Dynatraceは、無限の観測性、セキュリティ、ビジネス分析のための新しいデータレイクハウステクノロジーであるGrailを発表します。Grailは、Dynatrace Software Intelligence Platformの技術的なコアを根本的に強化するものです。マルチクラウドやクラウドネイティブアーキテクチャにより、データ量やアプリケーション環境、コンポーネント間の依存関係の複雑さは爆発的に増加しています。お客様は、データの保存、コンテキスト化、クエリを行い、即座に洞察を得て、自動化を推進するための効果的な方法を必要としています。
少し前のことですが、ボストン近郊のレストランで3人のDynatraceの同僚が食事をしながら、企業におけるデータの課題の増加について議論しました。この問題の核心は、企業内で収集されるデータの量と複雑さの急激な増加です。
既存の観測・監視ソリューションには、大量のデータの保存、保持、クエリ、分析に関して、組み込みの限界があります。これらのテクノロジーは、現代の企業のニーズ - データから有用な知見と真の価値を得ること - に対応するには不十分です。そのため、何か革新的なことをする必要がありました。こうして、Grailは誕生しました。
それは、すべてのデータをアクセス可能にして、リアルタイムで正確な答えを提供し、Davis AIによって収集された洞察を高め、自動化を推進するために、価値あるものにするというものです。この目標は、観測可能な取り組みに限定されるものではありません。Grailは、セキュリティデータだけでなく、ビジネスアナリティクスデータやユースケースもサポートする必要があります。このことを念頭に置き、Grailはコストへの影響を最小限に抑えながら、3つの主要な目標を達成する必要があります。
- データの追加と分析の両方で、膨大な量のデータに対応し、管理することが可能
- 異なる独立したデータタイプとして動作
- データに文脈を持たせ、トポロジーメタデータでリッチ化
Grailの基本的なアーキテクチャ
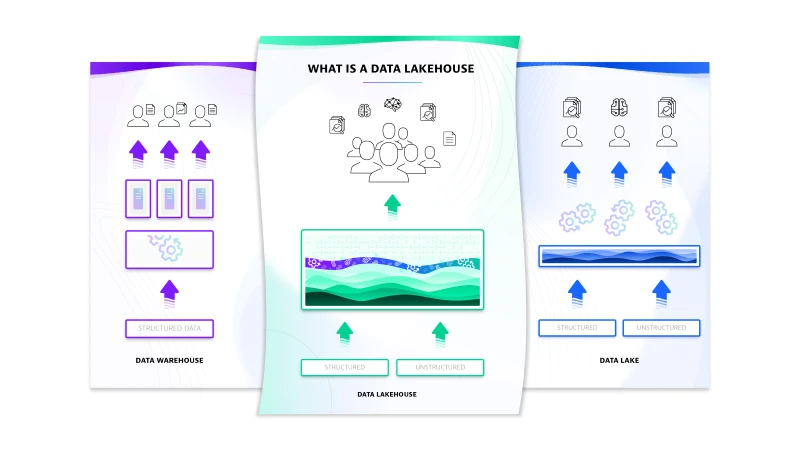
前述の原則は、もちろん全体のアーキテクチャに大きな影響を及ぼします。その本質は、Grailはデータレイクハウスである。しかし、それは何を意味するのでしょうか。データレイクハウスは、データウェアハウスの利点とデータレイクの利点を組み合わせたものです。データウェアハウスは、特定のユースケースを想定して構築・最適化されており、構造化されたデータに対する価値ある洞察を提供し、大規模なデータサイズを処理することができます。これに対してデータレイクは、構造化されていないさまざまな種類のデータや半構造化データに対して、どの程度まで扱えるのか不明ですが、オープン性と柔軟性を備えています。このオープン性は、データ品質の低下を伴い、データレイク上で実行される分析の価値を制限することになります。
データレイクハウスは、このような制限に対処し、まったく新しいアーキテクチャを導入しています。このアーキテクチャでは、データレイクで使用される低コストのクラウドストレージシステム上に、データウェアハウスモデルから取り入れた豊富なデータ管理・分析機能を提供します。
Dynatraceにとって、これは新しい旅の始まりであり、より強力なオファリングを提供する予定です。このアーキテクチャを実現し、データレイクハウスを構築するために、私たちはストレージと分析およびコンピューティングを切り離す必要がありました。このデカップリングにより、データとストレージのフォーマットのオープン性が確保され、またコンテキストに沿ったデータの保存が可能になります。さらに、Dynatraceの因果関係人工知能であるDavis® AIを搭載したリッチな分析レイヤーを構築し、比類ないスピードで洞察を提供するクエリエンジンを作成します。
その結果、私たちは3つの異なるビルディングブロックを持つGrailを作り、それぞれが特別な義務を果たしているのです。
- 収集と処理: 高性能な自動データ収集と処理
- 保持: 観測可能なセキュリティデータ専用に構築されたストレージソリューション
- 分析: ペタバイト級のデータからリアルタイムに情報を引き出し、真の価値を得る
Grailによるデータの収集と処理
Grailは当初から、大量のデータを管理するために高速かつスケーラブルに構築されています。クラウドネイティブアーキテクチャをベースに、クラウドのために構築されています。そのため、大規模な拡張が可能です。これは、毎日数百ペタバイトの追加をサポートするように設計された、非常に効率的なインジェストパイプラインから始まります。インジェストパイプラインにデータを追加するために、お客様はDynatrace® OneAgentまたはOpenTelemetry、Prometheus、Micrometerなどのオープンソースのオブザーバビリティツールを利用することも可能です。
Dynatrace OneAgentは、設定を必要とせず、アプリケーションスタックの各階層から自動的にデータを収集する唯一のエージェントです。インストール後わずか数分で、フロントエンドからバックエンドまで、あらゆる複雑なITインフラストラクチャを監視するために必要なすべてのパフォーマンスメトリクスとログデータを取得できます。このユニークなエンドツーエンドのデータ収集とSmartscape®トポロジーマッピングにより、Grailは利用可能なすべてのデータをコンテキストに沿って取得し、手動またはAI駆動の分析タスクに対応できるようになります。
Grailによるデータ保持
保存するデータと削除するデータを選択する必要はなく、異なるストレージ階層を管理する際の頭痛の種もなくなります。セキュリティ侵害の際、データを収集した後に削除されたり、利用できなくなったりして、根本的な原因を効果的に特定できないまま、オペレーションルームでフォレンジック・リサーチを行ったことを覚えていますか?データが再び蓄えられるのを待った日数を覚えていますか?
このシナリオは過去のものです。干し草の中から針を探す必要はありません。Grailのユニークなアーキテクチャのおかげで、すべてのデータを取り込み、保存する余裕があります。一度取り込まれたデータは、最大3年間保持され、分析レイヤーからアクセス可能な状態で、お客様のニーズと個々の設定に基づき、完全に柔軟に対応します。データは、私たちの強力なDynatrace Query Languageによって、インデックスを必要とせずにリアルタイムで利用できます。
インデックス作成不要のハイパフォーマンスな分析
従来のデータ管理および観測可能なソリューションは、スキーマとインデックスに依存し、高性能な分析を保証していました。スキーマとは、データを特定のフィールドに整理するための固定的な定義です。
イベント自体にエラーコード、重要度、タイムスタンプなどのフィールドがあるログイベントを考えてみましょう。インデックスは、データ検索操作の速度を向上させる高性能な構造です。通常、インデックスはインジェスト時にスキーマで定義されたフィールドに作成される。この手法はスキーマ・オン・ライトと呼ばれる。
スキーマ・オン・ライトはしばらくの間うまく機能していましたが、その限界に達しました。このコンセプトには、今日の増え続けるデータの複雑さと量を考えると、大きなデメリットがあります。データは全く利用できないか、多くの労力を費やして再インデックス化されるまで何時間も、あるいは何日も待つ必要があるのです。
グレイルのスキーマオンリードにより、ITチームはデータをネイティブフォーマットで保存することができます。つまり、データの準備はインジェストではなく、クエリを実行する際に行われます。これにより、インジェストパイプラインのセットアップ時にスキーマで定義されたフィールドに制限されることなく、ネイティブな構造のデータに対していつでも任意のクエリを実行できるため、より高い柔軟性が実現されます。
さらに、Grailはインデックスレスでもあります。インデックスはインデックスされたデータに対して高いクエリ性能を約束しますが、コストが高いため、そのサイズには制限があります。そのため、一般にデータはインジェスト時にストリップまたはドロップされ、インデックスのサイズを最小化します。また、データは一定の年齢に達すると、インデックスからコールドストレージに移されます。その結果、チームはコールドデータを分析に使用することができず、クエリに追加する前にデータのインデックスを再作成する必要があります。このプロセスでは、クエリを開始する前にインデックスの作成が終了するのを待つ必要があるため、柔軟性が損なわれます。
これらの概念とは逆に、Grailは取り込まれたあらゆるデータに問い合わせを行い、リアルタイムに回答を提供することができます。
超並列処理(MPP)エンジンのおかげで、どんなクエリでも実行でき、瞬時に結果を取得することができます。Dynatrace Query Language (DQL)の力を使って、Grail内に保存され利用可能なすべてのデータを検索、解析、フィルター、ソート、集計します。その親しみやすいコンセプトのため、習得が簡単です。SQL以外の構文を理解し、データサイエンティストでなくとも、独自の複雑なクエリを書くことができます。オンザフライの解析は、正規表現を使用するような類似のアプローチよりも5~10倍速く、あらゆるサイズのデータに対していつでもどんなクエリでも可能にします。DQLは、観測可能性とセキュリティのユースケースに特化して構築されています。AIを活用した回答や自動化を可能にしながら、あらゆるアドホックな分析に対して最大限の柔軟性と制御を提供します。
ボストンで始まったことが、ついにGrailで実現
Dynatrace Grailは、真に現代のエンタープライズを可能にします。指数関数的に増え続けるデータは、観測可能性、セキュリティ、ビジネスデータの収束によって大きく左右されます。Grailは、このような分析のために構築されており、ストレージではありません。あらゆる質問に対応し、正確かつ迅速な回答を提供し、AIによる意思決定とインテリジェントな自動化をリアルタイムに実現します。
Grailを使い始めましょう データから新しい洞察と価値を得ながら、アドホックにデータを掘り下げることが大好きになるはずです。