目次
1.はじめに
2.実行環境
3.分析手法
4.利用するデータ
5.分析
6.まとめ/反省
はじめに
分析技術、知識についてはほとんど初心者ではありますが、Pythonを用いて音楽データの分析を行いました。
私自身は、音楽データは所有していたいという古い考えを持っていたため、これまでサブスクはあまり多く利用してきていないのですが、SpotifyのAPIから面白いデータが取得できると聞き、これを用いた分析を行うこととしました。
当初の想定としては、Spotifyにて人気楽曲Top50のプレイリストが作成されている63ヶ国について、気象条件や地理的特徴、人口動態といった国の特性と好まれる楽曲の特徴を紐づけることができれば、と期待していましたが、当然のことながらマクロの人口データなどは各国について一意となり、サンプルデータが国の数だけとなってしまうため、断念しました。
そこで今回は分析の一歩目として、まず各国および地域における特性を把握し、それらの特性がどういった要因から形成されたものであるかについて、仮説を立てるところまでを目的としたいと思います。
実行環境
- OS Windows10
- Python 3.7.13
※Google Colaboratoryを使用
分析手法
Spotify APIから取得できる楽曲の特性データのうち、数値(=連続変数)として取得されるもの(後述)について、各国の人気曲Top50のプレイリストに含まれる楽曲の特徴を整理し、各国/地域における嗜好を確認します。
利用するデータ
取得可能な特性データは以下の通り;
- acousticness
- 楽曲のアコースティック(生音)である度合い
- dancability
- 楽曲がどれだけダンスに適しているかの度合い
- energy
- 楽曲の激しさや活気の度合い
- duration (length)
- 楽曲の長さ(ms)
- instrumentalness
- 楽曲における歌声のない箇所の度合い(スキャットやフェイクなどは歌声とみなされないらしい)
- liveness
- 楽曲内で聴衆の存在が検知される度合い
- loudness
- デシベル(dB)で表される音の大きさ
- speechiness
- 楽曲内で歌われるのではなく、話された単語の量の度合い。トークショーや本の朗読などのトラックでは、この指標が高くなる
- tempo
- BPMで表される曲のテンポ
- valence
- 楽曲の明るさ/暗さの度合い。楽しい、元気づけられる曲調であればこの値が高くなり、逆に陰鬱な曲であれば低くなる
- Popularity
- 曲の人気度。再生回数によって計算される
上記の他、キーやコードなどのデータも取得できますが、今回の分析では利用していません。詳細については、Spotify for Developersページを参照のこと。
分析
1. Spotify APIへのアクセス申請
SpotifyのWeb APIを利用するためには、SpotifyへDeveloper申請を行った上で、取得したClient IDおよびClient Secretの取得が必要となります。
参考:Spotify Web APIから分析用データセットをつくる
以下の通り、Client IDとClient Secretを読み込ませることで、事前準備は完了です。
("Spotipy"はSpotify API利用のためのライブラリです)
# spotify developerから取得したclient_idとclient_secretを入力
client_id = '************************'
client_secret = '************************'
client_credentials_manager = SpotifyClientCredentials(client_id, client_secret)
sp = spotipy.Spotify(client_credentials_manager=client_credentials_manager)
2. データ整理
ある国の人気Top50の楽曲についての特性データは、以下の流れで取得します。
- Top50のプレイリストのIDを取得
※以下の赤枠の部分がプレイリストのIDを表します
今回は、Top50プレイリストが作成されている63ヶ国を対象とするため、以下の通り、辞書形式でプレイリストIDを一覧化しておきます。# 各国のTop50プレイリストのIDを取得し、辞書形式でリストを作成 country_name_to_playlist_id={ "JPN" : '37i9dQZEVXbKXQ4mDTEBXq', #日本 "USA" : '37i9dQZEVXbLRQDuF5jeBp', #アメリカ "PHL" : '37i9dQZEVXbNBz9cRCSFkY', #フィリピン (中略) "ARE" : '37i9dQZEVXbM4UZuIrvHvA', #アラブ首長国連邦 "LUX" : '37i9dQZEVXbKGcyg6TFGx6' #ルクセンブルク } - 対象のプレイリストに含まれる楽曲のIDを取得
続いて、プレイリストのIDから楽曲のIDを取得する関数を"getTrackIDs"を定義します。
参考:世界のSpotify「週間トップ50」をPythonで分析# track idを取得する関数getTrackIDsを定義 def getTrackIDs(playlist_ids): track_ids = [] for playlist_id in playlist_ids: playlist = sp.playlist(playlist_id) while playlist['tracks']['next']: for item in playlist['tracks']['items']: track = item['track'] if not track['id'] in track_ids: track_ids.append(track['id']) playlist['tracks'] = sp.next(playlist['tracks']) else: for item in playlist['tracks']['items']: track = item['track'] if not track['id'] in track_ids: track_ids.append(track['id']) return track_ids - 楽曲IDをもとに、各曲の特性データを取得
2で取得した楽曲IDをキーとして特性データを取得する関数"getTrackFeatures"を以下のように定義します。
参考:世界のSpotify「週間トップ50」をPythonで分析# 各楽曲の情報を取得する関数getTrackFeaturesを定義 def getTrackFeatures(id): meta = sp.track(id) features = sp.audio_features(id) name = meta['name'] album = meta['album']['name'] artist = meta['album']['artists'][0]['name'] release_date = meta['album']['release_date'] length = meta['duration_ms'] popularity = meta['popularity'] key = features[0]['key'] mode = features[0]['mode'] danceability = features[0]['danceability'] acousticness = features[0]['acousticness'] energy = features[0]['energy'] instrumentalness = features[0]['instrumentalness'] liveness = features[0]['liveness'] loudness = features[0]['loudness'] speechiness = features[0]['speechiness'] tempo = features[0]['tempo'] time_signature = features[0]['time_signature'] valence = features[0]['valence'] track = [name, album, artist, release_date, length, popularity, key, mode, danceability, acousticness, energy, instrumentalness, liveness, loudness, speechiness, tempo, time_signature, valence] return track - 各国の人気曲Top50をまとめてデータフレーム化
定義した二つの関数を実行し、全対象国の人気曲をまとめてデータフレームとして取得します。
なお、どの国のデータであるかを判別するため、末尾に国コードの列を追加しています。以下のような形で結果が出力されます。(9/3時点の結果。国のリストのトップに日本を置いていたため、日本のTop5が表示されていますが、映画大ヒット中のワンピース関連が非常に強いです)country_names = ['JPN','USA','PHL','IDN','IND','VNM','ROC','PRY','TUR','BRA','MEX','THA','CHL','PER','FRA','ITA','COL','ESP','HKG','DEU','ARG','ISR','ECU','GBR','DOM','HND','MAR','MYS','UKR','EGY','DNK','BOL','GRC','CAN','POL','PRT','PAN','SGP','AUS','SLV','IRL','URY','KOR','CRI','NLD','SWE','GTM','NOR','HUN','ROU','EST','CHE','BEL','AUT','CZE','FIN','BGR','NZL','SAU','NIC','ISL','LVA','SVK','LTU','ZAF','ARE','LUX'] tracks = [] for country_name in country_names: time.sleep(0.5) playlist_id = country_name_to_playlist_id[country_name] #事前に作成した辞書を用いて、国名をplaylist idに変換 track_ids = getTrackIDs([playlist_id]) for track_id in track_ids: try: track = getTrackFeatures(track_id) track = track+[country_name] tracks.append(track) except Exception: continue df = pd.DataFrame(tracks, columns = ['name', 'album', 'artist', 'release_date', 'length', 'popularity','key', 'mode', 'danceability', 'acousticness', 'energy', 'instrumentalness', 'liveness', 'loudness', 'speechiness', 'tempo', 'time_signature', 'valence',"country"]) df.head()
3. 箱ひげ図の作成
取得した指標のそれぞれについて、全対象国をまとめた箱ひげ図を作成することで、国による差異を確認します。
地域ごとにまとめての表示とするため、以下の通りにグルーピングを行った上で、地域(Region)列をDataframeに追加します。
- 各地域および国
- アフリカ(南アフリカ・モロッコ・エジプト)
- アジア(タイ・日本・香港・フィリピン・シンガポール・マレーシア・韓国・インド・ベトナム・インドネシア・台湾)
- ヨーロッパ(ノルウェー・スウェーデン・ハンガリー・ルーマニア・アイルランド・ポルトガル・ポーランド・オランダ・ベルギー・アイスランド・ラトビア・ブルガリア・フィンランド・リトアニア・ルクセンブルク・スロバキア・チェコ・エストニア・スイス・オーストリア・デンマーク・イタリア・ウクライナ・イギリス・フランス・スペイン・ドイツ・トルコ・ギリシャ)
- 中東(イスラエル・アラブ首長国連邦・サウジアラビア)
- 北米(アメリカ・カナダ)
- 南米(地理・メキシコ・グアテマラ・ニカラグア・エルサルバドル・ブラジル・パラグアイ・パナマ・ボリビア・ペルー・アルゼンチン・ドミニカ共和国・ホンジュラス・コスタリカ・エクアドル・ウルグアイ・コロンビア)
- オセアニア(オーストラリア・ニュージーランド)
"Region"の列を追加したDataFrameを"merged_data"とします。
地域ごとに異なる色で表示するため、各地域の色を定義します。
Region_to_color={'Africa':'#F08080',
'Asia':'#E6E6FA',
'Europe':'#B0E0E6',
'Middle East':'#F8B400',
'North America':'#00FFFF',
'Oceania':'#FF7F50',
'South America':'#FFDEAD'}
設定した色を、地域内の国に対しても反映します。
country_to_color={}
for country_,region_ in merged_data[["country","Region"]].values:
if country_ not in country_to_color:
country_to_color[country_]=Region_to_color[region_]
色の設定が完了しましたので、実際に箱ひげ図を作成します。
今回対象とする指標は11項目のため、11行1列のサブプロットに各グラフを表示します。
箱ひげ図の色は変数"palette"を用いて設定できるため、palette=country_to_colorとすることで、各国の色が定義通りに表示されます。
また、基本的にすべての項目に対し、sym=""とすることで、外れ値のを非表示としています。"instrumentalness"のみは、下図に示されるとおり外れ値が非常に多く、あまり有意と思われる結果が得られないため、全て表示としています。
track_sort = merged_data.sort_values('Region')
fig, axes = plt.subplots(11,1, figsize=(25,40))
sns.boxplot(x='country', y='length', data=track_sort, palette=country_to_color, showmeans=True, sym="", ax=axes[0])
sns.boxplot(x='country', y='popularity', data=track_sort, palette=country_to_color, showmeans=True, sym="", ax=axes[1])
sns.boxplot(x='country', y='danceability', data=track_sort, palette=country_to_color, showmeans=True, sym="", ax=axes[2])
sns.boxplot(x='country', y='energy', data=track_sort, palette=country_to_color, showmeans=True, sym="", ax=axes[3])
sns.boxplot(x='country', y='loudness', data=track_sort, palette=country_to_color, showmeans=True, sym="", ax=axes[4])
sns.boxplot(x='country', y='liveness', data=track_sort, palette=country_to_color, showmeans=True, sym="", ax=axes[5])
sns.boxplot(x='country', y='speechiness', data=track_sort, palette=country_to_color, showmeans=True, sym="", ax=axes[6])
sns.boxplot(x='country', y='tempo', data=track_sort, palette=country_to_color, showmeans=True, sym="", ax=axes[7])
sns.boxplot(x='country', y='acousticness', data=track_sort, palette=country_to_color, showmeans=True, sym="", ax=axes[8])
sns.boxplot(x='country', y='valence', data=track_sort, palette=country_to_color, showmeans=True, sym="", ax=axes[9])
sns.boxplot(x='country', y='instrumentalness', data=track_sort, palette=country_to_color, showmeans=True, ax=axes[10])
plt.suptitle("Track Features by Country", y=0.89)
plt.show()
出力結果
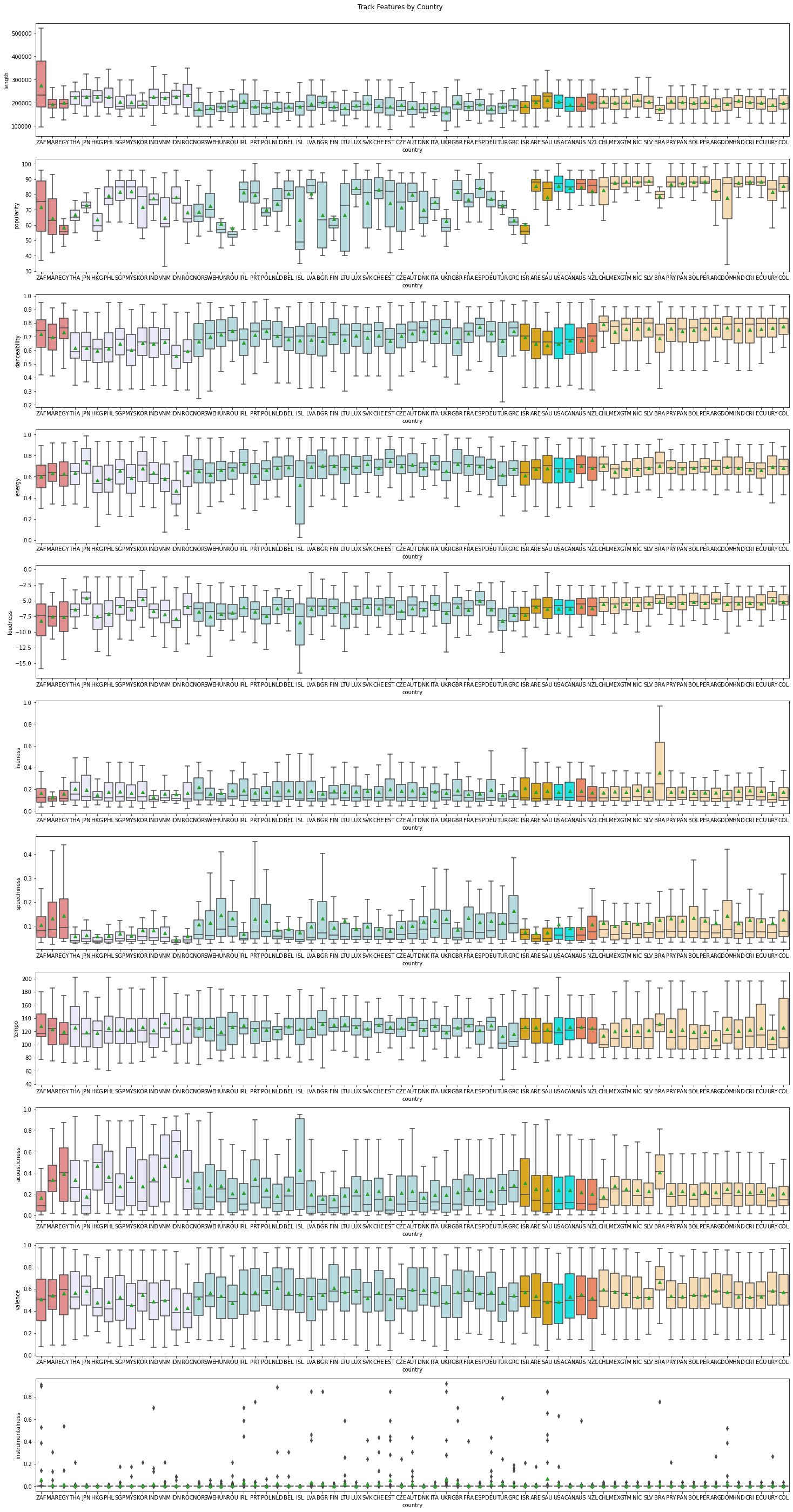
4. 読み取り/分析
上記の出力結果から読み取ることのできる内容を、各指標について整理します。
-
Length
楽曲の長さについては、アジア諸国では若干長い曲が好まれているが地域間での大きな差はなく、主に20,000ms(=200秒≒3分)前後の長さが一般的であり、驚くべき点はないように思われる。唯一南アフリカは他国の傾向から外れ、長い曲が好まれているようである。確かに実際にプレイリストを見ると、6~8分といった長い曲が複数含まれている。 -
Popularity
Popularityは、Spotifyでの再生回数が多いほど高くなる指標であるため、世界のトレンドに対する感応度が観察できるものと考えられる。各国間でかなりばらつきがあるが、南米諸国が総じて高い数値を示していることは興味深い。音楽については、世界的なトレンドの多くがアメリカやイギリスなどの英語圏から作られるものと考えると、英語を公用語とする国においてPopularityは高くなるものと予想していたが(アジアではシンガポール、フィリピン、マレーシアなど、英語を公用語に持つ国において高い数字が記録されている)、南米諸国の公用語の多くはスペイン語であり、予想に反した結果となった。むしろ、英語圏のトレンドとは別に南米という地域内でのトレンドが作られるため、この地域間での嗜好は類似するのかもしれない。 -
Danceability
ダンスに適しているかを測るこの指標については、アジアは相対的に若干低く、ヨーロッパや南米で高くなっている。正直、この指標がどのように決められているのかが不明ではあるが、南米の人々がダンスを好むというのは、ステレオタイプ的イメージには合致しているような気もする。。 -
Energy/Loudness
曲の激しさや音の大きさについては、平均で見ると地域間での大きな差異はない。アジアについて見ると、日本と韓国は同じく高い水準にあり、インドネシアでは低くなっている。日韓のトレンドの類似性については、日本でK-Popが流行している現状を見れば納得できる。インドネシアで比較的静かな音楽が好まれている要因は不明だが、アジア地域内でのインドネシアの特徴として一番に思いつくものとして、宗教が挙げられる。今回の分析では、宗教観の影響を確認することはできないが、一つの可能性として、今後の分析に生かすことはできるかもしれない。
その他、アイスランドの箱ひげ図は下に大きく伸びているが、アイスランドの有名なアーティストの楽曲を想像すると、驚くべき結果ではないと思われる。 -
Liveness
観客の存在の度合い、つまりそのトラックがライブ盤のようなものであれば高くなる指標だが、ブラジルの数値だけが異様に高くなっている。ブラジルのプレイリストを見ると、"Ao Vivo"(ポルトガル語でライブ)と付記されている楽曲が非常に多いことが分かる。これが恒常的なトレンドなのか一過性なものなのかは今回の分析では分からないが、ライブ盤が好まれるという特性がもしあれば、非常に興味深い結果である。 -
Speechiness
地域間で観察すると、アジアや北米、中東では低く、アフリカ、ヨーロッパ、南米で高くなっている。朗読などがそれほど多くTop50に入るとは想像しにくいため、ラップやポエトリーリーディングなどが流行っている国では、高い傾向になっているものと考えられる。いまだにラップというとアメリカ西海岸を想像してしまうが、もはやアメリカでの流行はそれほど強くはないのだろうか。 -
Tempo
テンポについては、箱ひげ図の範囲は幅広くなっているが、平均値で見ると非常に近く、BPM120程度の曲がどこの地域でも好まれていることが分かる。 -
Acousticness
アジアでは総じて高く、生音の楽曲が好まれる傾向にあるようである。ただし日本はこの例に当てはまらず、ヨーロッパや南米諸国と同水準となっている。上で韓国との類似性に言及した中、この指標については差異が大きくなっており、興味深い点である。(今の日本の人気曲を考えると、生音の度合いが低いのは想定通りであり、個人的なイメージとしては、韓国の数値の高さが不思議に感じられる。)
やはりアイスランドに非常に高い値が見られるのは、Energy/Loudnessと同様にイメージ通りと言える。またブラジルでも他の南米諸国と異なるトレンドとなっているのは、ボサノヴァなどのジャンルへの嗜好によるものなのであろうか。 -
Valence
曲のポジティブ/ネガティブの度合いを示すこの指標だが、ほぼ0.5の中庸なところに平均は集まっている。この指標についても測定方法が不明だが、ブラジルの値が他国に比べて高くなっているのは、ブラジルという国のイメージとは合うようにも思える。 -
Instrumentalness
先述の通り、Instrumentalnessについては外れ値が多く、ここから何か示唆を得ることは難しいようである。
まとめ/反省
以上、SpotifyのAPIを用いて各国の音楽性向の分析を行いました。
この分析をぼんやりと思いついた時点では、アイスランドやブラジルを想像し、国ごとに特色があるのではと考えていましたが、これらの二ヶ国は特に特徴がはっきりしており、その他の国についてはあまり顕著な差異が見られない部分も多くありました。一方で、大きな差異がないのはグローバル化の進展の結果でもあり、まさにSpotifyによって世界中の楽曲を自由に視聴することができるようになることで、全体としてのトレンドは一層集約されていくものと思われます。
また、アジアでは地域としてAcousticnessの値が高かったり、また南米諸国は全体的に同様の性向を持っている点など、興味深い差異もありました。
なお、今回の反省点としては、以下の点が挙げられます。
-
特性の分析のみに終始してしまったこと
初めにも記載しました通り、データの少なさにより、単に現状の整理となってしまいました。今後は取得するデータの切り口を工夫してデータを増やし、例えばSpotifyのサービス対象外の国において好まれるであろう楽曲の提案といった、予測モデルなどを構築できればと思います。 -
今時点の人気楽曲を対象としたため、それが一過性のトレンドなのかが判別できない点
ブラジルでライブ音源がランキング入りしている点など、瞬間的な流行なのか長期的な嗜好なのかを判別するには、一時点の人気楽曲では不十分でした。長期間での人気楽曲を取得できれば、より明確な特性が浮かび上がるものと期待できます。
以上、お読みいただきありがとうございました。