP_FOLDER = path.join(__dirname, '../resources/scalable-ecs-app');
const NAME = 'scalable-ecs';
export class ScalableEcsOnCdkStack extends cdk.Stack {
constructor(scope: Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
const vpc = this.createVpc();
const [cluster, service] = this.createEcs(vpc);
const alb = this.createAlb(vpc, service);
}
createVpc() {
return new ec2.Vpc(this, 'Vpc', {
ipAddresses: ec2.IpAddresses.cidr('10.0.0.0/16'),
vpcName: `${NAME}-vpc`,
subnetConfiguration: [
{
cidrMask: 24,
name: 'public',
subnetType: ec2.SubnetType.PUBLIC,
},
{
cidrMask: 24,
name: 'application',
subnetType: ec2.SubnetType.PRIVATE_WITH_EGRESS,
}
]
});
}
createEcs(vpc: ec2.Vpc): [ecs.Cluster, ecs.FargateService] {
const logDriver = new ecs.AwsLogDriver({
streamPrefix: `${NAME}-ecs`,
logRetention: logs.RetentionDays.ONE_WEEK,
});
const fargateTaskDefinition = new ecs.FargateTaskDefinition(this, 'Task', {
cpu: 256,
memoryLimitMiB: 1024,
});
const container = fargateTaskDefinition.addContainer('Container', {
image: ecs.ContainerImage.fromAsset(APP_FOLDER),
portMappings: [{ containerPort: 80, hostPort: 80 }],
logging: logDriver,
stopTimeout: cdk.Duration.seconds(60), // 停止シグナル送信から強制終了までの待ち時間
});
const cluster = new ecs.Cluster(this, 'EcsCluster', {
vpc: vpc,
});
const service = new ecs.FargateService(this, 'Service', {
cluster: cluster,
taskDefinition: fargateTaskDefinition,
//desiredCount: 1, // タスクの数
vpcSubnets: { subnetType: ec2.SubnetType.PRIVATE_WITH_EGRESS }
});
// スケーリング設定
const scaling = service.autoScaleTaskCount({ minCapacity: 2, maxCapacity: 8 });
scaling.scaleOnCpuUtilization('cpuScaling', { targetUtilizationPercent: 20 });
return [cluster, service];
}
createAlb(vpc: ec2.IVpc, ecsService: ecs.FargateService) {
// ALB
const alb = new elbv2.ApplicationLoadBalancer(this, 'Alb', {
vpc: vpc,
vpcSubnets: { subnetType: ec2.SubnetType.PUBLIC },
internetFacing: true
});
// リスナー
const listener = alb.addListener('Listener', {
port: 80,
defaultAction: elbv2.ListenerAction.fixedResponse(404)
});
// ターゲット
listener.addTargets('target', {
port: 80,
targets: [ecsService],
priority: 1,
conditions: [
elbv2.ListenerCondition.httpRequestMethods(['GET'])
],
healthCheck: {
path: '/sleep/1',
port: '80',
// 検証のためにヘルスチェックがNGにならないように長めに設定
interval: cdk.Duration.seconds(300),
unhealthyThresholdCount: 10
},
});
return alb;
}
}
ポイントは以下の2点です。
スケーリング設定
ECS では適切なタスク数を指定し、その数値に沿うようにタスクの運用が行われますが、メトリクスの値によってタスク数を動的に変更するため、タスク数指定の代わりに最小数・最大数を指定しています。
また、スケーリング条件としてCPU使用率を一定に保つように定義しています。この設定によって、CPU使用率が基準値を超える場合はタスクを増やし、基準値を下回る場合はタスクを減らしてくれます。
今回はタスクの最小数を2個、最大数を8個、スケーリングが発生しやすいようにCPU使用率の平均値が 20 %になるように設定しています。
// スケーリング設定
const scaling = service.autoScaleTaskCount({ minCapacity: 2, maxCapacity: 8 });
scaling.scaleOnCpuUtilization('cpuScaling', { targetUtilizationPercent: 20 });
強制終了待ち時間
ECS ではヘルスチェック NG による再構築やスケールインを実施する場合はコンテナ(タスク)を終了しますが、以下の手順で終了します。
- コンテナをALB のターゲットグループから外し、リクエストを受信しないようにする。
- コンテナ上のアプリに対して停止シグナル(SIGTERM)を送信する。
- アプリからのステータスコード受信後にコンテナを終了する。ステータスコードが一定時間返らない場合、強制終了する。
ヘルスチェック NGによるコンテナ強制終了はアプリに何かしらの問題が発生しているためあまり重要ではありませんが、スケールインによりコンテナが強制終了した場合、正常なアプリの処理が途中で終了してしまう可能性があります。
そのため、停止シグナルを受信した場合に終了する処理をアプリに実装し、コンテナの待機時間をアプリの終了時間より長く設定する必要があります。
今回はアプリの最大処理時間を60秒と想定しています。
const container = fargateTaskDefinition.addContainer('Container', {
image: ecs.ContainerImage.fromAsset(APP_FOLDER),
portMappings: [{ containerPort: 80, hostPort: 80 }],
logging: logDriver,
stopTimeout: cdk.Duration.seconds(60), // 停止シグナル送信から強制終了までの待ち時間
});
アプリ
コンテナ上で動かすアプリは Node.js + Express.js で実装します。以下の2機能を有しています。
| パス | 機能 |
|---|---|
| /calc | 無駄な計算を繰り返します。 CPU使用率を上げるために利用します。 |
| /sleep/:time | time 秒間スリープします。 コンテナ終了前にアプリが正常終了することを確認するために利用します。 |
'use strict';
const express = require('express');
const app = express();
const PORT = 80;
// ヘルスチェック
app.get('/calc', calc);
app.get('/sleep/:time', sleep);
const server = app.listen(PORT, async () => {
console.info(`********** Listening on port ${PORT} **********`);
});
process.on('SIGTERM', () => {
console.info(`停止シグナルを受信しました`);
server.close(() => {
console.info(`アプリを終了します`);
process.exit(0);
});
});
function calc(req, res, next) {
let num = 0;
for(let i = 0; i < 1_000_000_000; i++){
num++;
}
console.info(`calc return ${num}`);
res.status(200).send(`num = ${num}`);
}
async function sleep(req, res, next) {
const time = req.params.time;
console.info(`sleep ${time} second(s) start`);
if(time > 60){ res.status(400).send(`time は60秒以下にしてください`) }
await new Promise((resolve) => { setTimeout(() => resolve(true), time * 1000); });
console.info(`sleep ${time} second(s) end`);
res.status(200).send(`sleep ${time} second(s) end`);
}
停止処理
コンテナからの停止シグナル受信時にアプリが正常終了する処理を入れています。
server.close() は新たなリクエストを受信せず、現在のコネクションが無くなったら引数のコールバック関数を実行します。コールバック関数内ではステータスコード0でアプリを終了させています。
「停止シグナル受信」⇒「新規リクエスト遮断」⇒「コネクションが無くなったら終了」という流れにすることにより、クライアントが接続している状態でのアプリ終了を防ぎます。
process.on('SIGTERM', () => {
console.info(`停止シグナルを受信しました`);
server.close(() => {
console.info(`アプリを終了します`);
process.exit(0);
});
});
動作確認
実際にコンソール画面からスケーリングの様子を確認します。
構築直後
まずは構築直後の状態を確認します。
ECS の画面から最小数2個のタスクが構築されていることが分かります。

Cloudwatchのアラーム一覧にはCPU使用率を20%ターゲットにスケーリングするように設定したため、
- CPU使用率が 20% を超える状態が3分間連続で続いた場合にスケールアウト
- CPU使用率が 18% を下回る状態が15分連続で続いた場合にスケールイン
の2個のアラームが作成されました。
閾値を3 分連続で超えた場合にスケールアウト、閾値を15分連続で10%下回る場合にスケールインの条件が作成されるようです。
スケールインの条件は満たしていますが、すでにタスクが最小数のためスケールインは発生しません。

メトリクスを確認すると、初期構築後はほぼ負荷がない状態であることが分かります。
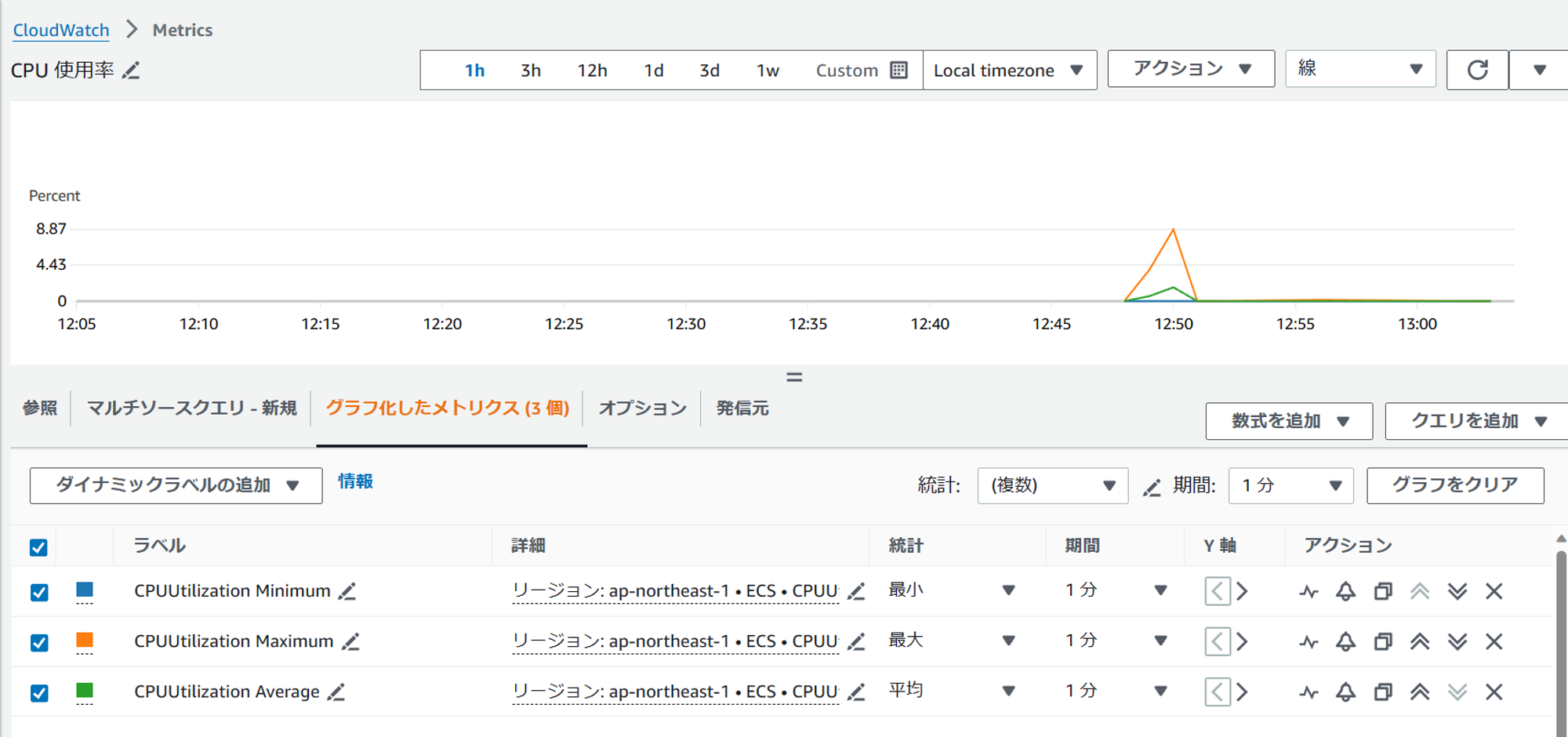
スケールアウト
次に10並列で /calc へ HTTP リクエストを送信しCPU使用率を上げます。実際にスケールアウトが実行されることを確認します。
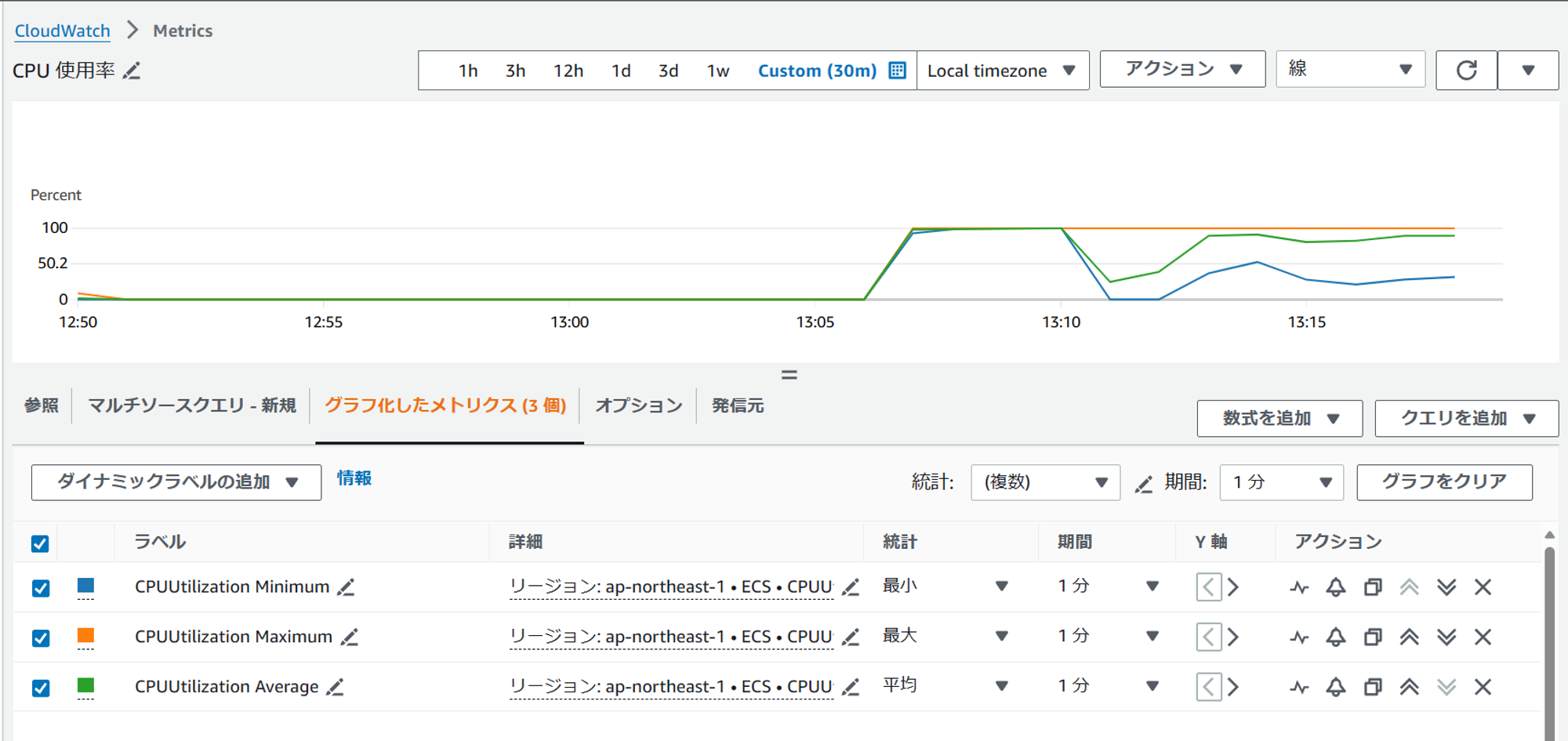
以下が負荷をかけたときのメトリクスです。
CPU使用率が100%まで上昇し、一時的に下がった後、再度上昇しています。スケールアウトによってCPU使用率が下がったことが分かります。
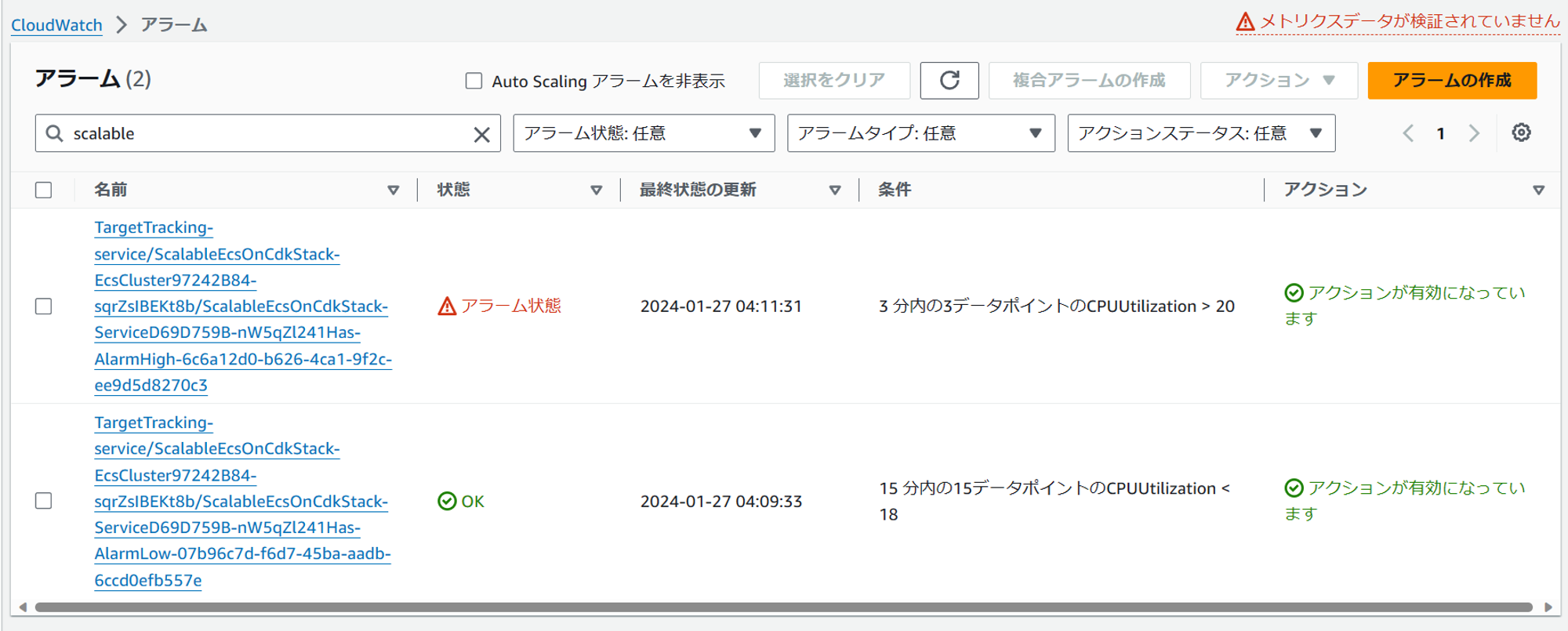
アラームを確認すると、スケールインアラームがOKに、スケールアウトアラームがNGになっています。
ECS の画面からは、タスクが8個まで増加したことが分かります。

スケールイン
最後に /calc への HTTP リクエストを停止し、CPU使用率を下げます。実際にスケールアウトが実行されることを確認します。また、 /sleep/60 へ10並列で HTTP リクエストを送信し、処理に60秒かかる場合でもスケールイン時にアプリが正常終了することを確認できるようにします。
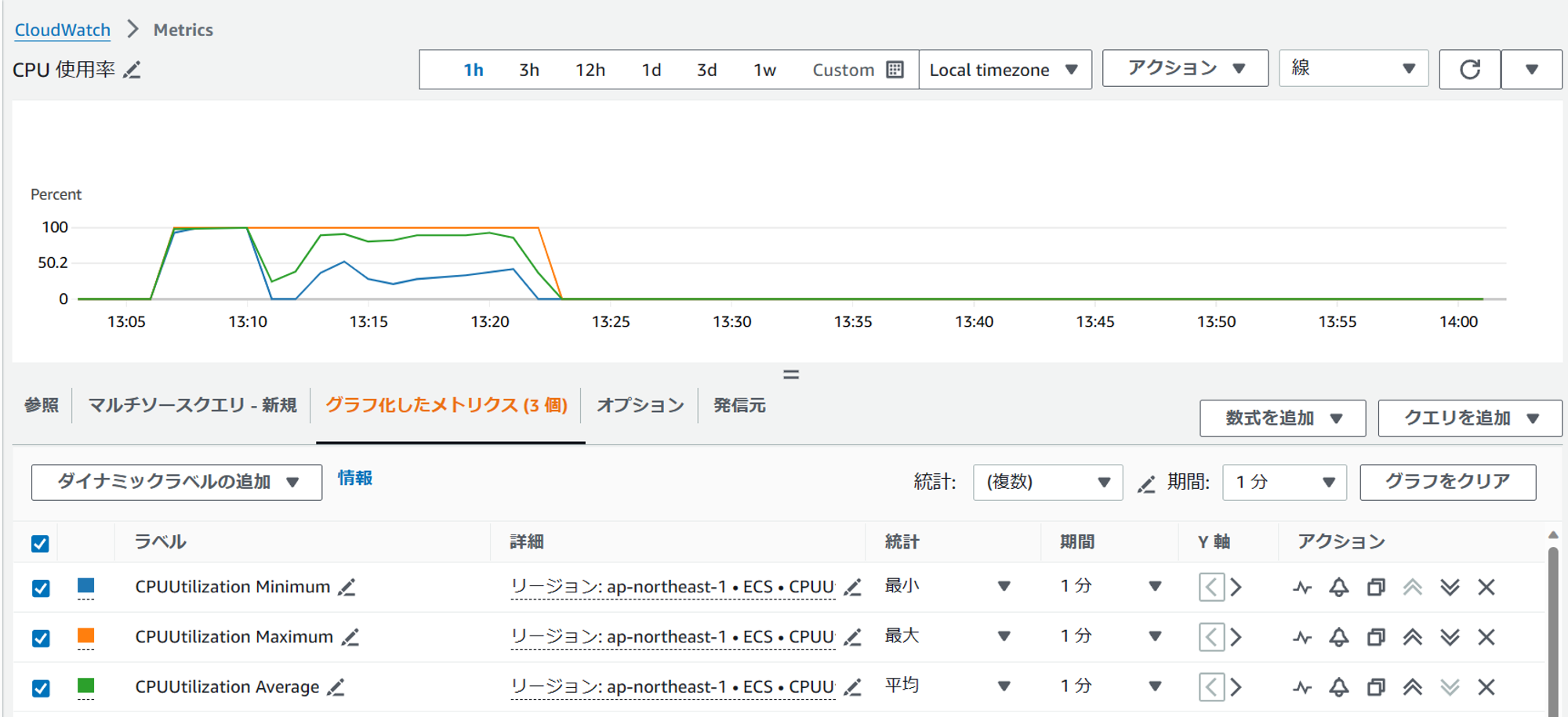
メトリクスから、CPU使用率が0%まで下がっていることが確認できます。
アラームを確認すると、スケールインアラームがNGに、スケールアウトアラームがOKになっています。
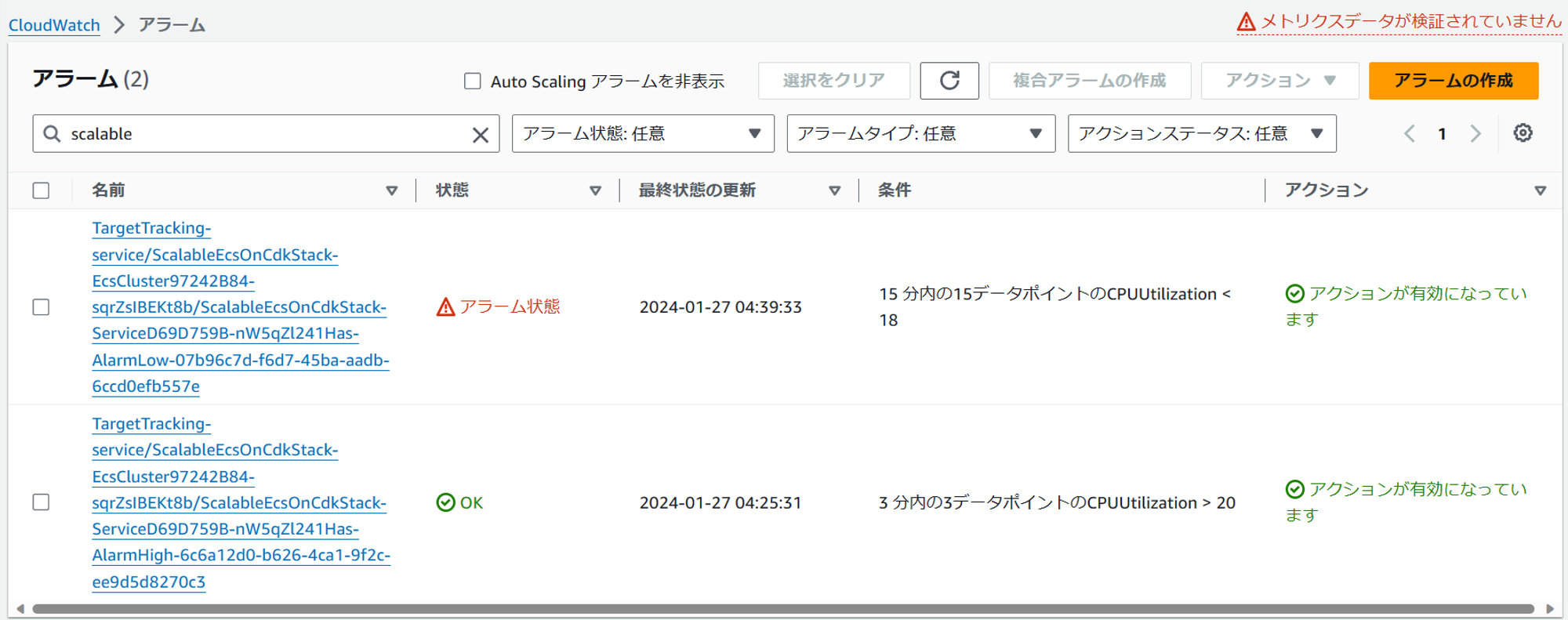
ECS の画面からは、タスクが6個停止し2個に減少したことが分かります。
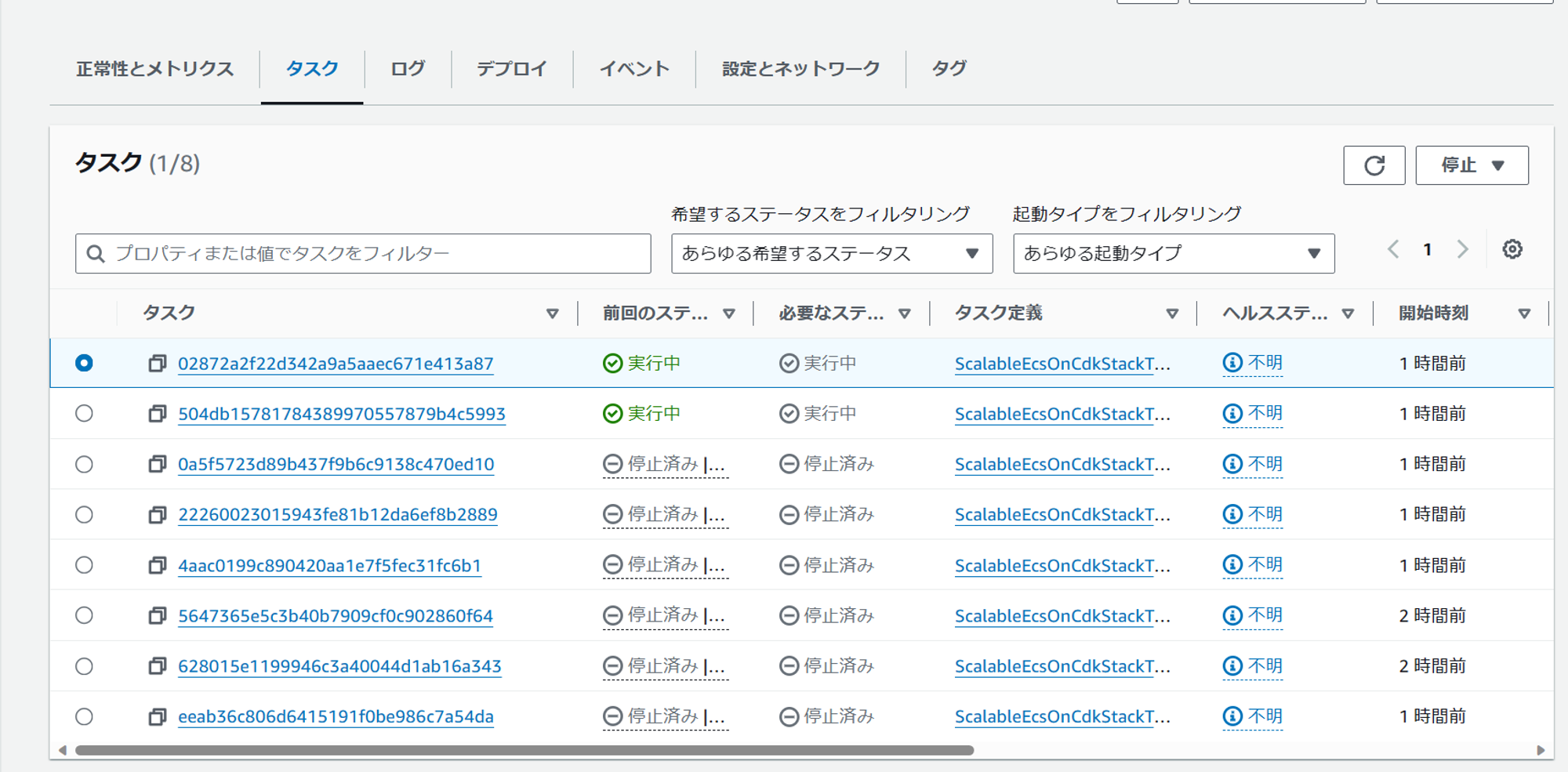
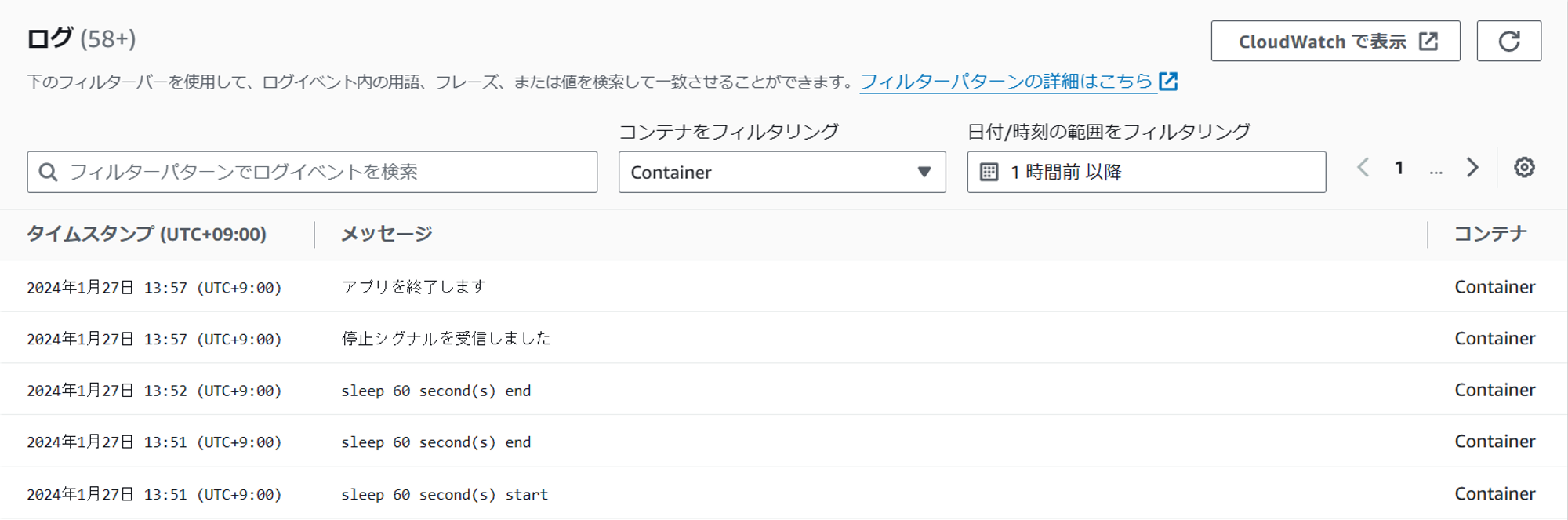
停止したタスクのログを確認すると、最後に Sleep リクエストを受信してから約5分後に停止シグナルを受信していました。
どうやら「ターゲットグループから削除」⇒「コンテナ停止シグナル」まで一定時間空いているようです。長時間の処理を行わないコンテナの場合、停止シグナル処理が無くても処理中にアプリが停止することは無さそうです。
参考資料
Linux シグナルの基本と仕組み (カーネル v5.5 時点) #Linux - Qiita
ECS のアプリケーションを正常にシャットダウンする方法 | Amazon Web Services ブログ