何も知らないで使うよりは、少しでも知っていたほうがいいだろうということで、
Batch Normalizationの論文を読んでみました。
Batch Normalization
この論文は、データの新しい変換方法の提案論文です。
著者はBatch Normalizationと読んでいる。著者いわく、バッチ毎のデータの分布の違い(internal covariate shift)により、学習の収束がおそくなったり、初期値パラメータを慎重に決めなければならなかったと言っています。Batch Normalizationを導入することにより以下の利点があるそうです。
利点
・学習が早く進む(learning rateに大きな値を使うことができる)
・初期値依存性を軽減できる
・初期化を気にしなくて良い
・Dropoutの必要性を減らせる
Algorithm
バッチごとに平均が0、分散が1になるように正規化を行う。この際、Normalizationは、各Featureごとに行う。すなわち、データのFeatureが10だった場合、平均と分散をそれぞれ10ずつ計算して、正規化を行う。εは安定化のための係数である。Batch Normalizationは各層の入力で行われる。
γ及びβはパラメータでそれぞれ正規化された値をScaling及びShiftするためのものである。

テスト時は、平均と分散の計算は行わず、学習時に計算されたものを使用する。
Gradient
Batch Normalizationは各層の入力で行われるので、Back PropagationのためのGradientの計算が必要になる。実際、各PlatformではBatch Normalizationがサポートされているので、自ら計算することは無いと思われる。
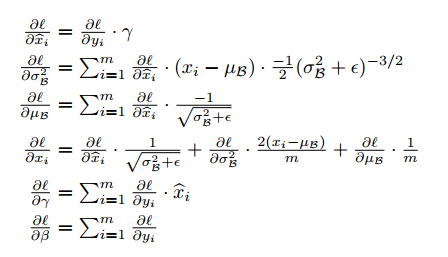
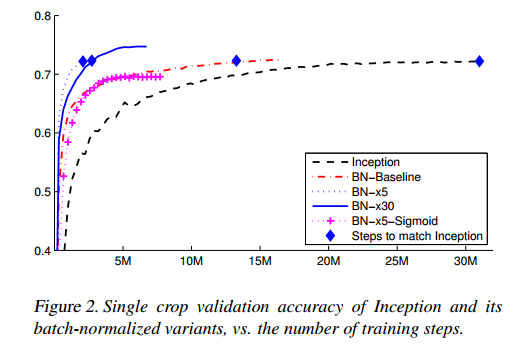
Experiments
横軸Step回数、縦軸は精度
LSVRC2012のデータ・セット使用して評価
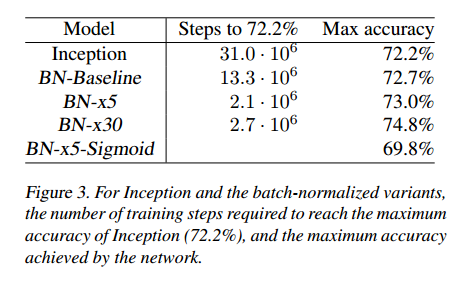
Batch Normalizationを使用することで、学習が早く収束することが下のグラフ及び表からわかる。
Platform
Chainerでは、「chainer.links.BatchNormalization」とか「chainer.functions.batch_normalization」とかでさくっと使えそうです。
Tensorflowは、「tf.nn.batch_norm_with_global_normalization」を使うようですが、なぜかAPIのDocumentには載っていないです。
Stackoverflowのここに使い方が書いてあります。コピペで動きますが、Chainerの手軽さに比べると少し萎えます。
ただ、コードを見ると、beta,gammaはパラメータ(というか固定ですが)みたいとか、平均、分散はmomentsを使って、Featureごとに計算するとか、計算した平均、分散は、Exponential Moving Averageするとか、中で何をやっているか知ることができます。
最後に
入力データに対して、平均を0,分散を1にする処理は前からありますが、batch毎及び各層で行って分布を揃えるというのがいいのかなと思います。
英語で頭が痛くなりました。間違っていないといいのですが。