App Serviceを使っていて何か問題が起きたとき、どうやって調査していますか?アプリケーションログを見る、App Insightsを使う、Failed Request Tracing (FREB) logを見る、Kuduを使うなどが主な方法だと思います。本稿では、これらの各種ログを自動で一括して走査し、原因を推定するシステム App Service Diagnostics を紹介します。
背景
もともとは我々開発チームが自分たちでの問題調査用に作ったツールだったのですが、App Service のサポートチームでもそのようなツールが切望されていたことが分かり、サポートチームからのフィードバックを受けながら改善していきました。今ではサポートチームが調査の始めに使うツールとして定着しています。これをさらに発展させ、ユーザ自身にも使ってもらえるようにポータル上にユーザインタフェースを作ったものが App Service Diagnostics です。
使い方
ポータルにログインし、調べたい Web App を開きます。左側のメニューの「問題の診断と解決」をクリックすると App Service Diagnostics が開きます。
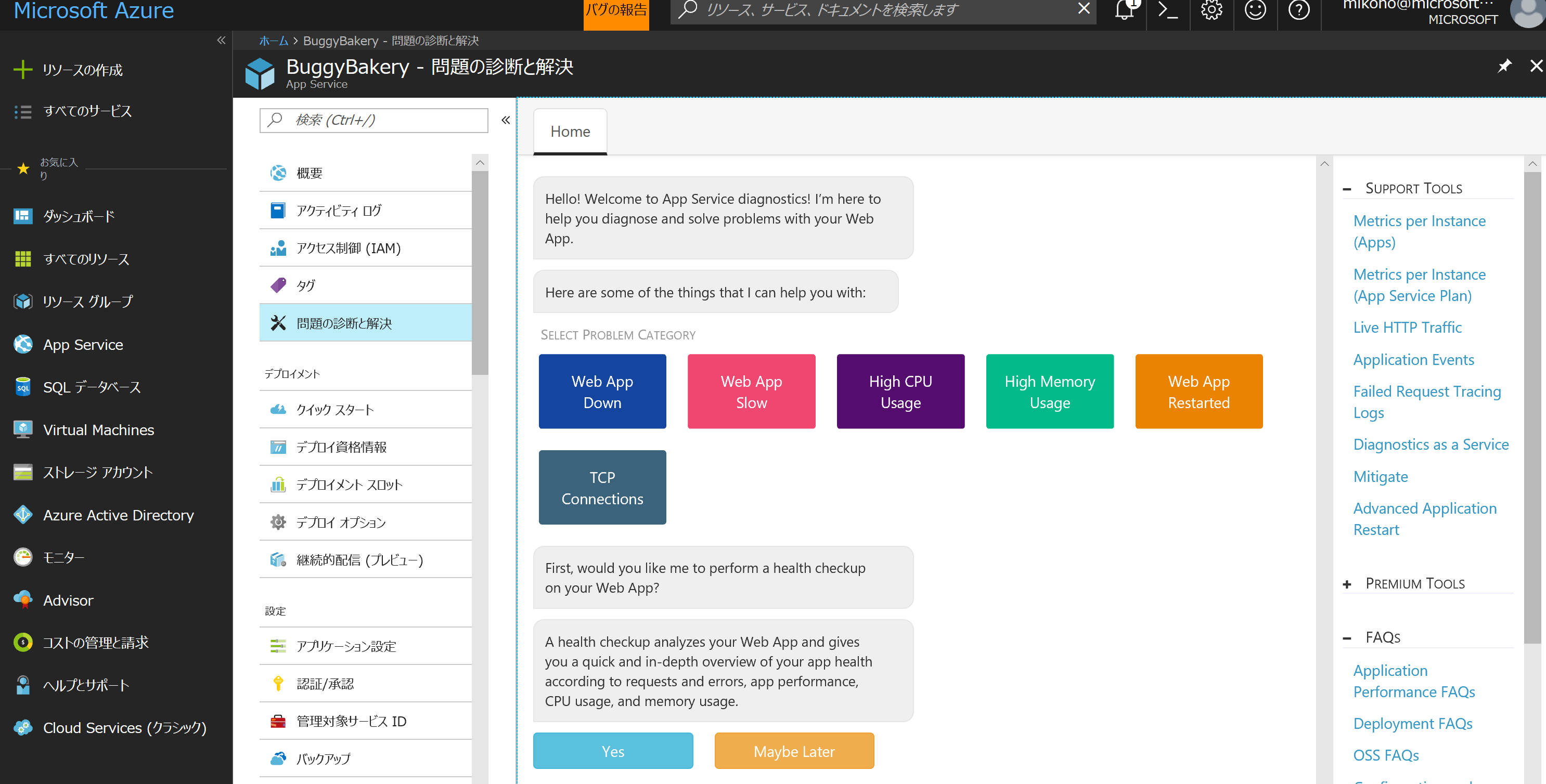
現状英語のみの対応ですが、難しい文章ではないです。右側中央にはカラフルなボタンが並んでいます。もし自分が調べたい問題の大まかな区分が分かっている場合は、この中のボタンをどれか押してください。分からない場合は下の方の水色の Yes ボタンを押せば、いろいろな問題について一通り調べ、根本原因の可能性の高い順に表示してくれます。
一応中央のボタン群について簡単に説明しておきます。
- Web App Down 過去のサイトダウンの原因を知りたい
- Web App Slow レスポンスタイムが遅い原因を知りたい
- High CPU Usage CPU 使用率が高い問題を調査したい
- High Memory Usage メモリ使用量が高い問題を調査したい
- Web App Restarted サイト(w3wpやコンテナ)の再起動の理由を知りたい
- TCP Connection ソケットの使用量が多い問題を調べたい
今後も増えていく予定です。また Web App on Linux/Container では表示が変わります(後述)。
自動診断
ともあれ、とりあえず Yes ボタンを押してみましょう。
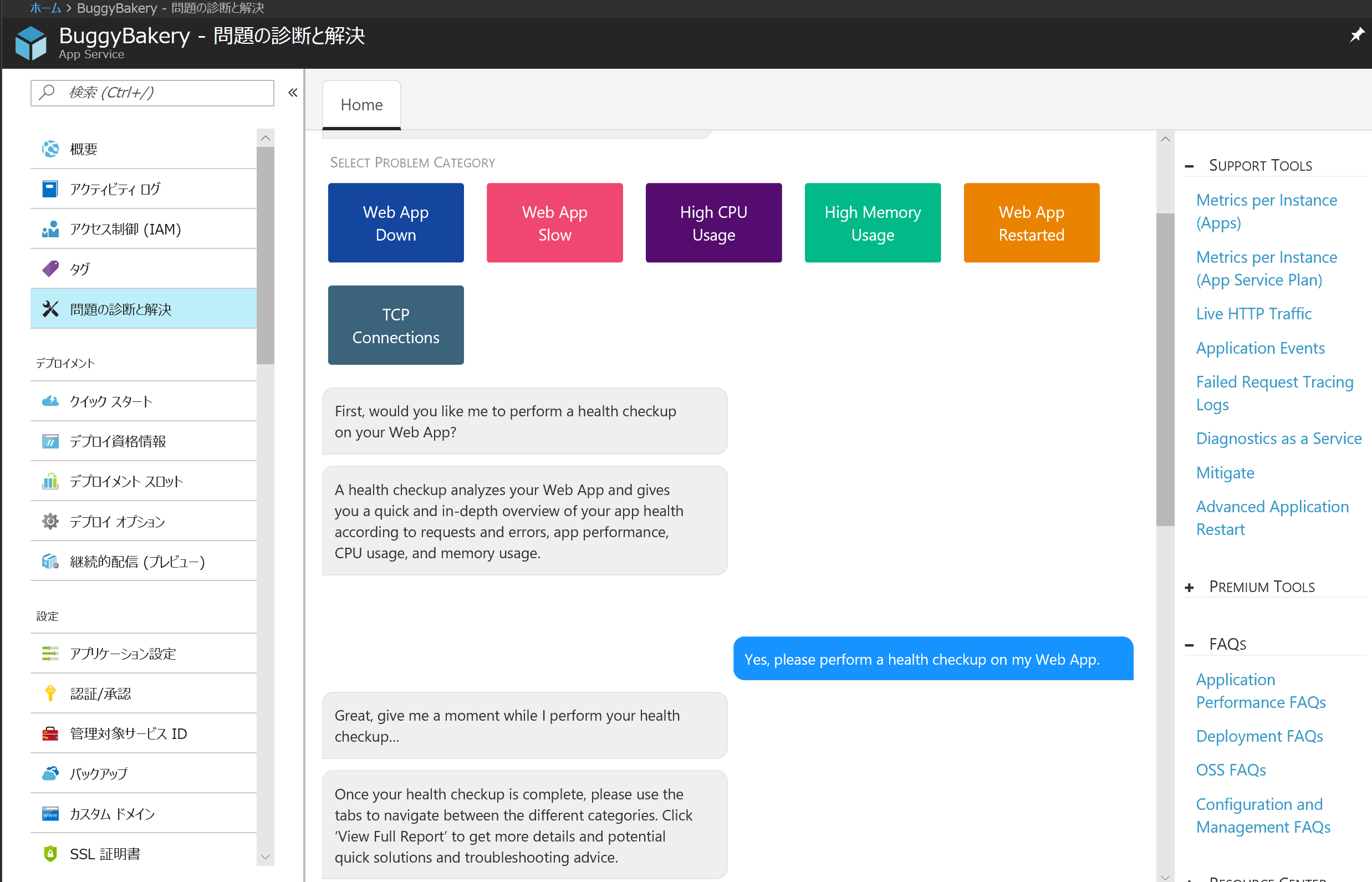
ChatBot 風のユーザインタフェースと共に自動診断がスタートします。
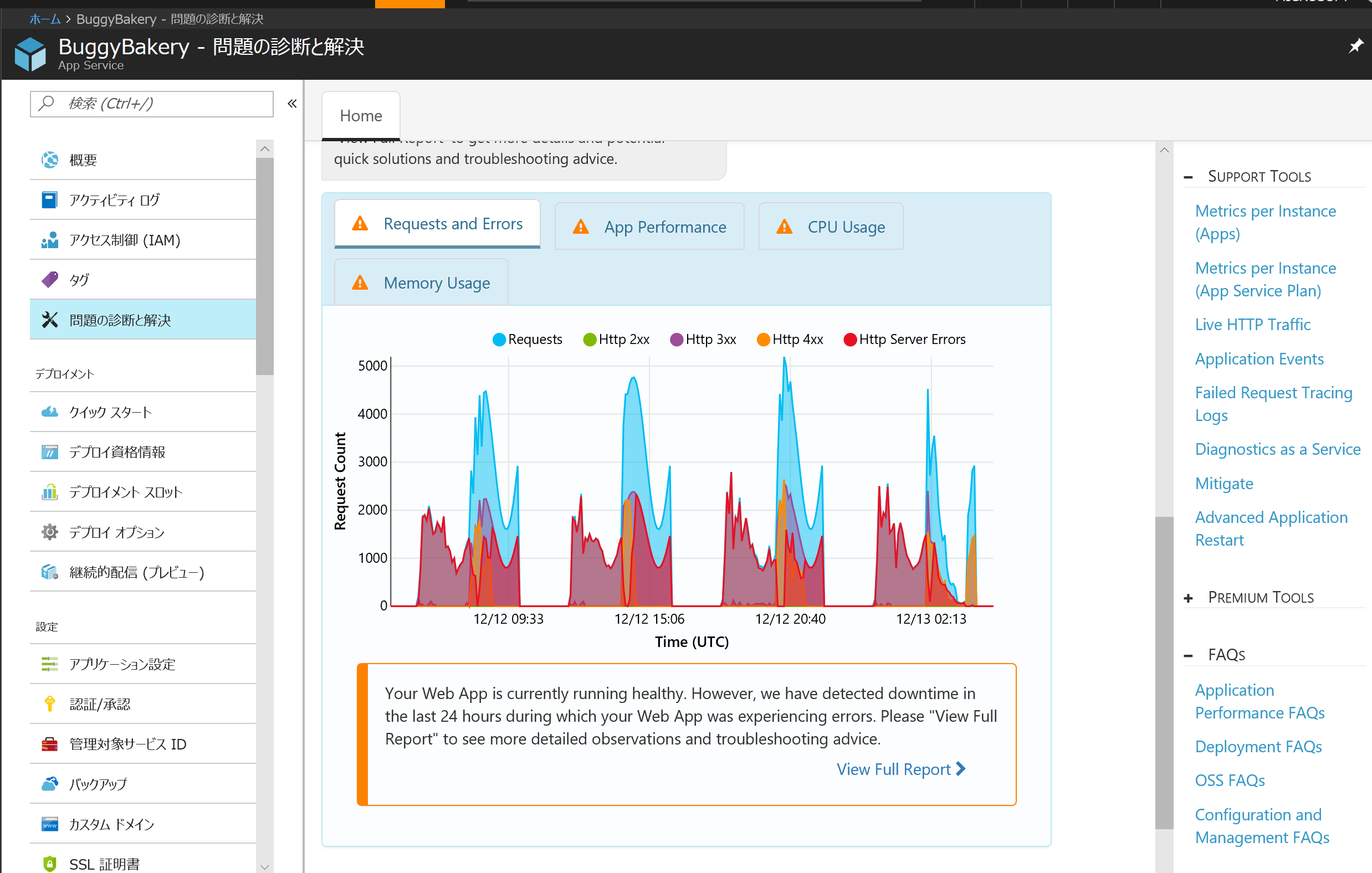
だいたい 10 秒程度で診断は終了し、グラフと発見した問題点が提示されます。どうやらこのサイトはいろいろ問題がありそうです。黄色の三角マークのタブをクリックすることで、発見した問題に特化したグラフを見ることができます。
各問題の詳細な報告は View Full Report> をクリックすることで見られます。
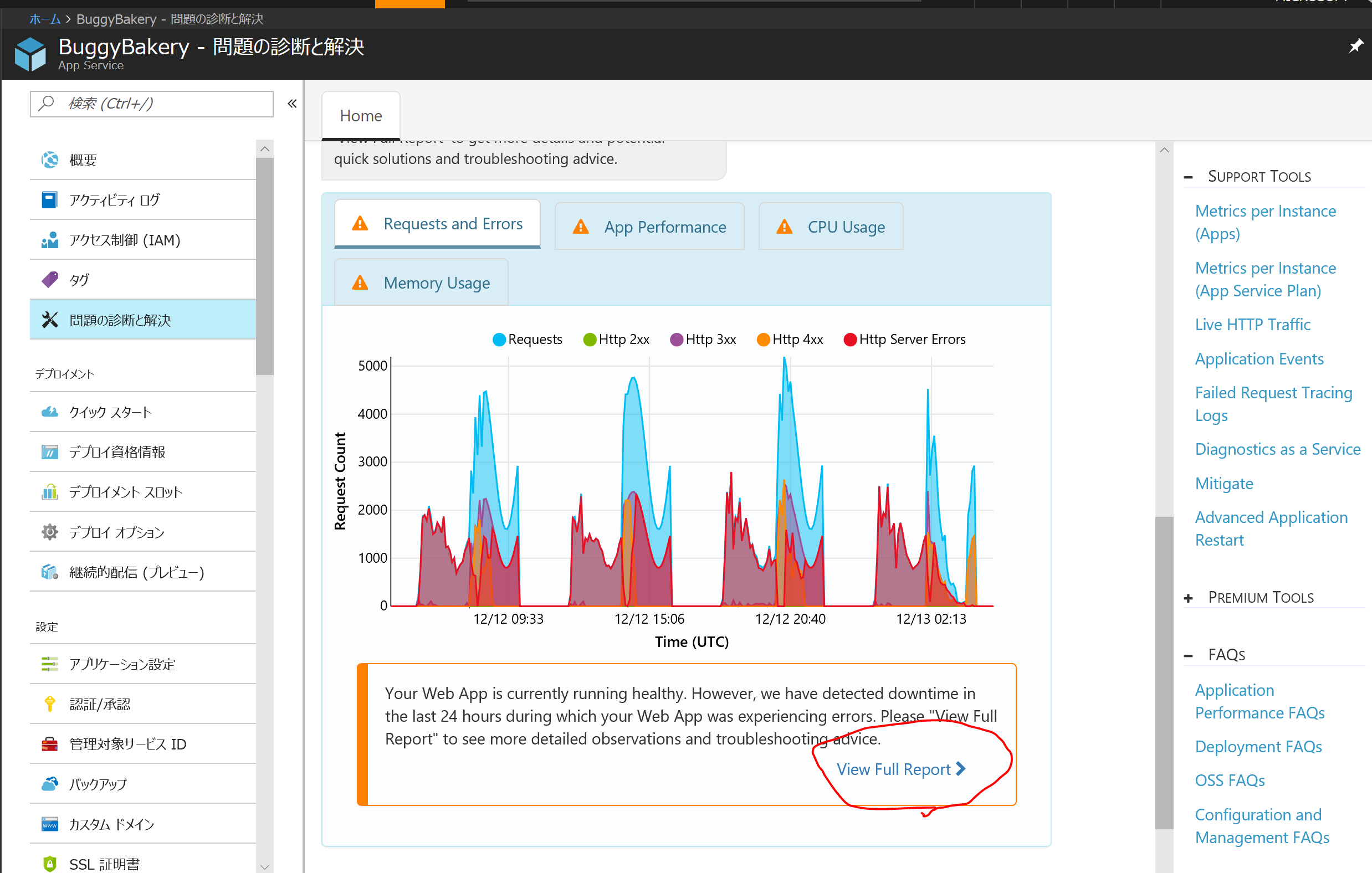
クリックすると画面が切り替わります。
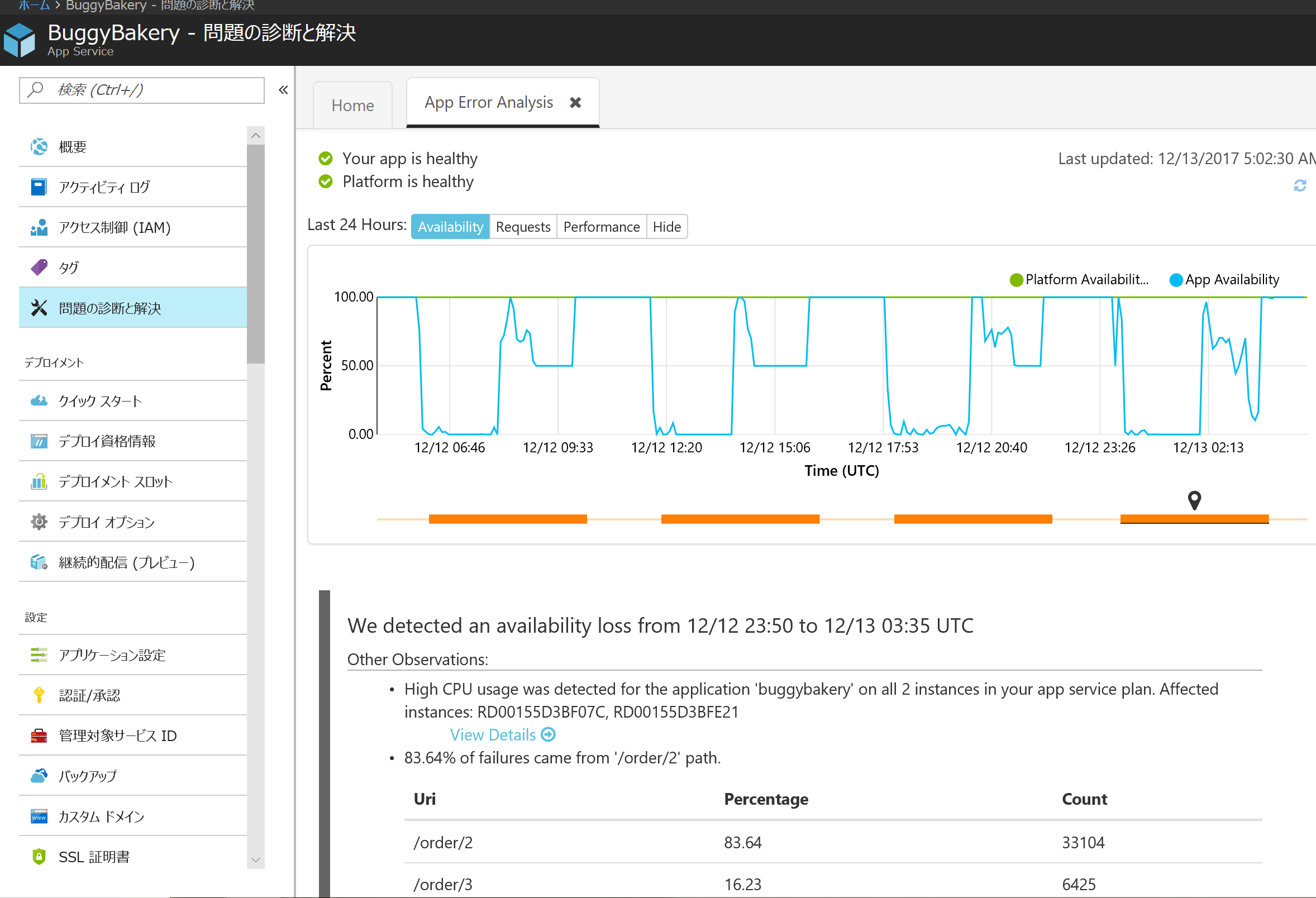
上部のグラフには青色と緑色の2本の線があります。緑色の線はプラットフォーム側の可用性で、ここが 100% の場合、プラットフォーム側は正常に動作しています。 一方青色の線はアプリがクライアントに正常に返答したレスポンスの割合です。この図では緑色の線はずっと 100% に張り付いており、青色の線だけが上下しています。つまりアプリに問題があることを示しています。
画面下部にはさらに踏み込んで、どのインスタンスで CPU 使用率が高かったか、どの URL パスからのエラーが多かったのかを示しています。
さらに下にスクロールすると、解決策を提案してくれます。
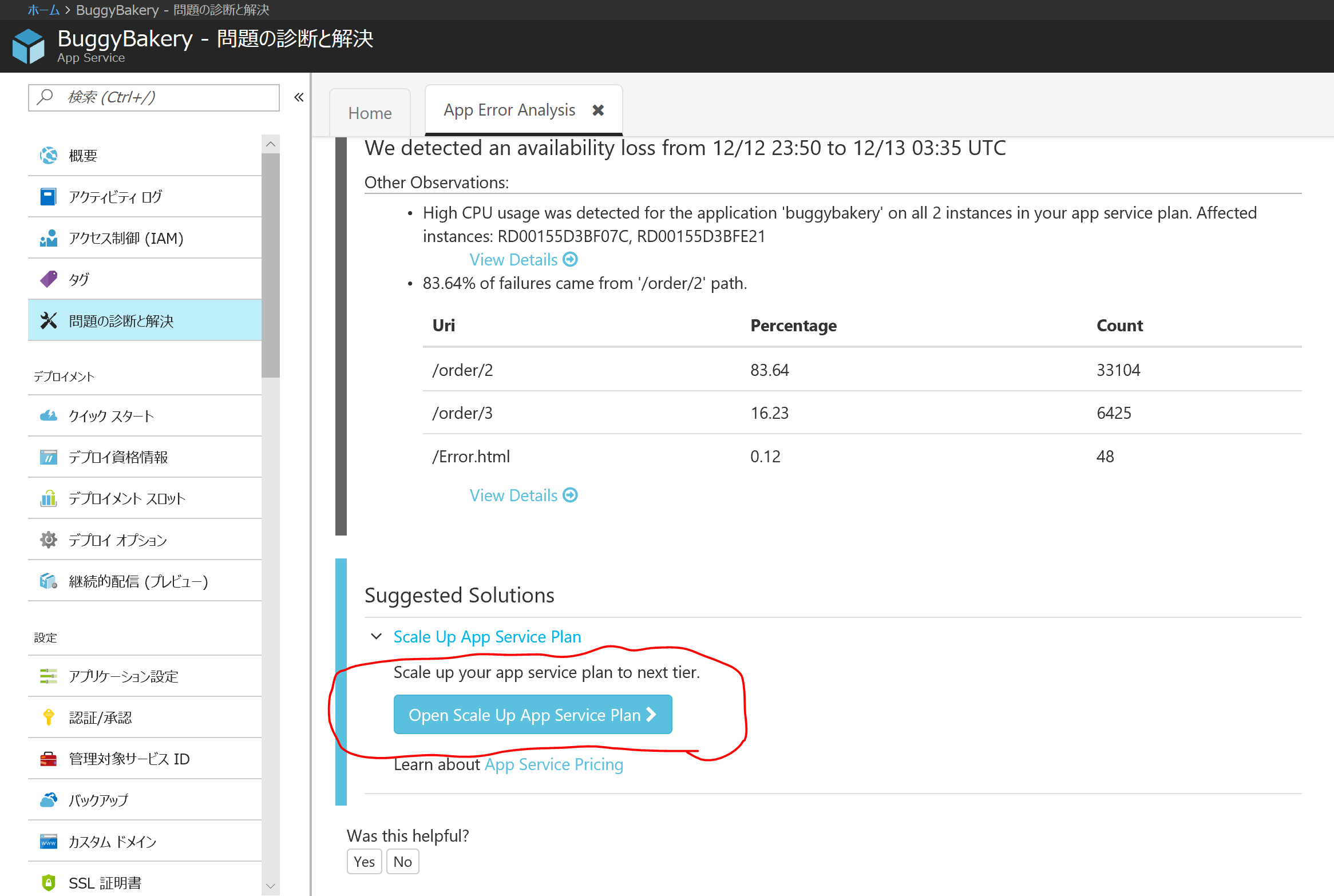
バグの特定まではできないものの、CPU 使用量が高い場合などはスケールアップを推奨し、ボタンを押すことでスケーリングのページに直接飛ぶことができます。
メモリ使用量診断
下記はメモリ使用量の診断ページを開いた場合です。
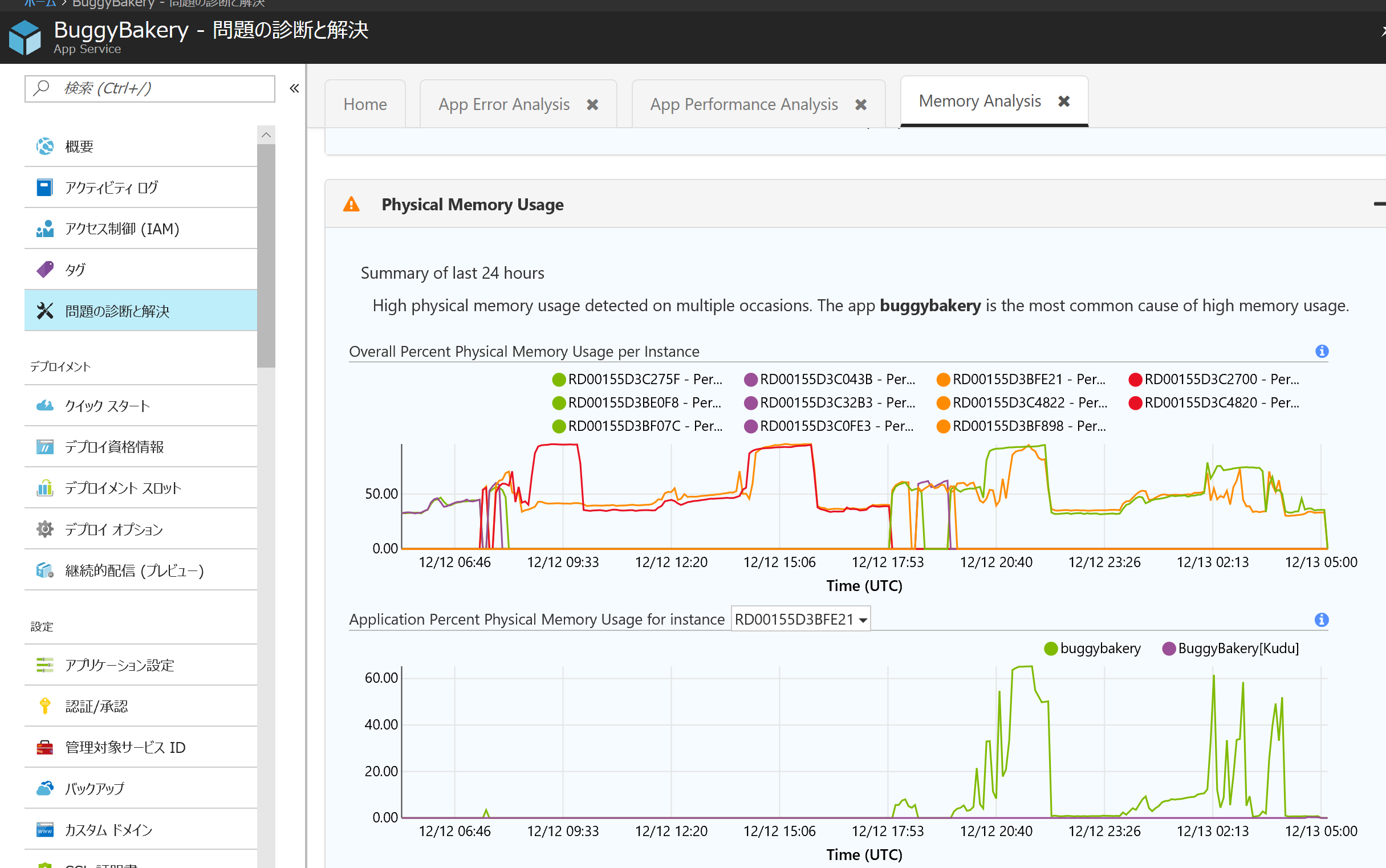
複数のインスタンスを使っている場合やワーカーの間を移動した場合でも、メモリ使用量を正しく把握して表示します。これを使うことで、どのインスタンスで問題が起きていたのかが簡単に分かります。
CPUやメモリ等のリソース診断で見つけることができるのは、開いたサイトの問題だけではありません。App Service Plan に複数のアプリがある場合、それらのアプリでマシンが共有されます。この時いわゆる noisy neighbor の被害を被ることがあります。こういう場合サイト自身のメトリクスだけを見ていてもわからないのですが、このリソース診断を使うことで、本当に問題のあるアプリはどれなのかを容易に特定できます。CPU 使用量についても同様です。
TCP ポート使用量診断
App Service ではそのアーキテクチャ上、アプリから接続できるTCPポート数に制限を設けています(詳細はこちら)。アプリ内で大量にソケットの作成と破棄を短時間で繰り返すとTIME_WAIT状態のポートが大量に残ってしまい、このポート数制限に引っかかることがあります。
厄介なことに App Service ではnetstat -aが使えないので、この問題をユーザ側から把握するのは非常に困難です。TCP ポート使用量診断はこのためにあります。
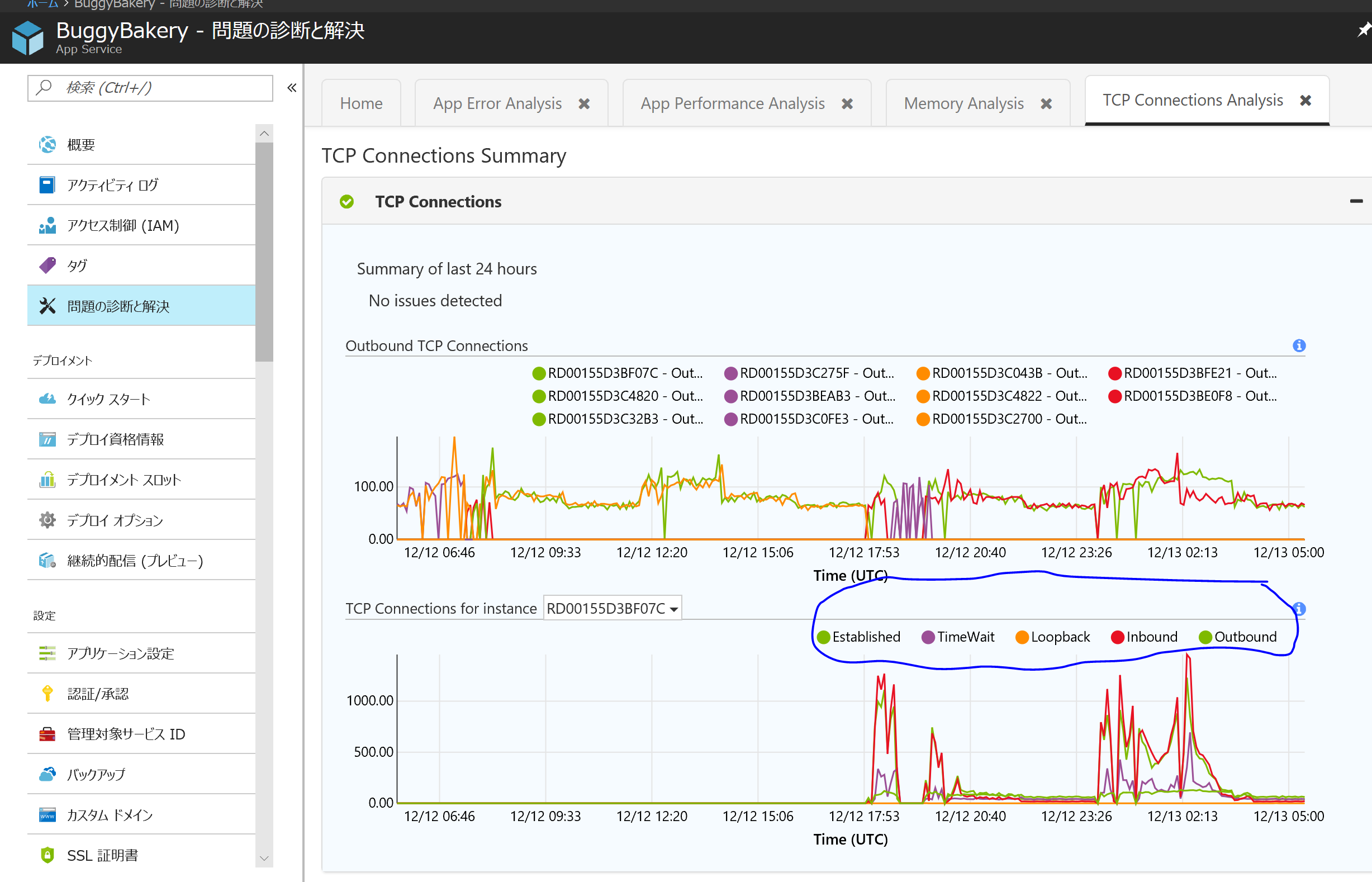
画面上部の Home を押して App Service Diagnostics の最初の画面に戻り、TCP Connections ボタンを押してみてください。
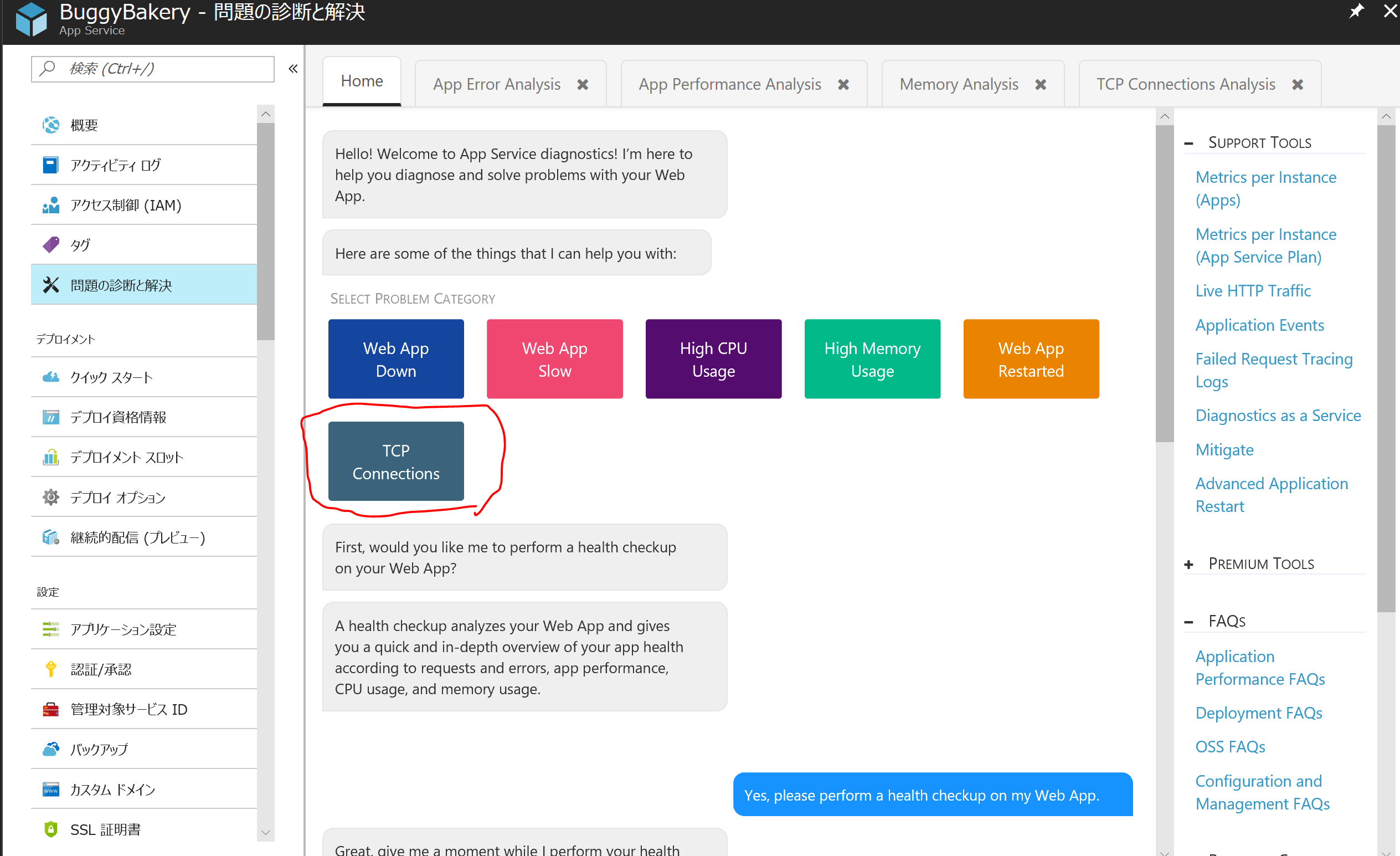
ポート数の時系列変化とステート毎のポート数が即座にわかるようになっています。
Linux 対応
Linux というかコンテナ特有の問題の検出にも対応しています。こちらはまだまだ検出できる問題数が多くないのですが、今後追加していく予定です。
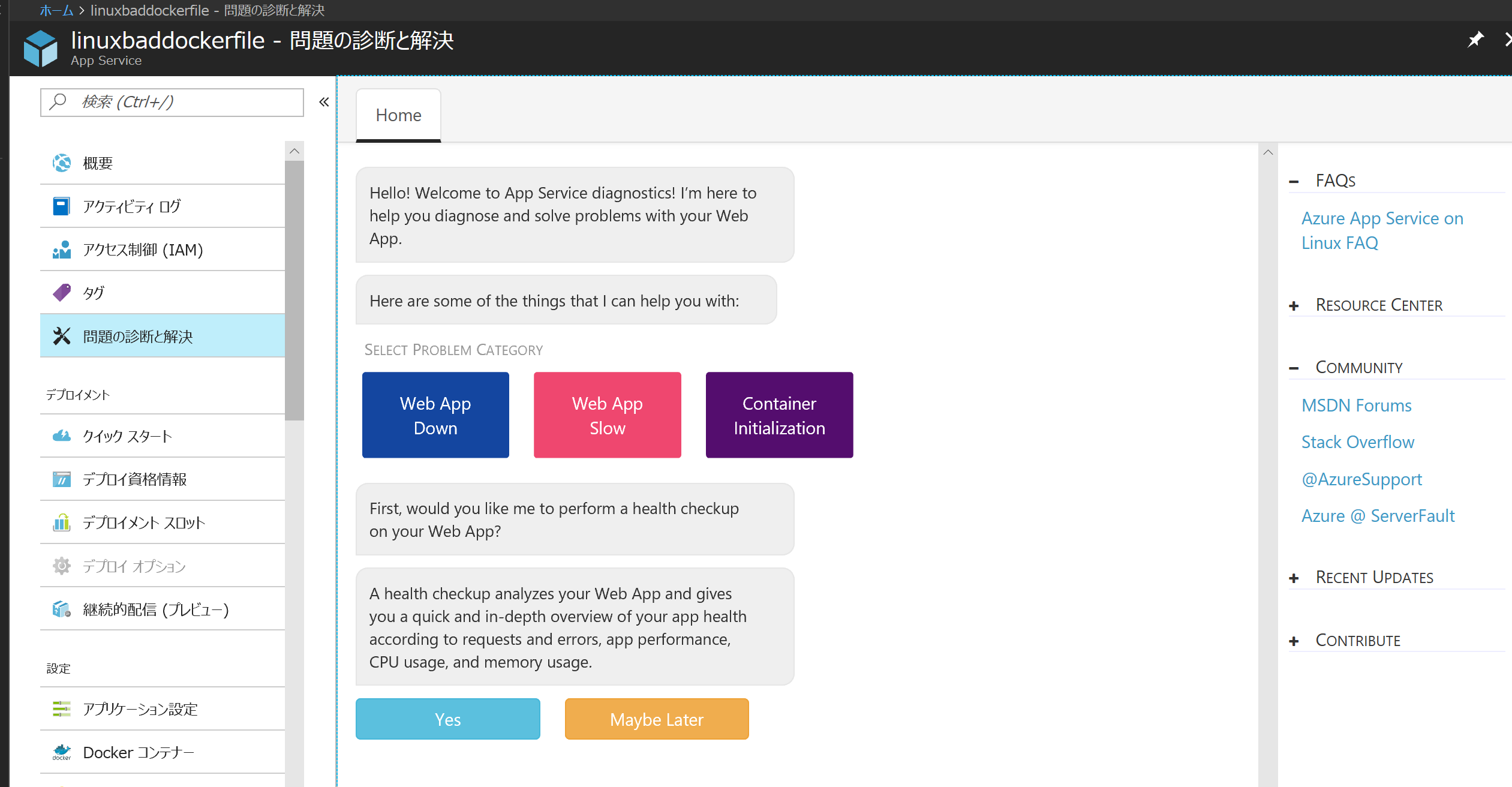
Linux アプリ(Web App on Linux または Web App for Container)の「問題の診断と解決」はボタンが3個しかありません(これから増えます)。とりあえずさっきなかった Container Initialization をクリックしてみましょう。
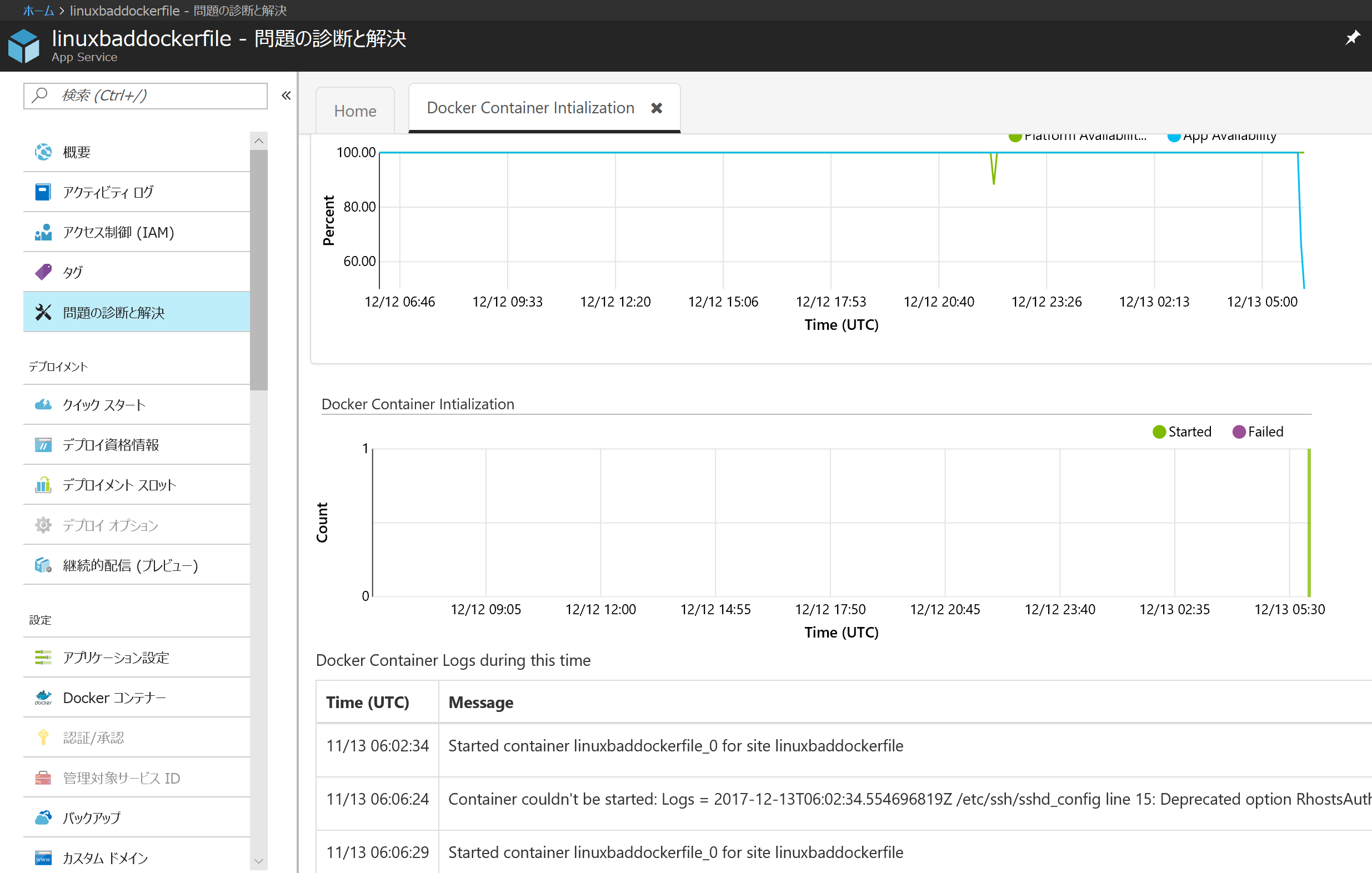
ここではコンテナが起動できなかった場合、そのログを表示してくれます。今後エラーの詳細な分析(ポート番号の指定間違いやリポジトリ名のミス等の検出)を追加していく予定です。
オープンソースなんですよ
App Service Diagnostics のソースコードは GitHub にて公開しています(GitHubへのリンク)。興味のある方はご覧ください。プルリクエストも歓迎です。
まとめ
App Insights をお使いであれば、App Insights と App Service Diagnostics を使うことでトラブルシューティングが捗ると思います。地味な機能ですが、サイト運用の助けになると思います。ぜひお試しください。フィードバックもお待ちしています。