2018-11-22更新 内容の追記、JDK 11 + Boot 2.1にアップグレード
環境
- JDK 11
- Spring Boot 2.1.0.RELEASE
- Spring Cloud Greenwich.M3
ソースコードはGitHubに公開しています。
https://github.com/MasatoshiTada/boot2-hystrix-sample
Spring Boot 2.1に対応しているSpring Cloud "Greenwich"というバージョンは、まだ正式リリースされていないので注意してください。今後、変更点が出る可能性があります。
Hystrixとは?
Netflixが開発した、Circuit Breaker(後述)をJavaで実装したライブラリです。
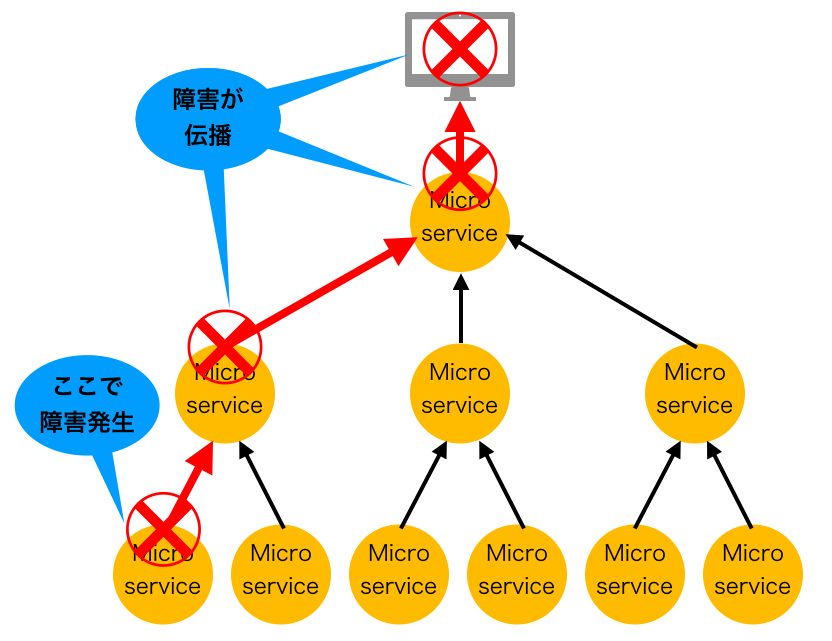
別のマイクロサービスにアクセスした際に異常なレスポンスが返ってきた場合、自分自身もエラーになってしまい、そのエラーを更に呼び出し元に返す・・・という「障害の伝播」が発生する可能性があります。
Hystrixを使うと、通信相手からエラーなどが返ってきたらそれを検知し、代わりの処理を実行することが出来ます。呼び出し元にエラーを返さないようになるため、障害の伝播を防ぐことが出来ます。
ちなみに、調べた限りだと発音は「ハイストリックス」「ヒストリックス」の両方があるみたいです。僕は普段前者を使っています。
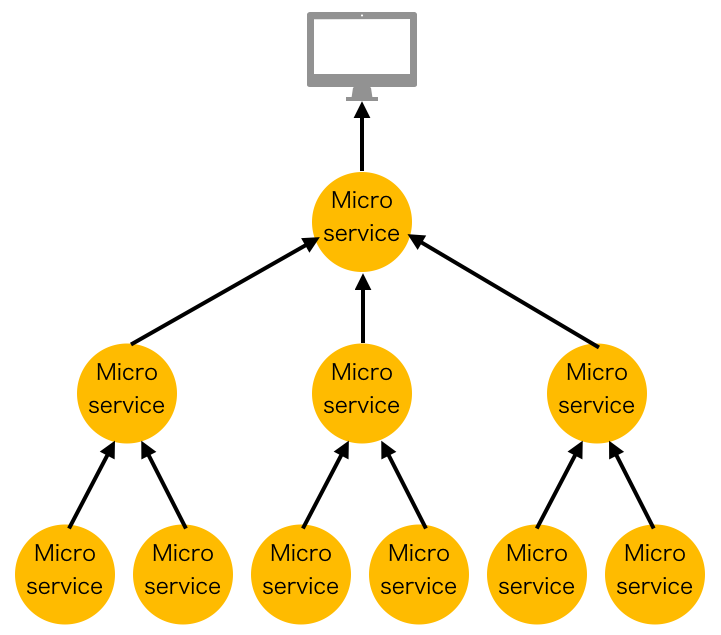
正常時の図
異常時の図
10個あるマイクロサービスのうち1つだけに障害が発生しても、それが全体に伝播してしまいます。
Circuit Breakerって何なの?
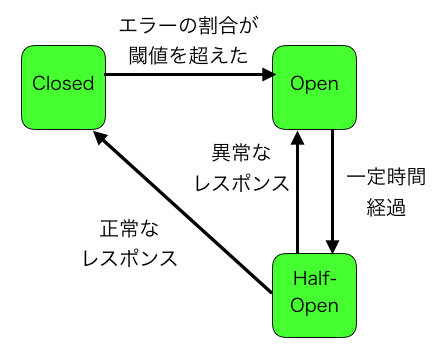
さて、Hystrixを理解する上で難しいのが「Circuit Breakerって結局何なの?」ということです。よく上の画像のような図が説明で出てきますが、この図と「エラー時にフォールバックメソッドを実行する」がどう関係してるのか分かりづらいと思いますので、解説します。
Closed
まず、これが初期状態です。電気回路が閉じていて(=すべての導線がつながっていて)正常に動作するように、プログラムの処理が正常に実行されている状態です。つまり、フォールバックではなく本来のメソッドが実行されています。
ただし、閾値(後述)を超えない程度にエラーが起こっている場合もあります。本来のメソッド内でエラーが起こった場合は、フォールバックメソッドが実行されます。
Open
エラーの発生確率が閾値を超えると、ClosedからOpen状態に遷移します。これは、電気回路が開いていて(=どこかで導線が切れていて)正常に動作しない状態です。
デフォルトの閾値は、「10秒間に20回以上リクエストして、エラーの発生確率が50%以上」です(各数値は、後述のプロパティで変更可能です)。
Open状態になると、本来のメソッドは一切実行されず(「reject」と言われる)、いきなり問答無用でフォールバックメソッドが実行されます。
閾値の計算方法については、Spring Cloudの公式リファレンスのこの部分に書かれています。
Half-Open
Open状態に遷移してから一定時間が経つと、Half-Open状態に遷移します(デフォルトは5秒。後述のプロパティで変更可能)。
Half-Openになると、Closedと同様に本来のメソッドが1回だけ実行されます。そして、その処理が正常に成功したらClosedに遷移し、失敗したらOpenに遷移します。
プロジェクトの準備
今回は、下記5つのマイクロサービスを作成します。

producer
固定のJSONを返すAPIです。
client
producerにリクエストしてJSONを受け取り、そのデータをHTMLで表示します。このマイクロサービスにHystrixを入れます。
client2
clientとほぼ同じです。クラス名などを少しだけ変えています。
hystrix-dashboard
各マイクロサービスのCircuit Breakerの情報を、一覧で見ることが出来ます。デフォルトでは1インスタンスごとにしか情報を見ることが出来ませんが、後述のTurbineを併用することで、複数インスタンスの情報を同時に見ることができます。Netflix OSSです。
eureka-server
マイクロサービスの名前解決を行うEureka Serverです。Netflix OSSです。
turbine
複数のマイクロサービスからのHystrixに関する情報を1つにまとめてHystrix Dashboardに転送します。Netflix OSSです。
フォールバックの概要
Hystrixを入れるのはclientです。
依存性
clientには、下記2つの依存性を加える必要があります。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
spring-cloud-starter-netflix-hystrixがHystrixのStarterです。
spring-boot-starter-actuatorは、あとでHystrix Dashboardと連携するために必要です。
spring-cloud-starter-netflix-eureka-clientは、あとでTurbineと連携するために必要です。
Netflix系StarterのartifactIdは、Spring Boot 1.xの頃と変わっているので注意してください。
Hystrixの有効化
main()メソッドがあるクラス、またはJava Configクラスに@EnableCircuitBreakerを付加します。
@EnableCircuitBreaker // コレを付ける!
@SpringBootApplication
public class ClientApplication {
public static void main(String[] args) {
SpringApplication.run(ClientApplication.class, args);
}
@Bean
@LoadBalanced
public RestTemplate restTemplate(RestTemplateBuilder builder) {
return builder.build();
}
}
フォールバックメソッドの指定
Serviceクラスでフォールバックを指定します。
@Service
public class HelloService {
private static final Logger logger = LoggerFactory.getLogger(HelloService.class);
private final RestTemplate restTemplate;
public HelloService(@LoadBalanced RestTemplate restTemplate) {
this.restTemplate = restTemplate;
}
// このアノテーションを付ける!
// fallbackMethod属性にフォールバック先のメソッド名を書く!
@HystrixCommand(fallbackMethod = "executeFallback")
public HelloDto execute(String prefix) {
HelloDto helloDto = restTemplate.getForObject(
"http://producer/api/hello", HelloDto.class);
helloDto.setMessage(prefix + " : " + helloDto.getMessage());
return helloDto;
}
// フォールバックメソッド!
// execute()メソッド内で例外が発生した場合にこちらが実行される
public HelloDto executeFallback(String prefix, Throwable throwable) {
logger.error(throwable.getMessage());
HelloDto helloDto = new HelloDto();
helloDto.setMessage(prefix + " : This is default message");
return helloDto;
}
- フォールバックメソッドの作り方ルール
- フォールバックメソッドは同一クラス内に作る
- メソッド名:
fallbackMethod属性に指定した名前にする - 戻り値:同じまたはサブタイプ(サブクラスとか)
- 引数:同じ、プラス最後の引数にThrowableを指定でき、元のメソッドで発生した例外を取得できる
- 以上のルールを守れば、中ではどのような処理をしてもOK
- フォールバックメソッドのフォールバックメソッドも作成可能(下記)
@HystrixCommand(fallbackMethod = "fallback1")
public String doSomething() {
return ...;
}
@HystrixCommand(fallbackMethod = "fallback2")
public String fallback1() {
return ...;
}
public String fallback2() {
return ...;
}
フォールバックメソッド内で何をする?
書籍やネット上のサンプルだと、通信相手の「レコメンド」マイクロサービスが落ちたら固定の商品リストを返す、というものばかりです。
固定値でも良い場合もあるかもしれませんが、ビジネスの要件に沿って適切な処理を行う必要があります。
上記のレコメンドの例で思いつく限りでは、下記のようなフォールバックが考えられます。
- 売上ランキングTOP10の商品リストを返す
- ただし、売上ランキングマイクロサービスからもエラーが返ってきた時のことも考えなければならない
- レコメンドを取得したら毎回キャッシュし、フォールバック時は直前のアクセスでキャッシュした商品リストを返す
- ただし、キャッシュするためのKey-Value Storeをどうするか考えなければならない
- 自アプリが複数インスタンスで動いている可能性があるので、ローカルキャッシュはNG
- また、そのKVSからエラーが返ってきた時のことも考えなければならない
- ただし、キャッシュするためのKey-Value Storeをどうするか考えなければならない
- 直前に購入した商品と同じカテゴリの商品リストを返す
- ただし、購入履歴マイクロサービスが(以下略
- ただし、商品カタログマイクロサービスが(以下略
とにかく、技術的に出来ることの中から売上・利益を最大化する手段を選びましょう。
状況によっては呼び出し元にもエラーを返すしかない場合もあるでしょう。その場合は、呼び出し元の方でフォールバックしてもらうことになりますが、エンドユーザーにエラー画面を見せるしか無い状況もあるでしょう。
代表的なプロパティの設定
プロパティの指定方法
@HystrixCommandのcommandProperties属性に、@HystrixPropertyアノテーションを配列形式で指定します。
@HystrixCommand(fallbackMethod = "executeFallback"
, commandProperties = {
@HystrixProperty(name = "execution.timeout.enabled", value = "true")
, @HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "1000")
}
)
public String hello(String message) { ... }
execution.timeout.enabled
"true"(これがデフォルト)にすると、通信相手からのレスポンスが一定時間経っても返ってこなかった場合に、例外になります。
execution.isolation.thread.timeoutInMilliseconds
タイムアウトが有効な場合に使われる、タイムアウト時間をミリ秒単位で設定します。デフォルトは"1000"(=1秒)です。
metrics.rollingStats.timeInMilliseconds
リクエスト数やエラー数をカウントする時間の幅(=ウィンドウ)です。デフォルトは"10000"(=10秒)です。
circuitBreaker.requestVolumeThreshold
ウィンドウサイズ内のリクエスト数がこの数値以上になると、Circuit Breakerがopen状態にすることを検討しはじめます。言い換えると、ウィンドウサイズ内のリクエスト数がこの数値未満の場合、全リクエストがエラーになってもOpenには遷移しません。
デフォルトは"20"です。
circuitBreaker.errorThresholdPercentage
エラーが返ってきた割合がこの数値(%)以上になると、Circuit Breakerがopen状態(後述)になります。デフォルトは"50"(%)です。
circuitBreaker.sleepWindowInMilliseconds
Open状態になってからHalf-Open状態に遷移するまでの時間をミリ秒で指定します。デフォルトは"5000"(=5秒)です。
その他のプロパティ
下記のHystrixのドキュメントを参照してください。プロパティ名は、Wikiの目次に書いてある名前を指定します。
https://github.com/Netflix/Hystrix/tree/master/hystrix-contrib/hystrix-javanica#configuration
https://github.com/Netflix/Hystrix/wiki/Configuration
更新系の処理ではどうする?
ここまでの例は、すべて検索系の処理でした。
では、更新系処理の失敗時はどうすればいいのでしょうか?例えば注文登録の失敗時に、デフォルトの値を返しても意味がありません。また、DBがマイクロサービスごとに分割されているのでトランザクションも使えません。
更新系処理でのメッセージキューの利用
それらの代替としてよく利用されるのが、RabbitMQなどのメッセージキューです。
例えば注文登録を「注文登録イベント」としてメッセージキューに渡し、色んなマイクロサービスがそこからイベントを「購読(サブスクライブ)」します。
下記のブログ記事が参考になります。
マイクロサービスアーキテクチャにおけるオーケストレーションとコレオグラフィ(@kawasimaさん)
https://qiita.com/kawasima/items/17475a993e03f249a077
メッセージキュー利用時の考慮点(思いつく限り)
- メッセージキュー自体の運用・管理・クラスタリングなどはどうするか?
- 本当にメッセージキューだけでデータ整合性が保てるのか?
- メッセージを2回受け取ったときに、2重登録をどうやって防ぐか?
- メッセージが来なかったらどうするか?
- ...など
Hystrix Dashboardで監視する
Hystrix Dashboardを使うと、指定したマイクロサービスのCircuit Breakerの状態をリアルタイムで監視することが可能です。
clientのセッティング
前述の通り、spring-boot-starter-actuatorを依存性に加える必要があります。こうすると、Dashboardで可視化するCircuit Breaker情報を公開するActuatorエンドポイント(/hystrix.stream)が作られます。
以前の記事「Spring Boot 2.0のActuator、とりあえず動かすために知っておきたい変更点3つ」で説明した通り、エンドポイントを公開する設定をapplication.propertiesに記述する必要があります。
management.endpoints.web.exposure.include=hystrix.stream
完成したら、clientとproducerを起動しておきましょう。
hystrix-dashboardを作る
依存性はこちら。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix-dashboard</artifactId>
</dependency>
main()メソッドのあるクラスに@EnableHystrixDashboardを付加します。
@EnableHystrixDashboard // コレを付ける!
@SpringBootApplication
public class HystrixDashboardApplication {
public static void main(String[] args) {
SpringApplication.run(HystrixDashboardApplication.class, args);
}
}
起動し、ブラウザで http://localhost:8100/hystrix にアクセスします。
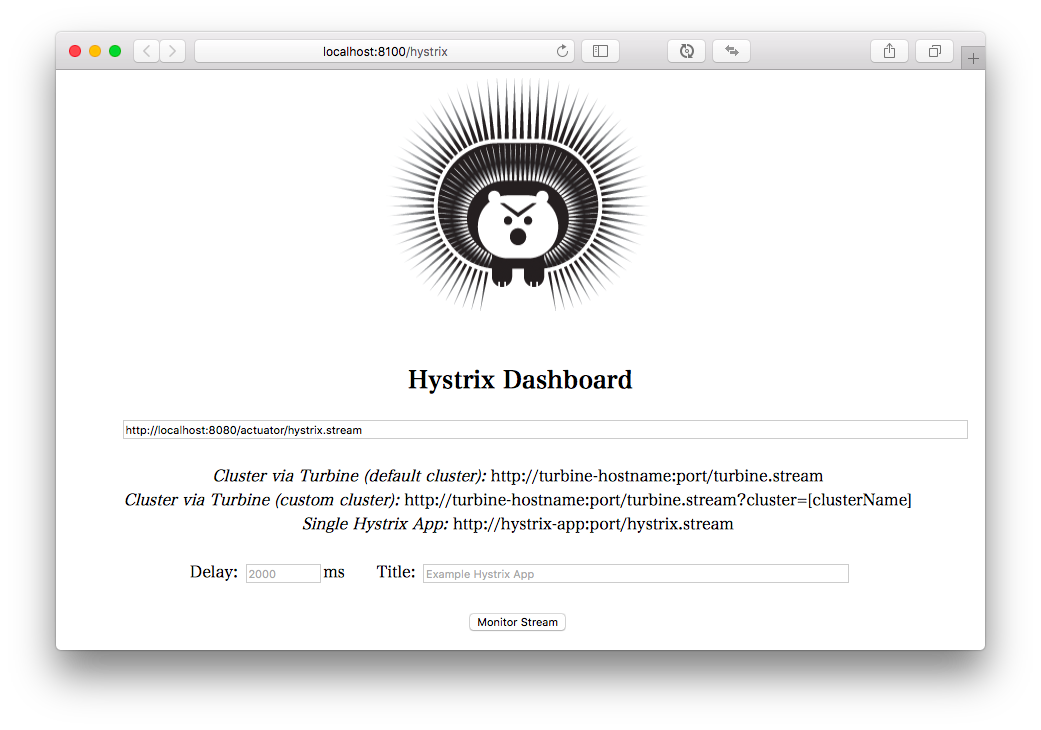
一番上のテキストボックスに http://localhost:8080/actuator/hystrix.stream と入力して[Monitor Stream]ボタンをクリックすると、ダッシュボードが表示されます。
ブラウザの別ウィンドウで http://localhost:8080/ にアクセスし、何回かリロードしましょう。
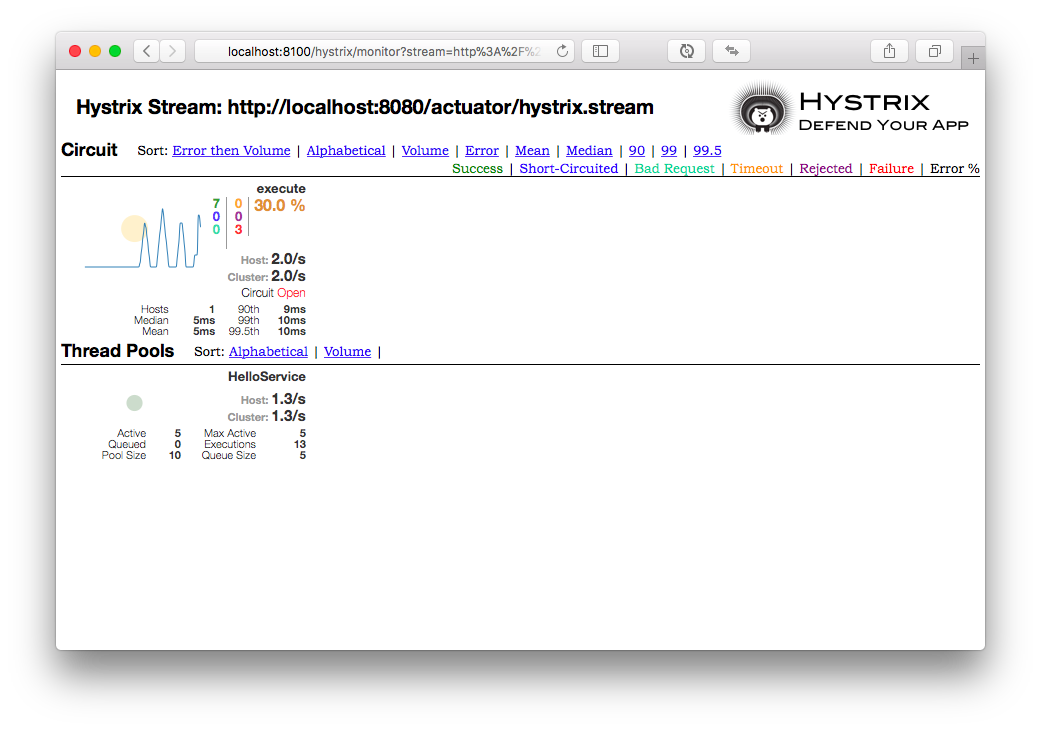
Turbineでまとめて監視する
Hystrix Dashboardには、1つのマイクロサービスの1インスタンスしか監視できないという弱点があります。
複数のマイクロサービスやインスタンスをまとめて監視できるように、Hystrix Streamを1つにまとめる役割を担うのがTurbineです。
そして、Hystrix DashboardからはTurbineにアクセスしてもらいます。

監視対象の各マイクロサービスに必要な設定
1つのHystrix Dashboardで監視できるマイクロサービスの集まりのことを、Turbineでは「cluster」と呼びます。
このcluster名は、各マイクロサービスでEurekaのメタ情報として設定する必要があります。
eureka.instance.metadata-map.の後に任意のメタ情報名を指定し(下記の場合はturbine-cluster)、右辺に任意のcluster名を指定します(下記の場合はMY_CLUSTER)。
eureka.instance.metadata-map.turbine-cluster=MY_CLUSTER
Turbineを作る
pom.xmlには、下記の依存性を追加します。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-turbine</artifactId>
</dependency>
main()クラスには@EnableTurbineを付加します。
@EnableTurbine // このアノテーションを付ける!
@SpringBootApplication
public class TurbineApplication {
public static void main(String[] args) {
SpringApplication.run(TurbineApplication.class, args);
}
}
application.propertiesにTurbineに関する設定を記述します。
server.port=8200
# Eureka ServerのURL
eureka.client.service-url.default-zone=http://localhost:8761/eureka
# Turbineで扱うcluster名(カンマ区切りで複数指定可能)
turbine.aggregator.cluster-config=MY_CLUSTER
# Turbineで扱いたい各マイクロサービスのspring.application.name
turbine.app-config=client,client2
# 各マイクロサービスがcluster名としてEurekaに登録したメタ情報名
turbine.cluster-name-expression=metadata['turbine-cluster']
# Eurekaから取得した「サーバー名:ポート番号/」の後ろに付けるURLサフィックス
turbine.instanceUrlSuffix.MY_CLUSTER=actuator/hystrix.stream
turbine.aggregator.cluster-config
このTurbineで監視したいcluster名を指定します。ここに記述しないと監視対象に出来ません。
カンマ区切りで複数指定可能です。
turbine.app-config
EurekaからIPアドレス+ポート番号を取得する対象のアプリケーション名です。各マイクロサービスのspring.application.nameに指定した値です。
カンマ区切りで複数指定可能です。
turbine.cluster-name-expression
EurekaのInstanceInfoクラスルートからのSpELを記述できます。
今回はMapであるmetadataフィールドからturbine-clusterがキーの値を取得しています。この値は、先ほど各マイクロサービスのapplication.propertiesで指定したeureka.instance.metadata-map.turbine-clusterの値です。
このプロパティを指定しない場合、デフォルトでappNameフィールド(spring.application.nameを大文字にした文字列)から値を取得するようになっています。
turbine.instanceUrlSuffix.MY_CLUSTER
デフォルトでは、Eurekaから取得した「サーバー名+ポート番号」の後ろに/hystrix.streamをくっつけたURLで、各マイクロサービスの/hystrix.streamエンドポイントにアクセスします。
しかし、Spring Boot 2.0では/actuator/hystrix.streamとなるため、デフォルトのままではHystrix Streamを取得できません。
このURLサフィックスを上書きするためのプロパティがturbine.instanceUrlSuffix.{cluster-name}です。{cluster-name}の部分には、上記のようにcluster名を指定します。
ちなみに、turbine.instanceUrlSuffix=/actuator/hystrix.streamとすると、clusterが複数あった場合のデフォルトのURLサフィックスになります。
Spring Cloud Finchleyの正式バージョンでは、
turbine.instanceUrlSuffixプロパティは必要無いかもしれません。現在、/actuator/hystrix.streamをデフォルトのURLサフィックスにする作業が進んでいます。詳細はこちらを参照してください -> https://github.com/spring-cloud/spring-cloud-netflix/commit/9b1d3b36fd09c7d7aadf472827575d96fa0d7a41
実行
eureka-server -> producer -> client -> client2 -> turbine -> hystrix-dashboardの順に起動します。
hystrix-dashboardには、http://turbineのサーバー名/turbine.stream?cluster=cluster名を指定します。

/turbine.streamは、Actuatorエンドポイントではなく、TurbineStreamServletというサーブレットクラスがレスポンスしています。
すると、指定したclusterに属する全マイクロサービス・全インスタンスの情報を見ることができます。
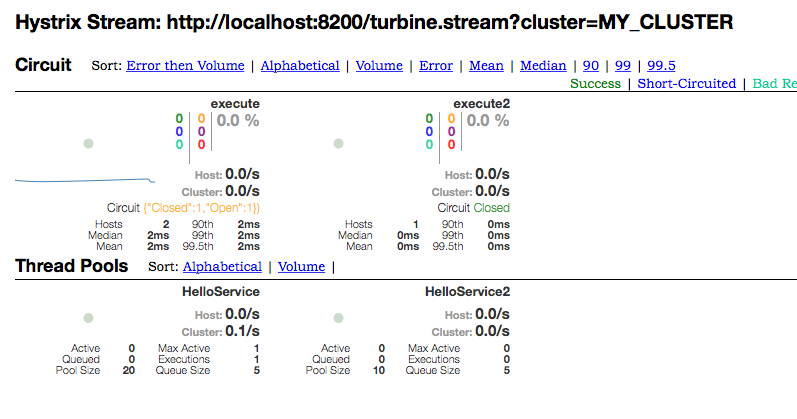
上記のスクショの例では、clientを2インスタンス、client2を1インスタンスで実行しています。
文字が小さいのですが、executeのHostsが「2」になっていることが分かります。そして、片方のインスタンスがClosed、もう片方がOpenになっています。
TurbineはEureka必須?
Spring Cloudのデフォルトの状態ではEurekaから監視対象の各マイクロサービスの情報を取得しますが、Turbineのドキュメントによると他のService Discovery技術を使っていてもOKのようです(未検証)。
TurbineがHystrix Streamにアクセスする際の認証は出来ないっぽい

調べた限りでは、Turbine単体では出来なさそうです。
Turbineは、Apache HttpClientを使って/hystrix.streamエンドポイントにアクセスしているのですが、そこにBASIC認証なりOAuth 2.0なりを挟み込む手段は無さそうでした(僕のソースリーディング力不足かもですが・・・)。
BASIC認証機能を追加するためのプルリクエストが取り込まれてはいるものの、対象バージョンがTurbine 2.xとなっています。詳細は後述しますが、今回のバージョンは1.xであり、かつ2.xは未だに正式リリースされていません。
となると、他の手段でセキュリティをかけるしか無さそうです。
(Actuatorのポート番号はアプリ側と別にして、AWSのApplication Security Groupを使うとか?)
Turbineは古い?
Spring Cloud Finchley M8で使われているTurbineのバージョンは、1.0.0です。

GitHubリポジトリを確認すると、Turbine自体の開発は2015年以降ストップしています(2018年3月現在)。
Maven Centralを確認すると、1.0.0以降、正式バージョンはリリースされていないようです。
これから先、どうなるんでしょうね・・・😅
Hystrixとスレッド
コントローラーからビジネスロジック(@HystrixCommand付き)を実行した場合、ビジネスロジック(およびフォールバックメソッド)は、コントローラーとは別のスレッドで実行されます。
2018-11-22 10:51:57.254 INFO 2161 --- [nio-8080-exec-4] c.e.client.controller.HelloController : コントローラーを実行します・・・
2018-11-22 10:51:57.347 INFO 2161 --- [-HelloService-1] com.example.client.service.HelloService : execute()を実行します・・・
2018-11-22 10:51:57.348 INFO 2161 --- [-HelloService-1] com.example.client.service.HelloService : user = user
2018-11-22 10:51:57.377 ERROR 2161 --- [-HelloService-1] com.example.client.service.HelloService : エラー!!!フォールバックしています。 Prefix = PREFIX =====
2018-11-22 10:51:57.380 ERROR 2161 --- [-HelloService-1] com.example.client.service.HelloService : 元のメソッドで発生した例外:
org.springframework.web.client.HttpServerErrorException$InternalServerError: 500 null
...(スタックトレース省略)...
2018-11-22 10:51:57.380 ERROR 2161 --- [-HelloService-1] com.example.client.service.HelloService : user = user
2018-11-22 10:51:57.382 INFO 2161 --- [nio-8080-exec-4] c.e.client.controller.HelloController : コントローラーが終了します・・・
[ ]の中がスレッド名です。
Spring Security対策
これで困るのは、Spring Securityを使っていた場合です。Spring Securityは、ユーザー情報などの入れ物であるSecurityContextがスレッドに紐付けられているため、別スレッドでは取得できません。
@HystrixCommand(fallbackMethod = "fallback")
public void method() {
SecurityContext securityContext = SecurityContextHolder.getContext();
Authentication authentication = securityContext.getAuthentication();
String userName = authentication.getName(); // ぬるぽ
}
@HystrixCommandメソッドを実行しているスレッドにSecurityContextを共有するには、application.propertiesに下記のプロパティを追記します。
hystrix.shareSecurityContext=true