はじめに
Hold-out Validationとk-Fold Cross Validationについてまとめました。
Hold-out Validation(ホールドアウト検証)
Hold-out Validationは、全てのデータを任意の割合で訓練データ、検証データ、テストデータに分割して検証する方法です。
検証データは、モデルの訓練後にハイパーパラメータを調整するために用います。
パラメータ調整に用いた検証データを流用してテストを行うと、未使用のデータを用いるよりもエラー率が低くなり、最終的なパフォーマンス計測には適していません。
そのため、未使用のデータとしてテストデータも別に用意する必要があります。
以下が検証データも含めたRidge回帰の例です。
α=100, 1でそれぞれRidge回帰を行い、検証データによって適したαを選択し、テストデータで最終パフォーマンスを評価しています。
from sklearn.model_selection import train_test_split
# 訓練データを70%、その他データを30%に分割
X_train, X_OTHER, y_train, y_OTHER = train_test_split(X, y, test_size=0.3, random_state=101)
# その他データを半々に検証データとテストデータに分割
X_eval, X_test, y_eval, y_test = train_test_split(X_OTHER, y_OTHER, test_size=0.5, random_state=101)
# データ(訓練、検証、テスト)の標準化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_eval = scaler.transform(X_eval)
X_test = scaler.transform(X_test)
# Ridgeインポート
from sklearn.linear_model import Ridge
from sklearn.metrics import mean_squared_error
# α=100で訓練、MSE導出
model = Ridge(alpha=100)
model.fit(X_train,y_train)
y_eval_pred = model.predict(X_eval)
mean_squared_error(y_eval,y_eval_pred)
# α=1で訓練、MSE導出
model = Ridge(alpha=1)
model.fit(X_train,y_train)
y_eval_pred = model.predict(X_eval)
mean_squared_error(y_eval,y_eval_pred)
# テストデータで最終パフォーマンス(MSE)を評価
y_final_test_pred = model.predict(X_test)
mean_squared_error(y_test,y_final_test_pred)
ただ、Hold-out Validationには、分割したデータに偏りがある場合に正確な検証ができなくなるという問題があります。
偏りに性能評価が影響されない検証方法としては、Stratified k-Fold Cross Validationがあります。
k-Fold Cross Validation(k分割交差検証)
k-Fold Cross Validationは、データをK個に分割して、そのうちの1つをテストデータ、残りのK-1個を訓練データとして使い、モデルの学習を行うCross Validationの手法の1つです。
以下の図はデータを5つに分割する場合の例です。

5つに分割したデータのうち、4つを訓練用、1つをテスト用として学習します。
そして、テストデータの位置を1つずつずらして学習し、最終的に5つのモデルを作成します。
最後に、5つのモデルの精度を評価し、平均化して最終的に一つのモデルに融合します。
ただ、k-Foldの場合は、データの分割をランダムに行うため、データの偏りなどは考慮されません。
データ数に偏りがある場合は正しくモデル性能を評価できないため、そのときはStratified k-Fold Cross Validationを使います。
cross_val_score
sklearnでk-Fold Cross Validationを実装するための関数の1つとして、cross_val_scoreがあります。
各モデルに対して指定した評価指標(スコア)を配列で返します。
from sklearn.model_selection import cross_val_score
# Cross Validationの各モデルのスコアの配列を返す
# スコアにはNegative MSEを指定(高いほどいい)
scores = cross_val_score(model,X_train,y_train,scoring='neg_mean_squared_error',cv=5)

cross_validate
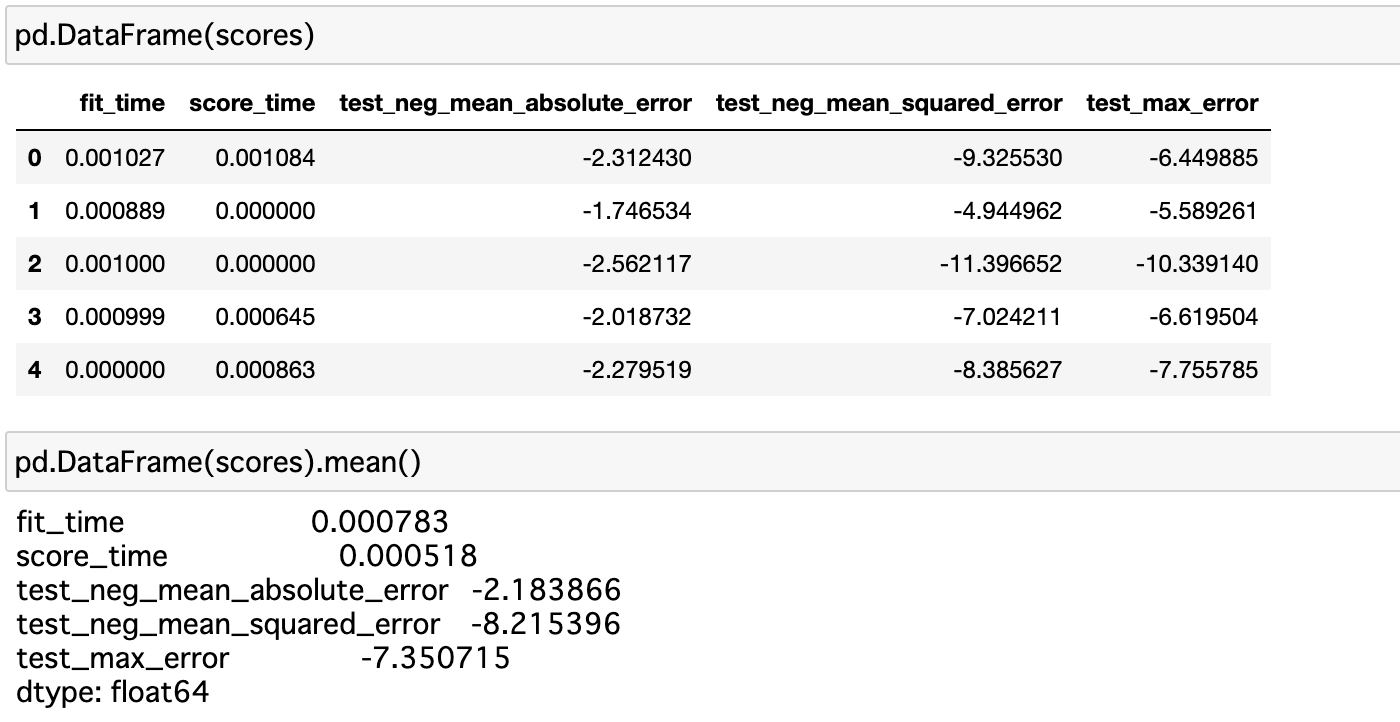
cross_val_scoreだと、指定した1つのスコアしか出力せず、複数の評価指標のスコアを算出してくれません。
Negative MSEだけではなく、Negative MAEなどもあわせて出したいときには、cross_validateという関数を使います。
使い方は、cross_val_scoreとほぼ同じで、scoringに算出したい評価指標を配列で指定するだけです。
すると、各評価指標について配列でスコアを返してくれます。
from sklearn.model_selection import cross_validate
# scoringに算出したいスコアを指定する
scores = cross_validate(model,X_train,y_train,scoring=['neg_mean_absolute_error','neg_mean_squared_error','max_error'],cv=5)
参考資料