はじめに
sklearn.feature_selectionの特徴量選択で、相互情報量なるものに出会ったので、その解説を試みたいと思います。
相互情報量
X, Yが共に離散値の場合
\sum_{y \in Y} \sum_{x \in X}p(x, y) \log \frac{p(x, y)}{p(x)p(y)}
X, Yが共に連続値の場合
\int_{y \in Y} \int_{x \in X}p(x, y) \log \frac{p(x, y)}{p(x)p(y)}dxdy
Xが離散値, Yが連続値の場合
\sum_{x \in X} \int_{y \in Y} \log \frac{\mu(x, y)}{p(x)\mu(y)}dy
相互情報量がもつ性質としては値が必ず0以上の正の数となり、X、Yが独立(p(x,y)=p(x)p(y))であれば0、依存関係(p(x,y)≠p(x)p(y))であればあるほど大きな正の数となります。
分解します
式をみると、どれもp(x,y)とp(x)p(y)(またはμ(x,y)とp(x)μ(y))で構成されていることがわかります。p(x,y)のことを同時確率分布、p(x)のことを周辺確率分布といいます(p(y)も同様)。
次は同時確率分布と周辺確率分布を使って相互情報量を計算します。
例1: X,Yが独立の場合
同時確率分布と周辺確率分布の考え方を説明します。離散値の場合と連続値の場合がありますが、先に離散値を扱います。まずは、この表をみてください。
例としてコイン投げを考えます。コイン1とコイン2を用意し、確率変数Xはコイン1を二回投げて表が出る確率、同様に確率変数Yはコイン2を二回投げて表が出る確率を表しています。

見方としては、表が0回となる確率はp(X=0)=1/6みたいな感じです。
次に下図のような表を用意します。

ここで、この6×6の表のことを同時確率分布、確率変数XとYの確率 (1/6, 1/3, 1/2...)を周辺確率分布といいます。

見方としてはX=0かつ、Y=0となる確率はp(X=0,Y=0)=1/18みたいな感じです。同時確率分布はXの条件とYの条件を同時に満たす確率分布なのでこのような名前になっているんですね。
また、同時確率分布は縦方向か、横方向に足し合わせれば、それぞれの周辺確率分布になります。(例えば、1/18+1/18+1/18=1/6=p(X=0)のときの周辺確率)
ではこのときの相互情報量I(X,Y)を計算します。
\begin{align}
I(X=0,Y=0) &=\frac{1}{18} \log\frac{\frac{1}{18}}{\frac{1}{6} \frac{1}{3}} \\
&=0 \\
\end{align}
\begin{align}
I(X=1,Y=0) &=\frac{1}{9} \log\frac{\frac{1}{9}}{\frac{1}{3} \frac{1}{3}} \\
&=0 \\
\end{align}
\begin{align}
I(X=2,Y=0) &=\frac{1}{6} \log\frac{\frac{1}{6}}{\frac{1}{2} \frac{1}{3}} \\
&=0 \\
\end{align}
他の点についても同様に計算し、まとめると、
I(X,Y)=0 \\
相互情報量は0となりました。
表を見ればわかるのですが、この例ではそれぞれの同時確率は、全て周辺確率同士の値を掛け合わさった値(例えば、p(x=0, y=0)=p(x=0)p(y=0))なので、確率変数XとYは独立であったと考えることができます。これがX,Yが独立である場合の例です。
例2: X,Yが独立でない場合
次のような表を用意しました。周辺確率分布は先ほどの例と同じで、同時確率分布が少し違います。

相互情報量I(X,Y)を計算します。
\begin{align}
I(X=0,Y=0) &=\frac{1}{6} \log\frac{\frac{1}{6}}{\frac{1}{6} \frac{1}{3}} \\
& \fallingdotseq 0.18 \\
\end{align}
\begin{align}
I(X=1,Y=0) &=\frac{1}{6} \log\frac{\frac{1}{6}}{\frac{1}{3} \frac{1}{3}} \\
& \fallingdotseq 0.068 \\
\end{align}
他の点についても同様に計算すると、
I(X,Y) \fallingdotseq 0.547 \\
ぐらいになりました。(logの底はネイピア数としました。底は2とすることが多いみたいですが、今回はただの概算なので計算しやすい方を使いました。ちなみにsklearnでもネイピア数を使用していました。)
これで周辺確率分布が独立の場合とそうでない場合を考えました!
これまでの例では同時確率分布、周辺確率分布がわかっている状態だったので、誰でも計算ができた訳ですが、実際にデータ解析を行う際はこうはいきません。自然現象から観測されたデータからは同時確率分布、周辺確率分布はわからないので、__真の相互情報量を求めることはできない__のです。
なので、__「推定」__という形で値を算出します。次からは推定するための二つの方法を説明していきます。
一般的な方法: binning
この方法が一般的とされています。しかし、sklearnが参照している「mutual information between discrete and continuous data sets」によると、この手法はパラメータの取り扱いが難しく、精度がよくない場合があるそうなので、sklearnのmutual_info_regressionではこのあとで説明するk-NN法が採用されています。
比較するためにこの手法についても触れておきます。
例として、200個の試料を用意し、それぞれの試料において遺伝子G1とG2の発現量を調べた実験を行ったとします。
その様子を散布図として表示します。

一般的に利用されるbinningと呼ばれる方法はとりあえずG1の変域とG2の値域をn等分して、それぞれの区画(bin)に中で相互情報量を離散値として計算します。(本当は連続値だけど)
例えばn=2(4等分)の場合、

このようにG1、G2をそれぞれ2等分し、それぞれの区画(全部で4つ)の中にある個数を確率として表します。

この個数を全体の200で割って確率値にします。

これで同時確率分布と周辺確率分布がわかりました。
ここからは先ほどと同様に、相互情報量を計算します。
計算過程は省きます。 (logは自然対数で計算)
I(G1,G2) \fallingdotseq 0.185 \\
結局同じように計算すればいいんじゃん!これで一件落着!かと思いきやそうではありません。この方法には問題点があります。
問題点
・nはいくつが妥当なの?
binningでは何等分(n等分)するかを自分で決めなければいけません。(k-NN法にも自分で決めないといけないパラメータがありますが、、)
他のnの場合はどうなるでしょうか。プログラミングしました。

このように、nによっていろんな相互情報量をもつことがわかります。
比較のために、同時確率分布と周辺確率分布がわかっているとしたとき(その分布については注記参照)の真の相互情報量を右図に破線(0.3当たり)として示してあります。
しかし、本来は真の相互情報量はわかっていない訳ですから、系統誤差、偶然誤差のことを考慮して、少なすぎるnまたは多すぎるnは使わない方がいいという推奨はあるものの、__nを操作して相互情報量を推定することは難しい__ということがわかると思います。
これがbinningがもつ問題点です。
次はk-NN法を用いた推定方法です。
![]() 注記
注記
ここで求めた真の相互情報量は、このようなV字型の確率分布を同時確率分布とし、計算を行いました。(無理やり作りました、、)

また、G1とG2それぞれの周辺分布は次のようになりました。下の青いプロットは観測データです。(右図がカクカクになってて違和感しかないけどお許しを、、)

また、nの範囲なのですが、
1 \leq n \leq 110 \\
としました。ある程度のnから、相互情報量は一定の値に収束していることが伺えます。これは、同じ区画に入るプロットが一つしかない状態になることで、これ以上区画を細かくしても計算される相互情報量の値が変わらなくなるからです。
sklearnで使われている推定: k-NN
sklearn.feature_selection.mutual_info_regressionでは連続値を対象として、k-nearest neighbors(k-NN)という方法を使って相互情報量を推定しています。
では推定するための式をみていきます。
I(X,Y)=\psi(k)-<\psi(n_{x}+1) + \psi(n_{y}+1)>+ \psi(N)
急に意味不明になりましたね、、この式が記載されていた「estimating mutual information」をみたところ、Shannonのエントロピーからいろいろやっていましたが、自分には理解できない展開となっていました。残念、、
式についてですが、ψはディガンマ関数といってガンマ関数を微分した関数です。Nは全てのプロットの個数、<>はその中を平均するとのことでした。他の文字についてはこのあと説明します。
k-nearest neighbors
根底にある考え方は単純で、あるプロットからk個プロット分離れたプロットまでを同じ区画とし、計算に反映させます。
例として次の図を考えます。(「estimating mutual information」からとってきました)

真ん中らへんにあるプロット(i)に注目します。k=1とすると、プロット(i)から1プロット分離れたプロットは図中のオレンジ色の矢印にあるプロットとなるので、このプロットを基にε(i)を求めます。
ε(i)の半分となるε(i)/2を求めます。この距離を求めれば、それを二倍すればε(i)がでます。(当たり前ですね!)
プロット(i)からk=1を満たすプロットまでの距離を測ります。普通にピタゴラスの定理を使うとユークリッド距離を求めることになるのですが、sklearnではチェビシェフ距離を使用していました。

チェビシェフ距離はx軸方向へ進む距離、y軸方向へ進む距離の内、より大きい方の距離のことです。

この例に関してはx軸方向の方が距離が大きいので、これをε(i)/2とします。
こうして求めたε(i)/2からε(i)を求めたら、縦方向(y)と横方向(x)に含まれるプロットの個数を数えます。今回はnx(i)=5、ny(i)=3となりました。
これを他のプロットに対しても行って、相互情報量を推定することができるのですね。
計算
先ほどのG1、G2の例を再び使用して相互情報量を推定します。プログラムの力を借りました。
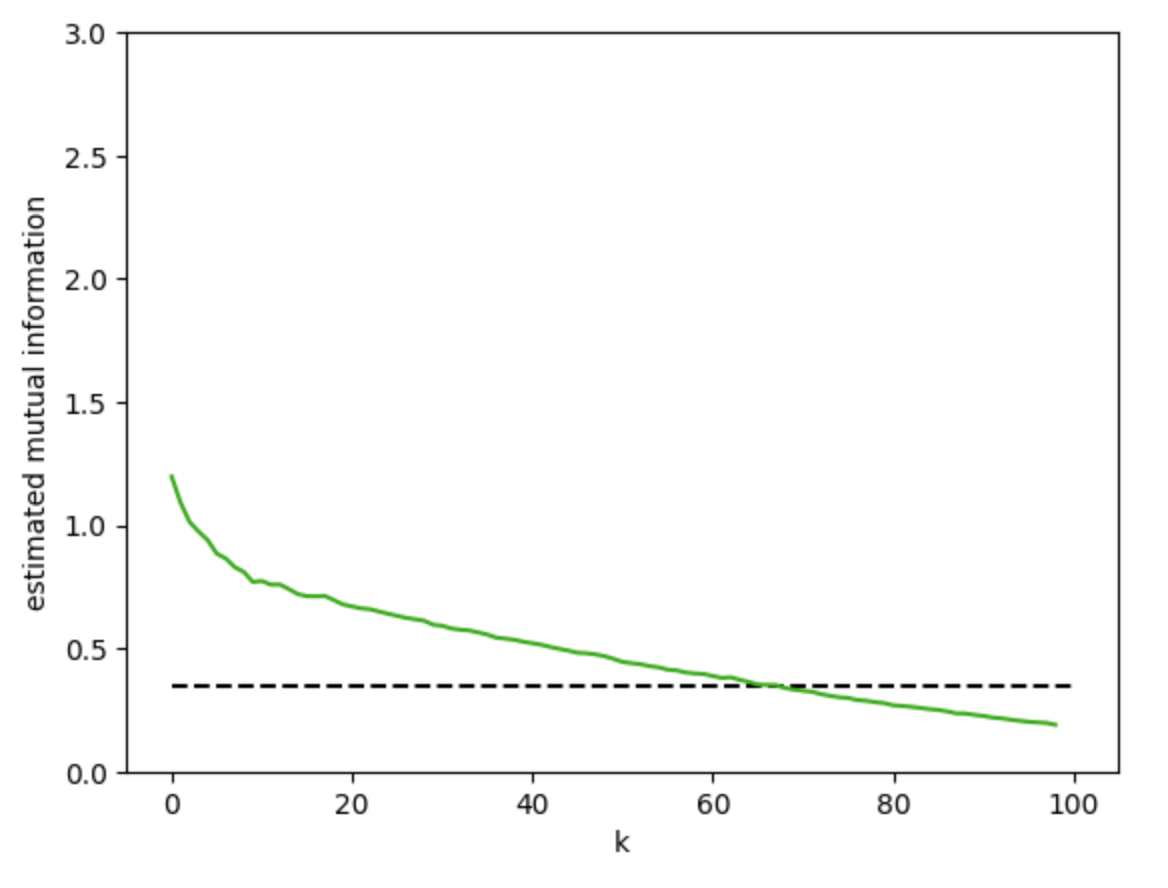
いろんなkのときの相互情報量を推定しました。破線部分が真の相互情報量です(0.3当たり)。
これもbinningと同様にkというパラメータをどう調整するかという問題があると思いますが、
・「estimating mutual information」
・「mutual information between discrete and continuous data sets」
によると、プロットの系統誤差、偶然誤差の影響を考えて、kは1よりは大きい方がいいが、かなり大きい(例えば全プロットNの半分くらいのk)と、系統誤差の影響が偶然誤差の影響を上回ってしまうため、k=2 to 10くらいが好ましいみたいなことが書いてありました。
図のk=2 to 10当たりをみると、真の相互情報量より大きな推定値となっていることがわかります。binningの結果と比べると、パラメータによる変動がbinningのときよりも少ないと考えることができます。
ここまでbinningとk-NNをみていきました!一般的にはbinningが使われているということですが、上の例でもみたようにk-NNはbinningよりパレメータによる変動が少ないとさています。
ちょいと番外編:相互情報量と相関係数
相関関係の強さを図る測る指標として相関係数がありますが、相関係数は線形の相関にしか対応することができず、例えば、今回扱ったような非線形な相関を示したい場合には役に立ちません。そこで、相互情報量を使うことで、非線形の場合にも対応させることができます。
MICという名前が付いているみたいです。
・「非線形の相関分析MICについて」
・「MICの解説」
などわかりやすい記事がありました。