Purpose & Motivation
Purpose
DNNモデルを性能を落とさずにできるだけ小さくしようというのがこの論文の目的です。
Motivation
Small DNN Architectureが必要になるSceneとして3つ考えられます。
-
分散学習
Server間におけるOverheadを小さくするため -
新しいModelを既存のNetworkにUpdate
自動運転Carなど既存の製品に新しいModelを取り込むときのOverheadを小さくするため -
FPGAなどのH/Wに実装する
H/W Resourceに限りがあるため(e.g. Xilinx Vertex-7 FPGA 最大8.5MB)
Strategy
Smaller DNNにするための3つの戦略
Strategy 1. 3x3 filterを1x1 filterにする
Parameterが1/9になる
Strategy 2. 3x3 filterのInput Channel数を減らす
Parameter数は$(input channel数)\times(filter数)\times3\times3$なので、input chennel数が1つ減るだけでParameter数が$(filter数)]times9$減る。
Strategy 3. Downsamplingは後ろの方でする
Activation mapサイズは、入力のサイズとDownsamplingの仕方によって決まります。
入力に近い場所でDownsamplingすると、ほとんどのLayerのActivation mapのサイズが小さくなります。
逆に、Downsamplingを後ろの方でする、ほとんどのLayerのActivation mapのサイズが大きくなります。
Downsamplingを遅らせて、大きいActivation mapの方がClassification精度が高い傾向にあります。
Strategy 1、Strategy 2はParameter数を減らすための戦略で、Strategy 3は、精度を保つための戦略です。
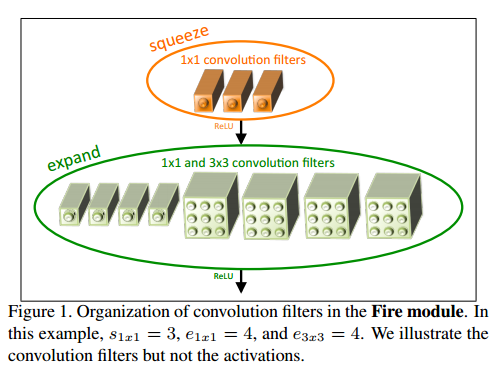
Fire Module
下図のFire ModuleをConvolutional Layerの代わりに使います。
この構造は、Strategy 1, 2から来ています。
Strategy 1よりParamter数を減らすために1x1フィルタを使っています。
次にStrategy 2より、入力Channel数が減るように、最初に1x1フィルタ通しています。
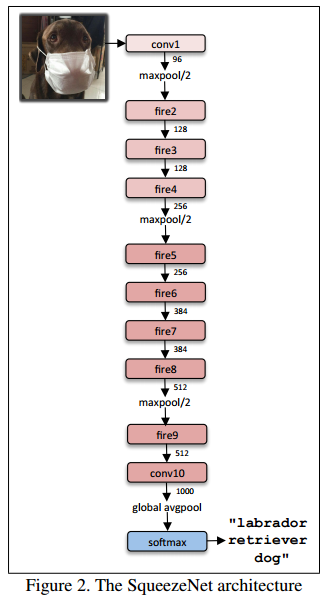
SqueezeNet architecture
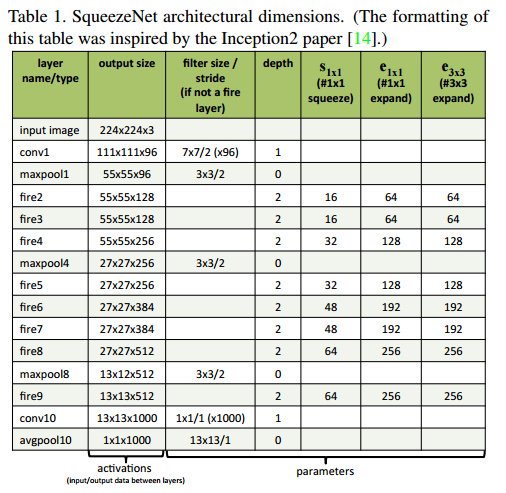
SqueezeNetの構造は、以下の通りです。最初と最後にConvolutional layer(conv1, conv10)、その間のLayerはfire module(fire2-9)になっています。Strategy 3より、max-poolingは、conv1, fire4, fire8, conv10の後に入っています。
その他は以下の通り
・出力サイズが同じになるように3x3filterはzero paddingする
・SqueezeとExpandの間にReLUを入れる
・Dropout 50%
・詳細はGithub参照
Evaluation
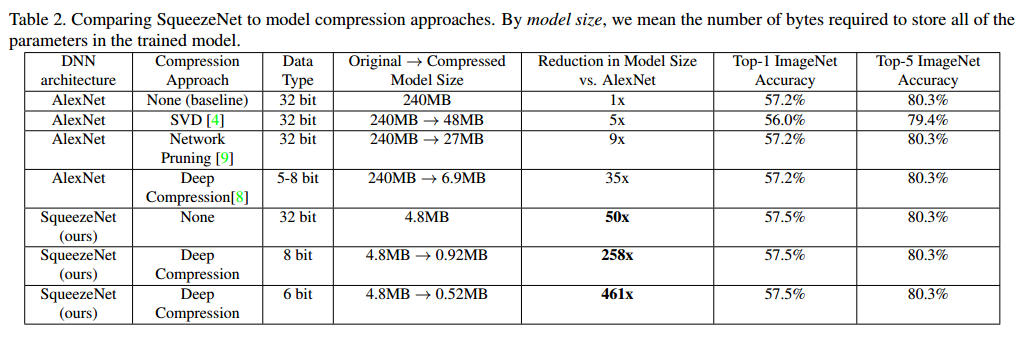
Data typeが32bit で1/50、Data typeを6bitにすると1/461で性能はほとんど変わっていない。
最後に
結局は、1x1を二股に分けて1x1と3x3に通して結合したということのようです。
それを一つのモジュール(fire module)と言っているようです。
こんなに減らしても性能が保たれているということは、解こうとしている問題に対してもともとの性能がOverspecということでしょうか?
1bitというのがあるくらいなので、このくらいは大丈夫ということなのかもしれないです。
ensembleにしたり、distributedにしたりするにはparameter数は少ない方がいいですね。