Autify x ZOZO x dipさんが共同開催の「AWSコスト削減事例祭り」というイベントの参加レポートとなります。
アーカイブ
塵も積もれば山となるコスト削減の話(Autify 松浦さん)
Autifyさんはソフトウェアのテストをノーコードで作成することができる製品を提供。
元々Webサービスに対するテストを作成できる製品があり、その後にモバイルアプリをテストできるサービスをリリース。
以下のような構成がAWS上で動いている。
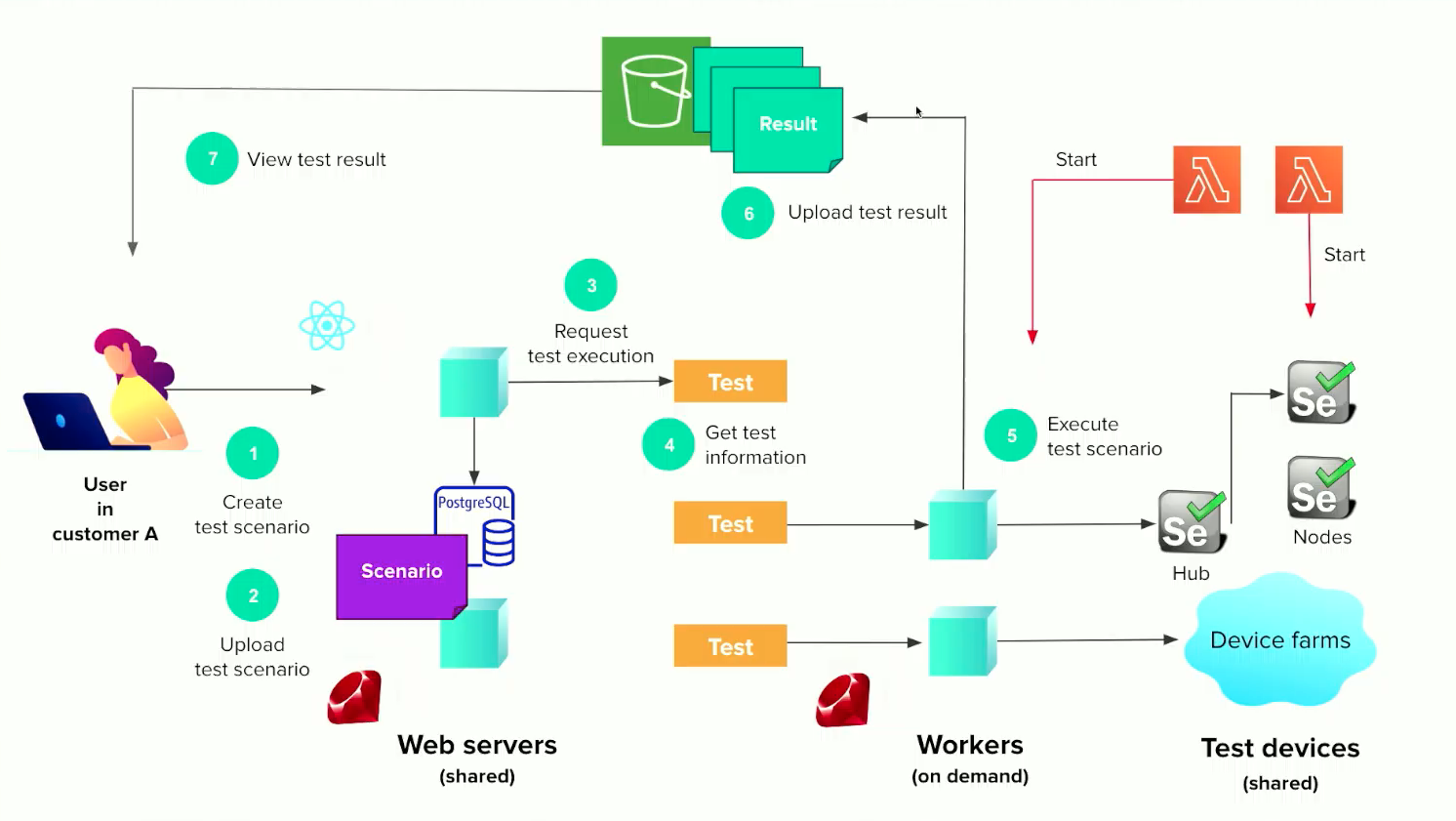
まずは、ワーカーとテストデバイスをFargateに移行してコストを最適化。
この最適化のおかげでお客様が増えれば売り上げも増えるような仕組みとなった。
モバイルアプリに対するテストをするサービスをリリースしたことで、急にコスト増加。
原因は以下
- 開発用インスタンスの一時的な軌道
- ユーザが少なくコスト効率が悪い
- Web障害からの学びで大きめのインスタンスを使っていた
それをきっかけにコストの見直しを実施
コスト削減の具体策
- NATゲートウェイを通るトラフィック
- VPC Endpointを設定して回避していたかと思いきや、実はVPC Endpointが存在していないリージョンもあったため、適切に設定
- 静的IPを付与する目的でNAT Gatewayを使っていたが、実は動的IPでいいコンポーネントもあったのでSGを制限をした上でパブリックサブネットへ移動。
- S3のストレージ費用
- Intelligent tieringを有効化
- 既存データが多くあったため、Intelligent tiering有効化直後、一時的にコストが増大したが長期的に考えればコスト効率は良くなる想定。
- EC2/RDSのインスタンスタイプ、EBSボリューム
- ストレージタイプをio2 → gp2/3へ変更し最適化
- 基本CloudWatchに送っていた
- リアルタイム性が低かったり、検索の必要性が低いものは、削除もしくはS3に送った。
- 監視に使っていたDatadogにもログを送りすぎた
- CloudWatchで見れるものはDatadogには送らない
- 必要ない監視項目は削除
- その他
- ECRの不要なイメージ削除
- Packer(AWSで言うところのAMI見たいなイメージを作ってくれるツール)が途中で失敗したインスタンスを削除する仕組みを導入
その他にもコストの可視化BIツールで可視化
例:インフラコストが売上の何%なのか
今やってること
- リソースごとにタグづけ
- コンポーネント、リージョンごとに
- Terraformを用いて一括でタグが付けられて便利
- Savings Planの購入も進めている
- Fargate(EC2)からEC2(EKS)への移行
- CPUよりメモリの方が重要なコンテナが必要な場合、FargateだとCPUとメモリの割合が固定なので使い方とマッチしていない。
- 最終的にメモリが大きなEC2にコンテナを詰め込む方が効率的と考えた
- コンテナキャッシュなるものも使えるらしい
まとめ
以下が重要
- コストが上がれば、その分売り上げも増えるようなシステム構成を選ぶ
- 定期的なシステム見直し
- コストの可視化
また、SAA,SAPの試験ではコスト管理も学べるのでオススメ!
感想
NAT Gatewayのコストを削減する方法としてVPC Endpointを使う話やS3のIntelligent tiering有効化後、既存リソースが多いと一時的にコストが発生してしまう話など知らなかった内容があってとても勉強になりました。
WEARのEKSコストを救いたい(ZOZO 小林さん)
ファッションのZOZOTOWNでお馴染みのZOZOさんが展開しているWEARというファッションコーディネートアプリについてのお話。
EKSのバッチ処理ワークフローを実行するクラスターのコストが想定を超えて増加
EKSを実行するFargateの使用量増加が大きな要因。
EKSのコストは
EKSクラスター自体のコスト + Kubernetesのワーカーノード(ECS, EC2)
で計算される
具体策
- Datadogから実際のメトリクスを確認して、Fargate Podのスペックを調整
- 不要なFargate Podの自動削除
- 稀にワークフローが完了しても削除されないPodが存在したので、ワークフロー完了から一定時間後にPodが削除されるような設定を入れた。
- Image Pull速度の改善
- Fargateの課金はイメージをプルする時点から始まるため、コンテナイメージを圧縮し、イメージサイズを小さくした。
- WEARの場合、イメージを圧縮してもそこまでイメージをプルする速度に影響を及ぼさなかったため、後回しにしている。
- EKS on FargateからEKS on EC2へ移行
- これは現在検証中
- EC2 Managed Node Groupを活用して運用コストを削減
- 単純なEKS on EC2ではなくPodの性質ごとに配置するノードを調整 → Podごとにインスタンスタイプを変える等
まとめ
以下の3点が重要
- まずはコストをWatchすること
- サービスのリソースを観測し続ける
- 現状に合わせたシステムの最適化
感想
今までEKSを食わず嫌いしていたのですが、具体的に利用されているケースや費用面の話を聞くことができ、自分の中でEKSのユースケースが見えてきたのでとても勉強になりました。
awsコスト分析サービスを利用したコスト最適化(dip ジョンフンモさん)
dipさんはバイト探しの「バイトル」などのサービスを展開。
今回はEC2, RDS, ElastiCacheにかかるコスト最適化したお話
- AWS Trusted Adviserを使用
- AWS ComputeOptimizerも使用
- 最近FargateでのECSサービスの最適化に対応!
また、コスト分析レポートを作成
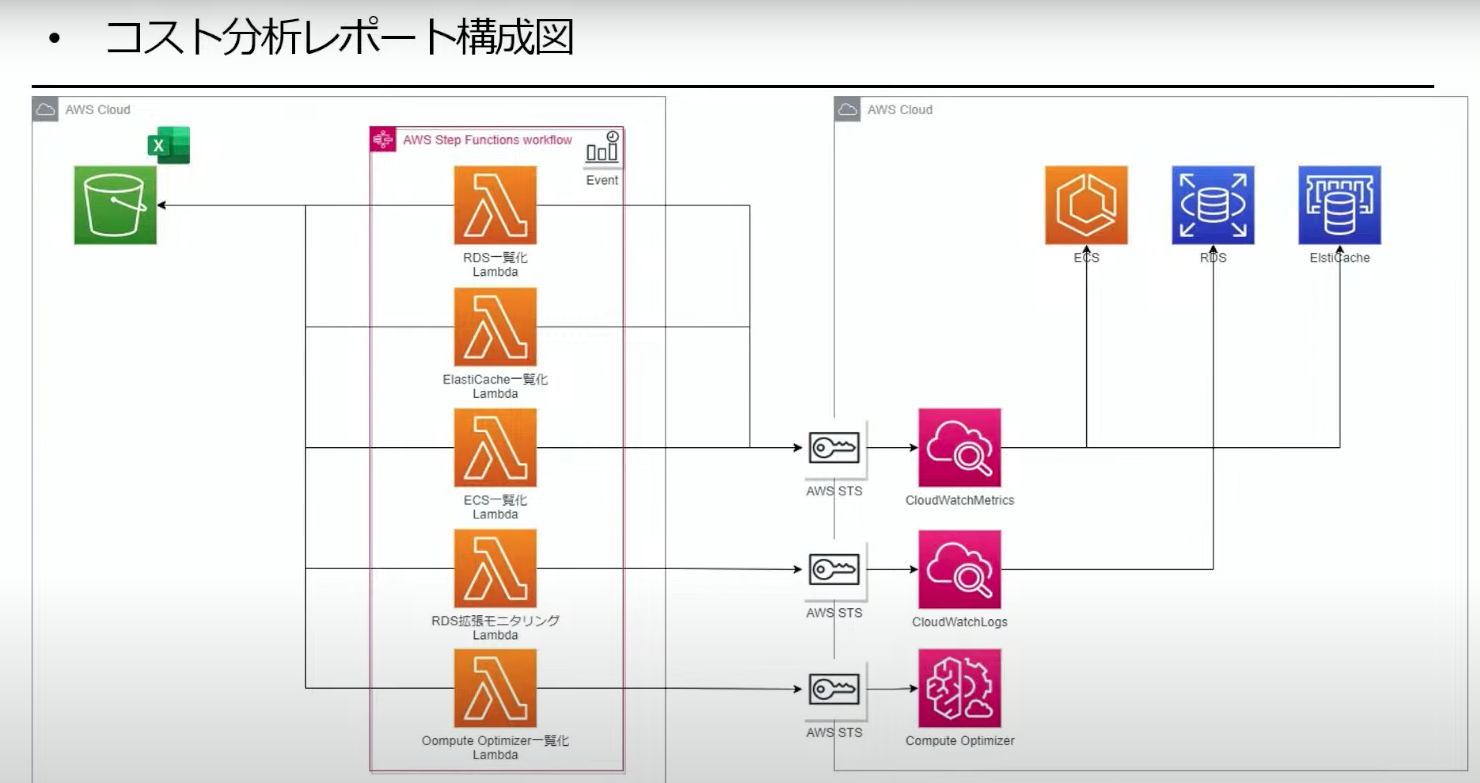
- 毎月1日にLambdaで情報を収集
- ComputeOptimizerで対応していないリソース(RDS, ElastiCache)はCloudWatchのメトリクスとログを取得
- レポートの情報を参考にインスタンスタイプやサイズを変更
また、インスタンスサイズ変更して、安定してきたことを確認したのちに、コンピューティングリソースはSavings Plan、RDSとElastiCacheに対してはReserved Instancesを購入。
感想
以前、EC2に対してAWS Compute Optimizerを使用した最適化を実施したことがあったので、とても共感する部分がありました。
また、ECSやRDS, ElastiCacheの最適化はやったことがなかったので参考にしたいと思いました。
プロダクト間のデータ連携をイベント駆動で作り直した話(dip 藤中さん)
先ほど出てきたバイトルとコボットという履歴書の送付、面接の日程調整を効率的にできるようにするサービスのお話。
コボットでバイトル側のデータも見えるようにするためのシステムは従来以下のような構成だった。
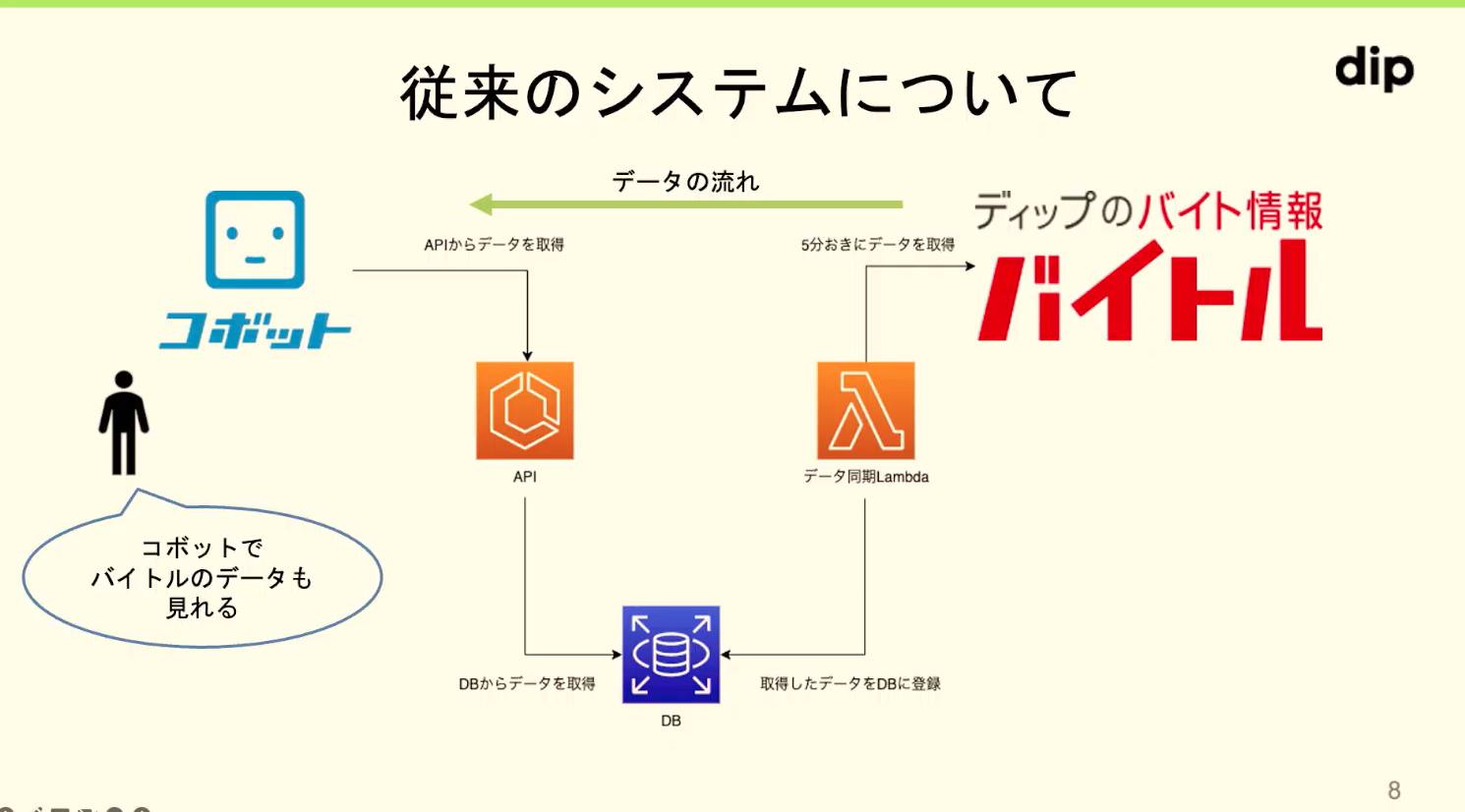
この構成は利用者が増加してコボットのAPIアクセスが増加、DBが高負荷、不安定になった。
そのためDBのレプリカを作成して安定化。
この構成の問題として
- DBサーバの増設によるコストの増加
- 5分に1回バイトルのデータを同期しているためタイムラグが発生
そこで、イベント駆動モデルの即時連携できるシステムを作ることに
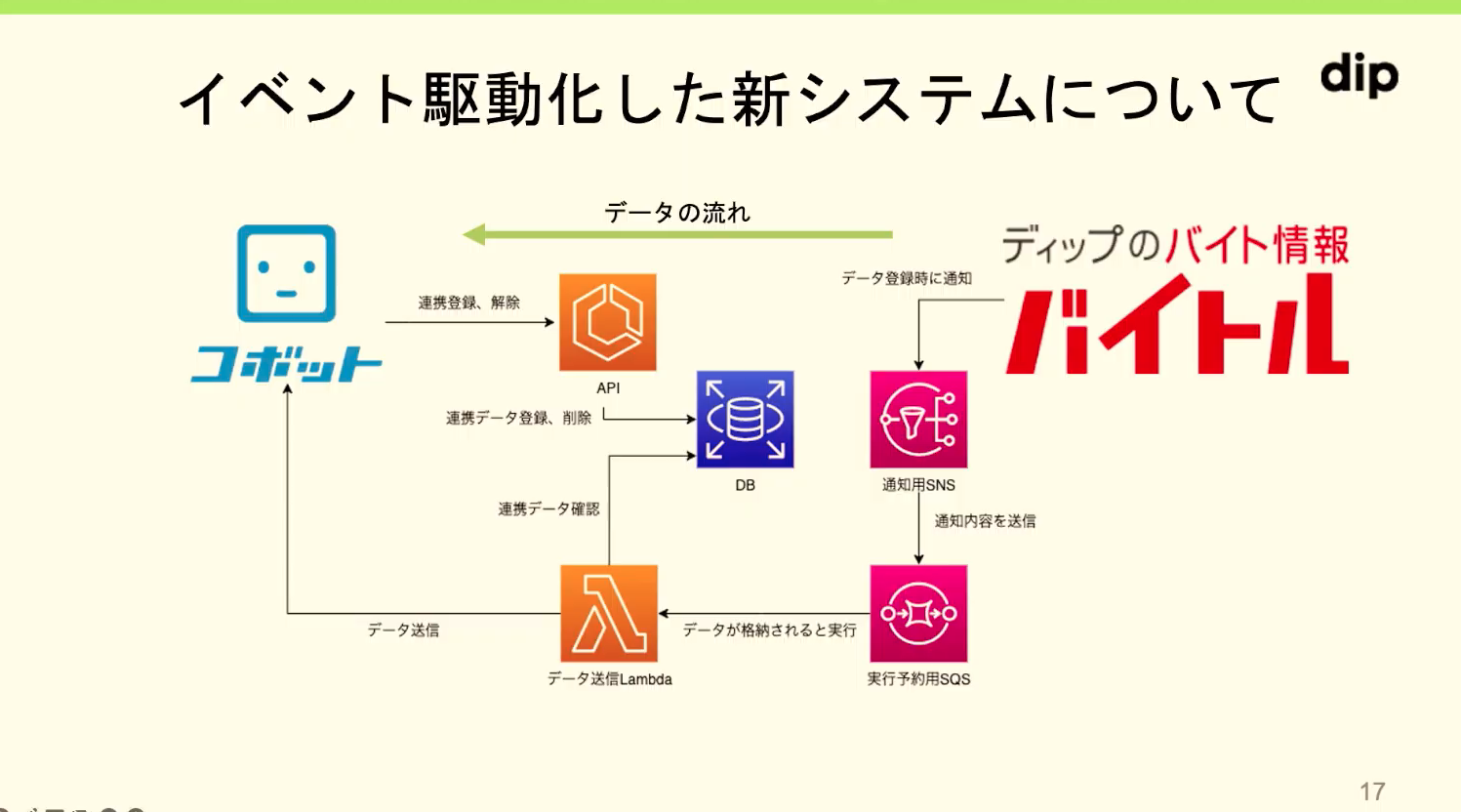
バイトルでデータを登録するとそれをトリガーにコボットにデータを送信するようなシステムに
これによって、インフラコストが1/10、タイムラグがなくなり即時連携のシステムとなった。
システムを作り替えて
良かったこと
- SNSの通知トリガーを他のプロダクトでも使用できた
大変だったこと
- バイトルも改修が必要となり、改修範囲が広範囲に
- LambdaのCI/CD環境の設計
感想
良かったことにあった、「SNSの通知トリガーを他のプロダクトでも使用できた」というところについて、あるサービスで使用したコンポーネントが別のサービスに転用できて、これぞマイクロサービスアーキテクチャの醍醐味だなとテンションが上がりました!