はじめに
2023年5月に一般提供を開始したAmazon Security Lake(以後Security Lakeと記載)についてサービスの概要と特徴であるアクセス管理(データアクセス,クエリアクセス)に焦点をあてて記載します。
今回解説を行わない内容
Security Lake 環境構築の諸設定解説
Security Lake に蓄積したデータの可視化
目次
・Security Lakeとは
・メリット
・システム構成図とアクセス管理の検証箇所
・導入ステップ
・アクセス管理動作検証
・どのような活用が期待されるか
・注意点
Security Lakeとは
Security Lakeは、フルマネージド型のセキュリティデータレイクサービスです。
AWS環境・SaaSプロバイダー・オンプレミス・クラウドソースからのセキュリティデータ(ログ・イベントデータ)を、アカウントに保存されている専用データレイクに自動的に一元化することができます。
収集したログは、Amazon Simple Storage Service (S3) バケットに保存されるため、データのコントロールと所有権を保持できます。
下図は概要図です。
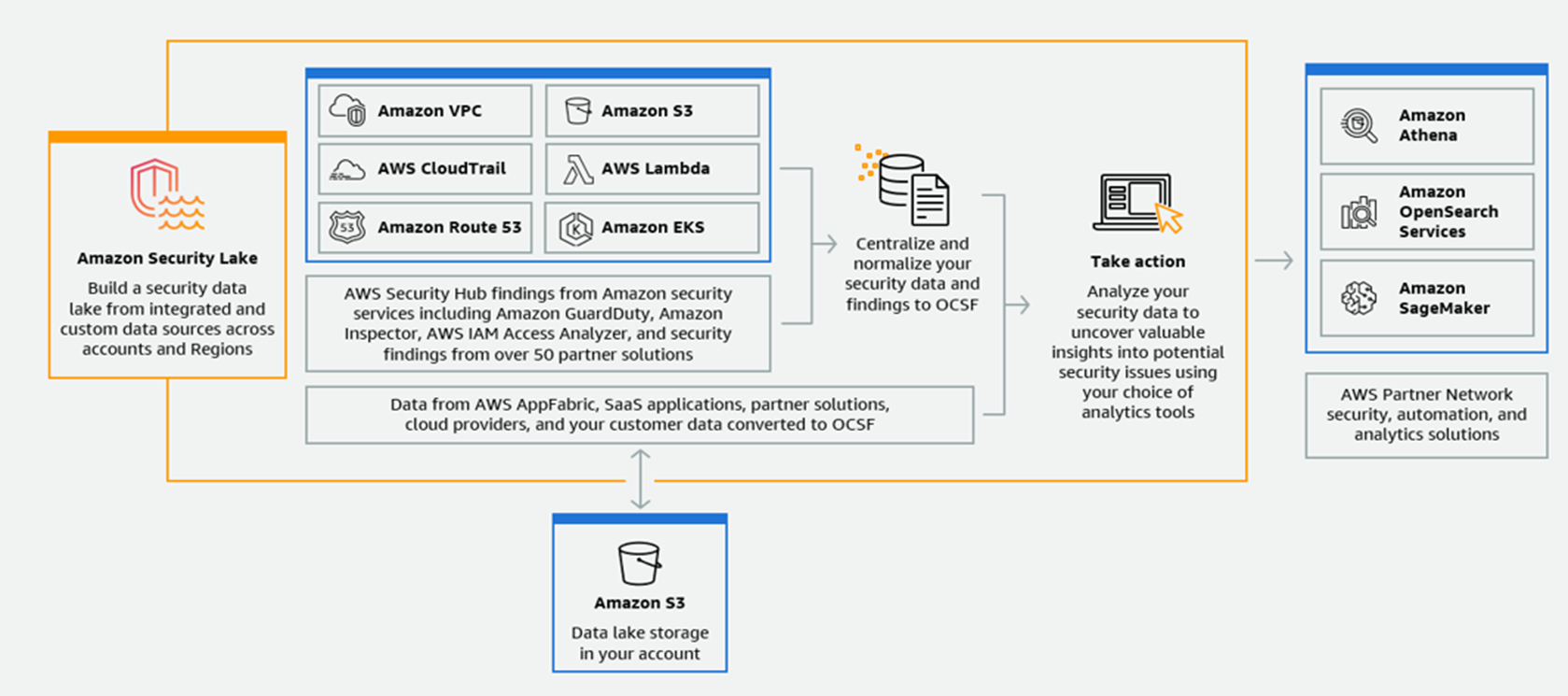
引用元:https://aws.amazon.com/jp/security-lake/
主に下記のログ・セキュリティデータをサポートしております。
その他サードパーティのデータもOSCF (Open Cybersecurity Schema Framework )形式に変換することで一元管理することができます。
・Amazon Virtual Private Cloud (VPC) フローログ
・AWS CloudTrail 管理イベントとデータイベント (S3、Lambda)
・Amazon Route 53 Resolver クエリログ
・Amazon Elastic Kubernetes Service (EKS) 監査ログ ※2024/2/29追加
・AWS Security Hub 調査結果
AWS Security Hub でもセキュリティデータを包括的に把握することができたのですが、主な役割としては脅威を検知し通知することで、Security Lakeは検知したデータと他のログデータと組み合わせて分析や機械学習に利用することを目的としていることが概要図からも分かります。(下図はSecurity Hubの概要図です)
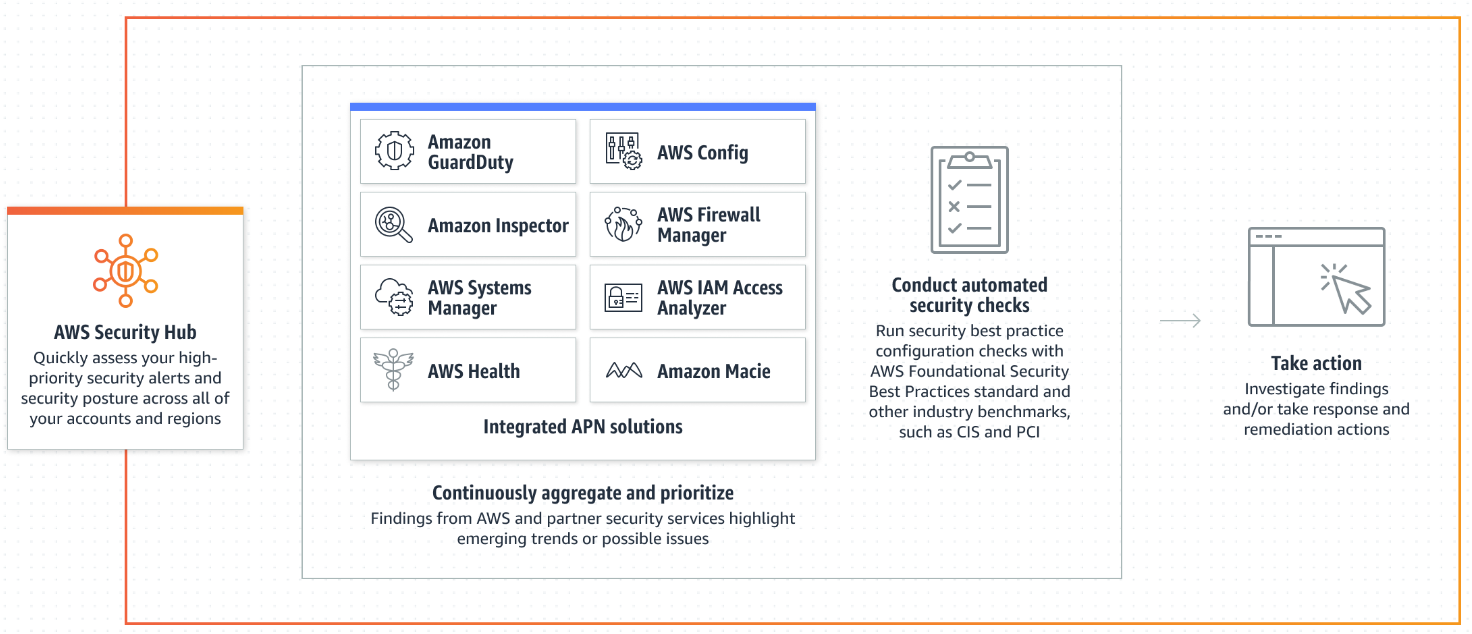
引用元:https://aws.amazon.com/jp/security-hub/
メリット
Security Lakeを利用することで得られる利点を私なりにまとめました。
・セキュリティデータ、ログを一元管理できる(マルチアカウント、マルチリージョンに対応)
・正規化によるデータの一貫性を担保できる(OSCFを採用)
・セキュリティデータ、ログを連携できる(アクセス管理)
・最終用途(分析など)の実現にかかる時間を削減できる
・分析の自由度が高い
公式ドキュメント
Amazon Security Lake ではじめる簡易な SIEM
システム構成図とアクセス管理の検証箇所
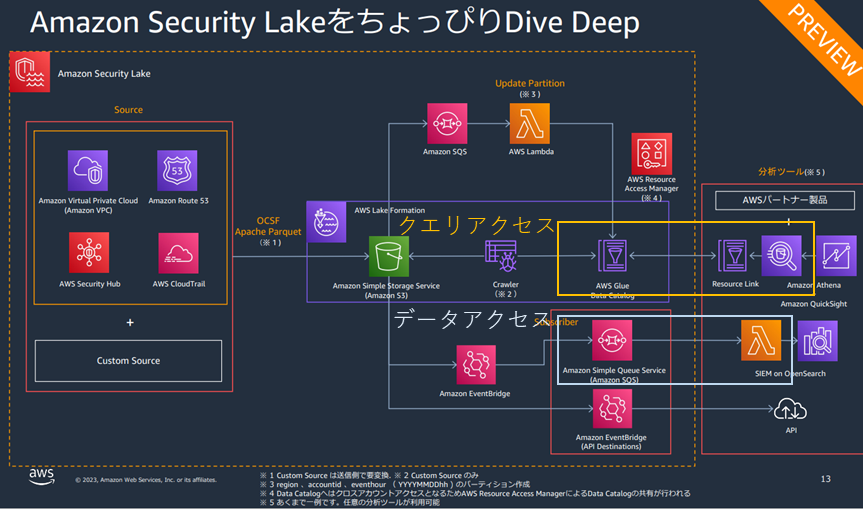
引用元:Amazon Security Lake ではじめる簡易な SIEM
Security Lakeのアクセス管理には、新しいオブジェクトがデータレイクに書き込まれたときに通知を発行する データアクセス と、セキュリティデータレイクに保存されているデータをツールでクエリできる クエリアクセス の2つのモードがあり、今回は2つのモードでSecurity Lakeへアクセスする検証を行います。システム構成図でいうと上記囲った部分が対象です。
導入ステップ
<前提>
AWS Organizationsの有効化 ( or スタンドアロンアカウント)
①開始:Security Lakeを開始(組織管理者1)
②開始:別のアカウントへSecurity Lakeの管理を委任(組織管理者)
※なぜ委任が必要なのかは組織単位のベストプラクティスが関係していると思います
③開始:委任先のアカウントでSecurity Lakeを開始(管理アカウント2)
④設定:Security Lakeの諸設定(管理アカウント)
※ここまでで管理アカウント側でデータを分析することもできます
⑤連携:データ連携用にサブスクライバー作成(管理アカウント)
a:データアクセス用
b:クエリアクセス用
⑥検証:各モードの検証作業(アクセスアカウント3)
a:主にIAMロールを用いてLambdaでSecurity Lakeの情報を取得する
b:AWS Lake Fomation設定してSecurity LakeのGlueテーブルに対してクエリを実行
アクセス管理動作検証
a:データアクセス
管理アカウントでサブスクライバーのデータアクセスの方法をS3、通知タイプをSQSに設定して作成します。
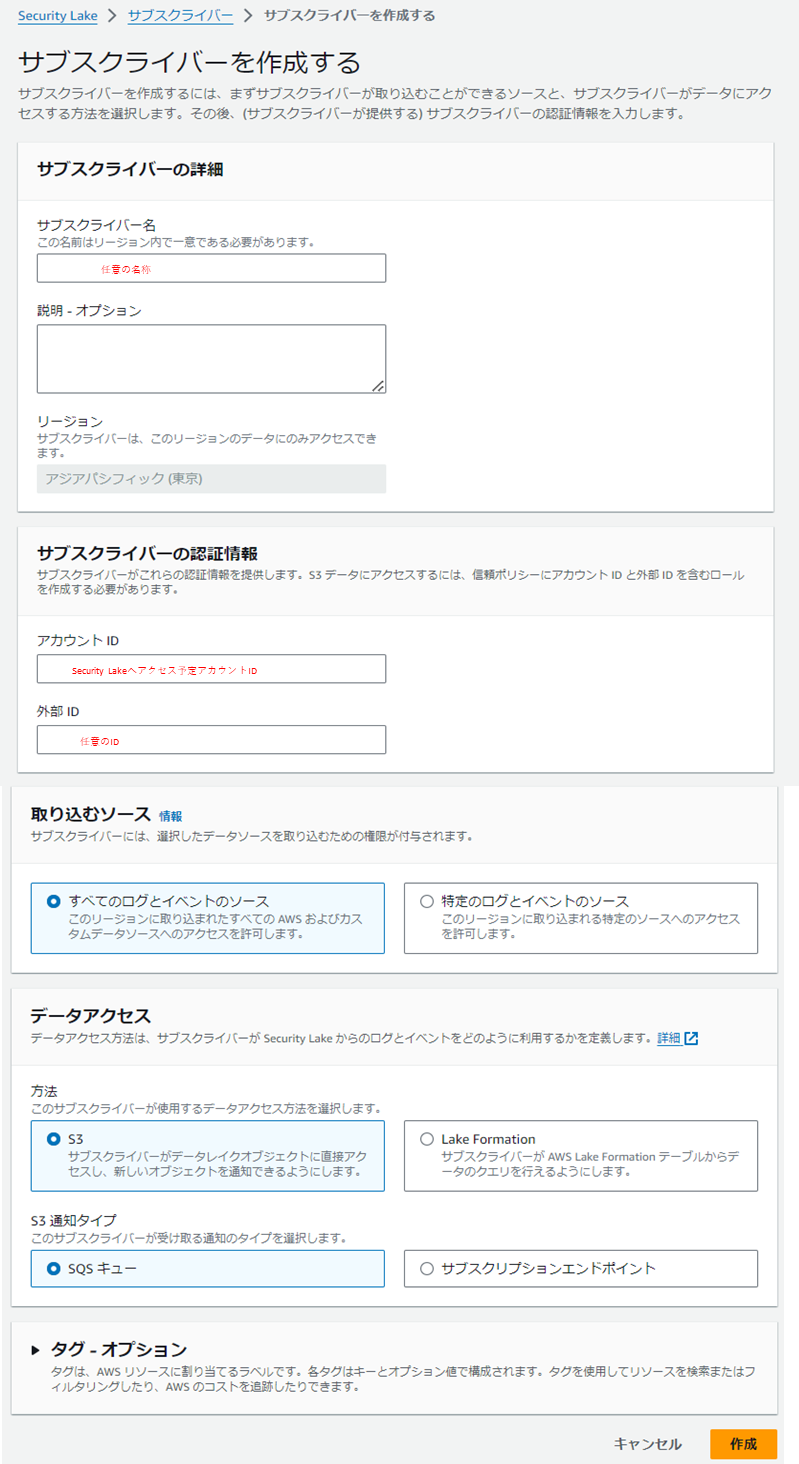
サブスクライバー作成後に下記の赤枠のSQSが自動で作成されます。
S3にデータ格納があったことを検知するSQSはAmazonSecurityLake-XXX-Main-Queueの方です。
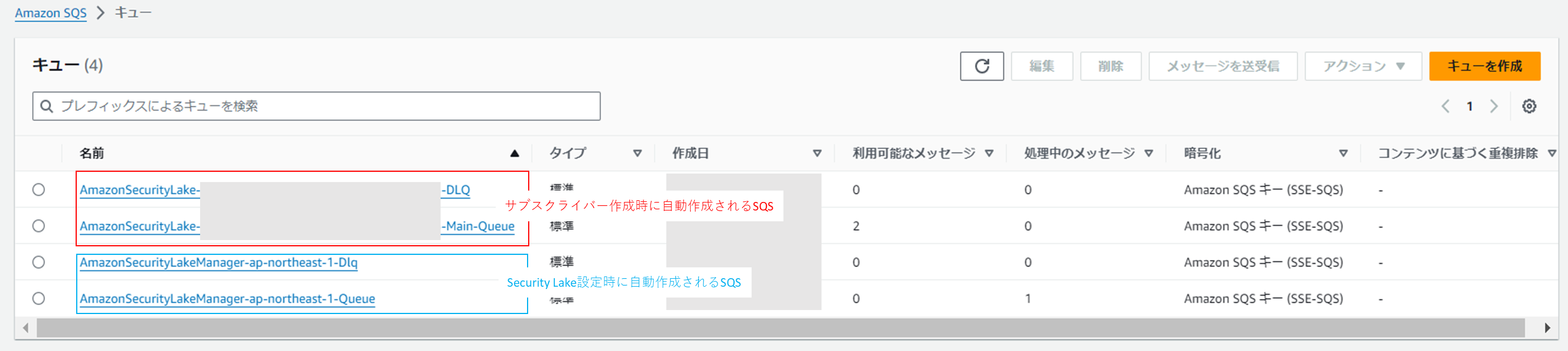
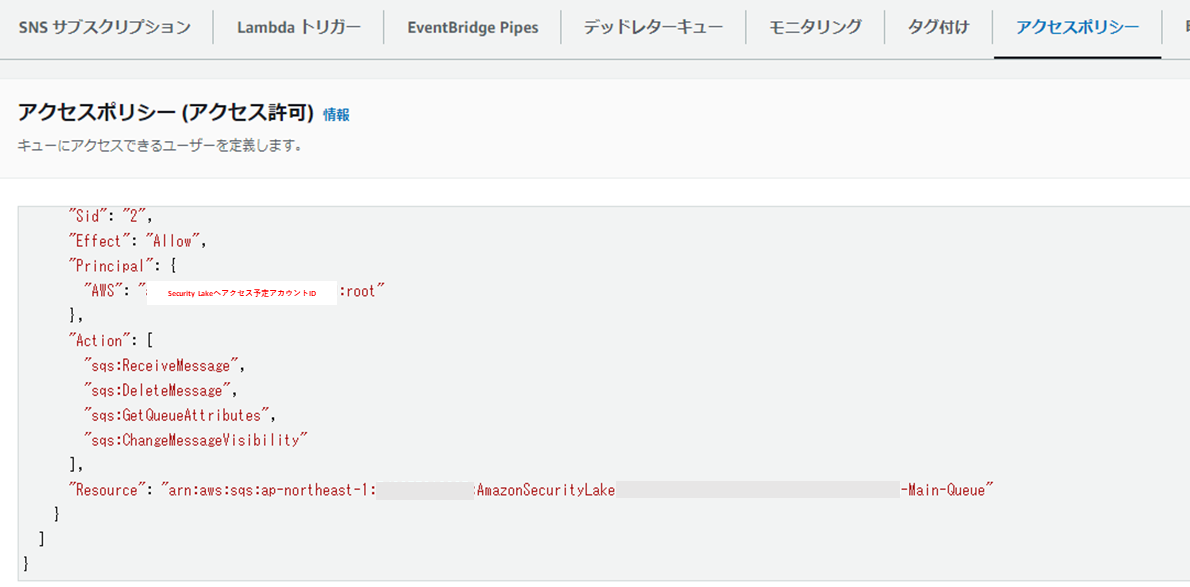
AmazonSecurityLake-XXX-Main-Queueのアクセスポリシーを確認すると、
サブスクライバー作成時に設定したアクセスアカウントがSQSにアクセスできるように設定されております。
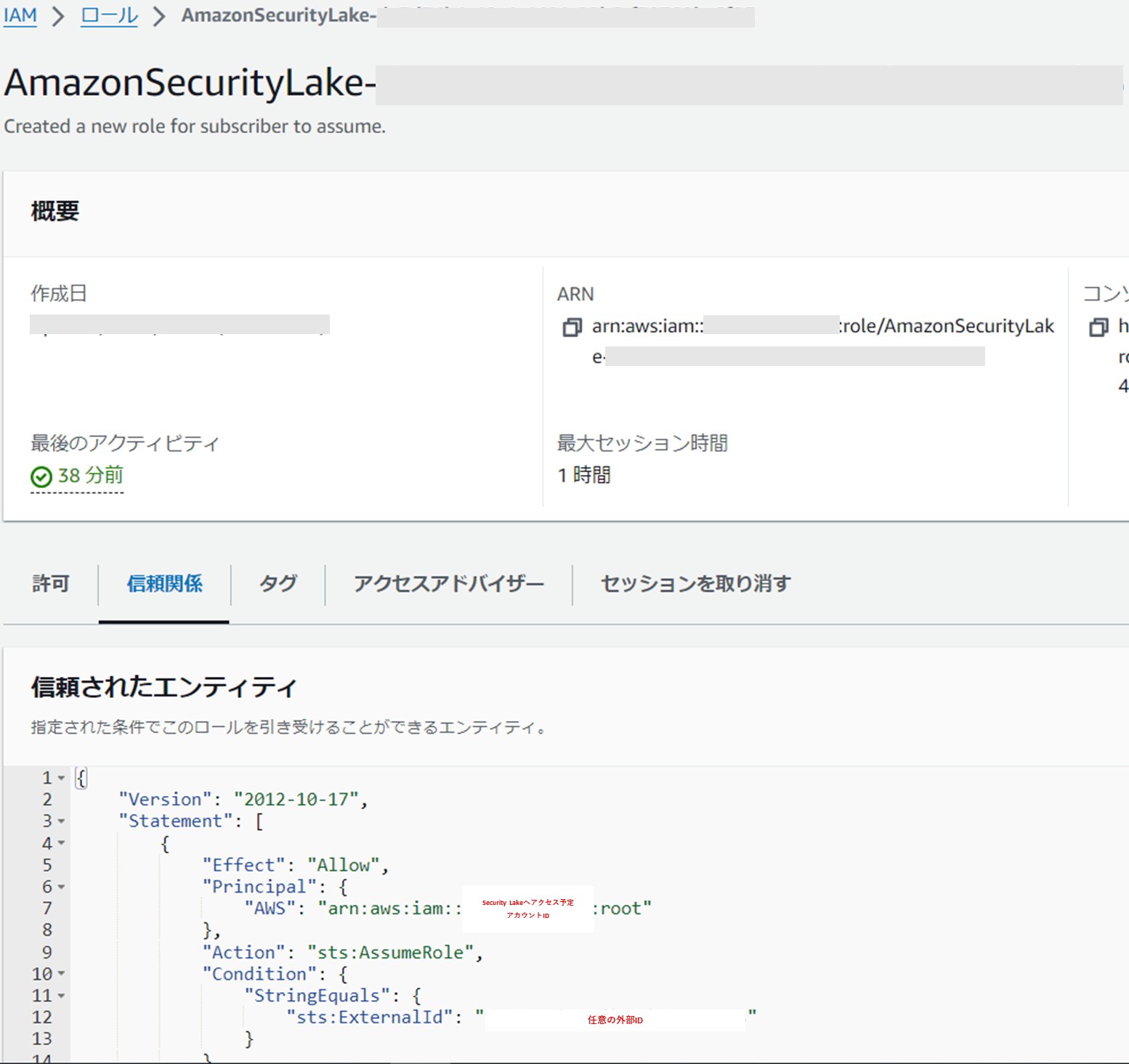
また、アクセスアカウントが対象のログデータを取得するときに利用するロールも自動で作成されます。
信頼関係にサブスクライブ作成時に設定した任意の外部IDと一致する場合にアクセス予定のアカウントがロールを利用できるように設定されております。
アクセスアカウントで先ほどのSQSをトリガーにSecurity Lake(S3)の情報を取得するLambda関数を作成する。
※ソースコードは下の方に記載
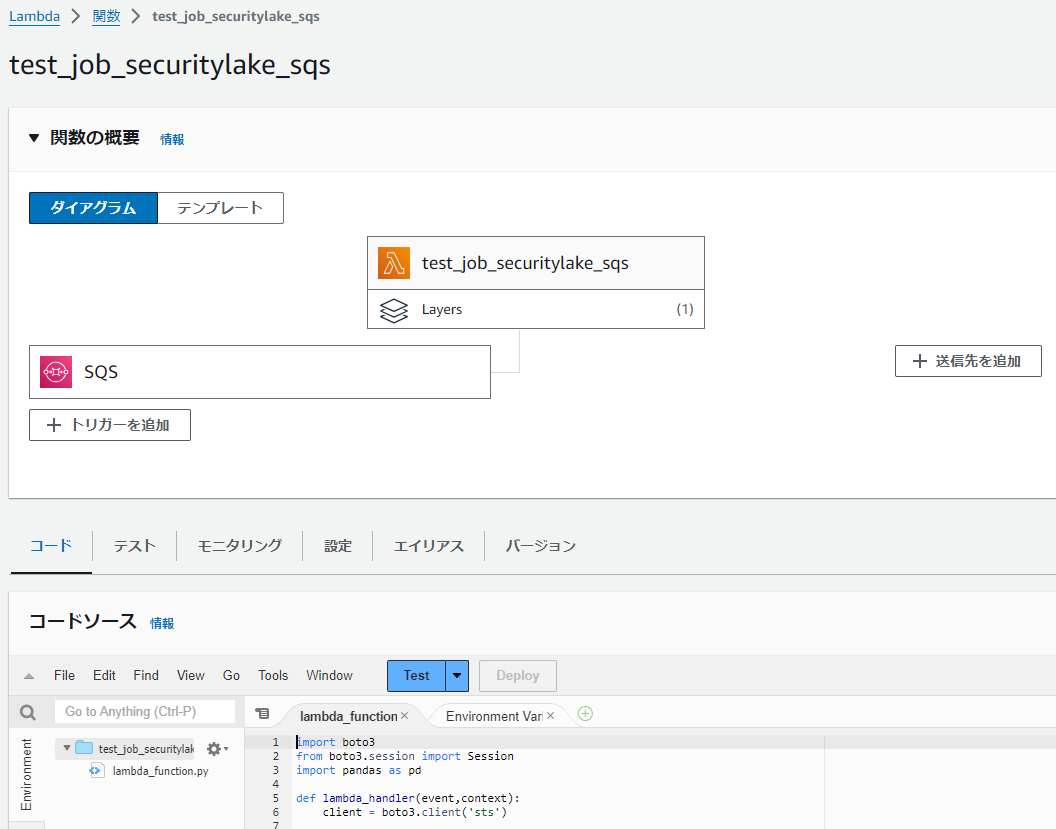
トリガーの設定にはサブスクライバー作成後にできたSQS(AmazonSecurityLake-XXX-Main-Queue)のARNを指定する。
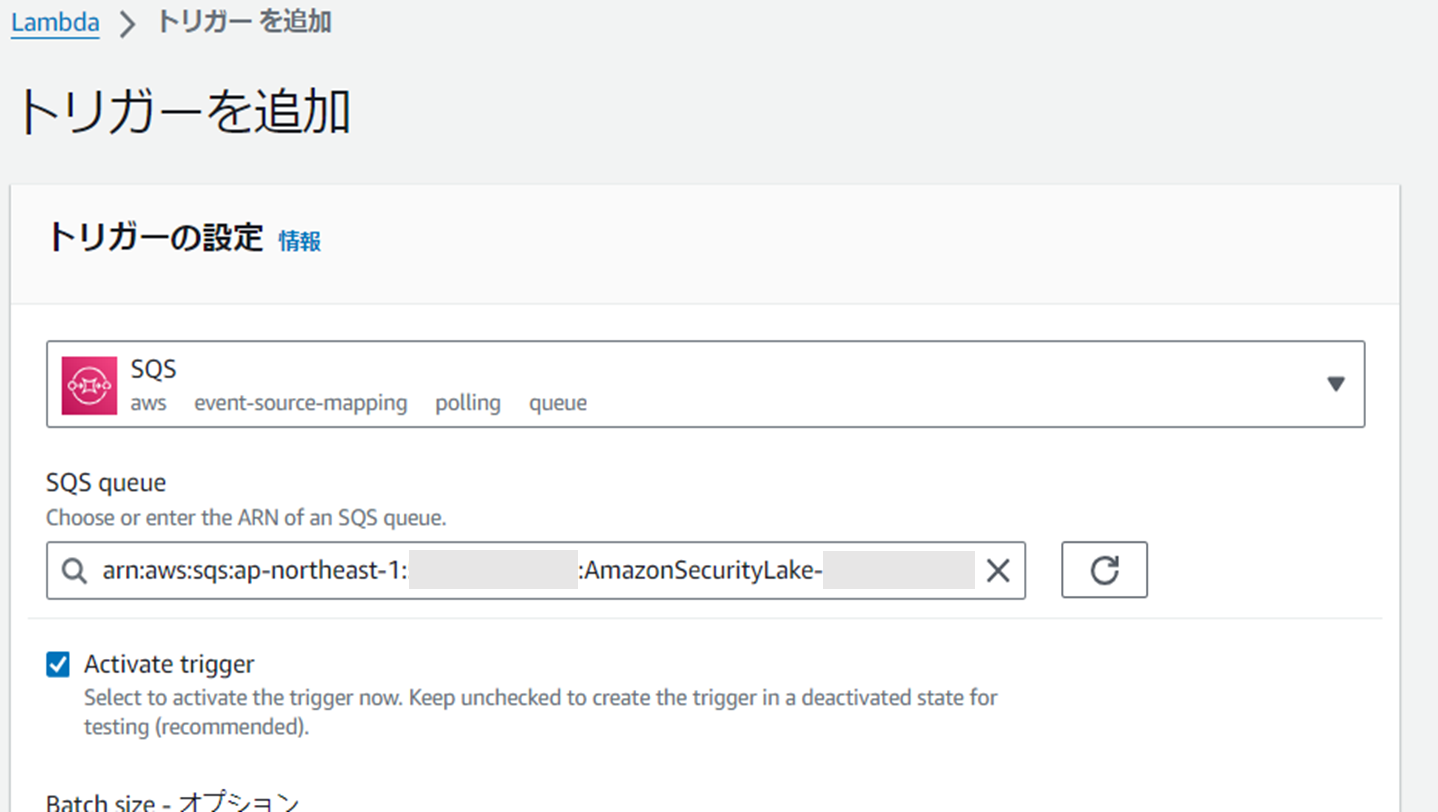
Lambda用のロールにSQSからの通知を受け取れるよう権限を付与し(検証のためフル権限を使用している)、管理アカウントのロールを利用するためにsts:AsuumeRoleをポリシーに追加する。
トリガー設定後にログを確認すると下記のとおり正常に実行しSecurity Lake(S3)の情報を取得することができます。(ログが発生する行動 or SQS側でメッセージを送信するで動作確認できます)

ソースコードは下記です。
管理アカウントにロールを経由して、Security Lake(S3)のオブジェクトをリスト化するコードです。
import boto3
from boto3.session import Session
def lambda_handler(event,context):
client = boto3.client('sts')
role_arn = "『Security Lake側のロールのARN』"
session_name = "hoge"
region = "ap-northeast-1"
external_name = "『サブスクライブ作成時の任意の外部ID』"
# AssumeRoleで一時クレデンシャルを取得
response = client.assume_role(
RoleArn=role_arn,
RoleSessionName=session_name,
ExternalId=external_name
)
aws_access_key_id=response['Credentials']['AccessKeyId']
aws_secret_access_key=response['Credentials']['SecretAccessKey']
aws_session_token=response['Credentials']['SessionToken']
session = Session(
aws_access_key_id=response['Credentials']['AccessKeyId'],
aws_secret_access_key=response['Credentials']['SecretAccessKey'],
aws_session_token=response['Credentials']['SessionToken'],
region_name=region
)
# s3 = session.resource('s3')
s3 = session.client('s3')
bucket_name = "『Security Lakeのログが格納されているバケット』"
# BUKET = s3.Bucket('bucket_name')
res = s3.list_objects_v2(Bucket=bucket_name)
print(res)
今回の検証は可視化を含んでおりませんが、Cloud Formationのテンプレートで SIEM on Amazon OpenSearch Service というものがあり容易に可視化できます。興味がある方は下記が参考になります。
Amazon Security LakeのサブスクライバーにSIEM on Amazon OpenSearch Serviceを設定してみた
またサードパーティと連携させたい場合はサブスクライバー作成時に通知タイプをサブスクリプションエンドポイントに設定することで連携可能です。下記が参考になります。
Amazon Security LakeのサブスクライバーにSumo Logicを設定してみた
b:クエリアクセス
参考にした記事は下記です。
Amazon Security Lake のサブスクライバー機能を使って他のアカウントから Athena で検索する
管理アカウントでサブスクライバーを作成します。設定としてはデータアクセス方法をLake Formationに変更するだけなので省略します。
次に、アクセスアカウントでLake Formationにアクセス。(初回は自分を管理者に含めるか問われるので含めてください)
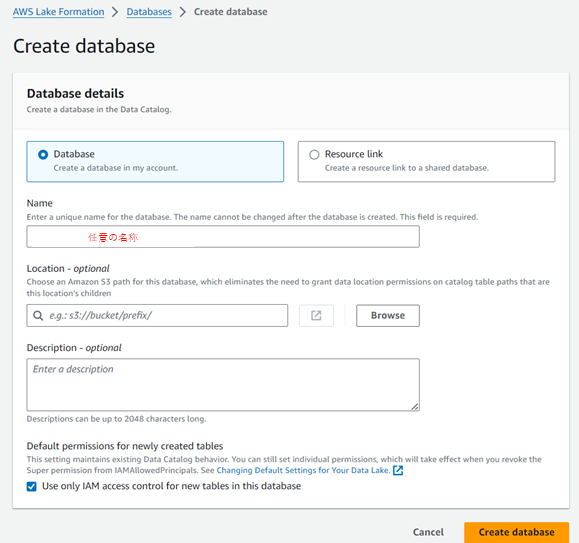
空のDatabaseを作成します。
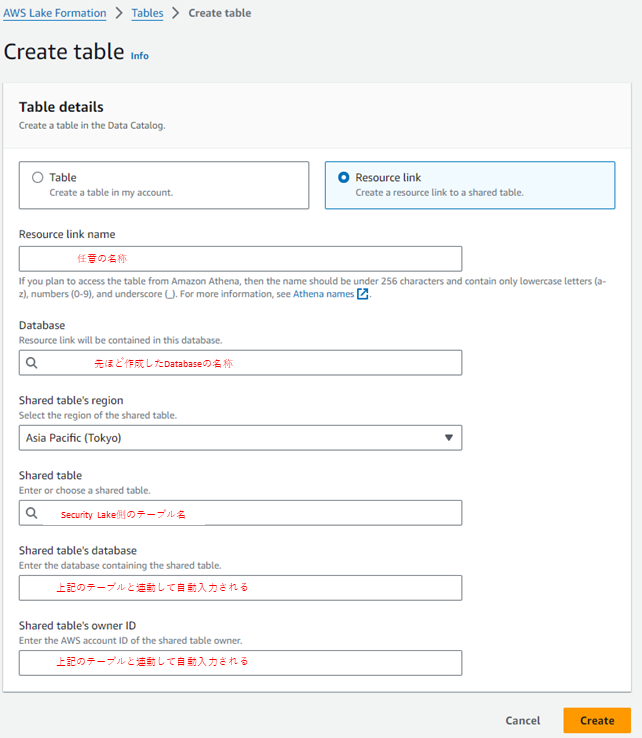
続いてテーブルを作成します。
作成時にResource link を選択して情報を入力することでSecurity Lakeのテーブルが選択できるようになります。
Athenaで連携されたテーブルにクエリを実行。
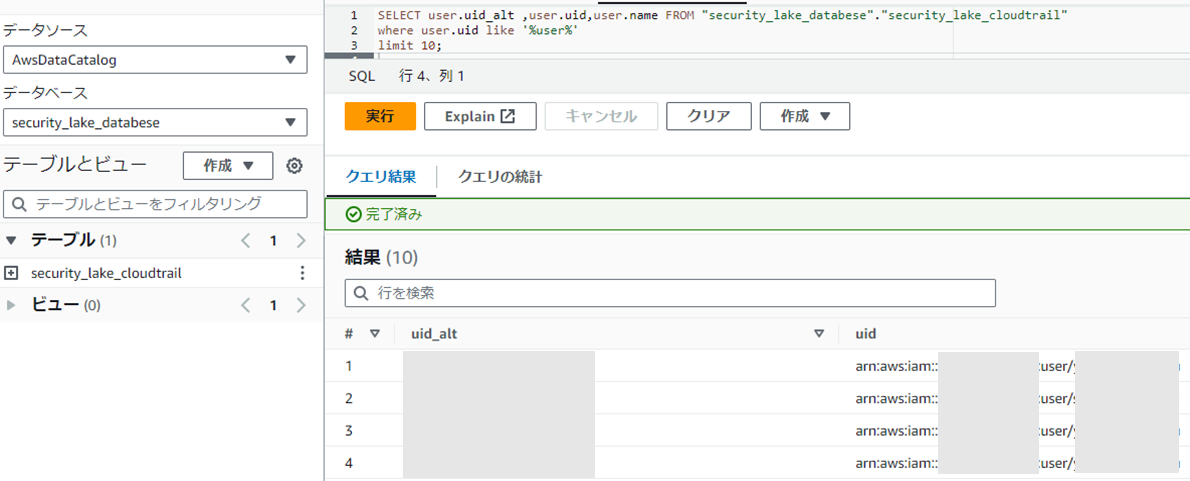
userの情報も取り出すことが可能です。
どのような活用が期待されるか
以前まではSecurity Hubで脅威を検知した情報を元にセキュリティ担当者がCloudTrailログやVPCフローログにそれぞれ照らし合わせて情報を整理する必要があったが、Security Lakeを活用することでそれぞれの情報を正規化して一元管理できるので情報整理や照らし合わせにかかる管理コストを削減が期待されます。
例えば、AthenaでSecurity Hub検知したユーザーの直近の行動ログを紐づけるVIEWを作成しておけば悪意のあるユーザーであるかどうかを瞬時に判断できると考えます。また悪意あるユーザーの行動パターンを機械学習してブラックリストに自動で追加し接続できないようにすることもできると思います。
直近にもAmazon Elastic Kubernetes Service(2024/2/29追加)を対応したりと、今後も対応するAWSサービスやサードパーティ製品が増えていくことが予想されますので、これまで人力で対応していた業務(管理コスト)を削減されることが期待されます。
注意点
Security lake はデータの取込みとデータ変換(正規化)に従量課金制で料金がかかります。
Amazon Security Lake の料金
マルチアカウント・マルチリージョンでログデータを取得する際は膨大なデータが予想されます。またそのデータをS3に格納するのでS3の料金もかかります。
ログデータの取得については対象のアカウントを絞る以外のコスト削減は見込めませんが、S3はSecurity Lakeの設定でライフサイクルルールを設けることができるので適切なライフサイクルルールの設定に注意する必要があります。(検証時2アカウントのログを1ヶ月程度取得してS3の容量が45GBになりました)
株式会社ジールでは、「ITリテラシーがない」「初期費用がかけられない」「親切・丁寧な支援がほしい」「ノーコード・ローコードがよい」「運用・保守の手間をかけられない」などのお客様の声を受けて、オールインワン型データ活用プラットフォーム「ZEUSCloud」を月額利用料にてご提供しております。
ご興味がある方は是非下記のリンクをご覧ください:
https://www.zdh.co.jp/products-services/cloud-data/zeuscloud/?utm_source=qiita&utm_medium=referral&utm_campaign=qiita_zeuscloud_content-area