最近、DeepSeekが開発したDeepSeek-R1という、第1世代推論モデルが注目を浴びています。その強みは数学、コーディング、推論タスクでのパフォーマンスの高さであり、多くのベンチマークでも非常に優秀な結果を出しています。今回私は、この「DeepSeek-R1-Distill-Qwen-7B」モデルを実際にPlatform for AI (PAI)で微調整することに挑戦しました。
DeepSeek-R1とは?
DeepSeek-R1はDeepSeekが開発したAIモデルで、LLamaやQwenモデルをベースとした、様々な高密度な蒸留モデルが作成されています。
その中でも今回利用したのは「DeepSeek-R1-Distill-Qwen-7B」というモデルです。比較的小規模で、個人でも扱いやすいモデルサイズです。
環境構築と準備
PAIのコンソールにログインして、事前に用意していたワークスペースを開きました。地域設定を行い(今回はシンガポールリージョン)、左側のナビゲーションから「QuickStart」「Model Gallery」を選んで、該当のモデルカードをクリックすると、モデルの詳細ページが表示されます。
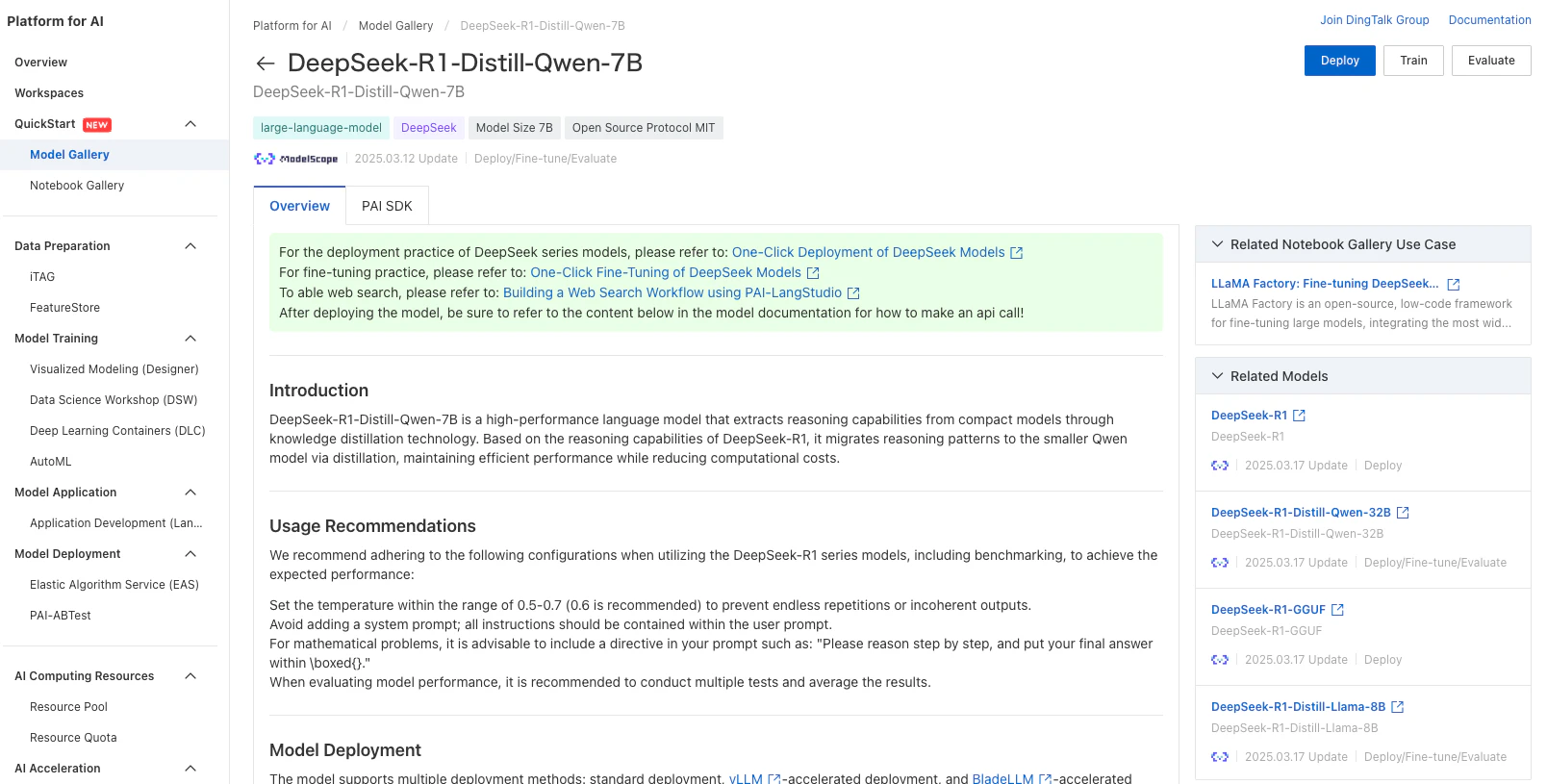
ここではモデルの詳細、微調整用のデータ形式、利用手順などの細かい情報を見ることができます。
トレーニング
右上にある「Train(トレーニング)」をクリックして、次の設定を行いました。
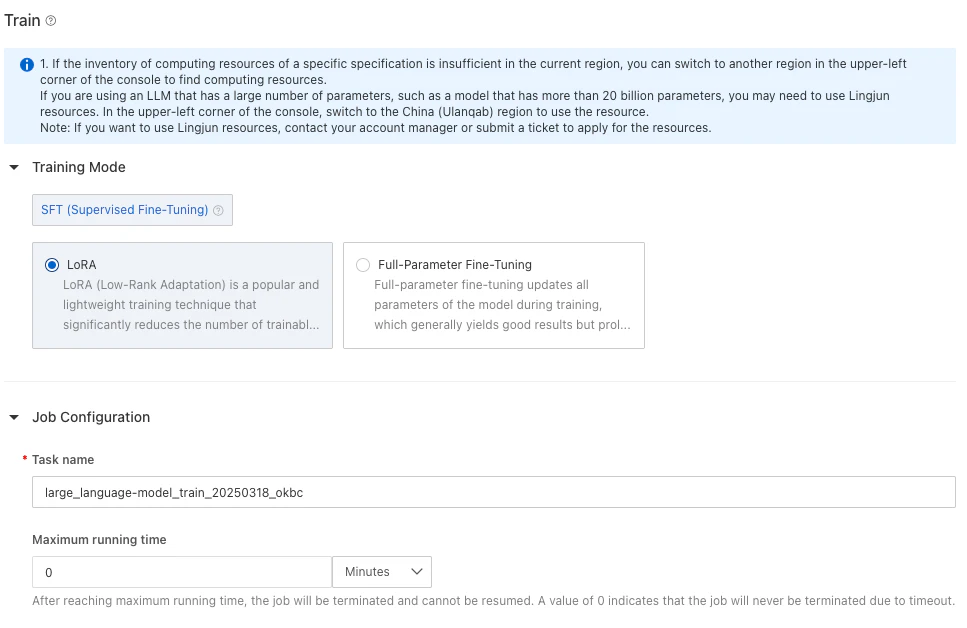
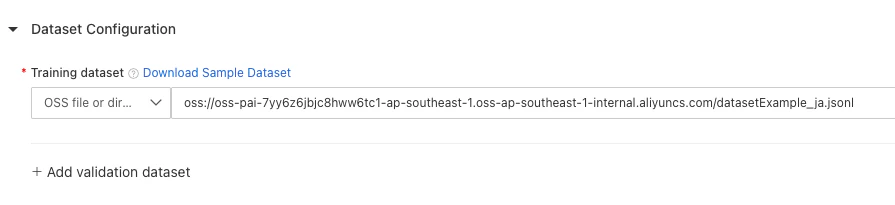
データセットの構成
事前に準備したデータをAlibaba CloudのObject Storage Service (OSS)バケットにアップロード済み。「Download Sample Dataset」をダウンロードし、中国語の部分を日本語に変換したものを「OSS file or directory」でアップロードしたものを利用します。
下記が変換したデータのサンプルです。

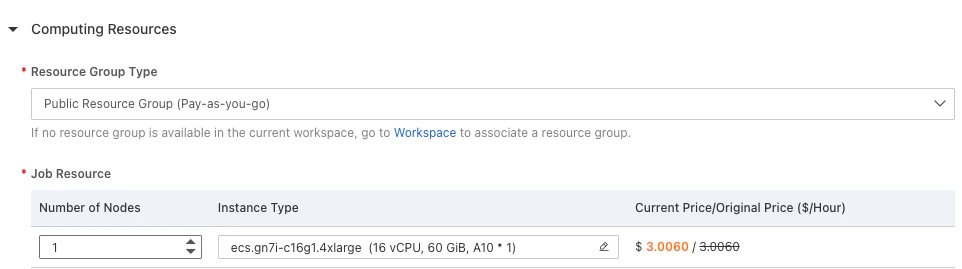
コンピューティングリソース
PAIの推奨する最低限設定(GPUの設定やメモリサイズなど)を選択。
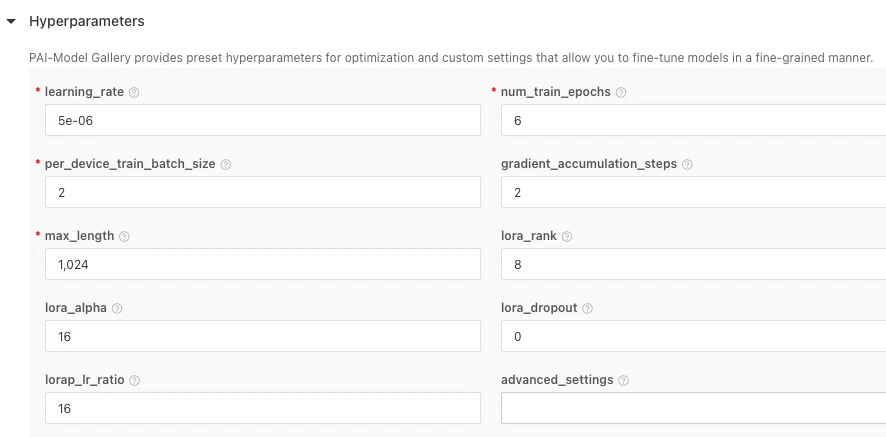
ハイパーパラメータ設定
主に以下のようなパラメータを設定しました(デフォルトの推奨値)。
- 学習率(learning_rate): 5e-6
- エポック数(num_train_epochs): 6
- デバイスごとのバッチサイズ(per_device_train_batch_size): 2
- 最大トークン長(max_length): 1024
- LoRAランク(lora_rank): 8
- LoRAドロップアウト率(lora_dropout): 0
特に、LoRA(Low-Rank Adaptation)はパラメータを効率的に調整できる手法で、小規模リソースのトレーニングでもパフォーマンス効率が期待できます。
トレーニング実施とその結果
設定が完了すると、「Train」でトレーニング開始。
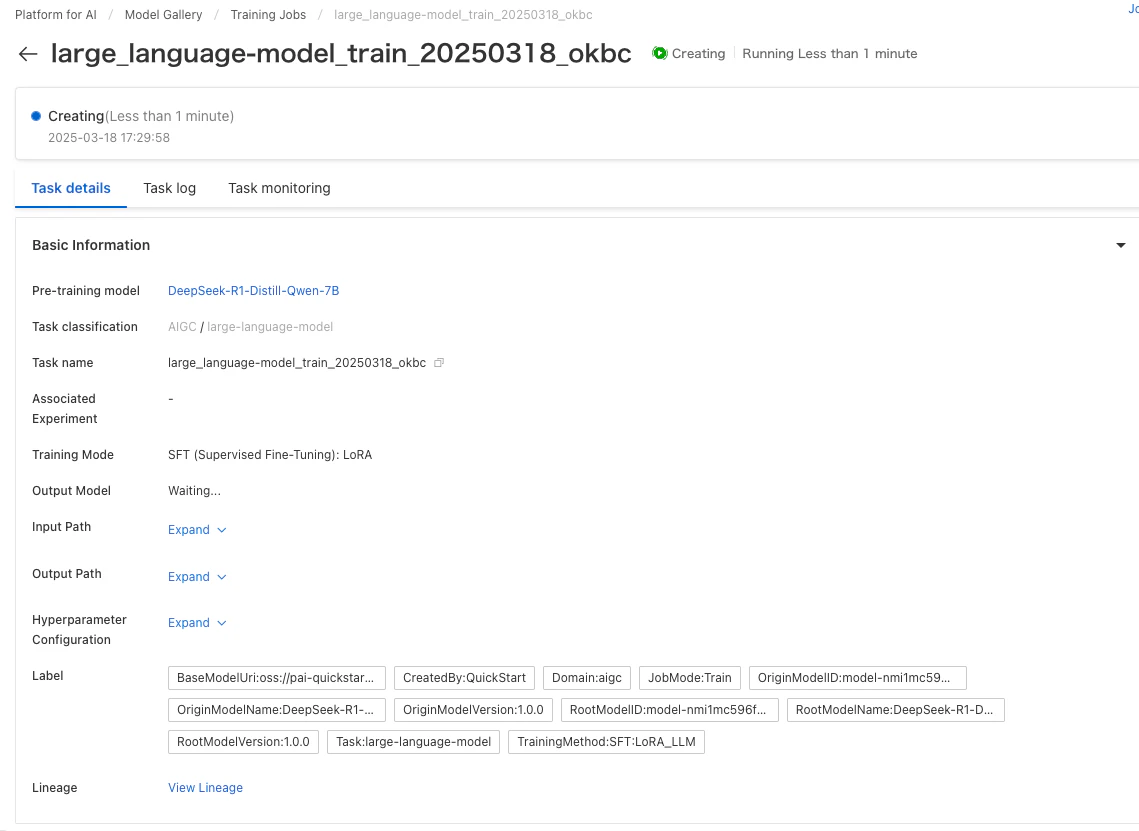
PAIのトレーニング画面で、進捗とログをリアルタイムで確認できます。

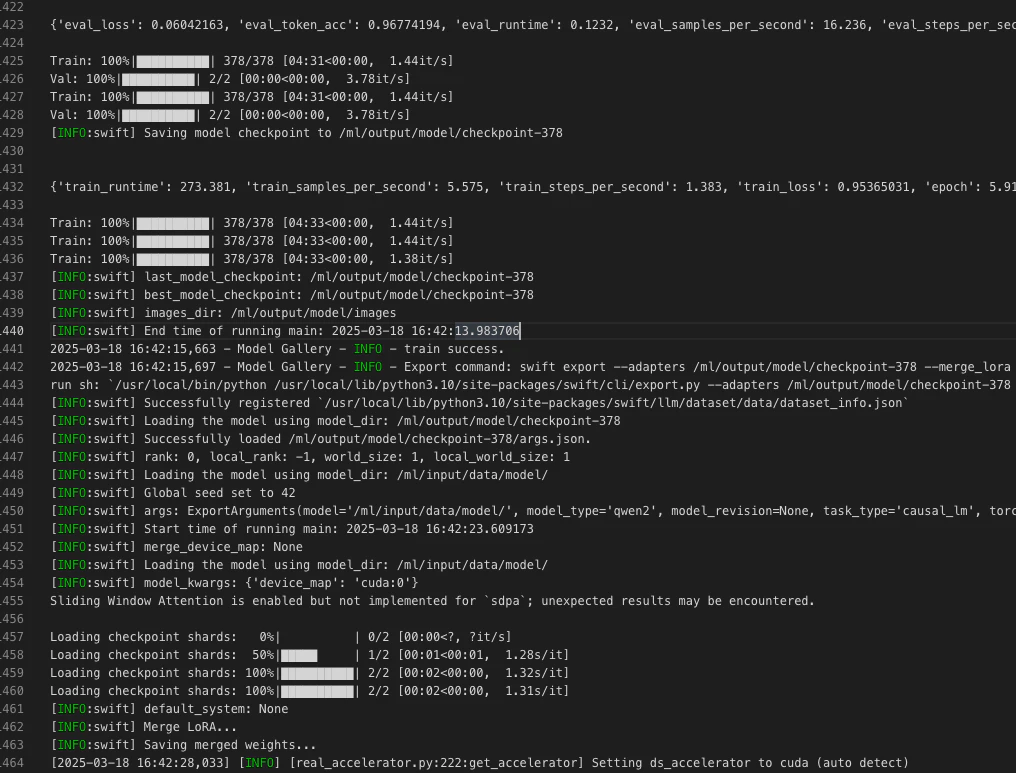
Task log
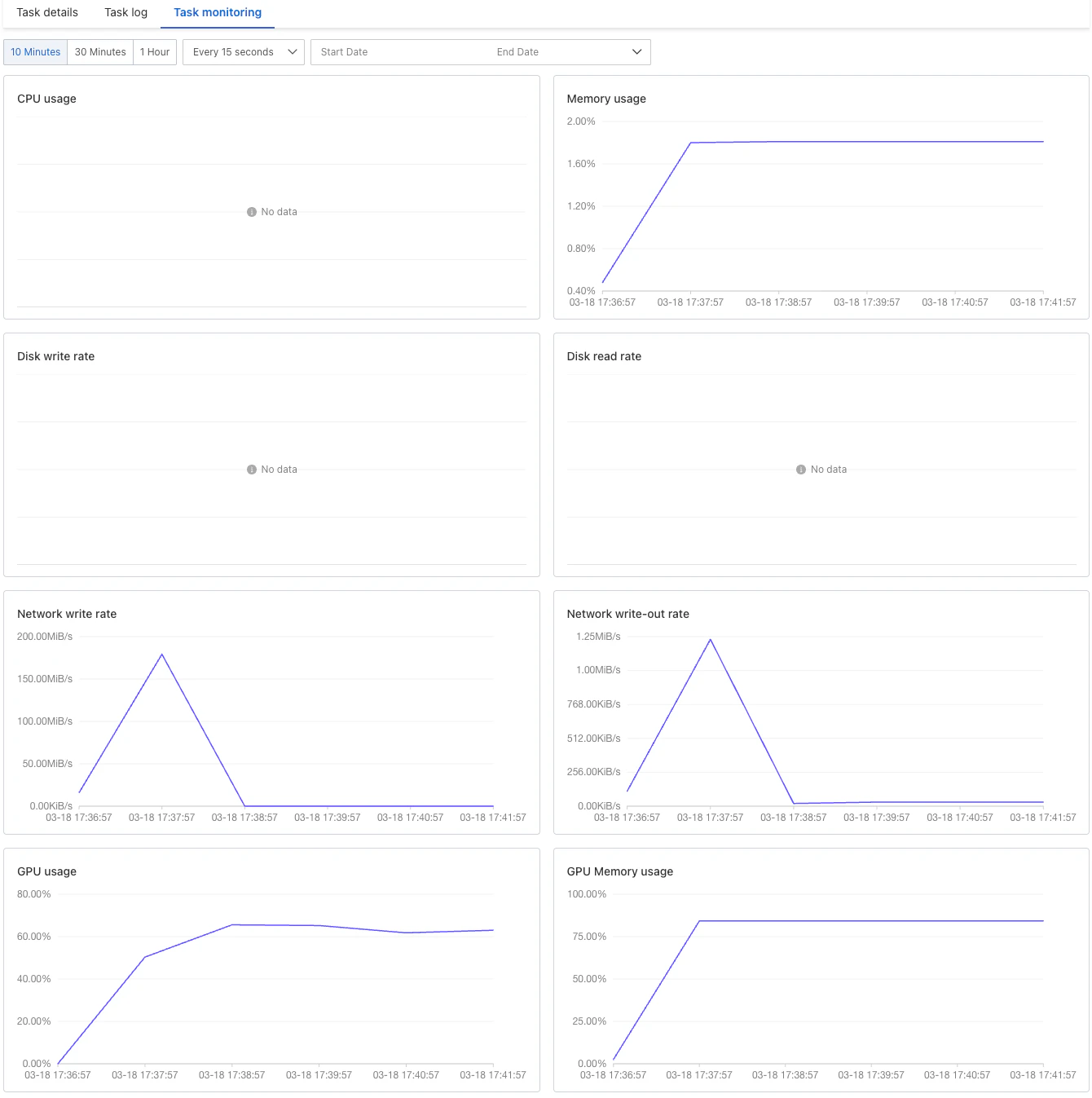
Task monitoring
Metric Curve
トレーニング中の損失の進行が表示されます。損失値が下降する様子が確認でき、問題なく進んでいることが分かりました。
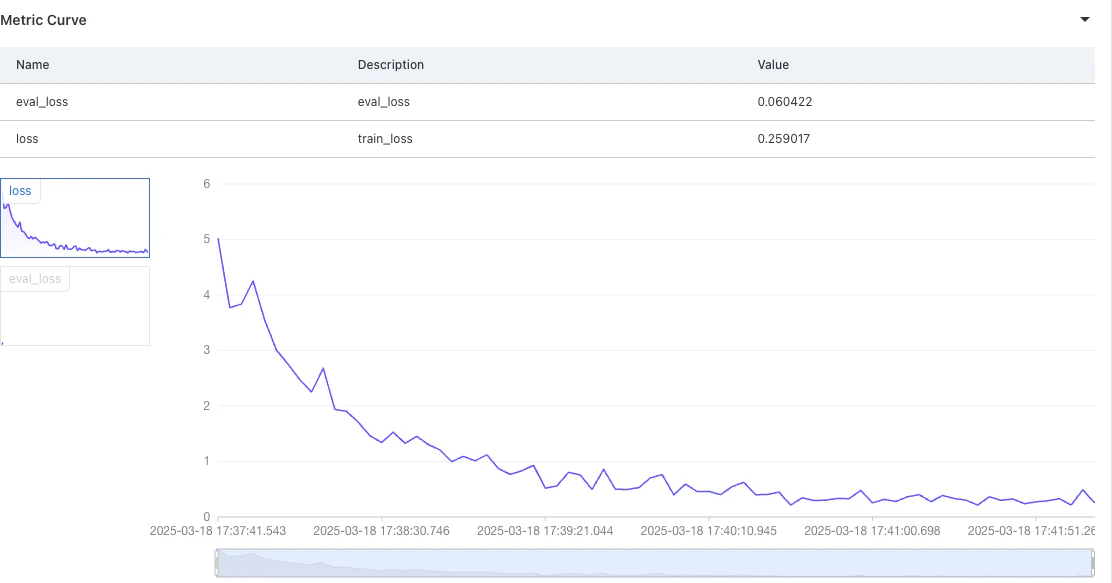
約15分でトレーニングが完了しました。

デプロイと実際の活用
トレーニングしたモデルはワンクリックでデプロイでき、EASサービスとして簡単に利用可能です。API経由でSNSや他システムと連携したり、個人的なプロジェクトでも応用できそうです。
デプロイ後、作成が始まります。
Runningになったら View Endpoint Information から URLとTokenを取得します。
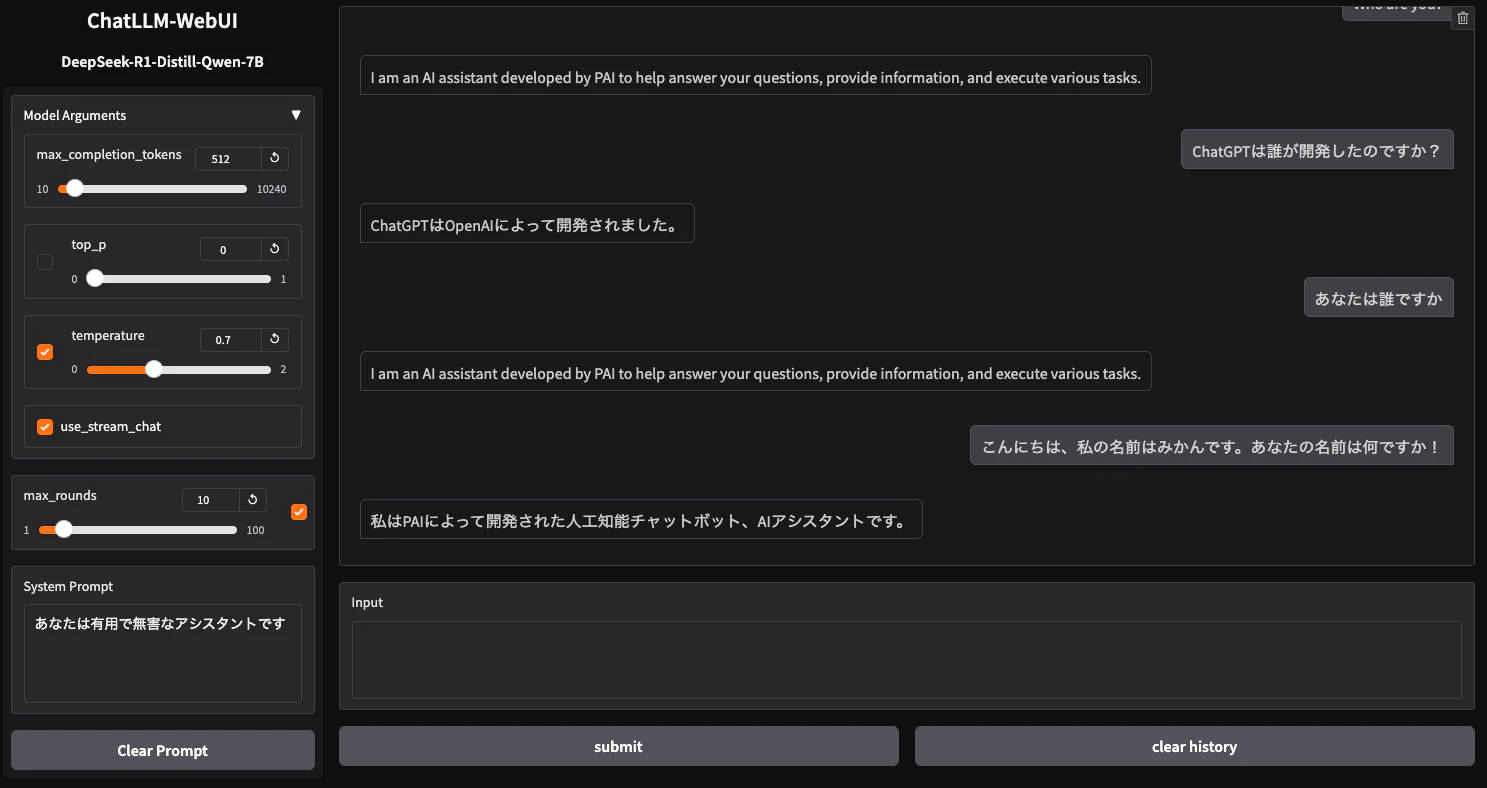
Pythonのプログラムを下記で実行し、Web UIにて確認していきます。
ダウンロードはここから。
https://github.com/aliyun/pai-examples/blob/master/model-gallery/deploy/llm/vLLM/webui_client.py
# 初回のみ環境整える
$ python -m venv .venv
$ source .venv/bin/activate.fish
$ pip install gradio openai
# 実行コマンド
$ python webui_client.py --eas_endpoint "<EAS API Endpoint>" --eas_token "<EAS API Token>"
...
* Running on local URL: http://127.0.0.1:7860
モデルがPAIによって開発されていることが学べています。
感想とまとめ
DeepSeek-R1モデルを自分の手で微調整した経験はとても有意義でした。手順が明確で迷いなくできるため、個人でも簡単にAIモデルの訓練ができそうでした