はじめに
Kubernetes は v1.25 で cgroup v2 サポートを GA しており、その後に cgroup v2 に関連する機能が追加されています。しかしまだ多くのディストリビューションで Kubernetes がデフォルトで cgroup v2 を使用しない設定のため、実際に利用している方は多くないと思います。PFN では2022年12月に Kubernetes バージョンを v1.25 にアップグレードするのと同じタイミングで cgroup v2 に切り替えています。
このエントリでは Kubernetes の cgroup v2 に関する機能である MemoryQoS フィーチャゲートと memory.oom.group の2つについて、機能概要と課題を共有します。なお、Kubernetes v1.28 時点での情報です。
そもそもの cgroup v2 について
そもそもの cgroup v2 がなにかについては下記 Kubernetes blog のエントリが詳しいですが、簡単に概要を説明します。
cgroup は、実行中のプロセスの CPU やメモリ使用の制限などの Linux カーネルのリソース管理機能です。Docker はリリース当初から cgroup をコンテナのリソース制限のために使用していて、当然コンテナを使用する Kubernetes であっても同様で、Pod のリソース要求/制限など、Kubernetes でリソースを管理する機能は cgroup で実現されています。
cgroup v2 は、cgroup API の最新バージョンで、より強化されたリソース管理機能があります(最新といっても2016年から提供されてます)。Kubernetes は cgroup v2 のみが有効なノードであればそのより強化されたリソース管理機能を使った機能を提供します。
手元のノードで Kubernetes が cgroup v2 を使用してくれるかを知るには
下記コマンドを実行して確認できます。
$ stat -fc %T /sys/fs/cgroup/
cgroup2fs
tmpfs と出力された場合は cgroup v1 が有効です。v2 への切り替え方法は上記の Kubernetes blog エントリを参照ください。
MemoryQoS フィーチャゲート
1つ目が MemoryQoS フィーチャゲートです。この機能は名前のとおりメモリに対して QoS (Quolity-of-Service) を導入してより柔軟な制御を可能にします。このフィーチャゲートは v1.28 時点でアルファです。
これまで Pod のメモリリソース制御は limits.memory で使用できるメモリ量の上限を設定するのみで、上限を超えると OOM が発生するだけでした。この上限の制御には cgroup memory.max が使われています。Pod requests.memory はというと、主に Pod をスケジューリングするノードを決定するための情報として使用されていてリソース制御には使われていません。
cgroup v2 では memory.max によるメモリ制限に加えて memory.min と memory.high を追加で使用します。
-
memory.min: Pod のメモリ要求 (requests.memory) と同じ値が設定され、設定された値のメモリが保護される。システムがメモリ (page cache) を回収しようとした場合にも対象にならず、保護されておらず回収可能なメモリがなくなった場合に OOM Killer が呼び出される。 -
memory.high: Pod のメモリ制限 (limits.memory) の90%の値が設定され(デフォルト)、これに達するとシステムがメモリをできる限り回収しようとする。

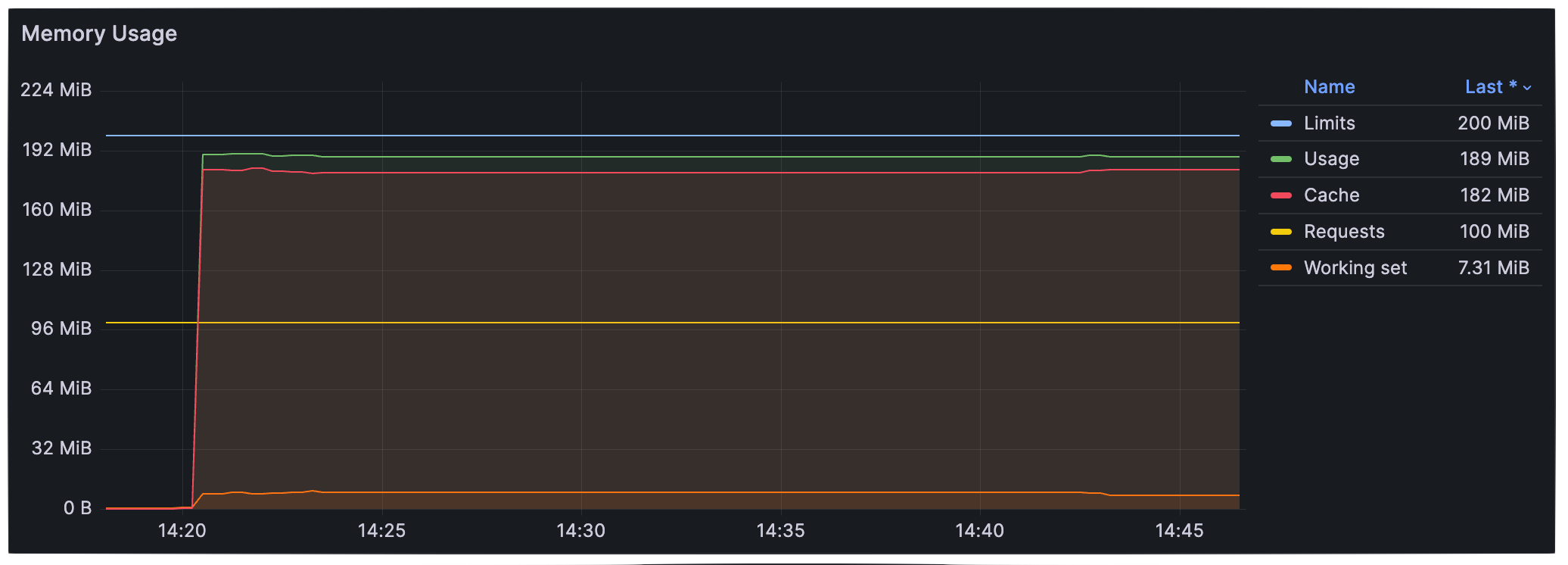
下記グラフはこの機能が有効なクラスタで Pod が page cache の使用を増やしていき memory.high に達した際のものです。上限 (Limits) の90%で抑えられていることがわかります。
課題: requests.memory == limits.memory の場合
MemoryQoS フィーチャゲートを有効にすると要求したメモリが保護されるためよりワークロードが安定することが期待できます。しかしPod のメモリ要求 (requests.memory) と制限 (limits.memory) に同じ値が設定されているワークロードが頻繁に OOM になってしまう可能性があります。
このフィーチャゲートが有効な場合、先に説明したとおりメモリ要求と同じ値が cgroup memory.min に設定されることで要求したメモリが保護されるためシステムから回収されません。そのまま回収されずに制限 (cgroup memory.max) に達してしまうと OOM になってしまいそうですが、使用量が制限の90%に達すると cgroup v2 memory.high によりメモリが回収されるため OOM にならずに済みます。しかし、Kubernetes v1.28 時点でメモリ要求と制限に同じ値が設定されている場合に memory.high が設定されません。そのためメモリが回収されずにそのまま OOM になってしまいます。KEP に下記の記述があり仕様のようです。
- If container sets
limits.memory, we setmemory.high=pod.spec.containers[i].resources.limits[memory] * memory throttling factorfor container level cgroup ifmemory.high>memory.min
// Guaranteed pods by their QoS definition requires that memory request equals memory limit and cpu request must equal cpu limit.
// Here, we only check from memory perspective. Hence MemoryQoS feature is disabled on those QoS pods by not setting memory.high.
if memoryRequest != memoryLimit {
// The formula for memory.high for container cgroup is modified in Alpha stage of the feature in K8s v1.27.
// It will be set based on formula:
// `memory.high=floor[(requests.memory + memory throttling factor * (limits.memory or node allocatable memory - requests.memory))/pageSize] * pageSize`
// where default value of memory throttling factor is set to 0.9
// More info: https://git.k8s.io/enhancements/keps/sig-node/2570-memory-qos
memoryHigh := int64(0)
if memoryLimit != 0 {
memoryHigh = int64(math.Floor(
float64(memoryRequest)+
(float64(memoryLimit)-float64(memoryRequest))*float64(m.memoryThrottlingFactor))/float64(defaultPageSize)) * defaultPageSize
} else {
allocatable := m.getNodeAllocatable()
allocatableMemory, ok := allocatable[v1.ResourceMemory]
if ok && allocatableMemory.Value() > 0 {
memoryHigh = int64(math.Floor(
float64(memoryRequest)+
(float64(allocatableMemory.Value())-float64(memoryRequest))*float64(m.memoryThrottlingFactor))/float64(defaultPageSize)) * defaultPageSize
}
}
if memoryHigh != 0 && memoryHigh > memoryRequest {
unified[cm.Cgroup2MemoryHigh] = strconv.FormatInt(memoryHigh, 10)
}
}
この問題はメモリ要求と制限の値を少しズラずだけで回避できますが、すぐに対処することが難しい場合にはこのフィーチャゲートを有効にすることは避けるべきでしょう(まだアルファですし)。ただ、この仕様のまま GA してしまうと将来無効にできなくなってしまうため、この仕様が期待したものなのかをアップストリームに確認する予定です。
Pod をより安定させる memory.oom.group
Kubernetes v1.28 から導入された機能に cgroup v2 memory.oom.group があります。
これまで Pod が OOM になった場合に子プロセスなど1つのプロセスだけが殺されてコンテナとしては健全なまま実行され続けていました。成熟したマルチプロセスなシステムではこのような子プロセスの OOM を正しく処理できますが、そうではないその他多くのシステムでは OOM になった場合に一部のプロセスが殺されて不安定になるよりはコンテナ全体を OOM として強制終了したほうが安定しそうです。そこで、Kubernetes v1.28 からコンテナ内のプロセスが OOM になった場合にコンテナ内のすべての PID を OOM として強制終了するようになりました。
課題: 子プロセスが OOM になる前提のワークロードの存在
OOM になった場合にコンテナ全体を終了するのは多くのワークロードが安定すると思われますが、私たちのワークロードの一部で問題がありました。クラスタを v1.28 にアップグレードして数日してこれまで成功していたジョブが OOM で失敗するようになったという問い合わせがありました。話を聞いてみるとそのジョブは実際に走らせてみるまで各エントリがメモリをどれだけ消費するかがわからないワークロードのためとりあえず走らせて子プロセスが OOM になったら別のエントリを計算するように実装しているとのことでした。memory.oom.group が有効になったため、子プロセスが OOM になると全体が終了されてしまうため計算を継続できません。
また別の問い合わせではインタラクティブ用途のワークロードで make の -k オプションを使用してビルド処理の一部が失敗しても継続するようにしていて OOM で失敗した場合にもビルドが成功するようにしていました(例えば make -j 20 -k || make -j 10)。こちらもこの機能により OOM が発生した事前でシェル自体が終了されてしまいます。
これら問題はマニフェストの修正のみで済まずアプリケーションやその使い方を変えてもらう必要があります。そのため一旦機能自体を無効にしたかったのですが、memory.oom.group の使用は v1.28 時点でオプションになっておらず無効にしたい場合は Kubernetes ノードで cgroup v2 を使わないように変更する必要があります。私たちの環境ではすぐに cgroup v2 を無効にすることは難しかったため、この機能を削除した kubelet をビルドして使うようにして対応しています。
diff --git a/pkg/kubelet/kuberuntime/kuberuntime_container_linux.go b/pkg/kubelet/kuberuntime/kuberuntime_container_linux.go
index f14b6d1a6fc..0aef6395ce7 100644
--- a/pkg/kubelet/kuberuntime/kuberuntime_container_linux.go
+++ b/pkg/kubelet/kuberuntime/kuberuntime_container_linux.go
@@ -233,15 +233,6 @@ func (m *kubeGenericRuntimeManager) calculateLinuxResources(cpuRequest, cpuLimit
resources.CpuPeriod = cpuPeriod
}
- // runc requires cgroupv2 for unified mode
- if isCgroup2UnifiedMode() {
- resources.Unified = map[string]string{
- // Ask the kernel to kill all processes in the container cgroup in case of OOM.
- // See memory.oom.group in https://www.kernel.org/doc/html/latest/admin-guide/cgroup-v2.html for
- // more info.
- "memory.oom.group": "1",
- }
- }
return &resources
}
アップストリームに対してこの機能を無効にするオプションを追加してほしいと要望しています1。今後 SIG-Node のミーティングの議題として扱ってくれるようです。
2024/04/04 追記: 残念ながら v1.30 には入りませんでした。この機能を追加するのであればコンテナレベルで制御すべきという意見があり硬直状態になっています。
2023/12/8 追記: v1.30 でこの機能を無効にするオプションを kubelet に追加することに決まったとのことです。
In the SIG-Node Meeting, we decided to pursue a node level kubelet config field that enables or disables this feature to allow an admin to opt-in. stay tuned in 1.30 for this
結論
Kubernetes は cgroup v2 サポートを GA しているものの、現実世界で cgroup v2 を使用したクラスタはまだ少ないと思われます。そのため、cgroup v2 に関連する変更の問題が表に出てきていないと考えられます。今後 cgroup v2 を使うクラスタが増えてくるなかで問題が顕在化する可能性があるため、cgroup v2 の使用はしばらく様子をみたほうがいいかもしれません。過去には下記の問題もありました。
最後に cgroup については gihyo.jp で連載の LXCで学ぶコンテナ入門 -軽量仮想化環境を実現する技術で学べます。このエントリを読んで cgroup に興味が湧いた方におすすめです。
PFN では大規模な機械学習プラットフォームを Kubernetes でいいかんじにしていくエンジニアを募集しています。お気軽にカジュアル面談にご応募ください。
- 株式会社 Preferred Networks "Infrastructure” 領域カジュアル面談応募フォーム
- Machine Learning Platform Engineer/機械学習プラットフォームエンジニア (Infrastructure) - Preferred Networks, Inc.