1.OpenAI x LangChain x Sreamlit x Chroma 初手(1)
1.1 はじめに
2025年1月時点での、StreamlitでRAG環境をつくるという初手をlangchain v0.3系で実施したので、そのコードになります。ChromaDBに関する基礎知識も記述してます
ベースとなるコードは、OpenAI x LangChain x RAG(ChromaDB) x Streamlitの組み合わせのサンプルがStreamlitのブログにあるので、まあトレースするだけですぐ終わると高をくくってましたが、
最近はDify等でサクッとやるのが流行りなのか、LangChainのライブラリの更新が早すぎるせいか、最新化されていませんでした。したがってそのまま写経して実行というわけにはいかず、LangChain v0.3系で最新化してます。
1.2 環境
- 環境(MacBookPro)
Python 3.12.7
sqlite3 3.39.5
openai==1.59.6
langchain-openai==0.3.0
chromadb==0.5.23
#現在:chromadbのLatest version:0.6.2ですが、langchain-chromaは >=0.4.0 かつ <0.6.0
#また以下バージョンは除外されます:0.5.10, 0.5.11, 0.5.12, 0.5.4, 0.5.5, 0.5.7, 0.5.9
langchain-chroma==0.2.0
langchain==0.3.14
langchain-community==0.3.14
langchain-core==0.3.29
langchain-text-splitters==0.3.5
langsmith==0.2.10
streamlit==1.41.1
python-dotenv==1.0.1
Folder
├── app.py
├── .env
├── components
│ └── llm.py ## envをロードしてllmを作るところだけを記述
└── resource # 永続化しないのでここは不要
└── chromadb/ #永続化しないのでここは不要
1.3 前提
- streamlit blogのサンプルではOpenAIの
APIキーをユーザが入力して使う。という作りでしたが、環境変数に入れて読み込ませている方式に変えてます - Streamlitでは、
.streamlit/secrets.tomlというファイルを使用して、シークレットキーを管理することが推奨されているようですが、馴染のある.envを使っています - app.pyにすべて書いても良いのですが、
.envを読み取ってChatモデルや、Embeddingモデルを作る部分は componentsフォルダ内のllm.pyに分離しています
1.4 コード
# OPENAI API KEY (自分で取得したもの)
OPENAI_API_KEY = sk-xxxxxxxxxxxxxxxx
import os
from dotenv import load_dotenv
load_dotenv() # .envファイルは親ディレクトリ方向に探索されるので同じフォルダでなくてもOK
OPENAI_API_KEY = os.environ.get('OPENAI_API_KEY')
from langchain_openai import ChatOpenAI
from langchain_openai import OpenAIEmbeddings
# ChatOpenAI
llm = ChatOpenAI(
model="gpt-4o-mini",
temperature=0,
api_key=OPENAI_API_KEY
)
# Embedding モデル
oai_embeddings = OpenAIEmbeddings(
#好きなモデルをコメントアウトして利用
#model="text-embedding-ada-002"
model="text-embedding-3-small"
#model="text-embedding-3-large"
)
# 動作確認
# python llm.pyを実行して返事が来ればOK
if __name__ == "__main__":
res = llm.invoke("こんにちは")
print(res)
# 2025.01.10
# streamlit
import streamlit as st
# streamlit blogのコード(以下は全部古い)
- from langchain.llms import OpenAI #old
- from langchain.text_splitter import CharacterTextSplitter # old
- from langchain.embeddings import OpenAIEmbeddings # old
- from langchain.vectorstores import Chroma # old
- from langchain.chains import RetrievalQA # old
+ from langchain_openai import OpenAI #最新化
+ from langchain_text_splitters import CharacterTextSplitter # 最新化
+ from langchain_chroma import Chroma #最新化
# RetrievalQAはすでにレガシーなので、代わりに以下が必要
# cf.https://python.langchain.com/docs/versions/migrating_chains/retrieval_qa/
+ from langchain import hub
+ from langchain_core.output_parsers import StrOutputParser
+ from langchain_core.runnables import RunnablePassthrough
# LLM(componentsフォルダにllm.pyがあればこれで動く)
+ from components.llm import llm
+ from components.llm import oai_embeddings
# llm.pyに分離して記述せず、app.pyの中に記述する場合は以下も必要
+ #from langchain_openai import ChatOpenAI
+ #from langchain_openai import OpenAIEmbeddings
# アップロードしたテキストを読み込んでLLMが応える部分
- def generate_response(uploaded_file, openai_api_key, query_text):
+ def generate_response(uploaded_file, query_text):
# Load document if file is uploaded
if uploaded_file is not None:
documents = [uploaded_file.read().decode()]
# Split documents into chunks
text_splitter = CharacterTextSplitter(chunk_size=512, chunk_overlap=0)
texts = text_splitter.create_documents(documents)
# Select embeddings
- #embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
+ #embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
+ embeddings = oai_embeddings
# Create a vectorstore from documents
vectorstore = Chroma.from_documents(texts, embeddings)
# Create retriever interface
- # old(ブログのこの書き方は古い):
- retriever = vectorstore.as_retriever()
- # Create QA chain
- qa = RetrievalQA.from_chain_type(llm=OpenAI(openai_api_key=openai_api_key), chain_type='stuff', retriever=retriever)
+ # new :
+ # cf.https://python.langchain.com/docs/versions/migrating_chains/retrieval_qa/
+ # See full prompt at https://smith.langchain.com/hub/rlm/rag-prompt
+ prompt = hub.pull("rlm/rag-prompt")
+
+ def format_docs(docs):
+ return "\n\n".join(doc.page_content for doc in docs)
+
+ qa_chain = (
+ {
+ "context": vectorstore.as_retriever() | format_docs,
+ "question": RunnablePassthrough(),
+ }
+ | prompt
+ | llm
+ | StrOutputParser()
+ )
- return qa.run(query_text) # old
+ return qa_chain.invoke(query_text)
# フロントエンド
# Page title
st.set_page_config(page_title='🦜🔗 Ask the Doc App')
st.title('🦜🔗 Ask the Doc App')
# ファイルアップロード
uploaded_file = st.file_uploader('テキストをアップロードしてください', type='txt')
# Query text
query_text = st.text_input('質問を入力:',
placeholder = '簡単な概要を記入してください',
disabled=not uploaded_file)
# Form input and query
# フォーム内にサブミットボタンを配置
result = []
with st.form('myform', clear_on_submit=True):
- #openai_api_key = st.text_input('OpenAI API Key', type='password', disabled=not (uploaded_file and query_text))
disabled=not (uploaded_file and query_text))
submitted = st.form_submit_button('Submit', disabled=not(uploaded_file and query_text))
- #if submitted and openai_api_key.startswith('sk-'):
+ if submitted:
with st.spinner('Calculating...'):
response = generate_response(uploaded_file, query_text)
result.append(response)
- #del openai_api_key
if len(result):
st.info(response)
1.5 実行
夏目漱石の小説「こころ」の冒頭をsample.txtに入れて質問をしてみましたがうまく動作しています
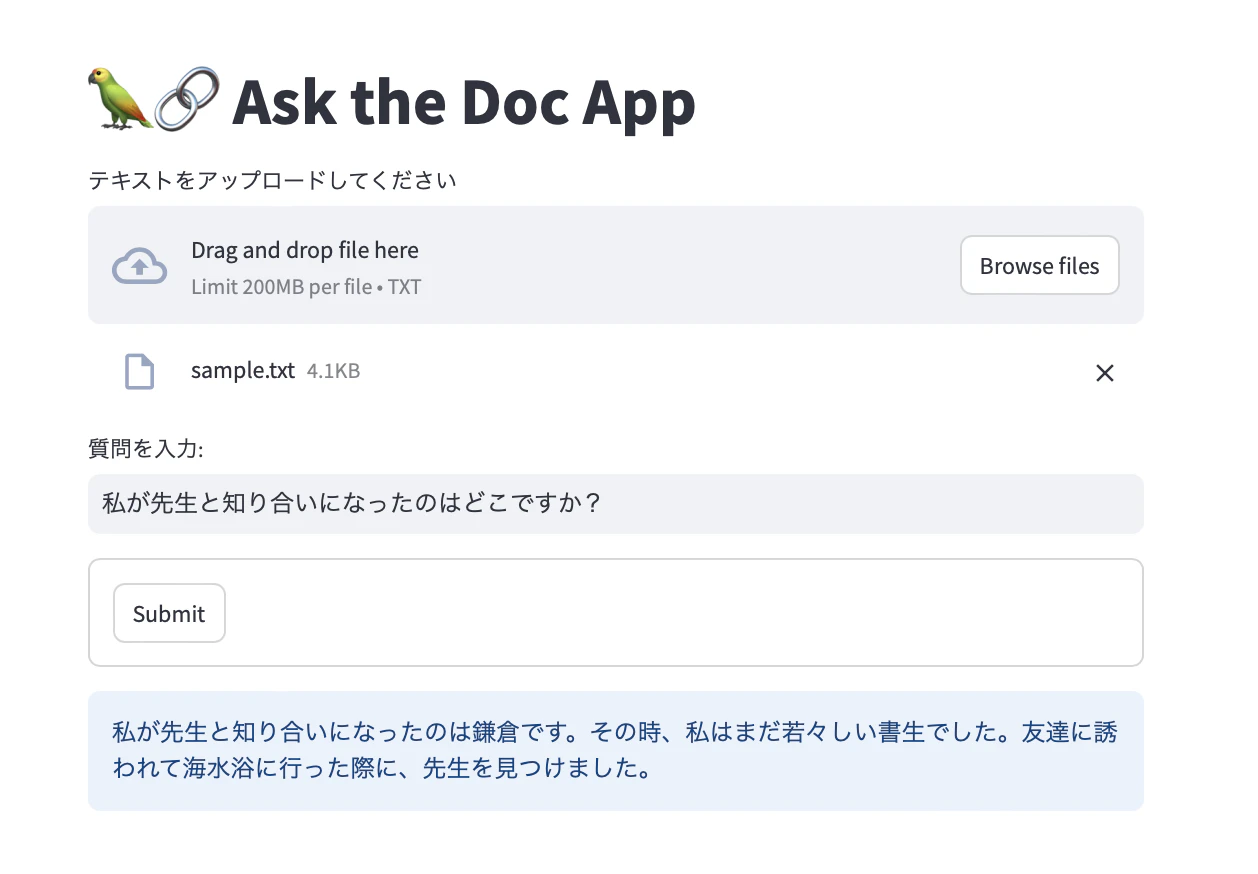
- コードの説明は Streamlitのブログ に任せるので省略します
- 動作させてわかりましたが、本サンプルは良くも悪くも一度テキストファイルを読み込んで、そのテキストをRAGデータとして、チャットしてができる。というだけです。従ってスナップショット的に動作させるには十分ですが、例えば同じテキストファイルをアップロードして実行しようとしても、エラーで動きません
- ではどこを修正すればよいでしょうか? それにはChromaDBを使ったRAG構築方法の再確認が必要でした。以降に、おさらいを兼ねて知見をまとめておきます
2.ChromaDBについて
2.1 基本情報
ChromaDBに関するドキュメントは、本家の公式サイトと、LangChainによるChromaのDocsの2つがあります
-
Chroma :
- Official Site https://www.trychroma.com
- GitHub : github.com → chroma-core → chroma
- 開発元(Chroma): docs.trychroma.com → about
- ライセンス情報: Apache License 2.0
- インストール: docs.trychroma.com → usage-guide
- Chromadbにはsqlite3のバージョンが3.35.0以上が必要です
-
$ sqlite3 --versionで確認ができます
-
- ChromaのデフォルトEmbeddingは Sentence Transformers all-MiniLM-L6-v2モデルが使用されす
- 任意のEmbeddingモデルを使用できます =>参考
-
LangChain Chroma
- docs v0.1 : https://python.langchain.com/v0.1/docs/integrations/vectorstores/chroma/
- docs v0.2 : https://python.langchain.com/v0.2/docs/integrations/vectorstores/chroma/
- docs v0.3 : https://python.langchain.com/docs/integrations/vectorstores/chroma/
- langchain-chromaで要求されるchromadbのバージョンは、>=0.4.0 かつ <0.6.0 であり、さらに以下のバージョンは除外されています:0.5.10, 0.5.11, 0.5.12, 0.5.4, 0.5.5, 0.5.7, 0.5.9
- langchain-chroma API reference: :https://python.langchain.com/api_reference/chroma/vectorstores/langchain_chroma.vectorstores.Chroma.html
2.2 ライブラリインストール
#ChromaのPythonライブラリをインストール
%pip install chromadb
# LangChain Chroma
%pip install -qU "langchain-chroma>=0.1.2"
%pip list | grep chroma
chroma-hnswlib 0.7.6
chromadb 0.5.23
langchain-chroma 0.2.0
2.3 ChromaDBのセットアップの注意点
以前からよく見かけるコードの記法が、LangChain docsにある、以下の.from_documentsを使った記法で、前述のStreamlitのサンプルでもこの記法です。しかしドキュメントの更新などを考えると、これは行き詰まります。1つのドキュメントからDBを構築してしまっているので、さらにドキュメントを追加することが考慮されてい無いからです。
# cf.https://python.langchain.com/v0.2/docs/tutorials/rag/
from langchain_chroma import Chroma
# -- 中略 --
vectorstore = Chroma.from_documents(
documents=splits,
embedding=OpenAIEmbeddings()
)
ではどうするか。
2.4 ChromaDBのセットアップ方法の種類
ChromaDBのセットアップ方法
- クライアント側から構築する方法
- サーバ側から構築する方法
2.4.1 2つの方法を公式のDocsから読み解く
- Chroma公式のdocs Getting Startedを読む限り、セットアップはクライアント側から構築する手順で紹介されています。一方、
- LangChain Chromaのpythonでは、サーバ側から構築と、クライアント側からイニシャライズする方法の両方が記述されています
2.4.2 ドキュメントの追加や更新の違い
- Chroma公式docs => クライアント側から構築を実施すると、ドキュメントの追加(ADD)、更新(UPDATE)、およびアップサート(UPSERT) ができると記載されています。
なおUPSERTという用語はデータベース用語です。こちら e-words.jp を参照してください - LangChain Chroma公式docs => サーバ側から構築を実施すると、LangChainによって、ドキュメントの (追加)ADD と、(更新)UPDATE は用意されているが、アップサート(UPSERT) は用意されていないように読めます
- ※以降で動作確認を記述しますが、結論から言うと、ADDはUPSERTの動作をしていました。つまり同じidであれば上書きするし、なければ追加されます
- そうするとUPDATEのモジュールを作った意義は?という疑問が残りますが、管轄外なので省略します
2.5 Collectionについて
-
Chromaには、
Collectionの理解が必要ですが、LangChain Chroma のDocsだけでは、その必要性を読み解きにくい気がします
Collections(コレクション) とは、
Embeddings、ドキュメント、その他のメタデータを保存する場所のことです。ドキュメントとは、チャンク分割されたchunkのことです。コレクションはEmbeddingsとドキュメント(チャンク分割されたチャンク)をインデックス化し、効率的な検索とフィルタリングを可能にします。コレクションは、名前をつけて作成できます。クライアント側からのcollectionがあれば、簡単に登録内容を確認できたりするコマンドも使えます
2.6 ChromaDB構造
- ChromaDBの非公式cookbook によると、
例えば、User-Per-Collectionの図を用いますが、このようなテナントからの階層構造を取っています。
User-Per-Collection
コレクション内のすべてのドキュメントへのアクセス権をユーザーに付与する場合
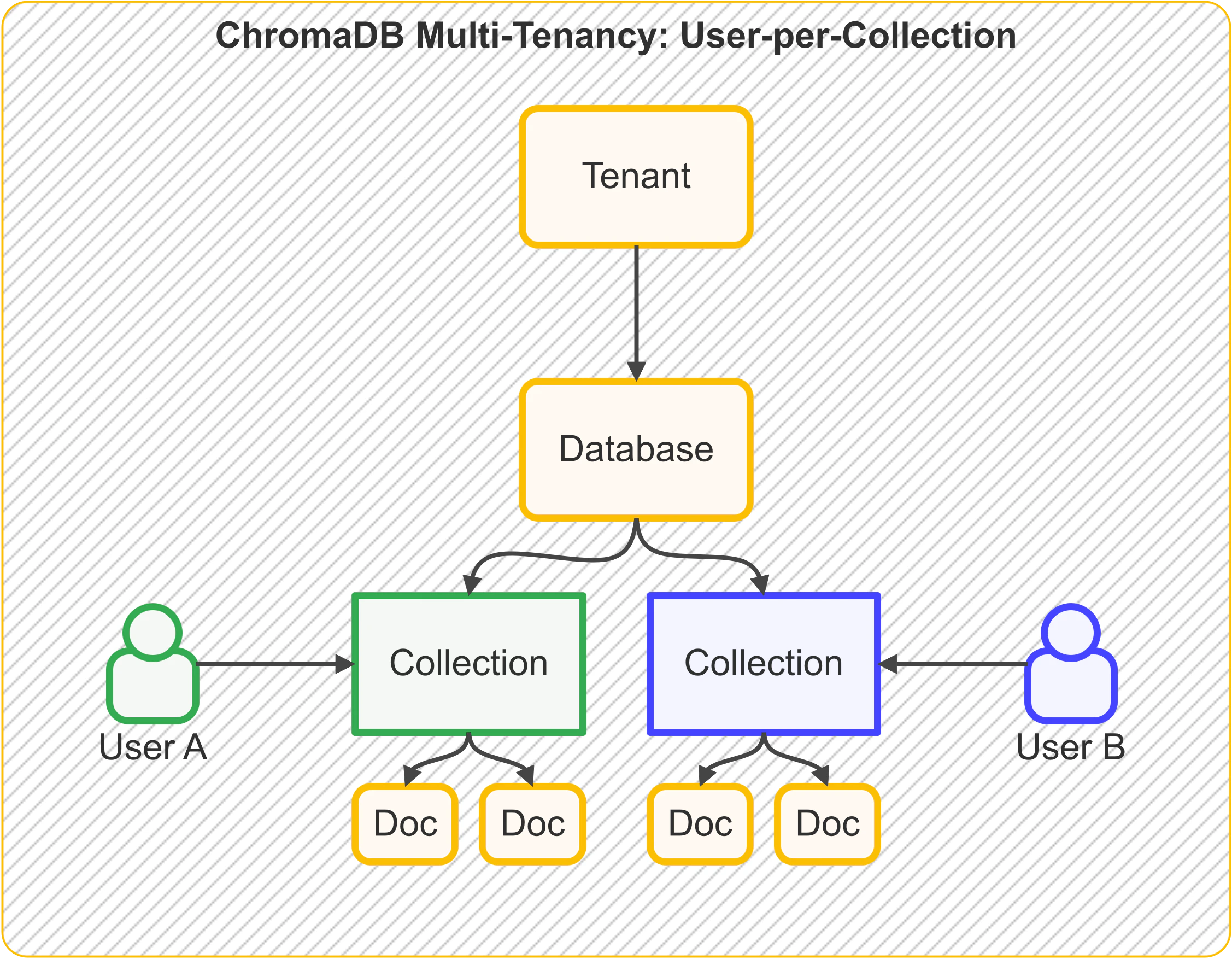
ユーザー(user_id)ごとにコレクションを作成する実装場合の例:
import chromadb
client = chromadb.PersistentClient()
user_id = "user1"
collection = client.get_or_create_collection(f"user-collection:{user_id}")
collection.add(
documents=["This is document1", "This is document2"],
ids=["doc1", "doc2"],
)
クエリ時に、次のようにクエリのフィルターとして user_id を指定する必要があります
user_id = "user1"
user_collection = client.get_collection(f"user-collection:{user_id}")
results = user_collection.query(
query_texts=["This is a query document"],
)
このような簡単な実装例も記述されていますので、公式サイトを参照していただくとよいかと思います
3.Chroma実装(1):クライアント側から構築
3.1 クライアント構築
- Create a Chroma Client (まずはクライアントをセットアップします)
import chromadb
# 揮発性の場合(Ephemeral Client)
chroma_client = chromadb.Client()
# Client() メソッドは、メモリ内で Chroma サーバーを起動し、
# そのサーバーに接続できるクライアントも返します
# データの永続性が必要ない場合に、Chroma エフェメラル クライアントが適しています
import chromadb
# 永続性の場合(Persistent Client)
#client = chromadb.PersistentClient(path="/path/to/save/to")
persistent_client = chromadb.PersistentClient(path="./chroma_db/")
# フォルダをchroma_dbとしています
#その中にsqlite3によるデータベースが構築されます。
#sqlite3はファイルシステムのDBなので、chroma.sqlite3のファイルがあることが確認できます
#()内に、ファイルパスを指定しない場合、デフォルトではchromaというフォルダ名で自動作成されます
3.2 コレクションの構築
- Create a collection
- 次にコレクションを作成します。コレクションは、embedding、ドキュメント(Chromaではチャンク分割されたチャンクドキュメントのことをドキュメントと呼んでいます)、メタデータを保存する場所になります。コレクションはEmbeddingとチャンクされたドキュメントをインデックス化し、効率的な検索とフィルタリングを可能にします。名前を付けてコレクションを作成します
- 作成方法3つ
# 新規作成する場合
collection = chroma_client.create_collection(name="my_collection")
# すでに作成済みのcollectionに接続するためには、get_collectionメソッドが使用できます
collection = chroma_client.get_collection(name="my_collection")
# 既存接続なければ新規構築
# 既存のCollectionがある場合は取得、ない場合は新規作成をするget_or_create_collectionメソッドもああります
collection = chroma_client.get_or_create_collection("new_collection")
- ここでは、永続性のあるクライアントからコレクションを作成してみます。名前は
collection_name_1としてみました
# 永続性あるクライアントからのコレクショの作成
collection_1 = persistent_client.get_or_create_collection("collection_name_1")
3.3 ドキュメントのコレクションへの登録
- Add some text documents to the collection
- 次に適当なドキュメントを用意して、ドキュメントを適切にチャンキングしたあとに、ベクトルにEmbeddingして、Chromaに保存します
- Chroma はテキストを保存し、Embeddingsとインデックス作成を自動的に処理します
- デフォルトではのSentence Transformers all-MiniLM-L6-v2が利用されます
- 埋め込みモデルをカスタマイズすることもできます。ここではOpenAIEmbeddinsを利用します
- ドキュメントには一意の文字列 ID(ids) を指定する必要があります
ChromaデフォルトのEmbeddingを利用する場合、384次元になります
一度決めたEmbeddingのドキュメントを格納した後、別の次元数でEmbeddinsしたものは格納できませんので、あらかじめどのEmbeddingsで何次元かは設計方針として決めて置く必要があります。一般的にEmbeddinsの次元が高いと、検索精度はよくなりますので、簡易的な動作確認以外でデフォルトを使うことはあまりないのかと思います
text-embedding-ada-002:1536次元
text-embedding-3-small:最大1536次元
text-embedding-3-large:最大3072次元
3.3.1 OpenAIEmbeddings
- OpenAIのEmbeddingsを用意
# OpenAI API Keyを.envから読み込む
import os
from os.path import join, dirname, abspath
from dotenv import load_dotenv
dir_path = dirname(abspath("__file__"))
dotenv_path = join(dir_path, './Path/to/.env')
load_dotenv(dotenv_path, verbose=True)
# OpenAIのEmbeddingsを用意
from langchain_openai import OpenAIEmbeddings
oai_embeddings = OpenAIEmbeddings(
# モデルを選択してコメントアウト
#model="text-embedding-ada-002"
model="text-embedding-3-small"
#model="text-embedding-3-large"
)
3.3.2 ドキュメント用意
# ドキュメントのリスト(チャンク分割された後のドキュメント)
documents = [
"aaa_昨日は金曜日です",
"bbb_今日は土曜日です",
"ccc_明日は日曜で嬉しいです"
]
# IDs のリスト
ids = ["No1", "No2", "No3"]
3.3.3 ドキュメントのEmbeddins
ドキュメントをベクトル変換しておきます
# OpenAIEmbeddings オブジェクトを使って埋め込みベクトルを生成
# cf.https://python.langchain.com/docs/integrations/text_embedding/openai/
# 1つのみ変換する場合
single_vector = embeddings.embed_query(chunked_doc)
# ドキュメントを複数まとめて変換する場合
two_vectors = embeddings.embed_documents([chunked_doc, chunked_doc2])
- 通常複数になるので後者(.embed_documents)で変換します。
# ベクトル変換
embeddings_doc = oai_embeddings.embed_documents(documents)
3.3.4 ドキュメントの追加・更新・アップサート
3.3.4.1 ADD(追加)
- Chroma にドキュメントのリストが渡されると、コレクションのEmbedding関数を使用してドキュメントが自動的にトークン化され、埋め込まれます(コレクションの作成時に何もEmbeddingsが指定されていない場合は、デフォルト(384次元)が使用されます)
collection.add(
documents=["lorem ipsum...", "doc2", "doc3", ...],
metadatas=[{"chapter": "3", "verse": "16"}, {"chapter": "3", "verse": "5"}, {"chapter": "29", "verse": "11"}, ...],
ids=["id1", "id2", "id3", ...]
)
Chroma はドキュメント自体も保存します。ドキュメントが大きすぎて選択した埋め込み関数を使用して埋め込めない場合は、例外(exception) が発生します。
各ドキュメントには、一意の関連ID が必要です。同じID を 2回 .add しようとすると、最初に登録された方だけが保存されます
collection.add(
documents=["doc1", "doc2", "doc3", ...],
embeddings=[[1.1, 2.3, 3.2], [4.5, 6.9, 4.4], [1.1, 2.3, 3.2], ...],
metadatas=[{"chapter": "3", "verse": "16"}, {"chapter": "3", "verse": "5"}, {"chapter": "29", "verse": "11"}, ...],
ids=["id1", "id2", "id3", ...]
)
ではADDによる登録方法がわかったところで、先程のサンプルを登録してみましょう
# コレクションにデータを追加
collection_1.add(
ids=ids,
documents=documents,
embeddings=embeddings_doc
)
登録したら確認したくなりますね。クライアントからコレクションを作成している場合、peekを使うことで簡易的に登録状況が確認できるので便利です
# 登録状況確認
# peek()- コレクション内の最初の 10 個の項目のリストを返します。
collection_sv1.peek()
{'ids': ['No1', 'No2', 'No3'],
'embeddings': array([[-0.00973406, -0.01312051, -0.02522031, ..., -0.02500766,
-0.01207853, 0.01915978],
[ 0.0456798 , 0.0135701 , 0.02023997, ..., 0.01925265,
-0.00278231, -0.00230511],
[ 0.01978434, -0.0207507 , -0.03493432, ..., 0.00364462,
-0.00536692, 0.0331263 ]]),
'documents': ['aaa_昨日は金曜日です', 'bbb_今日は土曜日です', 'ccc_明日は日曜で嬉しいです'],
'uris': None,
'data': None,
'metadatas': [None, None, None],
'included': [<IncludeEnum.embeddings: 'embeddings'>,
<IncludeEnum.documents: 'documents'>,
<IncludeEnum.metadatas: 'metadatas'>]}
3.3.4.2 UPDATE(更新)
コレクション内のレコードの任意のプロパティは、.update を使用して更新できます。
collection.update(
ids=["id1", "id2", "id3", ...],
embeddings=[[1.1, 2.3, 3.2], [4.5, 6.9, 4.4], [1.1, 2.3, 3.2], ...],
metadatas=[{"chapter": "3", "verse": "16"}, {"chapter": "3", "verse": "5"}, {"chapter": "29", "verse": "11"}, ...],
documents=["doc1", "doc2", "doc3", ...],
)
コレクション内に ID が見つからない場合、エラーがログに記録され、更新は無視されます。
対応するEmbeddingsなしでドキュメントを入れた場合、コレクションのEmbeddins関数を使用して埋め込みが再計算されます
提供された埋め込みがコレクションと同じディメンション(次元)でない場合は、例外が発生します。
やり方がわかったところでやってみます
# ドキュメントのリスト
documents_update = [
"aaa_昨日は金曜日で仕事をしてました",
"bbb_今日は土曜日でサッカーの大会です",
"ccc_明日は日曜日でショッピングに行きます"
]
# IDs のリスト(アップデートなので同じidを指定)
ids = ["No1", "No2", "No3"]
# Embeddinsさせます
embeddings_doc = oai_embeddings.embed_documents(documents)
# コレクションにデータをアップデート
collection_1.update(
ids=ids,
documents=documents_update,
embeddings=embeddings_doc
)
# 確認
# peekは、「ちらっと見る」という意味です
collection_1.peek()
{'ids': ['No1', 'No2', 'No3'],
'embeddings': array([[-0.00970023, -0.01313916, -0.02523655, ..., -0.02502394,
-0.01207612, 0.01912407],
[ 0.0456798 , 0.0135701 , 0.02023997, ..., 0.01925265,
-0.00278231, -0.00230511],
[ 0.01977915, -0.02072498, -0.03494352, ..., 0.00365857,
-0.00536313, 0.03313502]]),
'documents': ['aaa_昨日は金曜日で仕事をしてました',
'bbb_今日は土曜日でサッカーの大会です',
'ccc_明日は日曜日でショッピングに行きます'],
'uris': None,
'data': None,
'metadatas': [None, None, None],
'included': [<IncludeEnum.embeddings: 'embeddings'>,
<IncludeEnum.documents: 'documents'>,
<IncludeEnum.metadatas: 'metadatas'>]}
4つ目のチャンクドキュメントを用意して現在のデータに無いものをアップデートさせます
# ドキュメントのリスト
documents2 = [
"ddd_明後日は月曜で仕事です"
]
# IDs のリスト
ids = ["No4"]
# OpenAIEmbeddings
embeddings_doc2 = oai_embeddings.embed_documents(documents2)
# コレクションにデータをアップデート
collection_1.update(
ids=ids,
documents=documents2,
embeddings=embeddings_doc2
)
# Update of nonexisting embedding ID: No4
# Update of nonexisting embedding ID: No4
No4はないよ。と、エラーになりました
3.3.4.3 UPSERT
Chroma は、コレクションを指定すれば、既存のアイテムを更新するか、まだ存在しない場合は追加する upsert 操作もサポートしています。
コレクションに ID が存在しない場合は、対応するアイテムが追加に従って作成されます。既存の ID を持つアイテムは更新に従って更新されます。
collection.upsert(
ids=["id1", "id2", "id3", ...],
embeddings=[[1.1, 2.3, 3.2], [4.5, 6.9, 4.4], [1.1, 2.3, 3.2], ...],
metadatas=[{"chapter": "3", "verse": "16"}, {"chapter": "3", "verse": "5"}, {"chapter": "29", "verse": "11"}, ...],
documents=["doc1", "doc2", "doc3", ...],
)
では、先程アップデートが失敗した例を利用してアップサートで実行してみます
# コレクションにデータをアップサート
collection_1.upsert(
ids=ids,
documents=documents2,
embeddings=embeddings_doc2
)
#peek「ちらっと見る」で確認
collection_1.peek()
{'ids': ['No1', 'No2', 'No3', 'No4'],
'embeddings': array([[-0.00970023, -0.01313916, -0.02523655, ..., -0.02502394,
-0.01207612, 0.01912407],
[ 0.0456798 , 0.0135701 , 0.02023997, ..., 0.01925265,
-0.00278231, -0.00230511],
[ 0.01977915, -0.02072498, -0.03494352, ..., 0.00365857,
-0.00536313, 0.03313502],
[ 0.01555913, 0.03841347, 0.00644014, ..., 0.02779688,
-0.00846164, 0.02156927]]),
'documents': ['aaa_昨日は金曜日で仕事をしてました',
'bbb_今日は土曜日でサッカーの大会です',
'ccc_明日は日曜日でショッピングに行きます',
'ddd_明後日は月曜で仕事です'],
'uris': None,
'data': None,
'metadatas': [None, None, None, None],
'included': [<IncludeEnum.embeddings: 'embeddings'>,
<IncludeEnum.documents: 'documents'>,
<IncludeEnum.metadatas: 'metadatas'>]}
エラーもなく追加されています
3.3.4.4 ADDの追加検証
既存にidがあるものをADDで追加した場合はどうなるでしょうか
# ドキュメントのリスト
documents3 = ["ddd_明後日の予定をADDで上書きできるか"]
# IDs のリスト
ids = ["No4"]
# OpenAIEmbeddings オブジェクトを使って埋め込みベクトルを生成
embeddings_doc3 = oai_embeddings.embed_documents(documents3)
# コレクションにデータを追加
collection_1.add(
ids=ids,
documents=documents3,
embeddings=embeddings_doc3
)
#Insert of existing embedding ID: No4
#Add of existing embedding ID: No4
#peekで確認します
collection_1.peek()
{'ids': ['No1', 'No2', 'No3', 'No4'],
'embeddings': array([[-0.00970023, -0.01313916, -0.02523655, ..., -0.02502394,
-0.01207612, 0.01912407],
[ 0.0456798 , 0.0135701 , 0.02023997, ..., 0.01925265,
-0.00278231, -0.00230511],
[ 0.01977915, -0.02072498, -0.03494352, ..., 0.00365857,
-0.00536313, 0.03313502],
[ 0.01555913, 0.03841347, 0.00644014, ..., 0.02779688,
-0.00846164, 0.02156927]]),
'documents': ['aaa_昨日は金曜日で仕事をしてました',
'bbb_今日は土曜日でサッカーの大会です',
'ccc_明日は日曜日でショッピングに行きます',
'ddd_明後日は月曜で仕事です'],
'uris': None,
'data': None,
'metadatas': [None, None, None, None],
'included': [<IncludeEnum.embeddings: 'embeddings'>,
<IncludeEnum.documents: 'documents'>,
<IncludeEnum.metadatas: 'metadatas'>]}
上書きされずに終わっています。ADDは同じIDで追加すると初期値(元の値)が保持されているのがわかりました。
4.Chroma実装(2):サーバー側から構築
4.1 サーバ構築
以下のLangChain Chromaに従って、サーバ構築してからドキュメント登録をしてみます
# 1.ライブラリ
from langchain_chroma import Chroma
# サーバ構築
vector_store_server = Chroma(
collection_name="collection_name_server1",
embedding_function = oai_embeddings,
persist_directory = "./chromadb_server1", # ローカルにsqlite3でセーブするフォルダを作る
)
- vector_storeの後に(_server)とsuffixをつけて区別してみてます
- collection_name も "collection_name_server1"としています
- embeddinsは同じOpenAIで作成したものを流用します
- psersist_directory は別のフォルダを指定しています
4.2 ドキュメント作成
#LangChainの公式に習ってドキュメントを作ってみます
from uuid import uuid4
from langchain_core.documents import Document
document_1 = Document(page_content="ドキュメント1 吾輩は猫である",metadata={"source": "novel"}, id="No_001",)
document_2 = Document(page_content="ドキュメント2 米国LA付近の山火事は",metadata={"source": "news"}, id="No_002",)
documents_01 = [document_1,document_2,]
# idsにいれるユニークIDをドキュメントの数だけ作る
uuids = [str(uuid4()) for _ in range(len(documents_01))]
# 確認
print(f"documents = documents_01 # {documents_01}")
print(f"ids = uuids # {uuids}")
documents = documents_01 # [Document(id='No_001', metadata={'source': 'novel'}, page_content='ドキュメント1 吾輩は猫である'), Document(id='No_002', metadata={'source': 'news'}, page_content='ドキュメント2 米国LA付近の山火事は')]
ids = uuids # ['9a6f4126-7709-456e-ac73-8cabfc386227', 'a254c683-c76f-4bd2-942c-faf36b771aff']
4.3 ドキュメント登録(ADD)
.add_documents Functionを使用して、ベクター ストアに追加できます。
#ドキュメント登録
vector_store_server.add_documents(
documents=documents_01,
ids=uuids
)
#['9a6f4126-7709-456e-ac73-8cabfc386227',
# 'a254c683-c76f-4bd2-942c-faf36b771aff']
ここまではLangChain Chromaのサイトに実施方法が記述してあります。
しかしながら、peekなどを使って確認する方法まではありません。
どのように実施するのでしょうか。
4.4 登録状況確認(Peek)
4.4.1 Peekを使った確認
LangChain Chromaに従ってサーバ構築した場合も
クライアントを作成すればpeekで確認できるようになります
import chromadb
# クライアントを作成してみます
# PersistentClientで、構築済みサーバーのPathを指定します
client_from_sv = chromadb.PersistentClient(path="./chromadb_server1")
# .get_collectionを使って、作成済みのコレクション名を指定します
collection_sv1 = client_from_sv.get_collection(name="collection_name_server1")
確認してみましょう
#peek「ちらっと見る」で確認
collection_sv1.peek()
{'ids': ['9a6f4126-7709-456e-ac73-8cabfc386227',
'a254c683-c76f-4bd2-942c-faf36b771aff'],
'embeddings': array([[ 0.02646793, 0.00708621, -0.02202469, ..., 0.01978392,
-0.0442026 , 0.01324354],
[ 0.014067 , 0.00251728, -0.01905692, ..., -0.00477663,
0.00884892, 0.00681525]]),
'documents': ['ドキュメント1 吾輩は猫である', 'ドキュメント2 米国LA付近の山火事は'],
'uris': None,
'data': None,
'metadatas': [{'source': 'novel'}, {'source': 'news'}],
'included': [<IncludeEnum.embeddings: 'embeddings'>,
<IncludeEnum.documents: 'documents'>,
<IncludeEnum.metadatas: 'metadatas'>]}
うまく登録できています。またDocumentsで作成したid="No_001"などは全く使用されないことがわかります。あくまでidsで指定したIDのリストをもとにDBが作成されます
4.4.2 更に追加してPeek確認
もうすこし同じCollection内に、ドキュメントを追加してみましょう
#さらに追加するデータ
document_3 = Document(page_content="ドキュメント3 東京",metadata={"source": "location"}, id="No_003",)
document_4 = Document(page_content="ドキュメント4 埼玉",metadata={"source": "location"}, id="No_004",)
documents_01_2 = [document_3,document_4,]
# idsにいれるユニークIDをドキュメントの数だけ作る
uuids = [str(uuid4()) for _ in range(len(documents_01_2))]
print(f"documents = documents_01_2 # {documents_01_2}")
print(f"ids = uuids # {uuids}")
documents = documents_01_2 # [Document(id='No_003', metadata={'source': 'location'}, page_content='ドキュメント3 東京'), Document(id='No_004', metadata={'source': 'location'}, page_content='ドキュメント4 埼玉')]
ids = uuids # ['89f248c6-1301-4ada-a57f-68a7b5cbc42f', 'db56ae2d-3cbd-4f9a-81d0-0ec5e7fb6b40']
登録します
#ドキュメント登録
vector_store_server.add_documents(
documents=documents_01_2,
ids=uuids
)
['89f248c6-1301-4ada-a57f-68a7b5cbc42f',
'db56ae2d-3cbd-4f9a-81d0-0ec5e7fb6b40']
#peekは、「ちらっと見る」
# peek()- コレクション内の最初の 10 個の項目のリストを返します。
collection_sv1.peek()
{'ids': ['9a6f4126-7709-456e-ac73-8cabfc386227',
'a254c683-c76f-4bd2-942c-faf36b771aff',
'89f248c6-1301-4ada-a57f-68a7b5cbc42f',
'db56ae2d-3cbd-4f9a-81d0-0ec5e7fb6b40'],
'embeddings': array([[ 0.02646793, 0.00708621, -0.02202469, ..., 0.01978392,
-0.0442026 , 0.01324354],
[ 0.014067 , 0.00251728, -0.01905692, ..., -0.00477663,
0.00884892, 0.00681525],
[-0.00012498, -0.00107113, 0.01949918, ..., 0.02750386,
0.01394773, 0.00813137],
[-0.01294255, 0.03343956, -0.01138723, ..., -0.00905979,
-0.02070809, 0.02535185]]),
'documents': ['ドキュメント1 吾輩は猫である',
'ドキュメント2 米国LA付近の山火事は',
'ドキュメント3 東京',
'ドキュメント4 埼玉'],
'uris': None,
'data': None,
'metadatas': [{'source': 'novel'},
{'source': 'news'},
{'source': 'location'},
{'source': 'location'}],
'included': [<IncludeEnum.embeddings: 'embeddings'>,
<IncludeEnum.documents: 'documents'>,
<IncludeEnum.metadatas: 'metadatas'>]}
うまく追加できています
4.5 ドキュメント登録(UPSART)
.add_documents関数は、ドキュメントの追加(ADD)なので、UPSERTの動作は失敗するか確認します。
例として、document_4は同じIDなので上書きされ、document_5は今までにないdoumentなので追加されるというUPSERTが失敗することを確認してみます
# UPSERT試験
document_4 = Document(page_content="ドキュメント4 上書データ",metadata={"source": "location"}, id="No_004",)
document_5 = Document(page_content="ドキュメント5 神奈川",metadata={"source": "location"}, id="No_005",)
documents_01_3 = [document_4,document_5,]
#1つは重複、1つは新規(UPSERTならば、アップデートとインサートができるがADDなので失敗するはず)
uuids=['db56ae2d-3cbd-4f9a-81d0-0ec5e7fb6b40','doc5_uuid']
#ドキュメント登録
vector_store_server.add_documents(
documents=documents_01_3,
ids=uuids
)
# peek()- コレクション内の最初の 10 個の項目のリストを返します
collection_sv1.peek()
{'ids': ['9a6f4126-7709-456e-ac73-8cabfc386227',
'a254c683-c76f-4bd2-942c-faf36b771aff',
'89f248c6-1301-4ada-a57f-68a7b5cbc42f',
'db56ae2d-3cbd-4f9a-81d0-0ec5e7fb6b40',
'doc5_uuid'],
'embeddings': array([[ 0.02646793, 0.00708621, -0.02202469, ..., 0.01978392,
-0.0442026 , 0.01324354],
[ 0.014067 , 0.00251728, -0.01905692, ..., -0.00477663,
0.00884892, 0.00681525],
[-0.00012498, -0.00107113, 0.01949918, ..., 0.02750386,
0.01394773, 0.00813137],
[ 0.01347584, 0.03351198, 0.01063976, ..., -0.0031943 ,
0.00841352, 0.01404424],
[-0.04239953, 0.03411957, -0.0379879 , ..., 0.01351743,
0.00848643, 0.00208629]]),
'documents': ['ドキュメント1 吾輩は猫である',
'ドキュメント2 米国LA付近の山火事は',
'ドキュメント3 東京',
'ドキュメント4 上書データ',
'ドキュメント5 神奈川'],
'uris': None,
'data': None,
'metadatas': [{'source': 'novel'},
{'source': 'news'},
{'source': 'location'},
{'source': 'location'},
{'source': 'location'}],
'included': [<IncludeEnum.embeddings: 'embeddings'>,
<IncludeEnum.documents: 'documents'>,
<IncludeEnum.metadatas: 'metadatas'>]}
えっと、登録できました。ドキュメント4は、埼玉から上書きデータに変わっており、
ドキュメント5の神奈川も追加されていることが確認できました。従って
.add_documentsメソッドは、動作としては upsertの動作をするということです
4.6 ドキュメント登録(UPDATE)
- ドキュメントを1つだけアップデート登録
- 下のコマンドと違いが分かりづらいですが、documentの後に複数形のsが無いです
ids = ["id_001","id_002"]
# ドキュメントを1つだけUPDATEの場合
vector_store.update_document(
document_id=ids[0], #idのリスト(ここではids)の1つを指定
document=updated_document_1
)
- ドキュメントを複数アップデート
- 上のコマンドと違いが分かりづらいですが、documentの後に複数形のsがついています
# You can also update multiple documents at once
vector_store.update_documents(
ids=ids[:2],
documents=[updated_document_1, updated_document_2]
)
アップデートの仕方がわかったところで、1つだけアップデートしてみます
document_1_update = Document(
page_content="ドキュメント1 上書きデータ",
metadata={"source": "update_novel"},
id="No_001",
)
4.7 登録状況確認(count,get)
アップデートするためには登録状況のidsを知る必要があります.
peek() コマンドでは最初の10個しかわからないので、他のコマンドで確認します
-
.count() コマンド
- コレクション内のアイテム数を返します
# count()- コレクション内のアイテムの数を返します。
collection_sv1.count()
# 5
-
.get() コマンド
-
.getを使用して、ID でコレクションからアイテムを取得することができます -
.getは where および where ドキュメント フィルターもサポートします。- ID が指定されていない場合は、where および where ドキュメント フィルターに一致するコレクション内のすべてのアイテムが返されます
-
#collectionからアイテムを全取得
collection_sv1.get()
{'ids': ['9a6f4126-7709-456e-ac73-8cabfc386227',
'a254c683-c76f-4bd2-942c-faf36b771aff',
'89f248c6-1301-4ada-a57f-68a7b5cbc42f',
'db56ae2d-3cbd-4f9a-81d0-0ec5e7fb6b40',
'doc5_uuid'],
'embeddings': None,
'documents': ['ドキュメント1 吾輩は猫である',
'ドキュメント2 米国LA付近の山火事は',
'ドキュメント3 東京',
'ドキュメント4 上書データ',
'ドキュメント5 神奈川'],
'uris': None,
'data': None,
'metadatas': [{'source': 'novel'},
{'source': 'news'},
{'source': 'location'},
{'source': 'location'},
{'source': 'location'}],
'included': [<IncludeEnum.documents: 'documents'>,
<IncludeEnum.metadatas: 'metadatas'>]}
以下のようにすればidsだけ取得できます
collection_sv1.get()['ids']
['9a6f4126-7709-456e-ac73-8cabfc386227',
'a254c683-c76f-4bd2-942c-faf36b771aff',
'89f248c6-1301-4ada-a57f-68a7b5cbc42f',
'db56ae2d-3cbd-4f9a-81d0-0ec5e7fb6b40',
'doc5_uuid']
ちなみに、whereを使って、コレクションからメタデータが一致するものだけ取得することもできます
# コレクションからメタデータが一致するものだけ取得します
collection_sv1.get(
where={"source": "location"}
)
{'ids': ['89f248c6-1301-4ada-a57f-68a7b5cbc42f',
'db56ae2d-3cbd-4f9a-81d0-0ec5e7fb6b40',
'doc5_uuid'],
'embeddings': None,
'documents': ['ドキュメント3 東京', 'ドキュメント4 上書データ', 'ドキュメント5 神奈川'],
'uris': None,
'data': None,
'metadatas': [{'source': 'location'},
{'source': 'location'},
{'source': 'location'}],
'included': [<IncludeEnum.documents: 'documents'>,
<IncludeEnum.metadatas: 'metadatas'>]}
デフォルトで、embeddinsはパフォーマンス上の理由からデフォルトでは除外されるのでNoneになっています。include パラメータを使用すれば、返されるデータ(embeddins、documents、metadatas)を指定し、表示させることができます。embeddinsは、.getでは 2次元 numpy配列として返されます。
collection_sv1.get(
include=['embeddings','documents','metadatas'],
where={"source": "location"}
)
{'ids': ['89f248c6-1301-4ada-a57f-68a7b5cbc42f',
'db56ae2d-3cbd-4f9a-81d0-0ec5e7fb6b40',
'doc5_uuid'],
'embeddings': array([[-0.00012498, -0.00107113, 0.01949918, ..., 0.02750386,
0.01394773, 0.00813137],
[ 0.01347584, 0.03351198, 0.01063976, ..., -0.0031943 ,
0.00841352, 0.01404424],
[-0.04239953, 0.03411957, -0.0379879 , ..., 0.01351743,
0.00848643, 0.00208629]]),
'documents': ['ドキュメント3 東京', 'ドキュメント4 上書データ', 'ドキュメント5 神奈川'],
'uris': None,
'data': None,
'metadatas': [{'source': 'location'},
{'source': 'location'},
{'source': 'location'}],
'included': [<IncludeEnum.embeddings: 'embeddings'>,
<IncludeEnum.documents: 'documents'>,
<IncludeEnum.metadatas: 'metadatas'>]}
現在のidsのリストを取得して、更新してみます。
current_ids=collection_sv1.get()['ids']
print(current_ids)
#['9a6f4126-7709-456e-ac73-8cabfc386227',
#'a254c683-c76f-4bd2-942c-faf36b771aff',
#'89f248c6-1301-4ada-a57f-68a7b5cbc42f',
#'db56ae2d-3cbd-4f9a-81d0-0ec5e7fb6b40',
#'doc5_uuid']
# idの1番目を取得
current_ids[:1]
#['9a6f4126-7709-456e-ac73-8cabfc386227']
# 上書き前(現在のデータの1番目だけ取得)
collection_sv1.get(ids=current_ids[:1])
{'ids': ['9a6f4126-7709-456e-ac73-8cabfc386227'],
'embeddings': None,
'documents': ['ドキュメント1 吾輩は猫である'],
'uris': None,
'data': None,
'metadatas': [{'source': 'novel'}],
'included': [<IncludeEnum.documents: 'documents'>,
<IncludeEnum.metadatas: 'metadatas'>]}
# 1つのドキュメントだけアップデート
vector_store_server.update_documents(
ids=current_ids[:1],
documents=[document_1_update])
#アップデート後をまた取得して確認
collection_sv1.get(ids=current_ids[:1])
{'ids': ['9a6f4126-7709-456e-ac73-8cabfc386227'],
'embeddings': None,
'documents': ['ドキュメント1 上書きデータ'],
'uris': None,
'data': None,
'metadatas': [{'source': 'update_novel'}],
'included': [<IncludeEnum.documents: 'documents'>,
<IncludeEnum.metadatas: 'metadatas'>]}
確かに上書きされました。
5.OpenAI x LangChain x Sreamlit x Chroma 初手(2)
ここまででChromaDBの構築方法やドキュメント更新方法がわかりました。
これを踏まえて、streamlitへの初手を修正してみます
5.1 修正点
- サーバ構築は
.from_documetsメソッド利用をやめる。代わりにクライアント側構築(Chroma)もしくはサーバー側から構築(LangChain Chroma v0.3)を使って作る。以下のサンプルは後者を利用 - サーバにドキュメントを登録する際は、UPSERTを使う。すなわち同じドキュメントIDであれば上書きするし、そうでなければ追加(これを利用するにはクライアント側からのupsertもしくは、サーバに対してLangChainの
.add_documentsメソッドを使う。以下サンプルは後者を利用 - ユニークなID、かつ同じドキュメントであれば同じIDが、自動付与される仕組みを組み込む
3.1 例えばはuuidであれば、ユニークなIDにはなりますが、「同じドキュメントの場合は、同じIDになる」という条件を満たすには、仕組みを作り込む必要があります
3.2 私が紹介する例は1つのテクニックではありますが、スプリッター(ここでは、RecursiveCharacterTextSplitter)を利用する際に、add_start_index=Trueのオプションを入れることです。 これにより、自動的に「チャンク分割後のチャンクごとに、最初の文字が分割前ドキュメントの何文字目からスタートか」の情報がメタデータに入ります。これをうまく利用してIDを作ります。start_indexの数字と、入力ドキュメントのファイル名を組み合わせれば、同じファイルで同じ分割をすれば必ず同じIDになります.これをidsのリストにして登録します - サーバにドキュメントが正常に登録できたか確認できる画面や、登録したデータを削除する仕組みもほしい
- 一回登録したデータは揮発してくほしくないので、データ永続性を利用(すなわちPersist_clientを使う)
- LLMへの質問画面と、サーバへのドキュメント登録・追加・確認・削除画面をサイドメニューで分ける
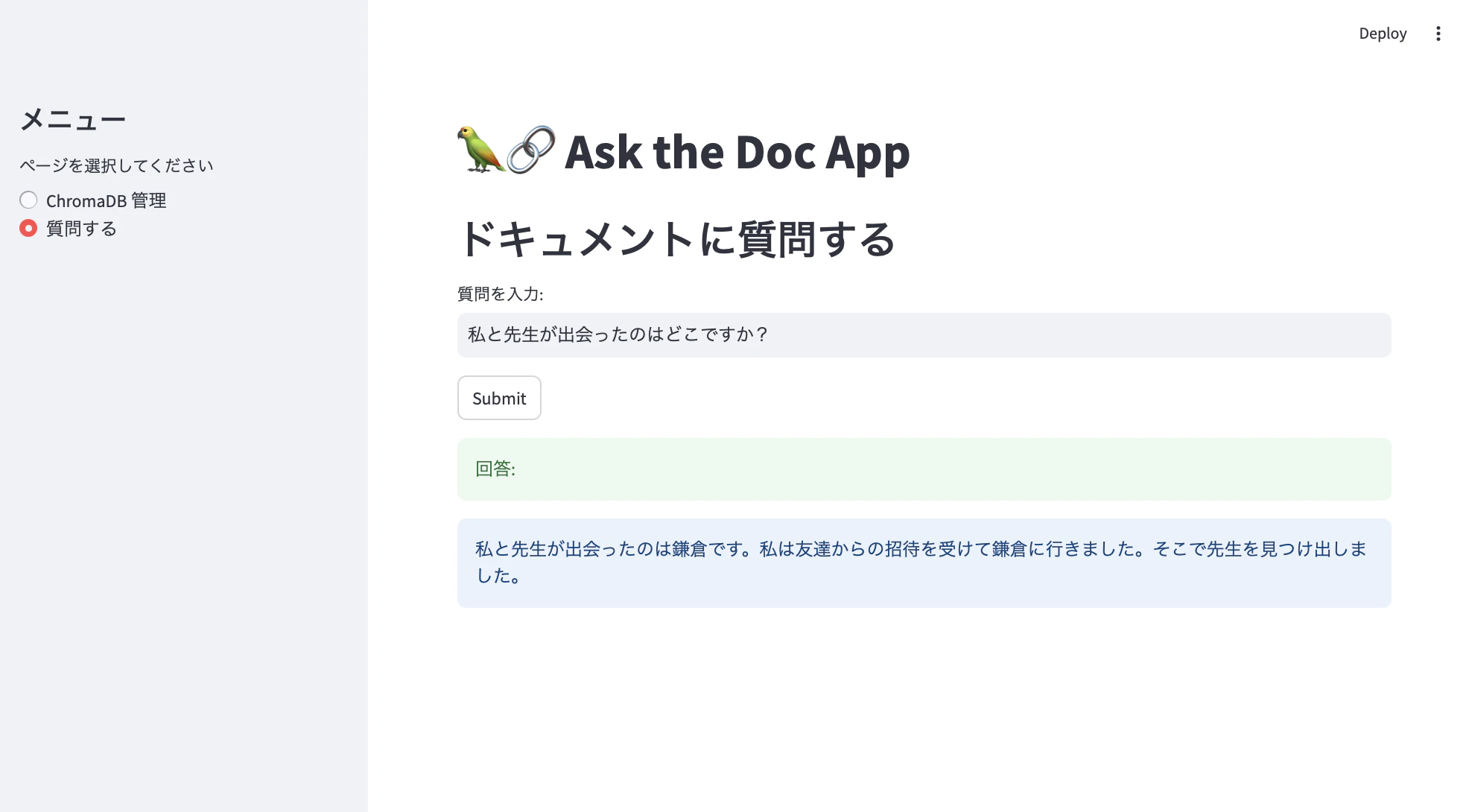
5.2 完成した画面イメージ
- 再度メニューで画面をわけ、ChromaDB 管理と、LLMに質問できる質問画面を分けています
-
文章登録画面(夏目漱石の「それから」の冒頭をsample.txtとして入れています)

-
質問の画面
4.3 最終版コード
以下が完成した最終版コードです
PJ_folder
├── app.py
├── .env
├── components
│ └── llm.py ## envをロードしてllmを作るところだけを記述
└── chromadb_server # 永続化するフォルダを作成
└── chroma.sqlite3 #Chromaによって自動作成
import streamlit as st
from langchain_openai import OpenAI
from langchain_chroma import Chroma
from langchain import hub
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
# --- LLM --- (componentsフォルダにllm.pyを配置する)---
from components.llm import llm
from components.llm import oai_embeddings
# --- LLM ---
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
import tempfile
import os
import chromadb
import pandas as pd
def register_document(uploaded_file):
"""
アップロードされたファイルをChromaDBに登録する関数。
"""
if uploaded_file is not None:
# 一時ファイルに保存
with tempfile.NamedTemporaryFile(delete=False, suffix=".txt") as tmp_file:
tmp_file.write(uploaded_file.getvalue())
tmp_file_path = tmp_file.name
try:
# TextLoaderを使用してドキュメントをロード
loader = TextLoader(tmp_file_path)
raw_documents = loader.load()
# メタデータとして元のファイル名を設定
for document in raw_documents:
document.metadata['source'] = uploaded_file.name # 元のファイル名を設定
# ドキュメントを分割
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=512,
chunk_overlap=10,
add_start_index=True,
separators=["\n\n", "\n", ".", " ", ""],
)
documents = text_splitter.split_documents(raw_documents)
# IDsの作成
original_ids = []
for doc in documents:
source_ = os.path.splitext(doc.metadata['source'])[0] # 拡張子を除く
start_ = doc.metadata['start_index']
id_str = f"{source_}_{start_:08}" #0パディングして8桁に
original_ids.append(id_str)
# LangChain の Chroma クラスを使用してChroma DBに接続
vector_store_server = Chroma(
collection_name="collection_name_server",
embedding_function=oai_embeddings,
persist_directory="./chromadb_server",
)
# ドキュメントの追加(UPSERT)
vector_store_server.add_documents(
documents=documents,
ids=original_ids
)
st.success(f"{uploaded_file.name} をデータベースに登録しました。")
except Exception as e:
st.error(f"ドキュメントの登録中にエラーが発生しました: {e}")
finally:
os.remove(tmp_file_path) # 一時ファイルを削除
def manage_chromadb():
"""
ChromaDBを管理するページの関数。
"""
st.header("ChromaDB 管理")
# ChromaDBの初期化とコレクションの取得
client_from_sv = chromadb.PersistentClient(path="./chromadb_server")
try:
collection_sv = client_from_sv.get_collection(name="collection_name_server")
except:
collection_sv = client_from_sv.create_collection(name="collection_name_server")
st.info("ChromaDB コレクションを新規作成しました。")
# 1.ドキュメント登録
st.subheader("ドキュメントをデータベースに登録")
uploaded_file = st.file_uploader('テキストをアップロードしてください', type='txt')
if uploaded_file:
if st.button("登録する"):
with st.spinner('登録中...'):
register_document(uploaded_file)
st.markdown("---")
# 2.登録状況確認
st.subheader("ChromaDB 登録状況確認")
if st.button("登録済みドキュメントを表示"):
with st.spinner('取得中...'):
dict_data = collection_sv.get()
if dict_data['ids']:
tmp_df = pd.DataFrame({
"IDs": dict_data['ids'],
"Documents": dict_data['documents'],
"Metadatas": dict_data['metadatas']
})
st.dataframe(tmp_df)
else:
st.info("データベースに登録されたデータはありません。")
st.markdown("---")
# 3.全データ削除
st.subheader("ChromaDB 登録データ全削除")
if st.button("全データを削除する"):
with st.spinner('削除中...'):
current_ids = collection_sv.get()['ids']
if current_ids:
collection_sv.delete(ids=current_ids)
st.success("データベースの登録がすべて削除されました")
else:
st.info("削除するデータがありません。")
# RAGを使ったLLM回答生成
def generate_response(query_text):
"""
質問に対する回答を生成する関数。
"""
if query_text:
try:
# LangChain の Chroma クラスを使用してChroma DBに接続
vector_store_server = Chroma(
collection_name="collection_name_server",
embedding_function=oai_embeddings,
persist_directory="./chromadb_server",
)
# リトリーバーとQAチェーンの設定
prompt = hub.pull("rlm/rag-prompt")
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
qa_chain = (
{
"context": vector_store_server.as_retriever() | format_docs,
"question": RunnablePassthrough(),
}
| prompt
| llm
| StrOutputParser()
)
return qa_chain.invoke(query_text)
except Exception as e:
st.error(f"質問の処理中にエラーが発生しました: {e}")
return None
def ask_question():
"""
質問するページの関数。
"""
st.header("ドキュメントに質問する")
# Query text
query_text = st.text_input('質問を入力:',
placeholder='簡単な概要を記入してください')
# 質問送信ボタン
if st.button('Submit') and query_text:
with st.spinner('回答を生成中...'):
response = generate_response(query_text)
if response:
st.success("回答:")
st.info(response)
else:
st.error("回答の生成に失敗しました。")
def main():
"""
アプリケーションのメイン関数。
"""
# ページの設定
st.set_page_config(page_title='🦜🔗 Ask the Doc App', layout="wide")
st.title('🦜🔗 Ask the Doc App')
# サイドバーでページ選択
st.sidebar.title("メニュー")
page = st.sidebar.radio("ページを選択してください", ["ChromaDB 管理", "質問する",])
# 各ページへ移動
if page == "質問する":
ask_question()
elif page == "ChromaDB 管理":
manage_chromadb()
if __name__ == "__main__":
main()
# OPENAI API KEY (自分で取得したもの)
OPENAI_API_KEY = sk-xxxxxxxxxxxxxxxx
import os
from dotenv import load_dotenv
load_dotenv() # .envファイルは親ディレクトリ方向に探索される
OPENAI_API_KEY = os.environ.get('OPENAI_API_KEY')
from langchain_openai import ChatOpenAI
from langchain_openai import OpenAIEmbeddings
# ChatOpenAI
llm = ChatOpenAI(
model="gpt-4o-mini",
temperature=0,
api_key=OPENAI_API_KEY
)
# Embedding モデル
oai_embeddings = OpenAIEmbeddings(
model="text-embedding-3-small" #モデルを設定しておく
)
# 動作確認
if __name__ == "__main__":
# LLM試験
res = llm.invoke("こんにちは")
print(res)
# Embeddings試験
# single_vector = embeddings.embed_query(text)
# two_vectors = embeddings.embed_documents([text, text2])
documents=["こんにちは","こんばんは"]
embeddings_doc = oai_embeddings.embed_documents(documents)
# 長いので最初のテキストの最初の5つのみ
print(embeddings_doc[0][:5])
5.4 UIについて
UIをもう少し変えたければ、以下などが参考になります。例えばサイドメニューをラジオボタンではなく、それっぽいメニューにしたり、DB登録状況を確認するテーブルをもう少しリッチな画面にしたりとか
6.参考
6.0 LangChainのTrutorial
v0.2 LangChain tutorials rag
v0.3 LangChain tutorials rag
- v0.3では、Select vector store In-memoryをプルダウンメニューからChromaに変えます
- v0.2まで記載のあった
.from_documentsに変わって、.add_documentsになっていますので、.from_documentsメソッドはもう使わないほうがいいと思います
6.1 ChromaDB
6.2 LanChain Chroma
6.3 LangChain tutorial #4: Build an Ask the Doc app
6.4 Chroma DBの基本的な使い方 | データ保存, Embedding, データの永続化, サーバー起動など
ChromaDBの完全なチュートリアル
ChromaDB チュートリアル(Github)