Identity Mappings in Deep Residual Networks
この論文は、ResNetのidentity mapping(skip connection)に関して、詳細は解析を行ったものです。
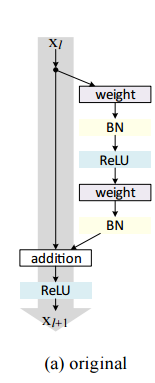
ResNetにおける重要な特徴は、残差$F$を学習することによって、100 layerを超えるdeepなNetworkでも安定した学習が行えるようにした点にあります。またResNetは、モジュール構造になっており、モジュールを単純に組み上げて行くことでDeepなArchitectureを実現しています。論文ではこのモジュールをResidual Unitsと呼んでいます。
Residual Unitsを図で示すと下記になります。
式で示したものが下記です。
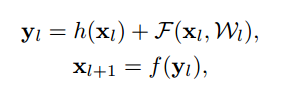
ここで、$F$は残差を表すResidual Functionです。Residual Unitsの出力は、Unitの入力$x_l$をfunction hに通した値$h(x_l$)と残差$\cal F(\mathbb x_l, W_l)$の和をactivation function $f$に通したものになっています。
この論文では、残差のPathを構成しているBatch Normalization(BN)やReLUの順番を変えたり、入力$x_l$のPathを変えたりしながら性能評価を行い、identity mappingの利点や、最適な構成を探っています。本論文の成果としては、従来はweight乗算の後でBNを行っていましたが、これを残差のPathの最初に持って行くことでResNetの場合は性能がUpするということを示したことにあります。
Analysis of Deep Residual Networks
Residual Unitsの式は下記の通りです。
$x_l$はl 番目のResidual Unitsの入力です。$\cal W_l=\{W_{l,k}|_{1 \le k \le K}\}$はweightです。
ここでfunction hを$x_{l+1}$ を $h(x_l) = x_l$ とおいたものをidentity mappingといいます。
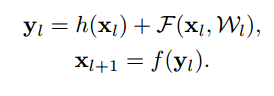
$h(x_l)=x_l$と置き換えると、下記のようになります。
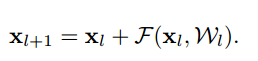
更に、再帰的になっている部分を展開する下記のようになり、$x_L$は$x_l$と残差に関する項$\sum _{i=l}^{L-1} F$の和で表現されます。
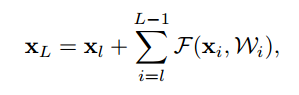
通常のネットワーク構造の場合は、$x_0$に重みをどんどんかけていく構造($\prod _{i=0}^{L-1} W_ix_0$)になります。
さらにloss function $\cal E$の勾配は、下記のようになります。勾配はBack propagationに使用します。
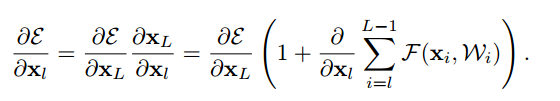
勾配は、$\frac{\partial \cal E}{\partial x_L}$と$\frac{\partial \cal E}{\partial x_L}(\frac{\partial}{\partial x_l}\sum _{i=l}^{L-1} F)$に分解されます。
この形は学習の時に問題となる勾配の消失が起こりづらい形になっています。
勾配が0になるには、$\frac{\partial}{\partial x_l}\sum _{i=l}^{L-1} F$が$-1$にならなければならないからです。
On the Importance of Identity Skip Connections
$h(x_l)=\lambda_lx_l$とした場合
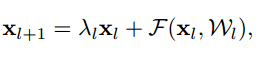
上記式を展開していくと下記のようになります。
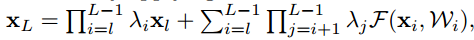
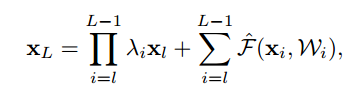
$\cal \hat F$は$\prod$以降の部分を置き換えたものです。
さらに勾配は下記のようになります。
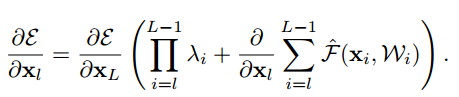
もし仮にすべてのiにおいて$\lambda_i > 1$ならば、$\prod_{i=l}^{L-1} \lambda_i$が指数的に大きくなります。
逆にすべてのiにおいて$\lambda_i < 1$ならば、$\prod_{i=l}^{L-1} \lambda_i$は指数的に小さくなります。
後の実験でもこのような構造は最適化が難しいことが示されています。
Experiments on Skip Connections
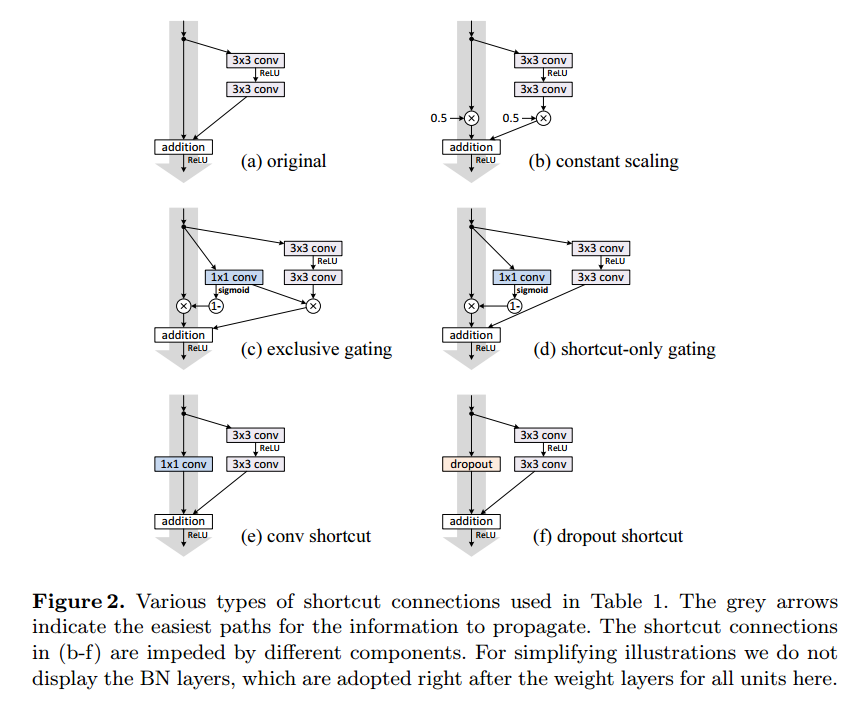
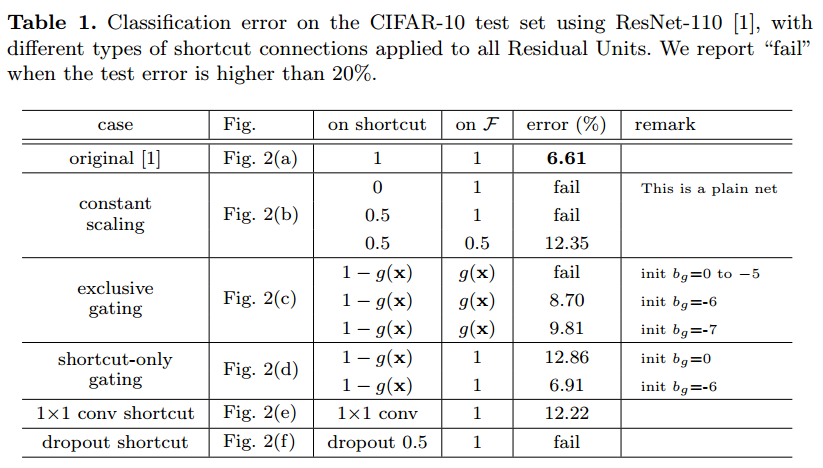
上記6つの構成で実験を行った結果が下記になります。
(b)Constant Scaling
Constant Scalingは2つのPathを$\lambda$および$1-\lambda$でScalingしたものになります。
このタイプは学習の収束が難しく、成功した場合でも性能がかなり悪くなっています。(Table 1, 12.35%)
(c)Exclusive gating
Exclusive gatingでは、gating function $g(x)=\sigma(W_gx+b_g)$で入力と残差の加算を制御しています。
また加算する場合は各値にかける重みの和が1になるようにしています。
この構造の場合にbias $b_g$の初期値が重要になります。そのためcross validationによってbiasの初期値を決めています。結果としてはbiasは−6がbestな値でしたが、性能はもともとのResNetより悪くなっています。
(d)Shortcut-only gating
Shortcut-only gatingもgating functionにより制御していますが、制御は入力のみになっています。そのため入力と残差にかけられる重みの和は1になりません。こちらも同様にbiasの初期値が重要になります。biasの初期値が-6の時は、$1-g(x)$の値が1に近くなり、identity mappingに近づくため元々のResNetの性能と近い値になっています。
(e) 1x1 convolutional shortcut
1x1 convolutional shortcutは、入力のPathに1x1 convolutionを入れたものです。この構成は先の論文に記載されているもので、34-layerのResNetで、良い性能が出ていました。構成をよりDeepにすると性能が12.22%と悪くなっています。
1x1 convolutional shortcutはparameterが増えてnetwork自体の表現能力が高くなっていますが、逆にoptimizationが難しくなっているためのようです。
(f) Dropout shortcut
Dropout shortcutは入力の接続を確率的にon/offするものです。(DropConnectと言ったほうがいい?)
Dropoutの確率は0.5にしています。これは結局Scale $\lambda$の期待値を0.5にしたのと同じことになるので、学習は収束しませんでした。
On the Usage of Activation Functions
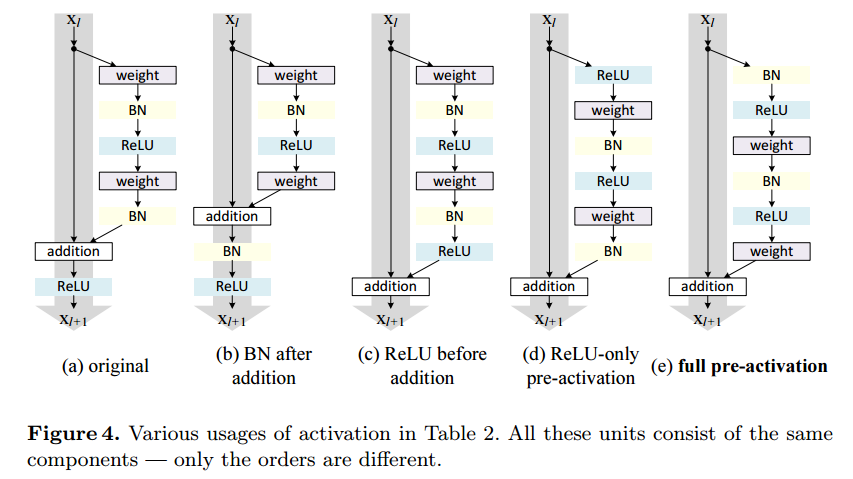
ここでは、各Pathの構成を変えて比較実験を行っています。
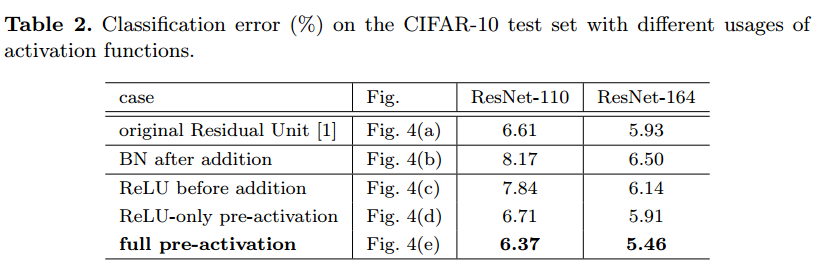
性能は下記の通りです。
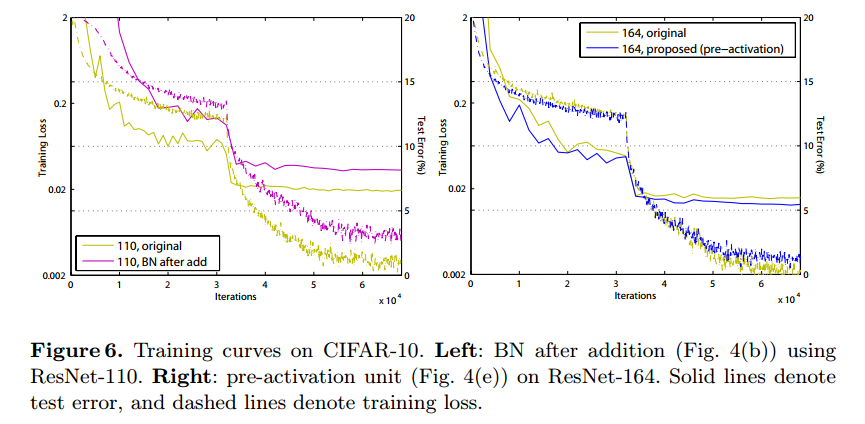
BN after addition
残差のPathの最後にあったBNを加算後に持ってきたものです。もともとのResNetより性能が劣化しています。
ReLU before addition
加算後にあったReLUを残差のPathの最後に持ってきたものです。こちらも性能が悪くなっています。残差Pathの最後にReLUを入れると残差がプラスの値しか取らなくなるためのようです。
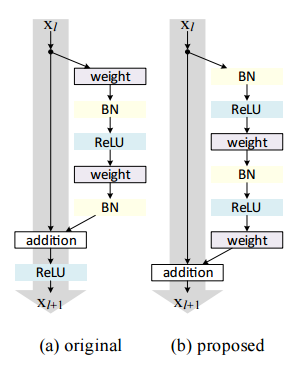
Post-activation or pre-activation
こちらは、通常最後に入っているReLUの出力は、次のResidual Unitsの入力のPathと残差のPathに伝播します。これを片側だけ(asymmetric)にしたものです。
論文では、出力を次のResidual Unitsに伝えるときに片側にReLUを入れるのと(post-activation)、入力Pathと残差Pathにわかれた後に残差Pathの先頭にReLUを入れる(pre-activation)のは同じだから、その差は気にしないと書いてあります。
その説明が下の図です。
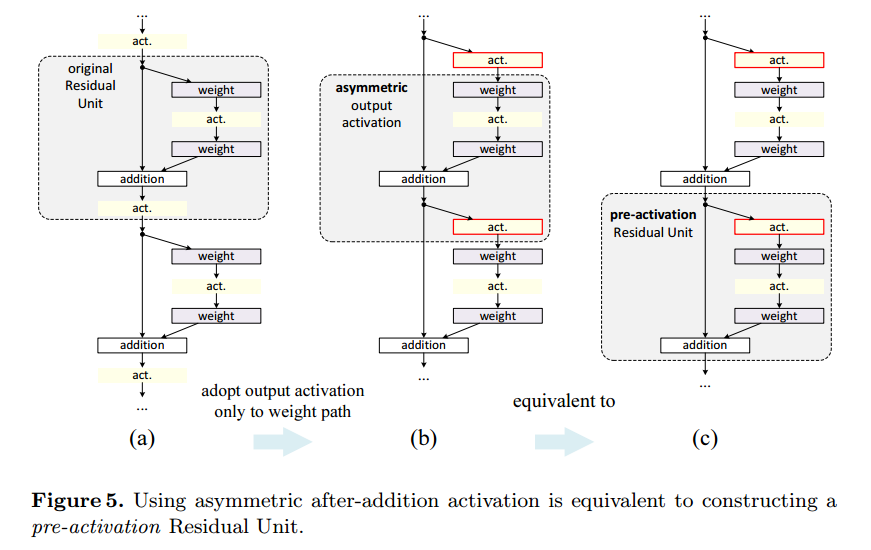
full pre-activation
pre-activationの最初にBNを入れて、残差Pathの最後のBNをやめたものです。
この構成が一番性能がよく、さらにもともとのResNetよりも良くなっています。
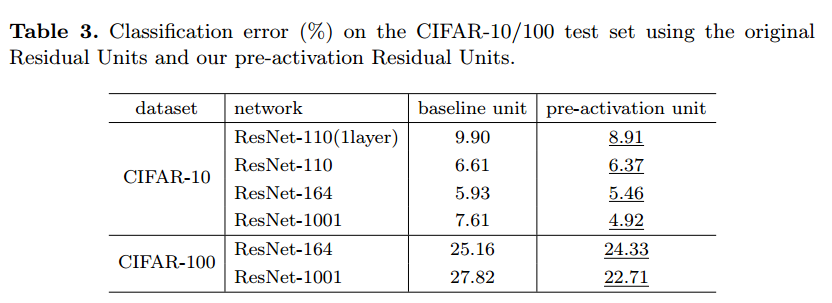
Analysis
pre-activationの解析です。
Ease of optimization
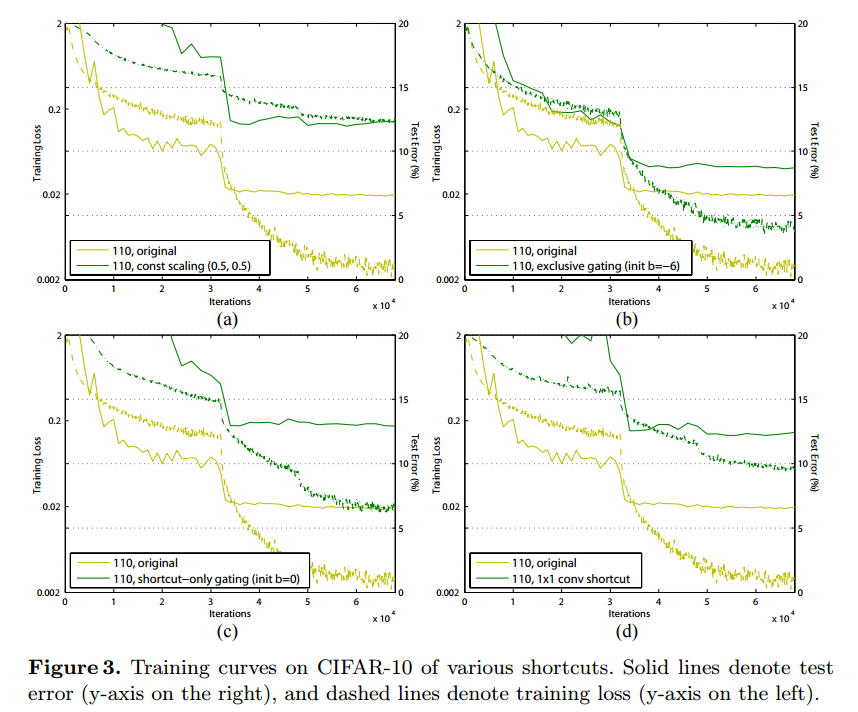
full pre-activationともともとのResNetの比較を行っています。
BNとReLUを入れることで、学習の収束が速くなっています。黄色が従来、青がpre-activationです。
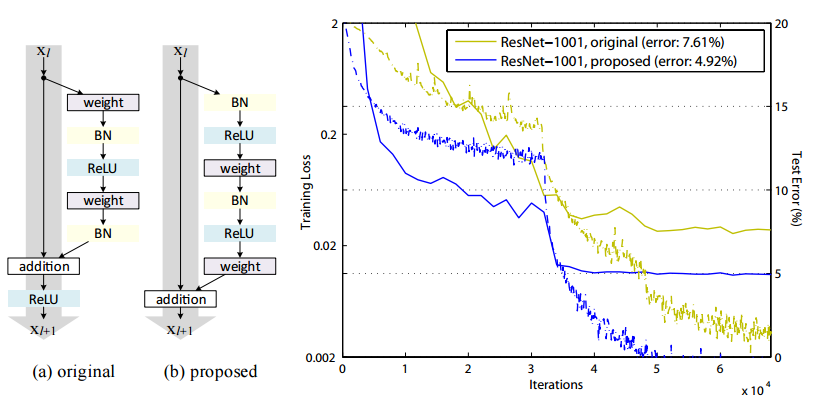
Reducing overfitting
training loss がtest lossに比べて高くなっています。下のグラフの右側。これはResNet-110, ResNet-164でも観測されています。
これは多分Batch Normalizationの影響と思われるということだそうです。
pre-activationの場合は最初に入っているので、Normalizationされたものが残差Pathの入力となります。
従来の場合は残差の最後にNormalizationが入っていて、そのあとに入力のPathと加算されるので、Normalizationされていないものが残差の入力となっています。
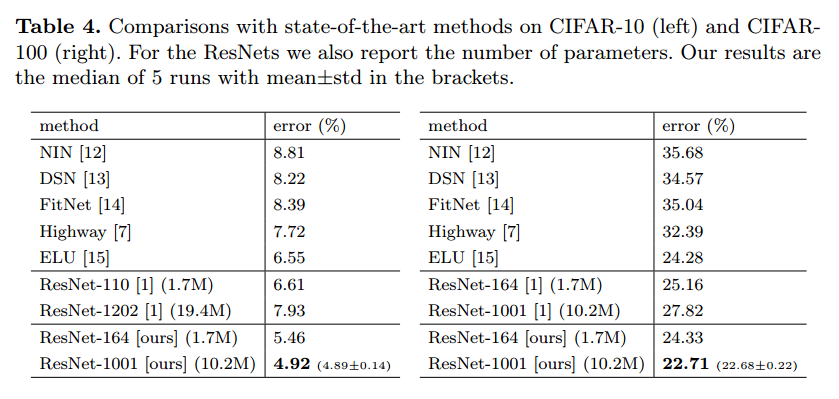
CIFAR-10/100での比較結果
ImageNetでの比較結果
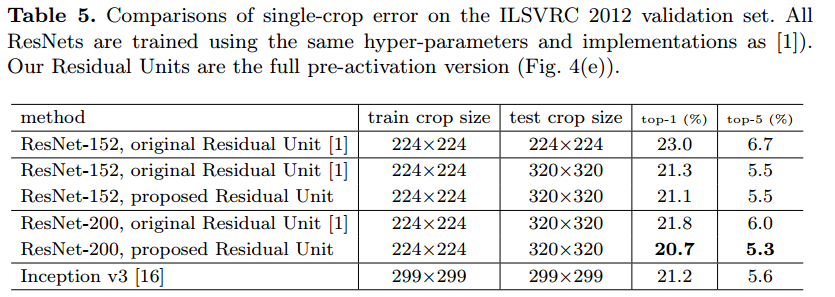
実験Parameterに関しては論文に書いてあるとおりです。
結論としてはResNet-200 + pre-activationが一番性能が良いです。
感想
ResNetの著者がidentity mappingに関して考察したものです。結局入力のPathはCleanに保ちつつ、残差Pathの先頭にBNを入れて入力Rangeを保つのがいいようです。性能を良くしようと複雑なことをすると、ネットワーク自体の表現能力はあがりますが、最適化がむずかしくなるというトレードオフがあるので、とくに入力Pathには余計なことはしないのがいいということでしょうか?