はじめに
現在,stanを使ってモデリング,パラメータ推定を行っているのですが,Trae plotがつぶれて見ずらいので少し見やすくする方法があったので共有します.(知っている人にとっては当たり前かも...)
あと,もっと良い方法があったら教えてください.
環境
| OS | Windows10 |
| Python | 3.7.4 |
| PyStan | 2.19.1 |
早速...
stan_model_ver1.py
import arviz
import pandas as pd
data = pd.read_csv("~~.csv")
dat = {"辞書で定義"}
model = StanModel(file="~~.stan")
fit = model.sampling(data=dat, n_jobs=-1, seed=999, iter=1000,chains=1)
arviz.plot_trace(fit)
でこのようなものが描かれます.
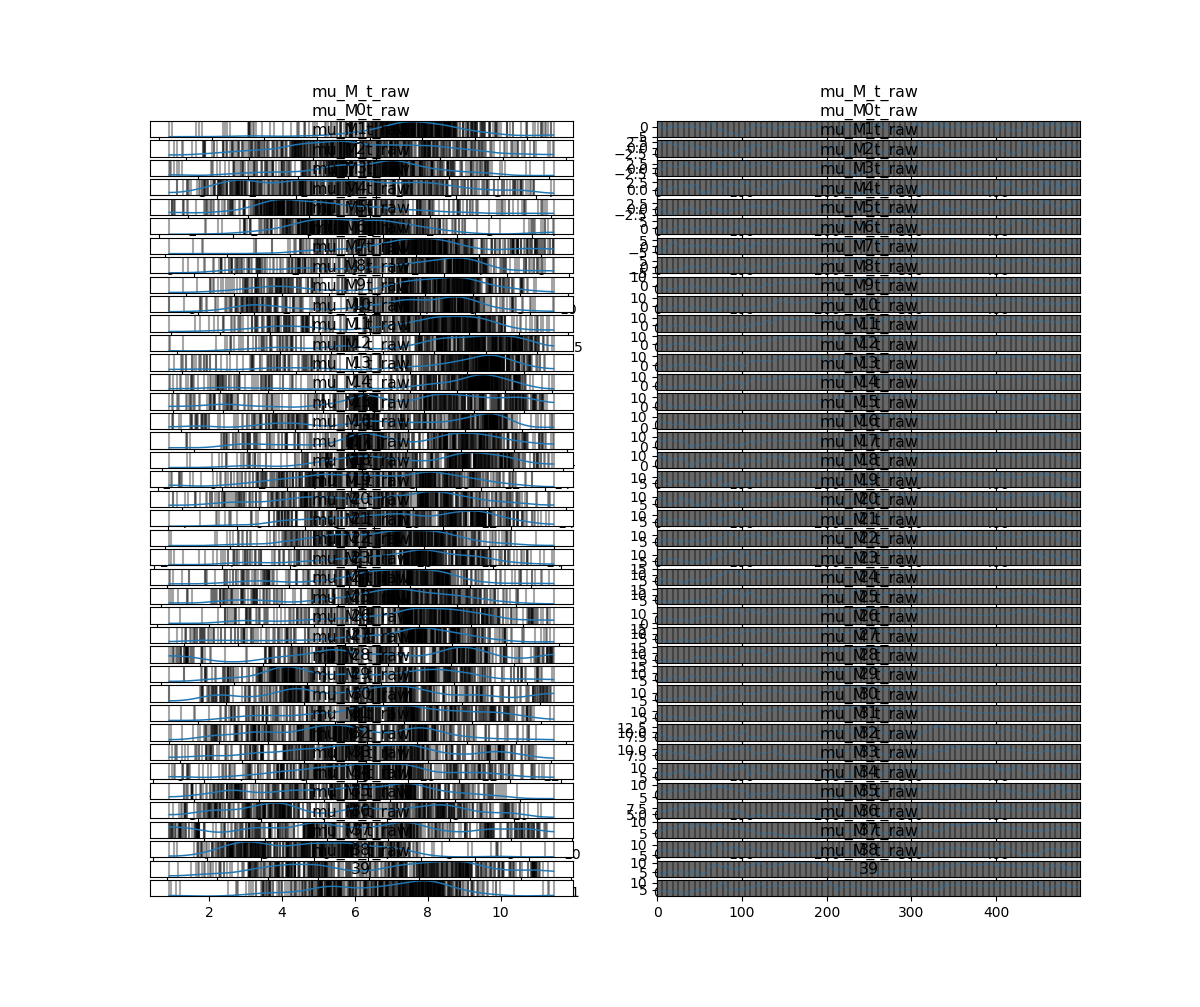
しかし,パラメータ数が多いと滅茶苦茶見づらいです...
そこで,
stan_model_ver2.py
import arviz
import pandas as pd
data = pd.read_csv("~~.csv")
dat = {"辞書で定義"}
model = StanModel(file="~~.stan")
fit = model.sampling(data=dat, n_jobs=-1, seed=999, iter=1000,chains=1)
'''====以下変更==='''
fit_df = fit.to_dataframe()
index = fit_df["draw"]
lenght = len(fit_df.keys())-7
for i in range(lenght):
ob = fit_df[fit_df.keys()[i+3]]
plt.subplots(figsize=(15, 7))
plt.title(f"{fit_df.keys()[i+3]}")
plt.subplot(1, 2, 1)
sns.distplot(ob)
plt.subplot(1, 2, 2)
plt.plot(index, ob)
plt.savefig(f"figure/stan_figure/{fit_df.keys()[i+3]}.png")
plt.show()
とします.
データフレーム化して,パラメータ1つずつ可視化することで,時間は少しかかりますが,
![Y[1,2].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F208370%2F5ce3c039-31cf-b964-c26e-20c90a489ec9.png?ixlib=rb-4.0.0&auto=format&gif-q=60&q=75&s=2b0163bb29beae89762ed8a97cf08b07)
このように各段に見やすくなります.
おまけ?
パラメータ数が多いとprint(fit.stansummary())をして各パラメータの収束状態を確認しようとしても,表示しきれないことがあるかもしれません.(特に時系列モデルを考えると)
そんな時は,
omake.py
summary_df = fit.stansummary()
file = open('summary_stan.txt', 'w')
string = summary_df
file.write(string)
このようにテキストファイルとして保存してしまえば見たいパラメータの状態を確認することができます.