Unicodeの異体字セレクター(variation selectors)を使い、ユニコード文字列内に隠し情報を埋め込む方法です。
異体字セレクターとは
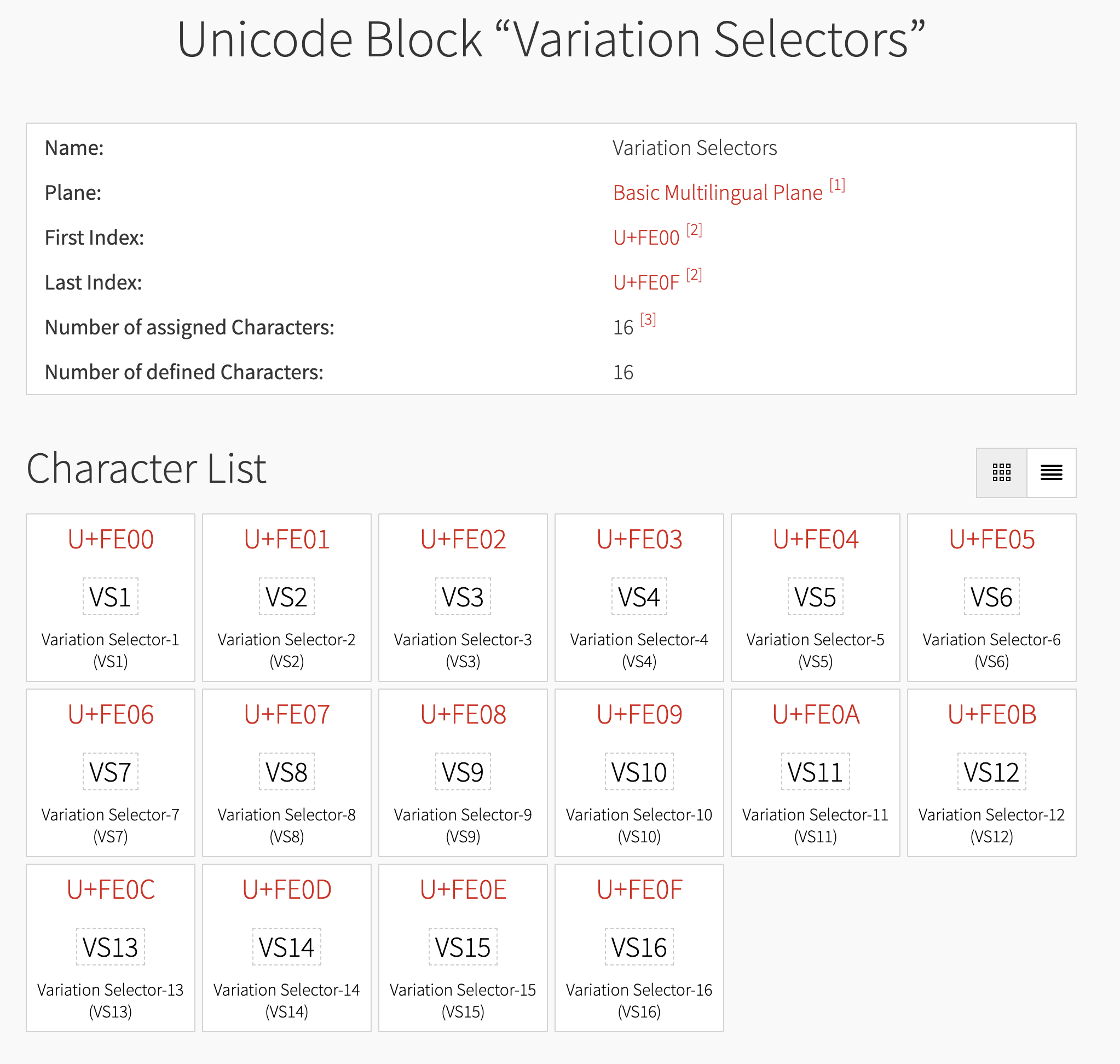
- 異体字セレクターは、文字の字体を詳細に指定するモディファイアのようなもの
- 異体字セレクターは16種類のコードポイントがある(FE00~FE0F)
仕組みの概要
- 隠したい文字列(hidden)を文字単位にバラす (例:
js→j,s) - 文字ごとに16進数に変換する (例:
j→6A) - その16進数をひと桁ずつ異体字セレクターのコードポイントにマッピングする
- (例:
6→FE06,A→FE0A)
- (例:
- 異体字セレクターの配列をひとつの文字列にまとめなおす
- 最後にそれを埋め込み先の文字列(body)に混ぜ込んで隠す。
よくあるユニコードステガノグラフィーとの違い
ゼロ幅文字を使ったステガノグラフィー
次のようなゼロ幅空白文字を用いたステガノグラフィーがあります。
- U+200B ZERO WIDTH SPACE
- U+200C ZERO WIDTH NON-JOINER
- U+200D ZERO WIDTH JOINER
- U+200E LEFT-TO-RIGHT MARK
- U+202A LEFT-TO-RIGHT EMBEDDING
ゼロ幅文字は種類が少ないので、容量が大きくなりがちです。また、ウェブサービスやアプリによっては、除去されてしまったり、?マークで表示されてしまったりします。
似た文字へ置き換えるステガノグラフィー
アルファベットは見た目が同じなのに違うコードポイントのものがあります。たとえば、ラテン文字a(U+0061)とキリル文字а(U+0430)は見た目の区別が難しいですが、コードポイントが異なります。一定の法則に基づいてラテン文字を類似したアルファベットに置き換えることで、情報を隠しこむことができます。
この方法弱点は、文字が別の文字におきかわるため、検索ができなかったり、エディタ上ではスペルチェックに引っかかることがあります。また、日本語のようなアルファベットがあまり出てこないテキストでは、情報を十分に埋め込めるだけのアルファベットが無い場合があります。
異体字セレクターステガノグラフィーのJSでの実装例
エンコーダーの実装
function encode(body, hidden) {
return (
"\u{FEFF}" +
[...hidden]
.flatMap((c) => [...c.charCodeAt(0).toString(16)])
.map((s) => String.fromCodePoint(0xfe00 + Number.parseInt(s, 16)))
.join("") +
body
);
}
デコーダーの実装
function decode(str) {
let hidden = "";
const body = str.replace(
/\uFEFF[\uFE00-\uFE0F]+/u,
([zeroWidthNoBreakSpace, ...variationSelectors]) => {
hidden += variationSelectors
.map((c) => (c.codePointAt(0) - 0xfe00).toString(16))
.reduce((acc, current, index, arr) => {
return index % 2 === 0 ? [...acc, arr.slice(index, index + 2)] : acc;
}, [])
.map(([a, b]) => String.fromCharCode(Number.parseInt(a + b, 16)))
.join("");
return "";
}
);
return [body, hidden];
}
使用例
「かくれみの」という文字列に「secret」というテキストを隠しこむ例です。
const encoded = encode("かくれみの", "secret");
encodedは出力するとUIでの見た目は「かくれみの」にしか見えず、「secret」はうまく隠れています。
console.log(encoded);
//=> ︇︃︆︅︆︃︇︂︆︅︇︄かくれみの
文字数(コードポイント数)を数えてみると、18になります。「かくれみの」だけだったら5のはずで、増えた13文字分が「secret」を保持する部分になります。
console.log([...encoded].length);
//=> 18
文字列がどういうコードになっているか調べてみると、
console.table(
[...encoded].map((char) => [char, char.codePointAt(0).toString(16)])
);
次のように文字列の冒頭が異体字セレクターになっているのがわかります。
┌─────────┬──────┬────────┐
│ (index) │ 0 │ 1 │
├─────────┼──────┼────────┤
│ 0 │ '' │ 'feff' │
│ 1 │ '︇' │ 'fe07' │
│ 2 │ '︃' │ 'fe03' │
│ 3 │ '︆' │ 'fe06' │
│ 4 │ '︅' │ 'fe05' │
│ 5 │ '︆' │ 'fe06' │
│ 6 │ '︃' │ 'fe03' │
│ 7 │ '︇' │ 'fe07' │
│ 8 │ '︂' │ 'fe02' │
│ 9 │ '︆' │ 'fe06' │
│ 10 │ '︅' │ 'fe05' │
│ 11 │ '︇' │ 'fe07' │
│ 12 │ '︄' │ 'fe04' │
│ 13 │ 'か' │ '304b' │
│ 14 │ 'く' │ '304f' │
│ 15 │ 'れ' │ '308c' │
│ 16 │ 'み' │ '307f' │
│ 17 │ 'の' │ '306e' │
└─────────┴──────┴────────┘
デコードすると「secret」が取り出せます。
console.log(decode(encoded));
//=> [ 'かくれみの', 'secret' ]