はじめに
8月から機械学習の案件を行うことになり、最近学習をはじめました。
統計やPythonまわりについて、自分用のメモとして記事を書いていこうと思います。
Feature Scalingとは
Feature Scaling(特徴量スケーリング)は機械学習の前処理の1つで、KNNなどのアルゴリズムで真価を発揮します。
例えば、特徴量によって単位や値の大きさが違っているときに、各次元の関係をわかりやすくすることで、学習モデルの精度改善ができます(言いかえると、特徴量による単位や値の大きさの違いが学習モデルに影響を及ぼさないような決定木などのアルゴリズムには、Feature Scalingは不要となります)。
標準化と正規化
Feature Scalingの代表的な手法として、標準化と正規化があります。
標準化(Standardization)
標準化は元のデータの平均を0、標準偏差を1のものへと変換する手法で、Z-score normalizationとも呼ばれます。
一般的に、標準化は最大値や最小値が決まっていない場合や外れ値が存在する場合に利用されます。
Z-scoreは以下のように求められます。
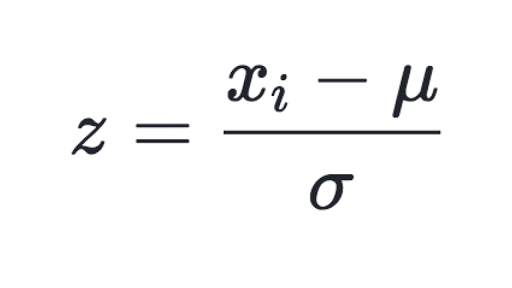
また、sklearnで標準化を行う場合には、StandardScalerを使用します。
標準化は説明変数(X_train, X_test)のみに対して行います。
目的変数(y)を標準化してしまうとそもそもの予測対象の値が変わってしまうため、yの標準化は不要となります。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
正規化(Normalization)
正規化は特徴量を最小値0、最大値1の範囲に変換する手法です。
標準化と異なり、外れ値がスケーリングに与える影響が大きいため、最大値と最小値が決まっている場合(画像処理など)に使用されます。
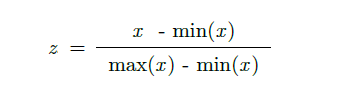
sklearnで正規化を行う場合、MinMaxScalerを使用します(使い方はStandardScalerとほぼ同じため割愛)。
fit, transform, fit_transformの使い分け
sklearnのスケーリング関数(StandardScalerやMinMaxScaler)にはfit, transform, fit_transformというメソッドがあります。
fit関数
データを変換するために必要な統計データ(標準化であれば標準偏差σと平均値μ、正規化であれば最大値Xmaxと最小値Xmin)を計算します。
fitは訓練データのみに適用し、テストデータには適用しません。
transform関数
fit関数で計算した統計データを元にスケーリング(標準化、正規化)を実行します。
fit_transform関数
fit関数とtransform関数をつなげて実行します。
fit_transformがあればfitやtransformが必要なさそうにみえますが、そのようなことはありません。
というのも、テストデータの変換には、 訓練データで計算された統計データを使用する必要があるためです。
テストデータにはfit_transformを使わないよう、以下の流れでFeature Scalingを行いましょう。
- 訓練データとテストデータを分割する
- トレーニングデータをfitする
- トレーニングデータをtransformする
- テストデータをtransformする
参考資料