本記事では、Google AI Blogの2020年の振り返り記事から、「どのようなAI系の研究が今重要とされているのか」、19個のテーマを紹介します。
また私が個人的に衝撃を受けた研究を、4つ紹介します。
0. ベース記事
以下のGoogleのブログ記事をベースとしています。
「Google Research: Looking Back at 2020, and Forward to 2021」
https://ai.googleblog.com/2021/01/google-research-looking-back-at-2020.html
(2021年1月12日発行)
1. AI研究の重要テーマ集(Google版)
上記記事の各見出しから、GoogleでのAI研究の重要テーマを羅列します。
- COVID-19 and Health
- Research in Machine Learning for Medical Diagnostics
- Weather, Environment and Climate Change
- Accessibility
- Applications of ML to Other Fields
- Responsible AI
- Natural Language Understanding
- Language Translation
- Machine Learning Algorithms
- Reinforcement Learning
- AutoML
- Better Understanding of ML Algorithms and Models
- Algorithmic Foundations and Theory
- Machine Perception
- Robotics
- Quantum Computing
- Supporting the Broader Developer and Researcher Community
- Open Datasets and Dataset Search
- Research Community Interaction
参考記事内では、各テーマに対して、20年に発表した論文のダイジェストが紹介されています。
気になるテーマについては是非、元の英語ブログをご覧ください。
2. 個人的に気に入った研究を紹介
上記のブログ記事より、私個人的に重要だなと衝撃を受けた研究をピックアップします。
もちろんどれもインパクトのある重要な研究ばかりですが、その中でも、
- AutoML-Zero: Evolving Code that Learns
- Lookout:On-device Supermarket Product Recognition
- Agile and Intelligent Locomotion via Deep Reinforcement Learning
- Chip Design with Deep Reinforcement Learning
の4つに対して、個人的に衝撃を受けました。
各研究を簡単に紹介します。
AutoML-Zero
AutoML-Zero: Evolving Code that Learns
(2020年7月)
は、AutoMLの分野のNAS(Neural Architecture Search)の新手法です。
これまでのNASは、AutoMLとして探索するネットワークの形の候補はある程度人手でのルールベースでした(例えば、カーネルのサイズは[A,B,C]など)
要は今までのAutoMLは、「自動で最適なディープラーニングモデルを作成する」と言っても、
ハイパーパラメータチューニングの延長に近く、
ただ探索空間が広すぎるので、強化学習やその他の最適化手法を活用していました。
AutoML-Zeroはまったくそうした人手でのディープラーニングのルール(知見)を活用せず、与えるのは単純な演算のみです。
そこから遺伝的アルゴリズムでモデルを進化させていき、gradient descent(勾配降下法)やReLUなどを自動的に発見していきました。
これは、人類の研究成果(ReLUの発見など)を、遺伝的アルゴリズムで自動的に発見できることを示唆し、人が研究するよりも、より良い手法・ディープラーニングの枠組みをコンピュータが自動的に発見できる可能性を示唆しています。
以下の図は、横軸が時間(遺伝的アルゴリズムの発展)、縦軸が正解率を示し、途中途中で人類が発見してきた手法をAutoML-Zeroが発見したタイミングを示しています。
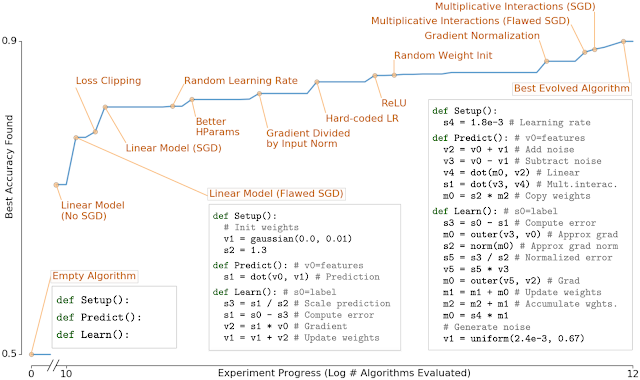
(図は参考記事より引用)
Lookout:On-device Supermarket Product Recognition
On-device Supermarket Product Recognition(Lookout)
(2020年8月)
様々な物体に対して、物体を検知し、そこに文字データなどをAR(拡張現実)として表示できます。
こちらは、既にアンドロイドアプリ、
Lookout by Google
https://play.google.com/store/apps/details?id=com.google.android.apps.accessibility.reveal
として、利用できるように公開されています。

(図は参考記事より引用)
良くある研究と言えばそうなのですが、きちんとアプリ化され、利用しやすいのが良いです。
またブログ記事(On-device Supermarket Product Recognition(Lookout))では、Lookoutのアーキテクチャや手法も紹介されています。
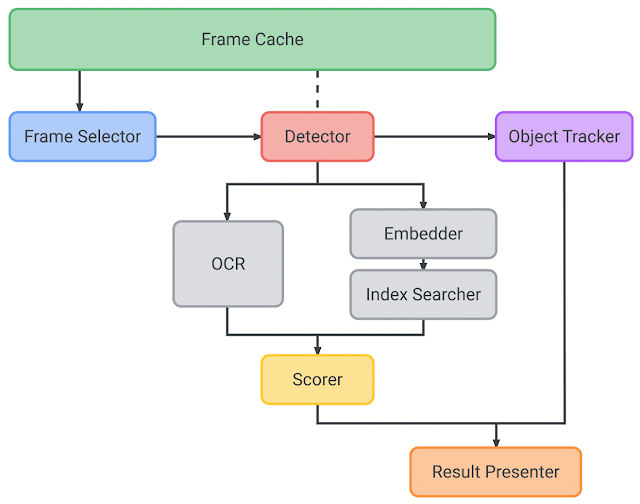
(図は参考記事より引用)
Agile and Intelligent Locomotion via Deep Reinforcement Learning
Agile and Intelligent Locomotion via Deep Reinforcement Learning
(2020年5月)
深層強化学習の新たな手法の提案です。
それまでのGoogle自身での優秀な手法であった、Soft Actor-Critic (SAC)の性能を大きく上回る手法です。
SACでは1時間の実ロボットの稼働データが必要だった4足歩行を、5分弱で学習できるようになりました。

(図は参考記事より引用)
手法としては、Hierarchical Reinforcement Learning(階層型強化学習)とメタラーニングがベースにあります。
アルゴリズムの独自実装はやや難しそうで、まだ強化学習の主要ライブラリ(Ray RLLibなど)には搭載されていません。
Chip Design with Deep Reinforcement Learning
Chip Design with Deep Reinforcement Learning
(2020年4月)
多くの方にとって「深層強化学習って実際のビジネスに使えるの??」という疑問があるかと思います。
私もまだまだこれからだと思うのですが、この研究はCPUなどのチップ上の素子の配置を深層強化学習とグラフニューラルネットワークで最適化した研究です。
チップ上の素子を、配線の総延長距離ができるだけ短くなるように配置させます。
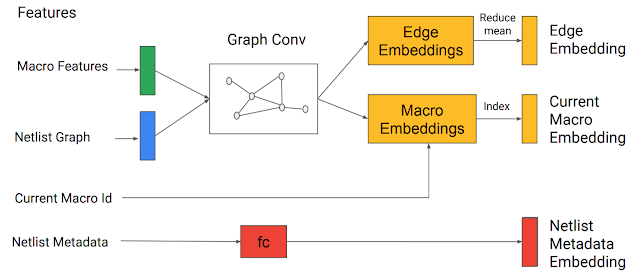

(図は参考記事より引用)
Google自身が記事内で、
The system is able to generate placements that usually outperform those of human chip design experts, and we have been using this system (running on TPUs) to do placement and layout for major portions of future generations of TPUs.
と、次世代のTPUの素子レイアウトにこの技術を使用している最中と述べ、ビジネスで活用していることを紹介しています。
まだ私自身、最適化に近い生成系において、遺伝的アルゴリズム等よりも深層強化学習の方が適しているケースをうまく言語化できていないのですが、
深層強化学習のビジネス適用が21年はますます増えそうな気がします。
3. おわりに & 参考文献
以上、AI研究の重要テーマ集(Google版)の紹介でした。
21年もGoogleのAI研究は要チェックし、Twitterで発信していきたいと思います。
【参考文献】
●Google Research: Looking Back at 2020, and Forward to 2021
https://ai.googleblog.com/2021/01/google-research-looking-back-at-2020.html
●AutoML-Zero: Evolving Code that Learns
https://ai.googleblog.com/2020/07/automl-zero-evolving-code-that-learns.html
●On-device Supermarket Product Recognition(Lookout)
https://ai.googleblog.com/2020/07/on-device-supermarket-product.html
●Agile and Intelligent Locomotion via Deep Reinforcement Learning
https://ai.googleblog.com/2020/05/agile-and-intelligent-locomotion-via.html
●Soft Actor-Critic: Deep Reinforcement Learning for Robotics
https://ai.googleblog.com/2019/01/soft-actor-critic-deep-reinforcement.html
●Chip Design with Deep Reinforcement Learning
https://ai.googleblog.com/2020/04/chip-design-with-deep-reinforcement.html
【記事執筆者】
電通国際情報サービス(ISID)AIトランスフォーメーションセンター 製品開発Gr
小川 雄太郎
主書「つくりながら学ぶ! PyTorchによる発展ディープラーニング」
(自己紹介詳細)
【情報発信】
Twitterアカウント:小川雄太郎@ISID_AI_team
IT・AIやビジネス・経営系情報で、面白いと感じた記事やサイトを、Twitterで発信しています。
【採用情報】
・新卒採用(22年)
データサイエンティスト
・中途採用
AIエンジニア/コンサルタント
AIアーキテクト
中途採用一覧
【免責】
本記事の内容そのものは著者の意見/発信であり、著者が属する企業等の公式見解ではございません