Adamはすでに、chainerやtensorflowに実装されているStochastic Optimizationの一種です。
Stochastic Gradient Descent(SGD)が固定Learning Rateなのに対し、Adamは、Adaptive Learning Rateな手法、すなわちLearning Rateを何らかの情報から適切にコントロールして学習効率を向上させようというものです。
Adamの特徴は下記の通りです。
・低次元モーメントに基づく適応的な推定処理
・単純に実装できる
・計算コストも低い
・省メモリ
・勾配の大きさに影響されない
Algorithm
Algorithmは非常に単純です。
勾配を$g_t$、最適化したい重みを$\theta$とすると勾配は下記のようになります。
\begin{eqnarray*}
g_t &=& \nabla_{\theta}f_t(\theta_t-1)
\end{eqnarray*}
Adamでは、勾配の1次モーメント(平均)$m_t$と2次モーメント(平均が0の時の分散)$v_t$を使用します。
Exponential moving averageで$m_t$と$v_t$を計算します。
\begin{eqnarray*}
m_t &=& \beta_1 m_{t-1}+(1-\beta_1)g_t\\
v_t &=& \beta_2 v_{t-1}+(1-\beta_2)g^2_t
\end{eqnarray*}
ここで、$m_t$と$v_t$の初期値が0なので、推定したモーメントが0方向に引っ張られてしまうという問題があります。
なので、バイアスを補正する処理をします。
論文では、$\beta_1=0.9$、$\beta_2=0.999$と1に近い値が使われています。
下記の式は、$t$が小さい時は、小さい値で割られるので値が大きくなり、$t$が大きくなると$1$に近い値で割られるので、Moving Averageがそのまま使われる感じになっています。
\begin{eqnarray*}
\hat{m}_t &=& \frac{m_t}{1-\beta^t_1}\\
\hat{v}_t &=& \frac{v_t}{1-\beta^t_2}
\end{eqnarray*}
最終的にパラメータの更新式は下記のようになります。イメージとしては、勾配の期待値を勾配の分散の期待値で正規化した値を更新量とするという感じでしょうか。これにより勾配が大きいところでは更新量が勾配の期待値からさらに小さくなり、勾配が小さいところでは更新量が勾配の期待値に近い値かまたは大きい値になります。
\theta_{t}=\theta_{t-1}-\alpha\frac{\hat{m_t}}{\sqrt{\hat{v_t}}+\epsilon}
論文で参考にしているAdaGradとRMSPropについても簡単に紹介します。
AdaGrad
AdaGradのコンセプトは、Adamと同じで、Adaptive Learning Rateで、一定期間の勾配の大きさの積算値で正規化を行います。
式は下記のようになります。期間内の勾配の積算値になっているので、勾配の出現頻度が少ない時には、頻度が大きい時に比べて分母が小さくなるので、Learning Rateが大きくなります。
\theta_{t+1} = \theta_{t} - \alpha\frac{g_t}{\sqrt{\sum^t_{i=1}g^2_t}}
RMSProp
RMSPropは、論文はなくてHinton先生の講義に出てくるそうです。コンセプトは、Outlierに引っ張られないように重み平均をした値でLearning Rateを決めるというやり方のようです。なので勾配にかける重みは$0.1$になっています。
式は下記のようになります。
\begin{eqnarray*}
MeanSquare(g_t)&=&0.9MeanSquare(g_{t-1})+0.1g^2_t\\
\theta_{t+1} &=& \theta_{t} - \alpha\frac{g_t}{\sqrt{MeanSquare(g_t)}+\epsilon}
\end{eqnarray*}
Alec Radfordさんと言う人がOptimizationの比較アニメーションを作っています。各アルゴリズムの動きがとてもわかり易いです。
この人はDCGANの論文の人です。
Beal's Functionの場合
各アルゴリズムの収束速度と収束までのパスを見ると、MomentumとNAGは初期勾配が大きいために、一旦全然違う方に行って戻ってきています。AdaGradは、最後に突然不安定になっています。これも同じ理由とリンク先にコメントで書かれているのですが、理由がいまいち理解できないです。単純な積算値だからということでしょうか?

Long Valleyの場合
これを見るとSGDは、局所解(Saddle Point)に収束しているのがわかります。Momentumは行ったり来たりしますが、止まりそうになってから持ち直しています。これはおそらく前の更新量が勾配よりも小さくなったので、持ち直せたのかなと思います。

Experiments
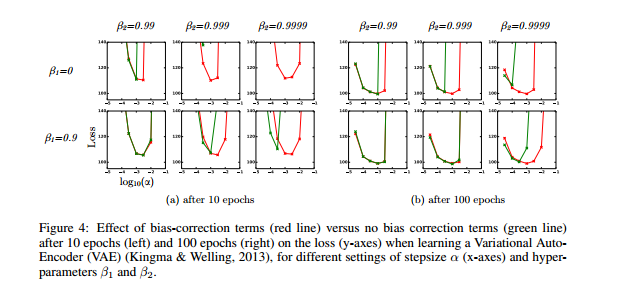
左がおなじみMNISTの結果です。
Adam,SGD+Nesterov momentum,AdaGradで比較しています。Adamが一番収束が速いのがわかります。
右はIMDB Movie Review Datasetでの結果です。
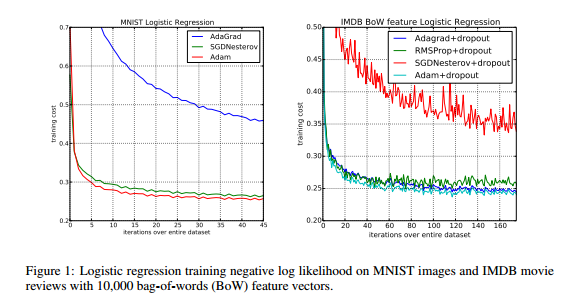
こちらはMulti Layerの時の結果です。
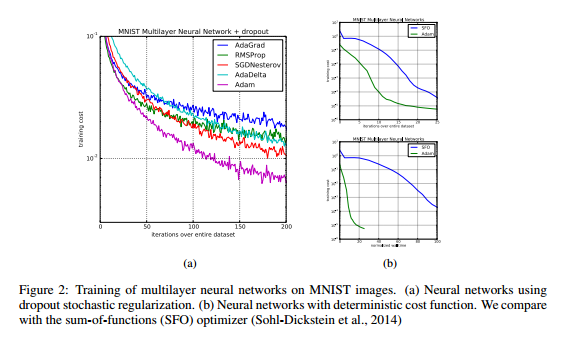
これはCNNでの結果です。
論文によるとCNNでは、2次モーメントの推定値が数epoch後に0になって、安定化用の$\epsilon$だけの状態になったとのことです。
なので、2次モーメントの推定精度は、最初の実験のfully connected networkに比べてCNNの方が悪い(poor approximation to the geometry)と言っています。しかしAdamの場合は1次モーメントの推定値があるので、こちらのほうが収束速度に効果があったため、AdaGradにくらべてAdamの収束が速かったようです。
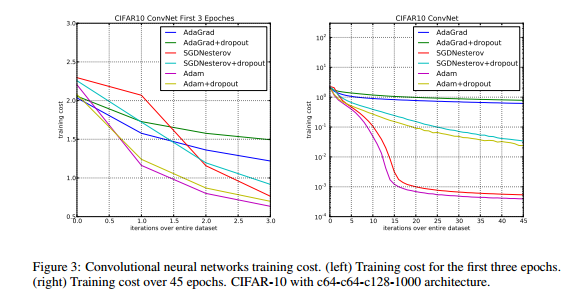
こちらはBias Correctionの効果の評価です。
赤がBias Correctionあり、緑がBias Correctionなしです。これを見ると、Bias Correctionなしの結果が特に数10Epochの時に不安定になっているのがわかります。(左側のグラフ)