はじめに
今は読めなくなってしまった ExcelができていればSQLはできている にあった消費税の誤差配賦の例題を、データベースの文脈からはとりあえずいったん離れて、Squeak Smalltalk の特徴を活かしてどんなふうにこの処理を変態チックに書けるかをちょっとした頭の体操をかねて考えてみました。具体的なイメージとしては、Squeak/Pharo Smalltalk に備わる APL/J ライクな配列演算機能 で紹介した機能を使って、普通に思いつくオーソドックスな処理よりももっと簡潔に(ある意味エクセルっぽくループ処理を意識せず)おおざっぱに書くことはできないか、という試みです。
消費税の誤差配賦処理について
一般に切り捨てで算出する消費税額は、請求書(あるいは領収書)ごとの総購入額から算出された額と、その明細で商品ごとに算出した消費税額を合算した額の間に差が生じることがあります。ここでは、この差を購入額の高いものから順に1円ずつ割り振る(配賦する)ことで帳簿上の整合性がとれるようにする処理を考えます。元記事では複数のテーブルで購入額や消費税もデータとして与えられていましたが、当記事では簡単のため請求書NO、商品CD、単価、購入数(数量)のみの必要最小限の情報から
①請求書NO別の購入額と消費税額
②商品ごとの購入額と消費税額
③消費税額の差額とそれを配賦後の消費税額
を求め、①の請求書表および、②と③をあわせた明細表を作成することとします。サンプルデータは元記事向けに用意されたエクセルファイルの内容を改変追記して利用させていただきました。→ data.utf8.txt
なお、下に示した Smalltalk のコードは個人的な好みで日本語のシンボル(インターンされた文字列)や変数名を使ってしまっているため、実際に動かすには日本語を扱えるように あらかじめ細工をした Squeak5.1 が必要です。どうぞあしからず。なお、オーソドックスなコードの方は 日本語表示を可能な設定を済ませた Pharo5 でも動かせるように書きました。コードを Squeak なら Workspace に、Pharo なら Playground に貼り付けて、あらためて全選択(ctrl + a)してから do it(ctrl + d)で実行すると、data.utf8.txt を読み込んで meisai.txt 、seikyuu.txt という二つのタブ区切りのテキストファイルを生成します。data.utf8.txt は仮想イメージ(*.image)と同じディレクトリに入れておきます(もしくはコード中の当該ファイル名をパスも含めるように変更します)。
オーソドックスな実装
簡単のため与えられるデータが 請求書NO でソート済みという前提で、ぱっと思いついた処理の流れは次のようなものでした。
- 1行を読み込んで要素に分解して明細レコードとする
- 明細レコードから 単価 と 数量 を得て 購入額 を、さらに 消費税 を算出。元の明細レコードに要素として追加
- 同じ 請求書NO の間、明細レコード をバッファーに蓄積。購入額 と 消費税 は加算
- 請求書NO の切り替わりのタイミングで請求書テーブルに 請求書NO 購入額 消費税を出力
- 購入額小計から算出した消費税と明細レコードの消費税の和との差を算出
- バッファー中の明細レコードを購入額でソートし上位から差額を1円ずつ配賦。残りの明細レコードには配賦0円に
- 配賦と消費税を加算した調整後消費税を各明細レコードに追加し、元の順番で明細テーブルに出力
- 以上をデータが尽きるまで繰り返し
これをスクリプトっぽい Smalltalk のコードにすると次のようになります。Squeak なら Workspace に、Pharo なら Playground に貼り付けて(ctrl + v)、あらためて全選択(ctrl + a)してから do it(ctrl + d)で実行できます。
| sepalator dataFIleName outFileNames 消費税率 |
(Deprecation respondsTo: #raiseWarning:) ifTrue: [Deprecation perform: #raiseWarning: with: false].
sepalator := Character tab.
dataFIleName := 'data.utf8.txt'.
outFileNames := #('meisai.txt' 'seikyuu.txt').
消費税率 := 0.08.
FileStream oldFileNamed: dataFIleName do: [:dataFile |
| 既存カラム |
既存カラム := dataFile nextLine subStrings: {sepalator}.
FileStream newFileNamed: outFileNames first do: [:outFile1 |
| 導出カラム 請求書カラム |
導出カラム := #(購入額 消費税額 配賦額 配賦後消費税額).
既存カラム, 導出カラム do: [:項目 | outFile1 nextPutAll: 項目] separatedBy: [outFile1 tab].
outFile1 cr.
請求書カラム := (既存カラム first: 1), #(購入額 消費税額).
FileStream newFileNamed: outFileNames second do: [:outFile2 |
| 配賦処理 レコード 請求書NO 明細バッファ 請求書購入額 消費税額小計 |
請求書カラム do: [:項目 | outFile2 nextPutAll: 項目] separatedBy: [outFile2 tab].
outFile2 cr.
請求書NO := レコード := 明細バッファ := nil.
請求書購入額 := 消費税額小計 := 0.
配賦処理 := [
請求書NO notNil ifTrue: [
| 請求書消費税額 差額 |
請求書消費税額 := (請求書購入額 * 消費税率) truncated.
outFile2
nextPutAll: 請求書NO printString; tab;
nextPutAll: 請求書購入額 printString; tab;
nextPutAll: 請求書消費税額 printString; cr.
差額 := 請求書消費税額 - 消費税額小計.
(明細バッファ sorted: [:x :y | x fifth > y fifth]) doWithIndex: [:明細 :idx |
明細 add: (idx <= 差額) asBit; add: (明細 last: 2) sum
].
明細バッファ do: [:明細 |
明細 do: [:項目 | outFile1 nextPutAll: 項目 printString] separatedBy: [outFile1 tab].
outFile1 cr
]
].
明細バッファ := OrderedCollection new.
請求書購入額 := 消費税額小計 := 0.
請求書NO := レコード first.
].
[dataFile atEnd] whileFalse: [
レコード := (dataFile nextLine subStrings: {sepalator}) asOrderedCollection collect: #asNumber.
self assert: 既存カラム size = レコード size.
請求書NO ~= レコード first ifTrue: [配賦処理 value].
明細バッファ add: レコード.
請求書購入額 := 請求書購入額 + (レコード add: (レコード atLast: 2) * レコード last).
消費税額小計 := 消費税額小計 + (レコード add: (レコード last * 消費税率) truncated).
].
配賦処理 value
]
]
].
outFileNames do: [:fname | (FileStream oldFileNamed: fname) edit]
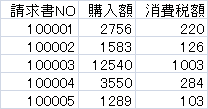
以下がこのコードで生成される導出項目が追加された明細一覧(meisai.txt)と請求書ごとにまとめた一覧(seikyuu.txt)です。配賦額の項で、同じ請求書内の購入額の多い順に差額が配賦されているのがわかります。
明細テーブル(meisai.txt)
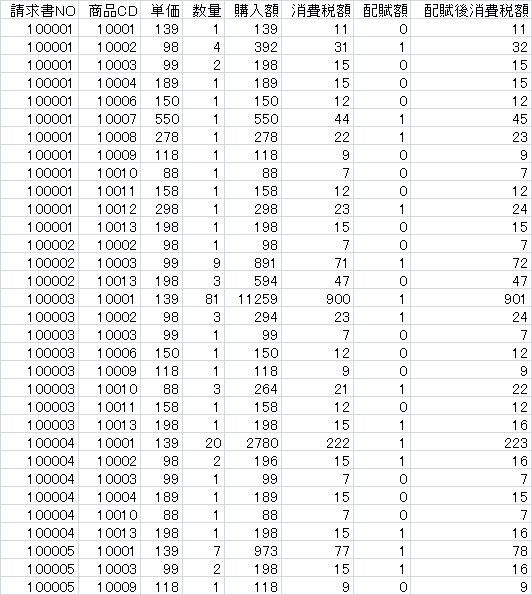
請求書テーブル(meisai.txt)
寄り道: 宇宙船演算子の話(Squeak 限定)
このコードを書いているときに気づいたのですが、いつの間にか Squeak に宇宙船演算子こと #<=> が導入されているのを発見^^;しました。
3 <=> 4 "=> -1 "
3 <=> 3 "=> 0 "
3 <=> 2 "=> 1 "
というように、他の言語と同様の動きをします。ただ、Smalltalk でソート関数は古来 [:a :b | a < b] のようなブロック(無名関数)で与えるのが慣習となっているので
# (9 6 1 2 8 7 4 5 3) sort: [:a :b | a < b] "=> #(1 2 3 4 5 6 7 8 9) "
これと宇宙船演算子との棲み分けをどうするのかと思ったら、こんなふうにするみたいです。
# (9 6 1 2 8 7 4 5 3) sort: [:a :b | a <=> b] ascending "=> #(1 2 3 4 5 6 7 8 9) "
# (9 6 1 2 8 7 4 5 3) sort: [:a :b | a <=> b] descending "=> #(9 8 7 6 5 4 3 2 1) "
宇宙船演算子(より正確には演算子ではなくセレクター。通常の言語でメソッド名のこと)を使った比較式を記述するブロックに対して、ascending もしくは descending メッセージを送ることによって、SortFunction のインスタンスが生成され、それが従来のソートブロックと同じ振る舞いをするしくみになっています。よいアイデアですね。
もちろんブロック引数同士の単純な比較だけではなく、それらにメッセージを送った返値同士の比較も行なえます。
# ((1 1) (1 2) (1 3) (2 1) (2 2) (2 3) (3 1) (3 2) (3 3)) sort: [:a :b | a first <=> b first] ascending
=> #(#(1 1) #(1 2) #(1 3) #(2 1) #(2 2) #(2 3) #(3 1) #(3 2) #(3 3))
例によって、このような単項メッセージの場合はそのセレクターであるシンボルをブロックのように振る舞わせることも可能です。
# ((1 1) (1 2) (1 3) (2 1) (2 2) (2 3) (3 1) (3 2) (3 3)) sort: #first ascending
=> #(#(1 1) #(1 2) #(1 3) #(2 1) #(2 2) #(2 3) #(3 1) #(3 2) #(3 3))
抜かり無し、といった感じですね。さらにおもしろいことに、この SortFunction は #, による合成も可能で、これにより第二キー、第三キーを指定できます。
# ((1 1) (1 2) (1 3) (2 1) (2 2) (2 3) (3 1) (3 2) (3 3)) sort: #first ascending, #second descending
=> #(#(1 3) #(1 2) #(1 1) #(2 3) #(2 2) #(2 1) #(3 3) #(3 2) #(3 1))
この仕組みを使うと、明細バッファの第5要素(購入額)による降順ソートは次にように書くことができます。
明細バッファ sorted: #fifth descending
もっとも現時点では Pharo にはこの機構はないので、上のコードを実際にこんなふうに書きかえてしまうと Pharo では動かないコードになってしまいます。
配列演算機能を使って作業の流れを見やすく書く
結論からいうと失敗しました。^^; もっと簡潔に書けると思ったのですが、なかなか難しいものですね。ということで、ネタに走りつつ書き上げたのが次のコードです。上の descending を使ったこともさることながら、後で述べるネタのカラクリのこともあって、こちらのコードはそのままでは Pharo では動きません。あしからず。
| separator dataFileName outFileNames columnNames
消費税率 入力カラム数 明細 請求書 逆引き 請求書別配賦額 消費税額小計 |
separator := Character tab.
dataFileName := 'data.utf8.txt'.
outFileNames := #('meisai.txt' 'seikyuu.txt').
columnNames := #(
(請求書NO 商品CD 単価 数量 購入額 消費税額 配賦額 配賦後消費税額)
(請求書NO 購入額 消費税額)).
消費税率 := 0.08.
入力カラム数 := 4.
明細 := (columnNames first first: 入力カラム数)
inject: Dictionary new
into: [:dic :key | dic at: key put: OrderedCollection new; yourself].
FileStream oldFileNamed: dataFileName do: [:dataFile |
| labels |
labels := dataFile nextLine subStrings: {separator}.
self assert: labels = (columnNames first first: 入力カラム数).
[dataFile atEnd] whileFalse: [
| items |
items := dataFile nextLine subStrings: {separator}.
self assert: items size = 入力カラム数.
labels with: items do: [:item :val | (明細 at: item) add: val]
]
].
明細 at: #購入額 put: (明細 at: #単価) * (明細 at: #数量).
明細 at: #消費税額 put: ((((明細 at: #購入額) * 消費税率) truncated) collect: #asString).
明細 at: #配賦額 put: (Array new: 明細 anyOne size withAll: '0') deepCopy.
請求書 := Dictionary new.
請求書 at: #請求書NO put: ((明細 at: #請求書NO) groupBy: #yourself) keys.
逆引き := [:assoc | [:値 | (明細 at: assoc value) at: ((明細 at: assoc key) identityIndexOf: 値)] ].
請求書 at: #購入額 put: (((明細 at: #購入額) groupBy: (逆引き value: #購入額 -> #請求書NO)) values collect: #sum).
請求書 at: #消費税額 put: ((請求書 at: #購入額) * 消費税率) truncated.
請求書別配賦額 := ((明細 at: #配賦額) groupBy: (逆引き value: #配賦額 -> #請求書NO)) values
collect: [:グループ | グループ sort: [:値 | ((逆引き value: #配賦額 -> #購入額) value: 値) asNumber] descending].
消費税額小計 := ((明細 at: #消費税額) groupBy: (逆引き value: #消費税額 -> #請求書NO)) values collect: #sum.
(請求書 at: #消費税額) - 消費税額小計 with: 請求書別配賦額 do: [:配賦数 :配賦額 |
(配賦額 first: 配賦数) do: [:値 | 値 become: '1' copy]
].
明細 at: #配賦後消費税額 put: (明細 at: #消費税額) + (明細 at: #配賦額).
{明細. 請求書} doWithIndex: [:table :pos |
(FileStream newFileNamed: (outFileNames at: pos) do: [:file |
(columnNames at: pos) do: [:each | file nextPutAll: each] separatedBy: [file tab].
file cr.
1 to: table anyOne size do: [:idx |
(columnNames at: pos) do: [:key | file nextPutAll: ((table at: key) at: idx) asString] separatedBy: [file tab].
file cr.
].
file
]) edit
]
順を追ってざっくり解説
このコードではカラム間で配列演算を使えるように、データをレコードごとではなくカラムごとに扱っているのがその特徴です。
まず明細テーブルを Dictionary(辞書。言語によってはハッシュやマップと呼ばれる連想配列)として用意し、データとして与えられることがわかっているカラム名をキーに、空の OrderedCollection(追記可能な配列ライクなオブジェクト)をそのキーに対応する値として準備します。次に、データファイルを読み込みながら、行をタブで分断(#subStrings:)し、各カラム(OrderedCollection)に対応する値を追加しています。
明細 := (columnNames first first: 入力カラム数)
inject: Dictionary new
into: [:dic :key | dic at: key put: OrderedCollection new; yourself].
FileStream oldFileNamed: dataFileName do: [:dataFile |
| labels |
labels := dataFile nextLine subStrings: {separator}.
self assert: labels = (columnNames first first: 入力カラム数).
[dataFile atEnd] whileFalse: [
| items |
items := dataFile nextLine subStrings: {separator}.
self assert: items size = 入力カラム数.
labels with: items do: [:item :val | (明細 at: item) add: val]
]
].
次に、購入額、消費税額を算出して明細テーブルに新たに導出したカラムとして追加します。配列演算を使って、単価×数量、購入額×消費税率で一気に算出しているところがミソです。配賦額の初期化(デフォルト値である '0' つまり「配賦なし」の設定)も行なっています。
明細 at: #購入額 put: (明細 at: #単価) * (明細 at: #数量).
明細 at: #消費税額 put: ((((明細 at: #購入額) * 消費税率) truncated) collect: #asString).
明細 at: #配賦額 put: (Array new: 明細 anyOne size withAll: '0') deepCopy.
次に請求書テーブルを作成します。請求書NO カラムは、明細テーブルの請求書NO カラムの値を #groupBy: でまとめて重複を排除したものを使います。ちなみに #goupBy: は次のように動作するメソッドです。
# (1 2 3 4 5) groupBy: [:each | each odd]
=> a Dictionary(false->an OrderedCollection(2 4) true->an OrderedCollection(1 3 5) )
結果がちょっとわかりづらいですが、#groupBy: の引数として与えたブロックを各要素について評価し、結果(この例では奇数判定 #odd の結果として返された true もしくは false )をキーに持ち、要素を返値によってグループ分けしたコレクションをそれぞれのキーに対応する値として持つ Dictionary を返してくれます。余談ですが、結果の Dictionary に keys を送るとグループ分けのキーの一覧が、values を送るとそれぞれのグループ(配列の配列)が得られます。
請求書テーブルも明細テーブルと同様に Dictionary で用意します。請求書NO カラムには、明細テーブルの請求書NO カラムの値を #groupBy: して得られたキー(重複のない請求書NO の一覧)を得てそれを使います。購入額カラムは、明細テーブルの購入額カラムの値を、請求書NO ごとに #groupBy: したものの和(#sum)を集めて(#collect:)使います。消費税額は、明細テーブルの時と同様に購入額から配列演算を使って算出します。
請求書 := Dictionary new.
請求書 at: #請求書NO put: ((明細 at: #請求書NO) groupBy: #yourself) keys.
逆引き := [:assoc | [:値 | (明細 at: assoc value) at: ((明細 at: assoc key) identityIndexOf: 値)] ].
請求書 at: #購入額 put: (((明細 at: #購入額) groupBy: (逆引き value: #購入額 -> #請求書NO)) values collect: #sum).
請求書 at: #消費税額 put: ((請求書 at: #購入額) * 消費税率) truncated.
最後は差額の算出と配賦です。まず配賦の準備。明細テーブルの配賦額の項を #groupBy: して請求書NO 別にグループ分けします。グループ内で、対応する購入額の高い順(#descending)にソートしておきます。
請求書別配賦額 := ((明細 at: #配賦額) groupBy: (逆引き value: #配賦額 -> #請求書NO)) values
collect: [:グループ | グループ sort: [:値 | ((逆引き value: #配賦額 -> #購入額) value: 値) asNumber] descending].
明細テーブルの消費税額をやはり請求書NO ごとにグループ分けして、それぞれの和をとることで消費税額小計を得ます。
消費税額小計 := ((明細 at: #消費税額) groupBy: (逆引き value: #消費税額 -> #請求書NO)) values collect: #sum.
最後に、おなじみの配列演算を使って請求書テーブルの消費税額カラムから消費税額小計を差し引き差額を算出します。この差額を配賦する分だけ配賦額項目を取得(first: 配賦数)し、そこに配付金額である 1 を代入しています。
(請求書 at: #消費税額) - 消費税額小計 with: 請求書別配賦額 do: [:配賦数 :配賦額 |
(配賦額 first: 配賦数) do: [:値 | 値 become: '1' copy]
].
明細 at: #配賦後消費税額 put: (明細 at: #消費税額) + (明細 at: #配賦額).
のこりは、各テーブルの出力の処理となります。請求書テーブルの請求書NO がソートされていないのはご容赦ください。
ちまちまレコードをはき出すオーソドックスな方法に比べて、テーブルにカラムがごそっごそっと次々と生成され追加されていく様子は元記事のエクセルでの処理を彷彿とさせて、気持ちよいものです。
と…ちょっと待て!
ちゃんとネタばらし
上の解説を読んで、たとえば他の言語で同じ処理を書こうとしてもたぶんできないと思います。そう、これはジョークコードなんです。ごめんなさい。動くことは動くのですが、いろいろな意味であまり現実的なものではありません。
まず初っぱなのデータの読み込みのところからヘンですね。配列演算を使うためにカラムに分解するのは百歩譲ってよいとして、#subStrings: で分解した文字列をそのままカラムに突っ込んでいます。請求書NO や商品CE はともかく、単価や数量は数値として扱いたいところです。
items := dataFile nextLine subStrings: {separator}.
labels with: items do: [:item :val | (明細 at: item) add: val]
にも関わらず、続く購入額の算出は問題なく処理できています。不思議ですね。
(明細 at: #単価) * (明細 at: #数量)
というのも、Squeak では数値の文字列を使って演算ができるのです。返値も文字列になる念の入れよう。なんとも恐ろしいですね。
'3' + '4' "=> '7' "
ちなみにこの機能は Pharo からは排除されています。
そんなわけで、しれっと購入額も数値の文字列でカラムに収められていることになります。
対して怪しさ満開なのが、消費税額の算出と配賦額の初期化です。前者は #asString とやってそれを #collect: していることから、配列演算で算出(購入額 × 消費税率 の #truncated )して得られた数値を、わざわざ文字列にしています。後者も文字列で '0' を与えてしまっています。もはやうっかりでは済まされませんね。
明細 at: #消費税額 put: ((((明細 at: #購入額) * 消費税率) truncated) collect: #asString).
明細 at: #配賦額 put: (Array new: 明細 anyOne size withAll: '0') deepCopy.
最後の #deepCopy はいわゆる浅いコピー(通常の #copy あるいは #shallowCopy)ではなく、要素をすべて作り直し、相互に区別可能な個別のオブジェクトとして成立させていることを意味します。これがまさに本コードのネタのミソの部分で、つまり通常数値として扱うところを、文字列にすることで同値でも区別がつくようにしているわけです。
続く #groupBy: によるグループ分けの補助関数として使われる逆引き関数において、この“仕込み”が活きてきます。
逆引き := [:assoc | [:値 | (明細 at: assoc value) at: ((明細 at: assoc key) identityIndexOf: 値)] ].
この「逆引き」という名前の関数(ブロック)は Association、つまり、キーとバリューの組からなるオブジェクト(#key -> #value で生成できる)を引数にとってコール(たとえば、逆引き value: #購入額 -> #明細書NO )することで、バリューとして与えた明細テーブルのカラム(例では購入額)の要素と同じ位置にあるキーとして与えたカラム(請求書NO )の要素を取り出す別の関数(ブロック)を返します。
この返値として与えられた関数を #groupBy: の引数として用いることで、たとえば対応する請求書NO ごとの購入額のグループ分けが可能になります。また同じ関数は、配賦額を対応する購入額を使ってソートする際にも使われています。
グループ sort: [:値 | ((逆引き value: #配賦額 -> #購入額) value: 値) asNumber] descending
ただ。数値の文字列でも比較は文字列として行なわれてしまうので、正しくソートされるように都度 #asNumber をコールして数値としての比較を強制しています。
こんなカラクリだらけだと、#become: を使ったオブジェクトの置き換えなんてかわいいものですね。^^;
(配賦額 first: 配賦数) do: [:値 | 値 become: '1' copy]
念のため #become: はオブジェクトのポインタをスワップして入れ替えるメソッドで、非即値オブジェクト限定ですがこんな事を可能にします。
| string float |
string := 'abc'.
float := 3.14.
string become: float.
^ {string. float} "=> #(3.14 'abc') "
本コードでは、購入額の多い順にソートされた配賦額のデフォルト値の '0' を配賦する分だけ '1' に置き換えることで、配賦額カラムを直接さわらずに、各要素を介した遠隔操作による代入のようなことを実現しています。ただし今回は '0' を '1' にするだけ(つまり文字列の長さは変わらない)ので、#become: まで使わずとも
(配賦額 first: 配賦数) do: [:値 | 値 at: 1 put: $1]
というように、文字オブジェクトの入れ替えでも同様の事は可能です。
まとめ
いろいろ無茶や遊びを重ねたネタコードではありますが、冒頭のオーソドックスな処理と違って、ループを意識せず、こんなふうに操作したいと思いついた処理をストレートに書き下すことはある程度できたと思います。カラム間の操作をエクセルのように書けるだけでなく、同時におのおのの値をオブジェクトとしてのアイデンティティを活用して細やかに扱えること(そしていくつか諦めたときの隔靴掻痒感)は、ライブラリでの機能拡張や DSL やマクロとも違う言語に求められる新しい側面を予見させます。
加えて、今回のような遊び心をそのままコードに落とせる Smalltalk が持つ自在感に加えて、実行時の効率面も処理系内部でよしなにしてくれる新機軸の言語が出てきてくれると個人的には言うこと無しですね。