はじめに
画像やメールを使うとBase64でデコードとエンコードするという場面に出会います。
これまで、ふんわりは理解していましたが、詳細が気になったので調べてみました。
そもそもBase64とは?
-
データのエンコード方式で、主に以下の用途で使用されます。
- 電子メールの添付ファイル
- Basic認証(HTTPヘッダー)
- ファイルアップロード
- 全てのデータを64種類の文字(64進数)で表現します。
Base64で使用する64種類の文字
| 種類 | 使用文字 |
|---|---|
| アルファベット | A~Z, a~z |
| 数字 | 0~9 |
| 記号 |
+, /
|
| 補足記号 |
=(不足部分の埋め合わせ) |
Base64が必要な理由
-
通信や保存の際、一部のシステムでは**ASCII文字(7bit)**しか扱えない制約がある。
例:電子メールでは日本語や画像データを扱えない。 -
エンコーディング制限: 一部の通信プロトコルやサービス(例えば、HTTPでのPOSTリクエスト)では、バイナリデータを直接扱うことができず、通常はテキストデータに変換する必要がある。
なので、Base64でバイナリデータをASCII文字に変換し、幅広い環境で扱えるようにするわけですね。
ASCIIがいまいち分からない方は、記事の最後に余談で書いてるのでご参照ください〜
エンコードの手順
じゃあ、バイナリデータをBase64に変換することをエンコードと呼ぶのは分かったけど、具体的にどういう操作をしているのでしょうか。その手順を追ってみます。
以下は、画像データをBase64エンコードする例です。
画像データをBase64エンコードする手順
1.画像データ(バイナリ)を読み込む
- バイナリデータとしては以下のように表現されます:
10001001 01010000 01001110 01000111 00001101 00001010 00011010 00001010
2.6ビットずつに分割
- 上記のバイナリデータを6ビット単位に分割します:
100010 010101 000001 001110 010001 110000 110100 001010 000110 100000 1010
_
- 6ビット単位にならない部分は不足分を
0で埋めます:100010 010101 000001 001110 010001 110000 110100 001010 000110 100000 001010
3.Base64変換表を使って文字に変換
- 分割した6ビットをBase64の文字変換表に基づいて対応する文字に変換します:
100010 -> i 010101 -> V 000001 -> B 001110 -> O 010001 -> R 110000 -> w 110100 -> 0 001010 -> K 000110 -> G 100000 -> g 001010 -> K
_
- ここでの出力例:
iVBORw0KGg==
4.不足部分を=で埋める
- エンコードされた文字列が4の倍数になるように末尾を
=で埋めます(この例ではすでに4の倍数なので不要)。
これで画像データをBase64にエンコードできました🎉
デコードの手順
次に、Base64でエンコードされた文字列を受け取った側が元のバイナリデータに戻すには、デコードと逆の手順で処理すれば良さそうです。
Base64文字列をデコードする手順
1.Base64文字列を取得する
- エンコードされたBase64文字列を取得します(例:
iVBORw0KGg==)
2.Base64文字変換表を使ってバイナリに変換する
- 各文字を6ビットのバイナリに変換します。
Base64文字変換表を参照し、以下のように対応させます。i -> 100010 V -> 010101 B -> 000001 O -> 001110 R -> 010001 w -> 110000 0 -> 110100 K -> 001010 G -> 000110 g -> 100000 K -> 001010
3.6ビットを連結する
- 6ビット単位のバイナリを全て連結します。
100010 010101 000001 001110 010001 110000 110100 001010 000110 100000 001010
4.8ビット単位に戻す
- 元のデータ形式に戻すため、6ビットごとに連結されたバイナリを8ビット単位に戻します。
10001001 01010000 01001110 01000111 00001101 00001010 00011010 00001010
5.データを復元する
- バイナリデータを元の形式に戻します。これは、画像データや文字列など、元のデータ形式に従って扱われます。
エンコードとデコードの比較
エンコードとデコードの手順は逆の処理を行います。
| 手順 | エンコード | デコード |
|---|---|---|
| 入力 | バイナリデータ | Base64文字列 |
| 処理1 | バイナリデータを6ビット単位に分割 | Base64文字列を6ビット単位のバイナリに変換 |
| 処理2 | Base64変換表を使って文字に変換 | 6ビットのバイナリを連結し、8ビット単位に分割 |
| 処理3 | 4の倍数になるように末尾を=で埋める(必要な場合のみ) |
元のバイナリデータを復元 |
| 出力 | Base64文字列 | 元のデータ(バイナリ、画像、文字列など) |
デコードの注意点
-
=の末尾はパディングとして使われるので無視してデコードする - 変換後のデータは、元のデータ形式(画像、テキストなど)に従って復元する必要がある
まとめ
調べてみると、意外と単純でしたが勉強になりました。
「単純にバイナリで送ればいいじゃん」って思いそうですが、そうできない場面もあるのでそんな時はエンコードして使えるようにしましょう、ということですね🤔
ASCIIとは(余談)
1. ASCIIの基本
- ASCIIは、7ビットの文字コードで、以下を表すのに使われます:
- アルファベット(大文字・小文字)
- 数字
- 一部の記号(例:
!,@,#など) - 制御文字(例: 改行
LF、タブTAB)
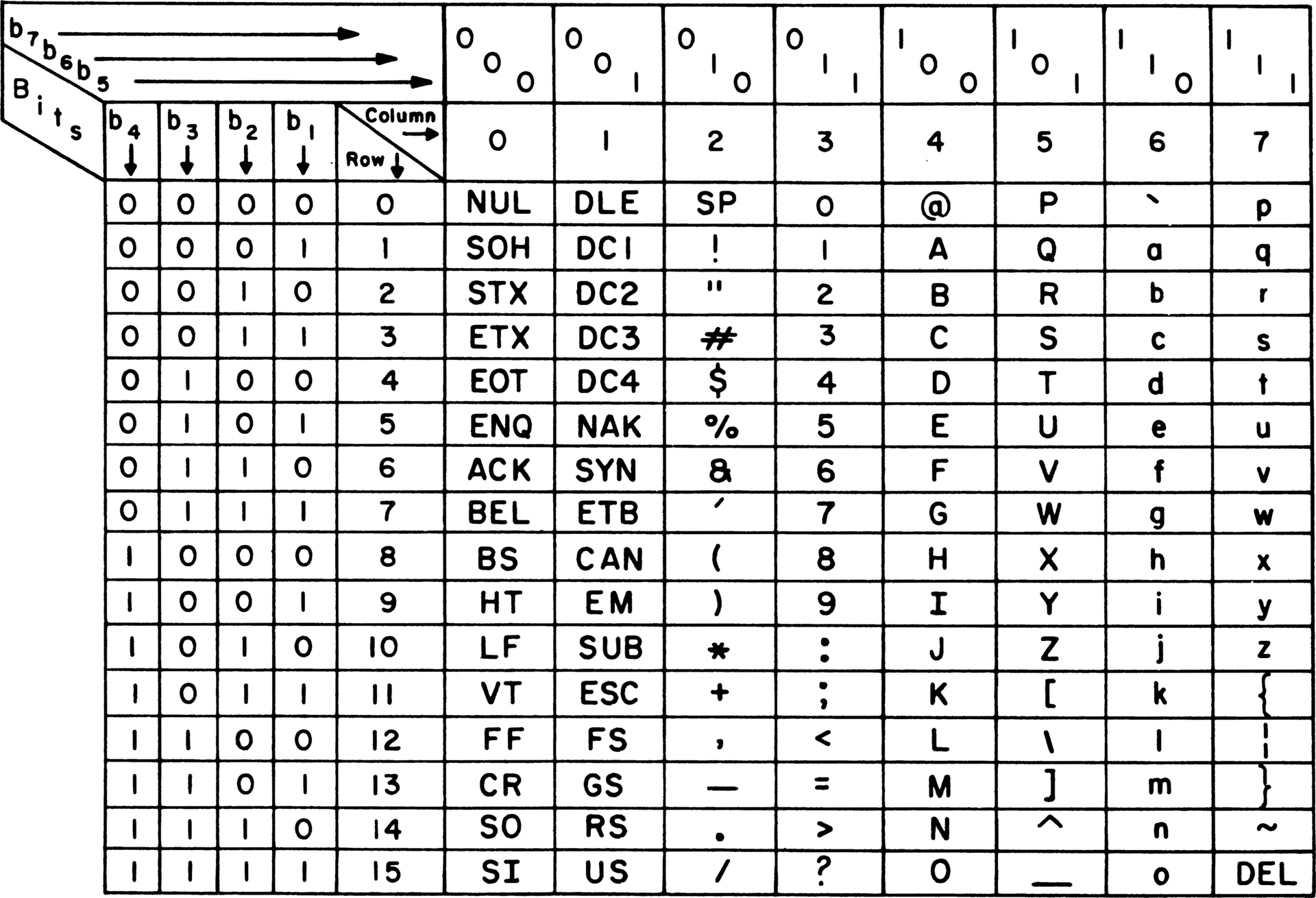
2. ASCIIコード表
ASCIIコード表は縦軸と横軸で構成され、7ビット(128文字) で表されます。表の使い方としては、縦軸と横軸の値を組み合わせて1文字を特定します。たとえば:
-
Aのコードは 0x41(16進数)、01000001(2進数) -
aのコードは 0x61(16進数)、01100001(2進数)
3. 先頭ビットとパリティ
-
これは一部の古い通信方式で使用される概念です。パリティビットはデータ通信時にエラーを検出するために追加されるもので、7ビットのASCIIに1ビットを加えて8ビットで送信していました。
-
現在では、パリティビットを使用しないケースが多く、ASCIIは純粋に7ビットの文字コードとして解釈されます。
4. 補足: ASCIIの限界
ASCIIは英語圏を想定して作られた文字コードなので、日本語や多言語には対応していません。そのため、国際化のためには拡張された文字コード(UTF-8やUnicode)が必要です。