本記事では、文章ソースに質問を投げると自動で回答を返すAzure Question answeringを、日本語で使用する方法について解説します。
実装例で目指すところとしては、withコロナの東京において現在、「何人での外食が認められているのか?」という質問に対して、「8名」と回答してくれるサービスを作ります。
また別パターンとして、「日本で2番目に高い山は?」という質問に答えられる実装例を紹介します。
本記事の内容
0. Azure Question answering(質問応答)とは
1. リソース「Language service」の作成
2. 「Language Studio」でプロジェクトの作成
3. 「ナレッジベース」にソースとなるファイルを追加する
4. 「Language Studio」から動作確認をする
5. 「Language Studio」からデプロイする
6. Python SDKを使用し、質問応答を行う
7. ナレッジベースを使用せず、文章も入力して、質問応答を行う
8. さいごに
※※
本記事はCOVID-19に関する内容を含んでおります。
情報は記事執筆時点のものであり、COVID-19に関する情報についてはご自身で最新の内容をご確認ください
※※
0. Azure Question answering(質問応答)とは
「Question answering(質問応答)」は、2021年11月にGAになったAzure Cognitive Servicesの新しいサービスです。
サービスの内部では、MicrosoftのTransformerベースの自然言語モデルであるT-ULRv2(Turing Universal Language Representation model)が使用されています。
この新しいサービスがいったいどう嬉しいのか説明します。
これまでのAzureの質問応答(QnA Maker)では、「質問と回答のペアをたくさん用意したナレッジベース」を作成していました。
今回のQuestion answering(質問応答)は、このような質問・回答ペアをわざわざ用意しなくても、サイトやカタログや説明書や解説書など、事前に用意した文書ソースをベースに、質問が与えられると、都度自動で回答を作成してくれるのが嬉しい点となります。
チャットボットやFAQなどの作成において、大幅な時間削減が期待できそうです。
なお回答を自動で、と記述しましたが、回答の生成方法は抽出型であり、元のソース文書から回答に該当する部分を抜き出します。
(本サービスの発表記事)Question answering feature is generally available (Published Nov 02 2021)
それでは、日本語の文書ソースに対して、日本語で質問をし、日本語で回答を取得するサンプルを実装していきます。
1. リソース「Language service」の作成
(1)Azure Portalの上部の検索バー(リソース、サービス、ドキュメントの検索(G+/))に、"Language service"と入力して検索します
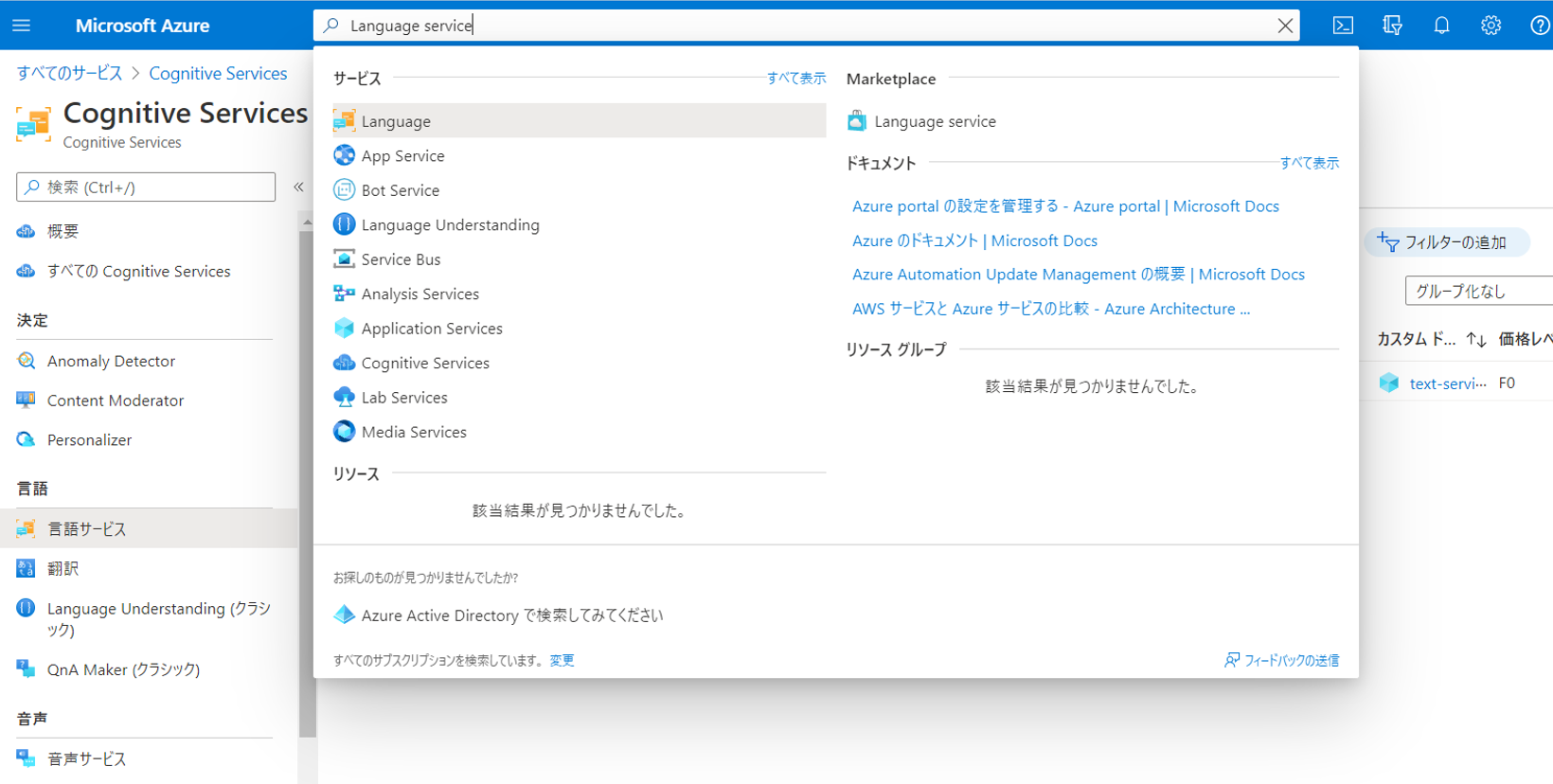
(2)すると以下の図のように、Markeplace Language serviceが表示されるので、こちらをクリックします
(3)「追加機能の選択」が表示されます。規定の機能(左側)に加えて、右側上の「カスタム質問応答」の「選択」をクリックして、選択状態にします
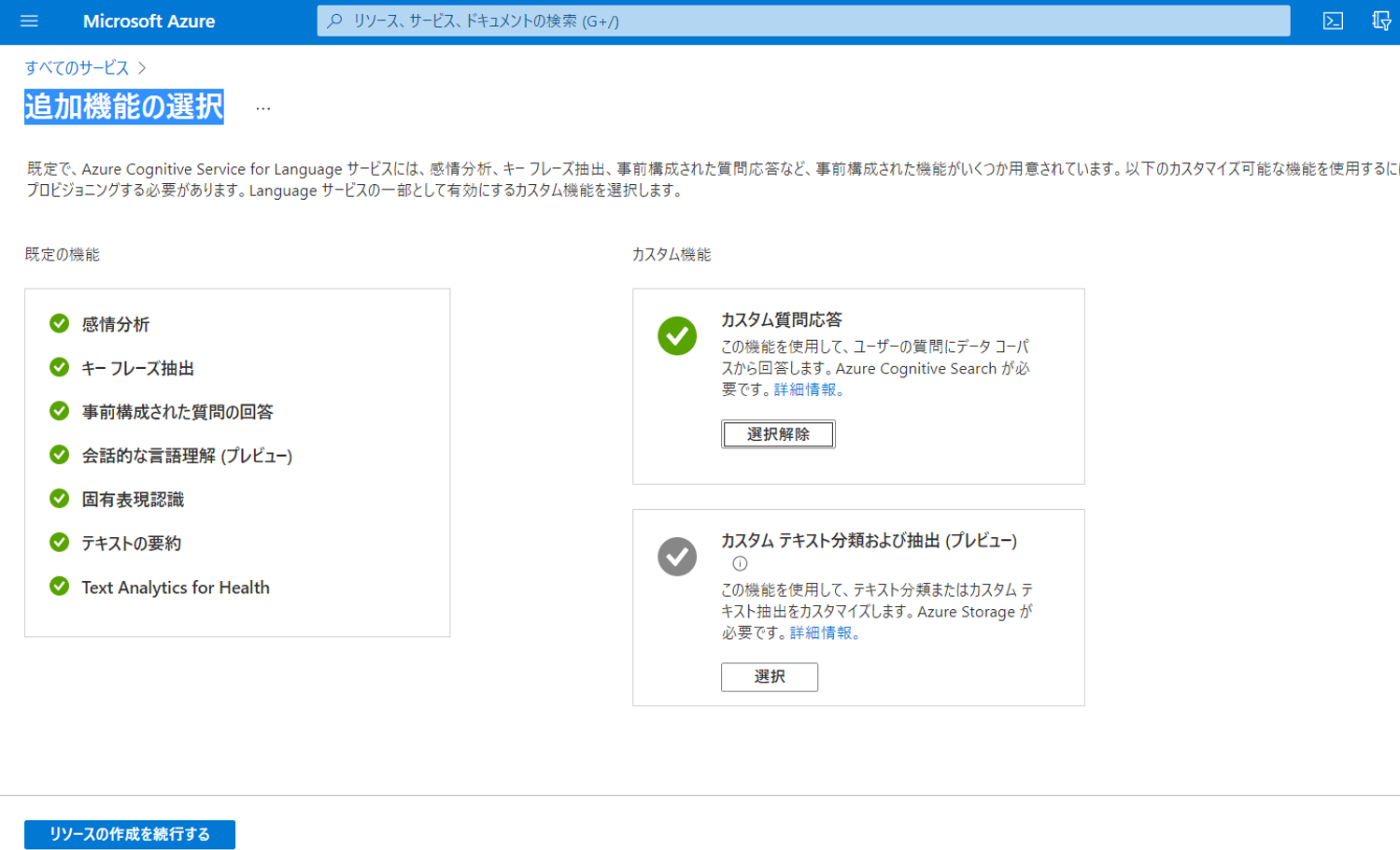
(4)左下の「リソースの作成を続行する」をクリックします
(5)続いて「作成」の画面になります。リソースグループを選択し、リージョンと名前を選択します。今回は全て「東日本」で統一しました
(6)価格レベルは今回はお試しなので、「Free F0」に設定します
(7)画面を下げると、「カスタム質問応答」のセクションがあります。Azure Searchの場所は「東日本」、価格レベルは「Free F」を選択しました
(8)法律条項、責任あるAI通知にチェックを入れ、左下の「確認および作成」ボタンをクリックし、その後「作成」を実行します
2. 「Language Studio」でプロジェクトの作成
(1)Azureのサービスサイト「Language Studio」にアクセスします
https://language.azure.com/
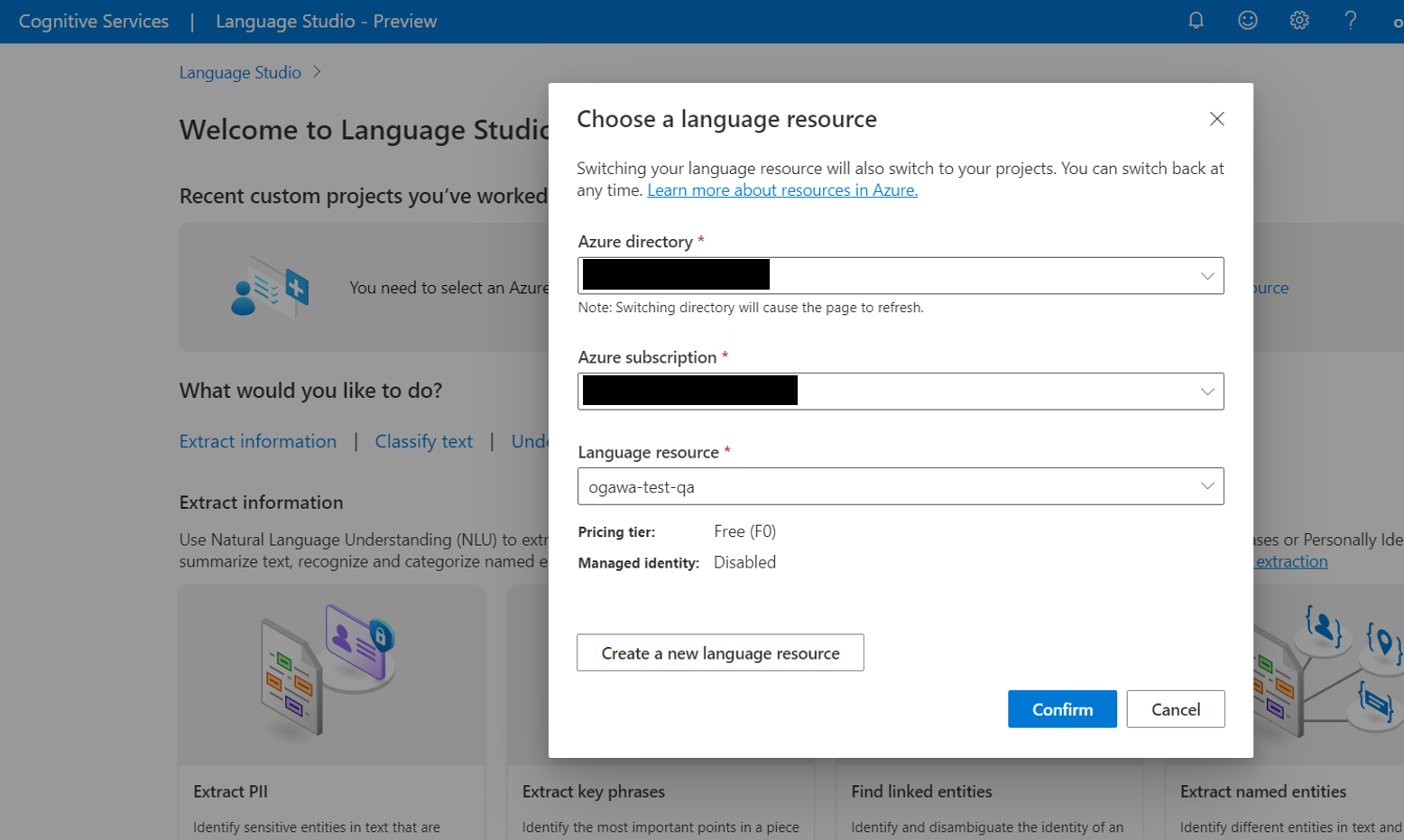
(2)リソース「Language service」を作成したアカウントでSign inします
(3)「Choose a language resource」のモーダル(ウィンドウ)が表示されるので、先ほど作成したリソースを選択し、右下の「Confirm」をクリックします
(4)画面最上部の「Recent custom projects you’ve worked on」のセクションの「Create New」ボタンをクリックして新しいプロジェクトを作成します
(5)プルダウンで作成するプロジェクトタイプを選べるので、「Custom question answering」を選択します
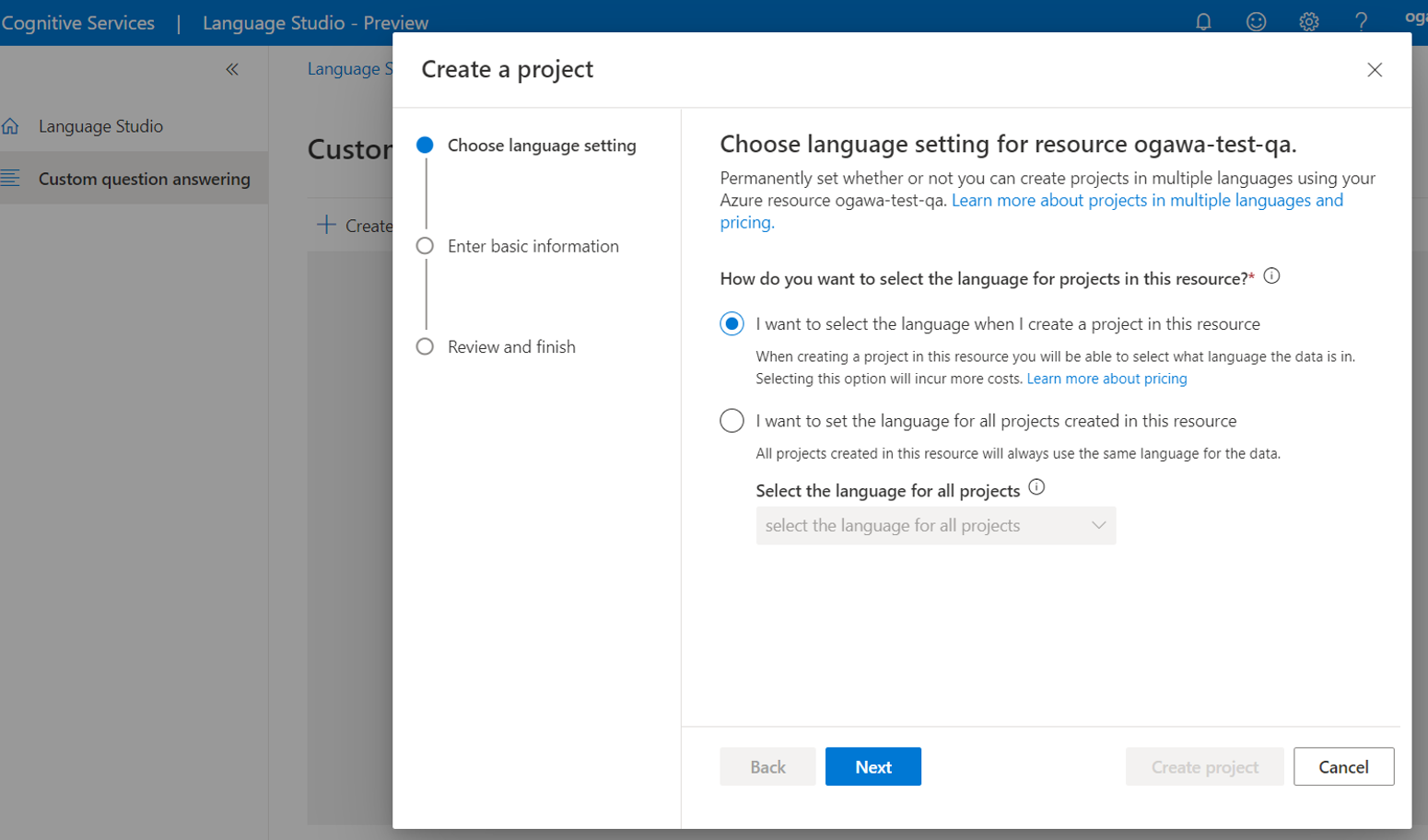
(6)以下の図のように、言語の種類はプロジェクトごとに設定するのか、それとも全プロジェクトで統一するのか聞かれるので、上側の個別に設定を選択し、「Next」をクリックします
(7)以下の図のように、ナレッジデータベース(質問と回答を収納するもの)を設定するので、名前と、description(説明)を記入し、**Source languageは「Japanese」**を、Default answerには「答えが見つかりません」と記入して、「Next」をクリックします
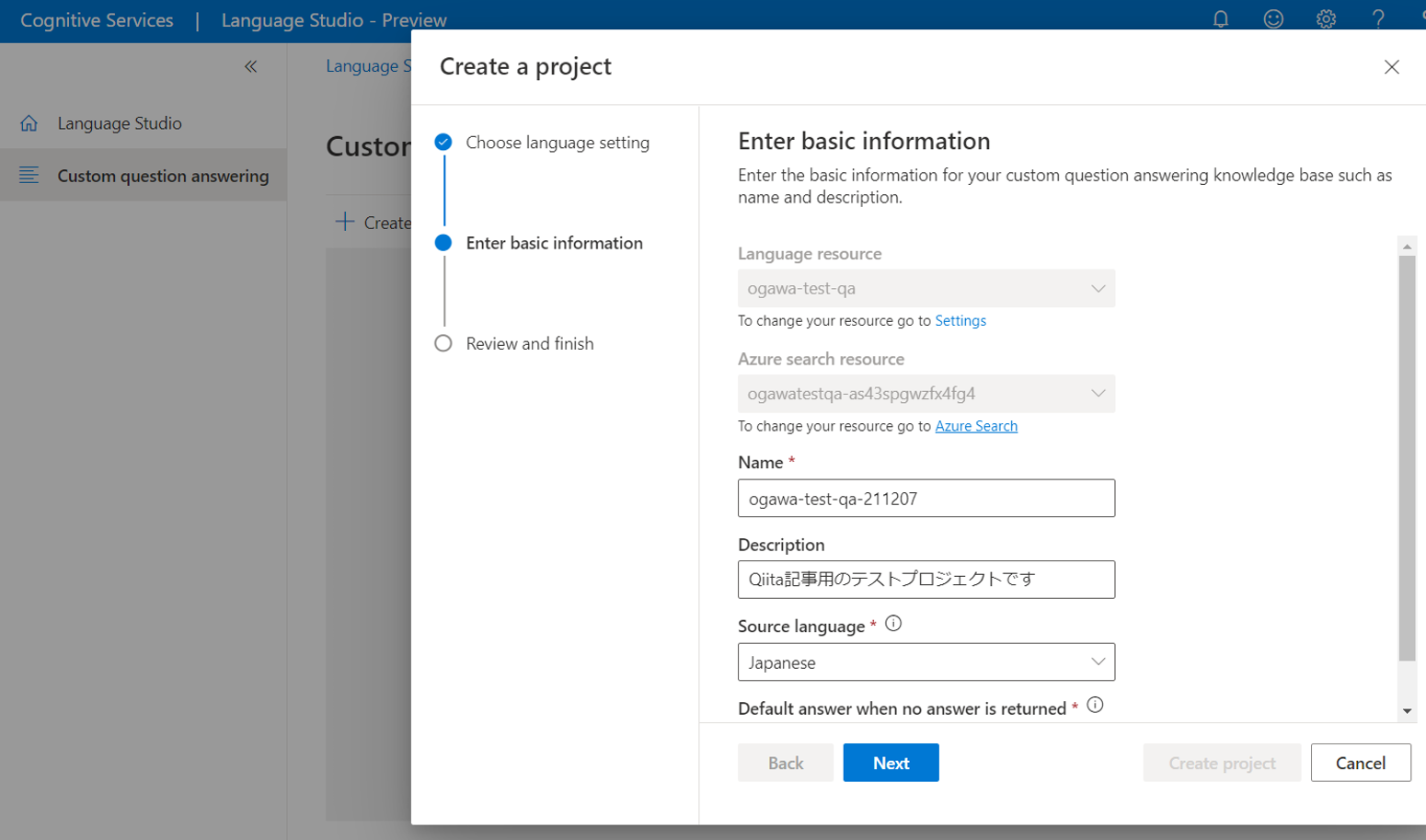
(8)Review and finishの画面になるので、「Create project」をクリックします
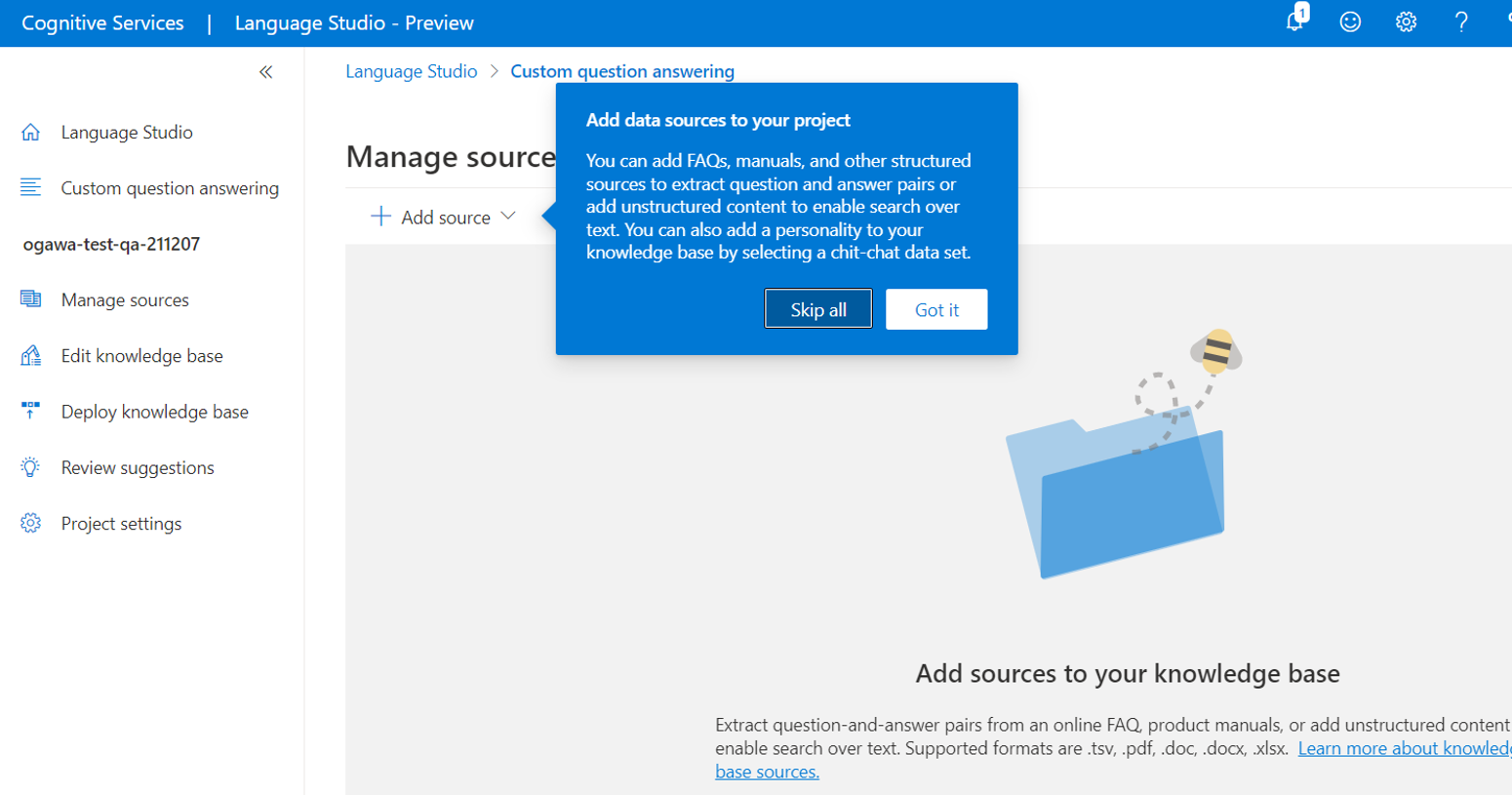
(9)以下の図のように、「Add data sources to your project」と案内が出ますが、ひとまず「Skip all」をクリックします。後ほど設定していきます
3. 「ナレッジベース」にソースとなるファイルを追加する
(1)今回は東京都の防災ホームページから「【12月1日から】基本的対策徹底期間における対応(令和3年11月25日発表)」ページのPDFをソースファイルとします
(サイトURL)【12月1日から】基本的対策徹底期間における対応(令和3年11月25日発表)
https://www.bousai.metro.tokyo.lg.jp/1009757/1020631.html
(2)上記サイトの、別紙のPDFをソースファイルとすることにします。
このたび、基本的対策徹底期間について、別紙のとおり取りまとめましたので、お知らせします。
添付ファイル
基本的対策徹底期間における対応 (PDF 727.3KB)
https://www.bousai.metro.tokyo.lg.jp/_res/projects/default_project/_page_/001/020/631/20210928/20211125a.pdf
PDFの様子は以下となります
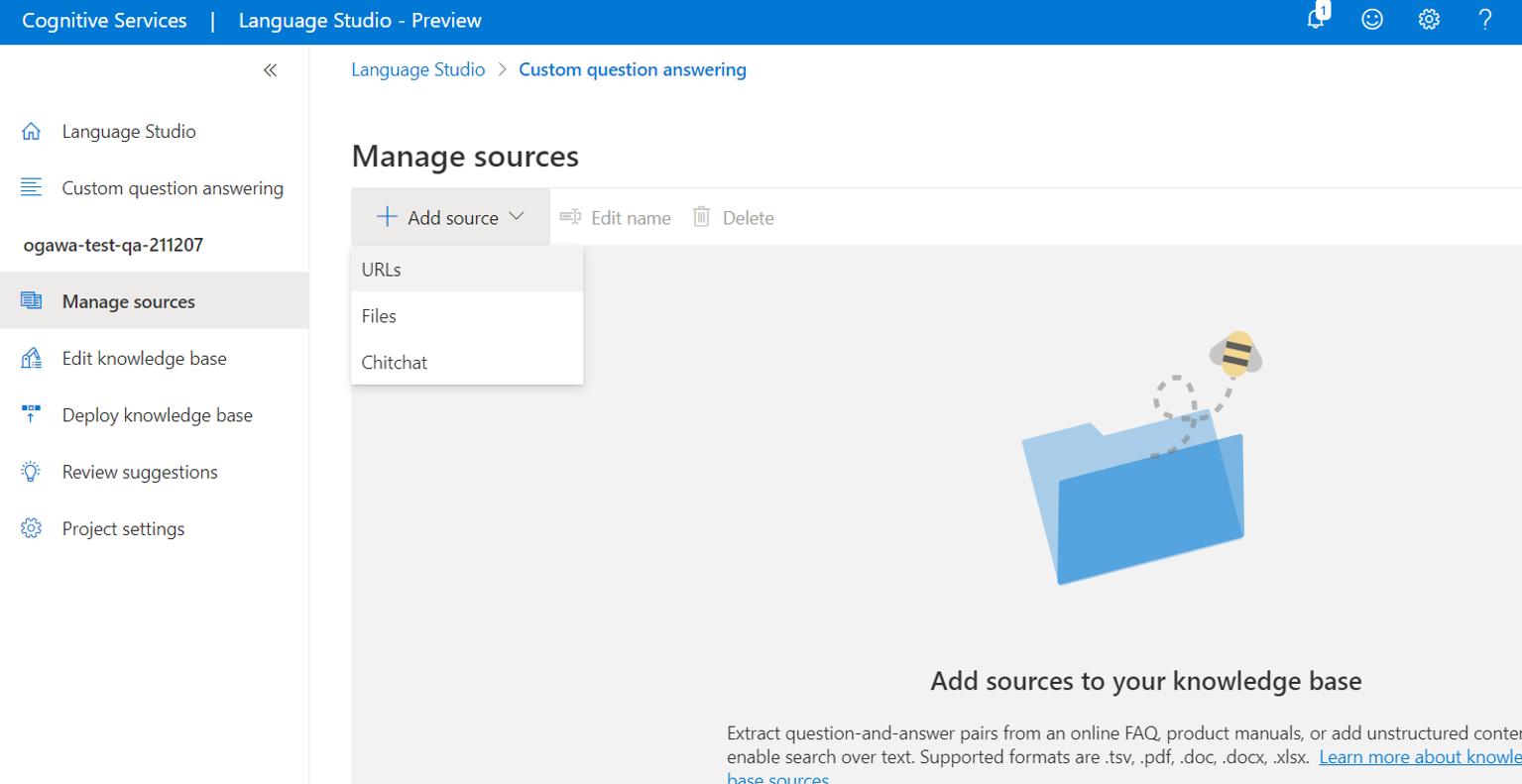
(3)以下の図のように、「Language Studio」の左側メニューの「Manage sources」を選択し、「+Add source」からURLsを選択して、
先のPDFのURLを追加します。Classify file structureは「Auto-detect」にして、「Add all」ボタンをクリックします
(なおURLの指定ではなく、PDFファイルが手元にある場合はファイルのアップロードでも可能です)
(4)以下の図のように、アップロードと処理が完了すると、「Look at questions from one source」と表示されます
(5)以下の図のように、アップロードしたソースをクリックすると、「Add a new question」と表示されます。
通常のQnAのように、あらかじめ想定質問と回答を用意する場合はここで設定していきます。
今回は想定質問と回答のナレッジベースは作成せずに進めます。
質問と回答ペアのナレッジベースを作成せずに質問応答(question answering)できることが、本サービスの利点です
※もちろん、これまでのQnA Makerで構築済みの質問と回答ペアのナレッジデータベースや、新たなナレッジベースを作成して、この質問応答(question answering)と融合させることもできます。
4. 「Language Studio」から動作確認をする
(1)以下の図の矢印、上側メニューの「Test」をクリックします
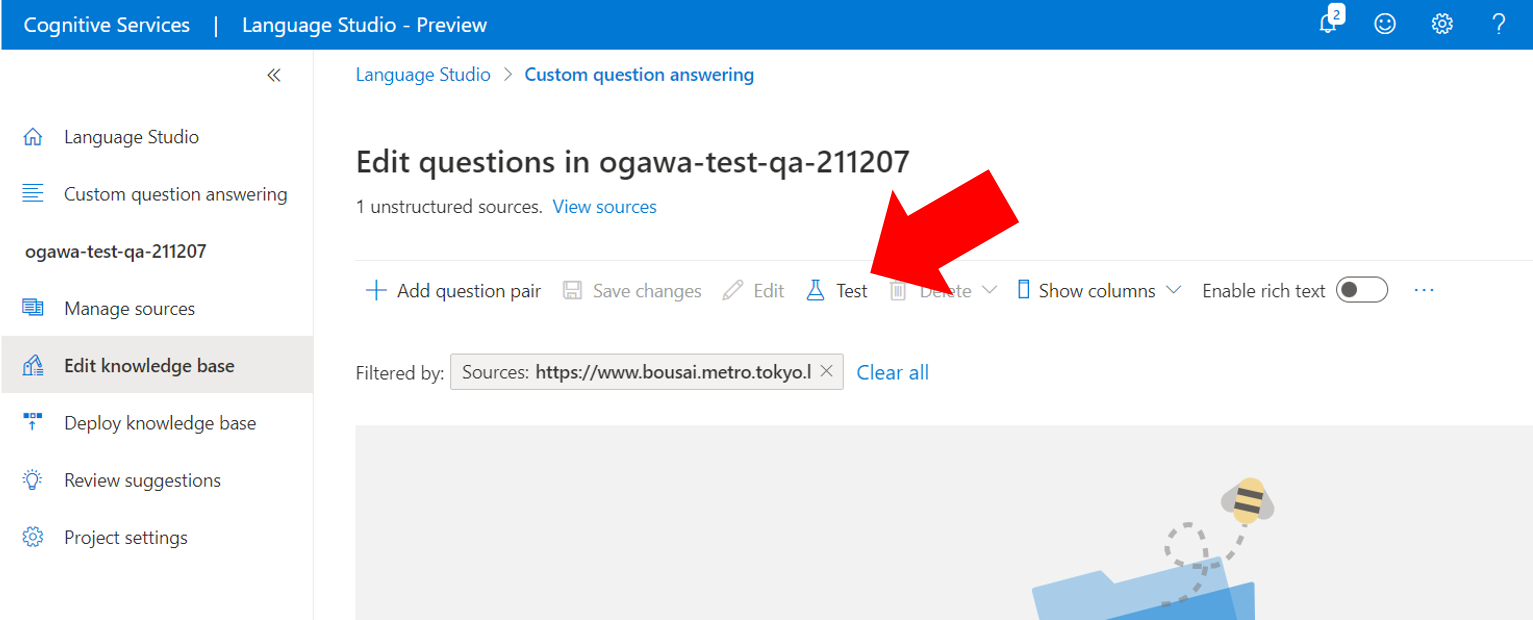
(2)画面右側に「Response options」が開くので、「Include short answer response」にチェックを入れます
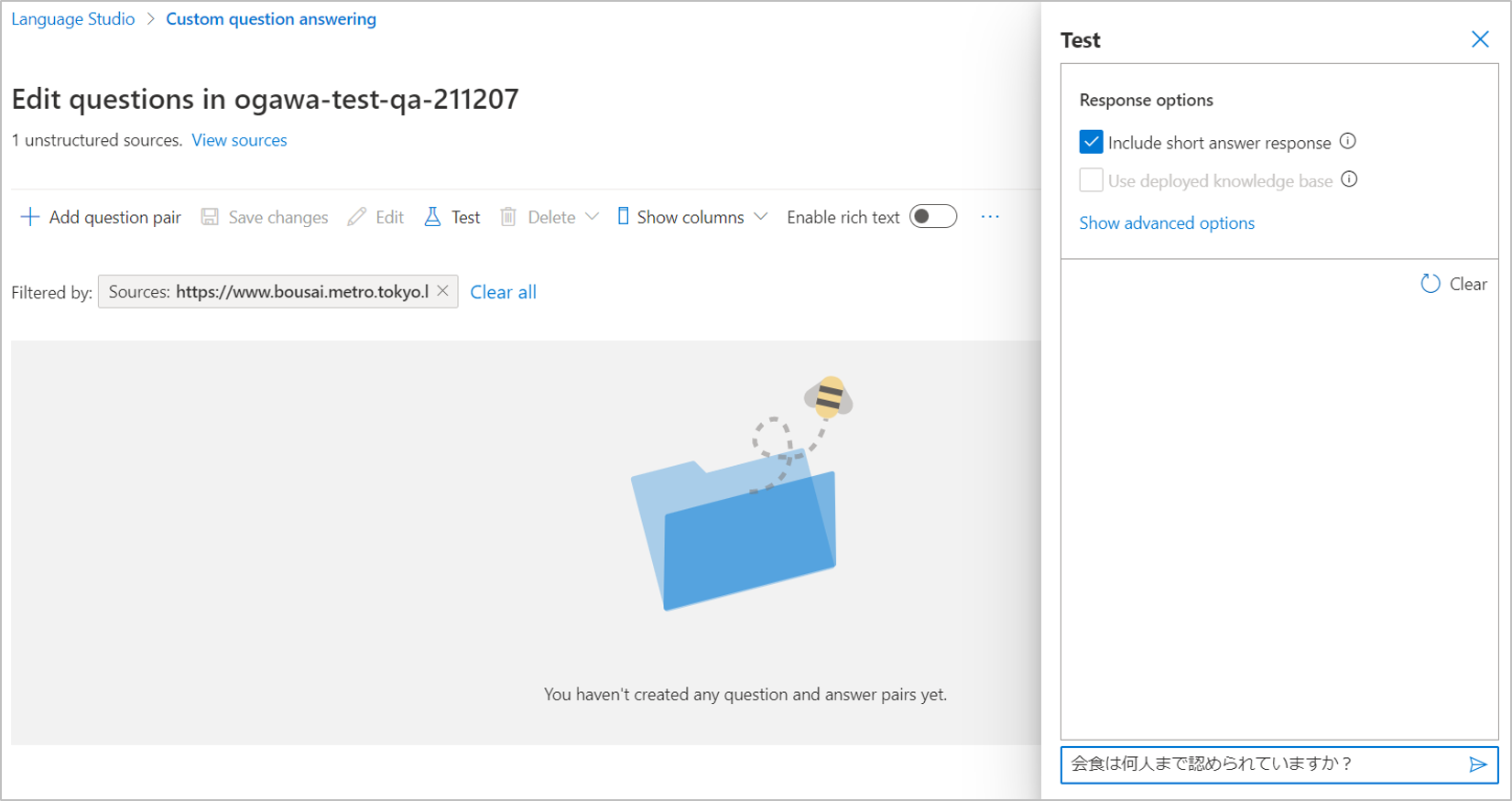
(3)画面右下の「Type your message and press enter」の入力欄に質問を記入して、Enterキーを押します。質問は**「会食は何人まで認められていますか?」**とします。
(4)結果が以下の画面です。「Short answer」が「都民」、「Long answer」には「同一グループの同一テーブルへの入店案内を8人以内 とするよう協力を依頼」の文章が含まれています。
「Short answer」が「8人」となっておらず、「都民」なので、想定通りではない残念な結果です。
そもそも放り込んだソースのPDFファイルの回答となった該当部分は以下のような表になっており、これだけ非構造なファイルからでは難しいものがあるようです。

ただ、Long answerには求める内容(同一グループの同一テーブルへの入店案内を8人以内)が返ってきた点は良いですね。
(5)さすがに元のソースPDFの構造が難しすぎるので、もう少し文章になっているページもソースに追加します。複数のソース文書をプロジェクトには追加できます。左側メニューの「Manage sources」をクリックし、上側の「+Add source」をクリックします
(6)「URLs」を選択し、「【12月1日から】基本的対策徹底期間における対応 質問と回答」のサイトページ(https://www.bousai.metro.tokyo.lg.jp/1009757/1020629.html)を追加します。
自動の質問回答サービスを作ろうと試しているのに、「質問と回答」が書かれたHPページをソースに使用するのは微妙すぎです(それならそのページからQnAでナレッジベース作れるし)。
ですが、今回は仕方なくOKとします。。。
なお、アップロード時のClassify file structureは「Auto-detect」としました。
(7)再度、上側メニューの「Test」をクリックし、「Response options」を開き、「Include short answer response」にチェックを入れます
(8)画面右下の「Type your message and press enter」の入力欄に質問を記入して、Enterキーを押します。
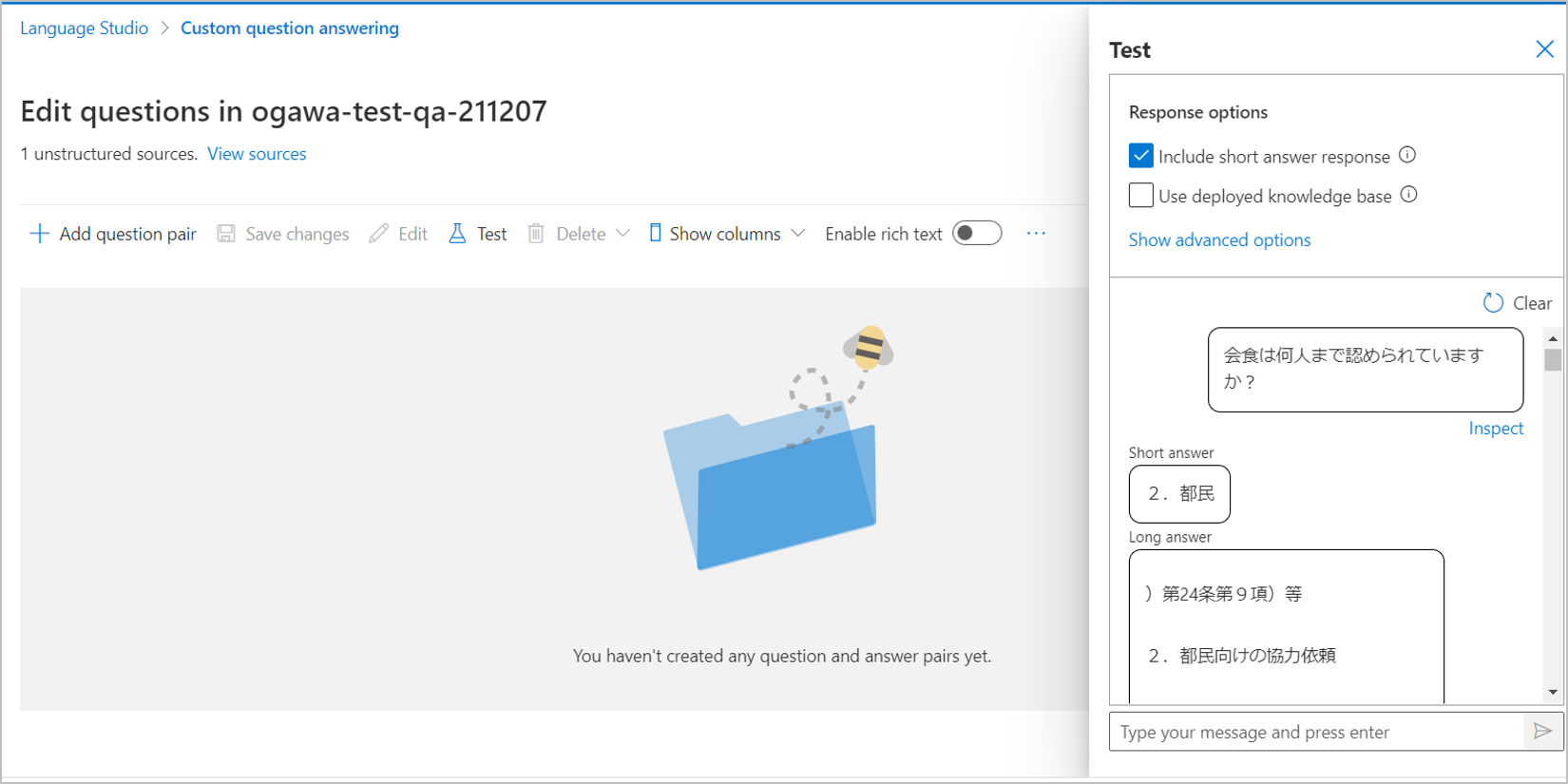
今度は入力文を「何人まで食事は認められていますか?」としましょう
(9)結果は以下の図の通りです。
「Short answer」が「8人」、「Long answer」には「A2:忘年会や新年会など、特に大人数の会食が増加することが想定される年末年始において、特に大人数での会食における感染リスクを低減するため、「同一テーブル8名以内の利用」をお願いしています。」
が返ってきました。
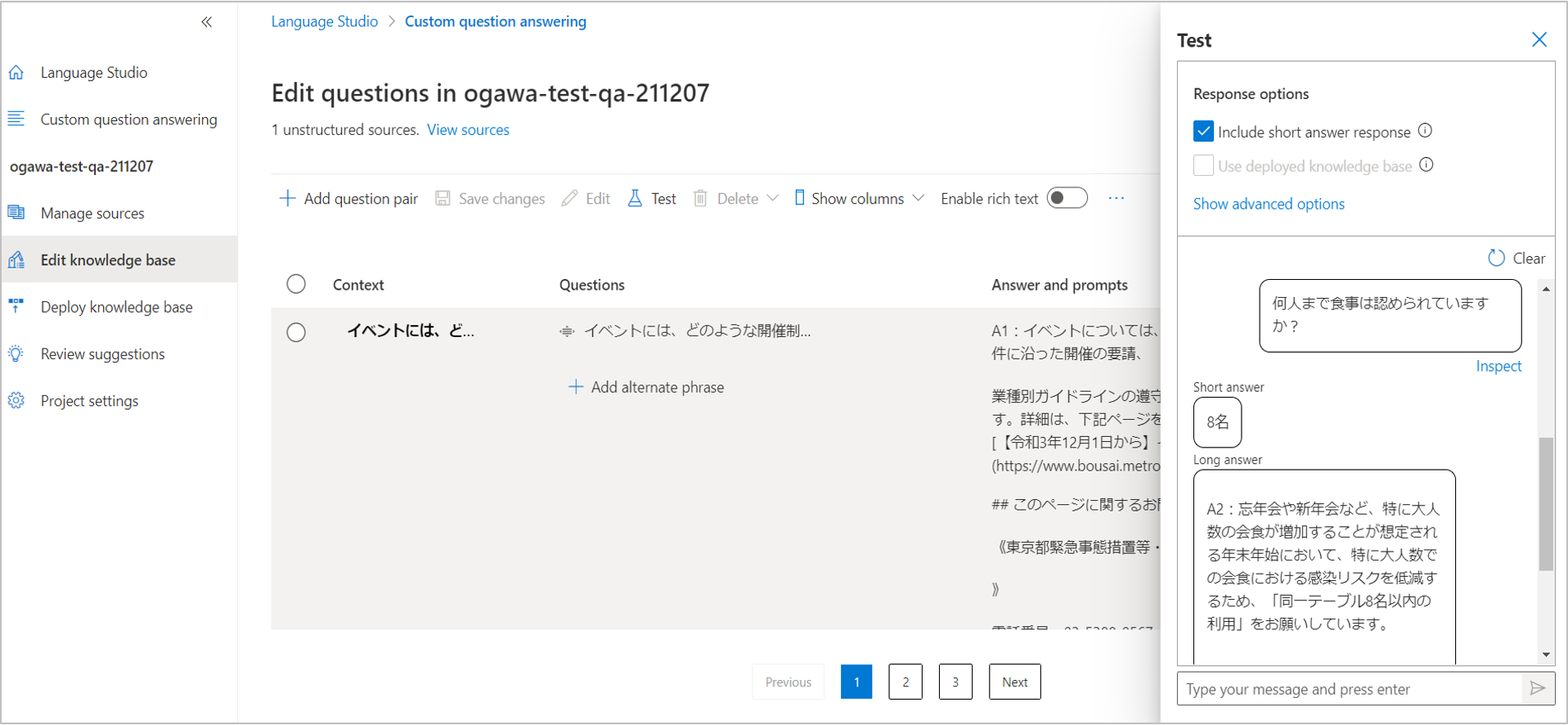
今回返却された「Long answer」はもともとソースのURLでは、
質問「認証店において、同一グループの同一テーブルへの入店案内を8人以内としているのはなぜか。」
への回答部分です。
HPに記載されている質問文章は今回の質問と意図が違うのですが、Question answeringが適切な回答部分を自動で選択し、端的に「Short answer」では「8名」、「Long answer」でより詳細部分を返してくれました。
5. 「Language Studio」からデプロイする
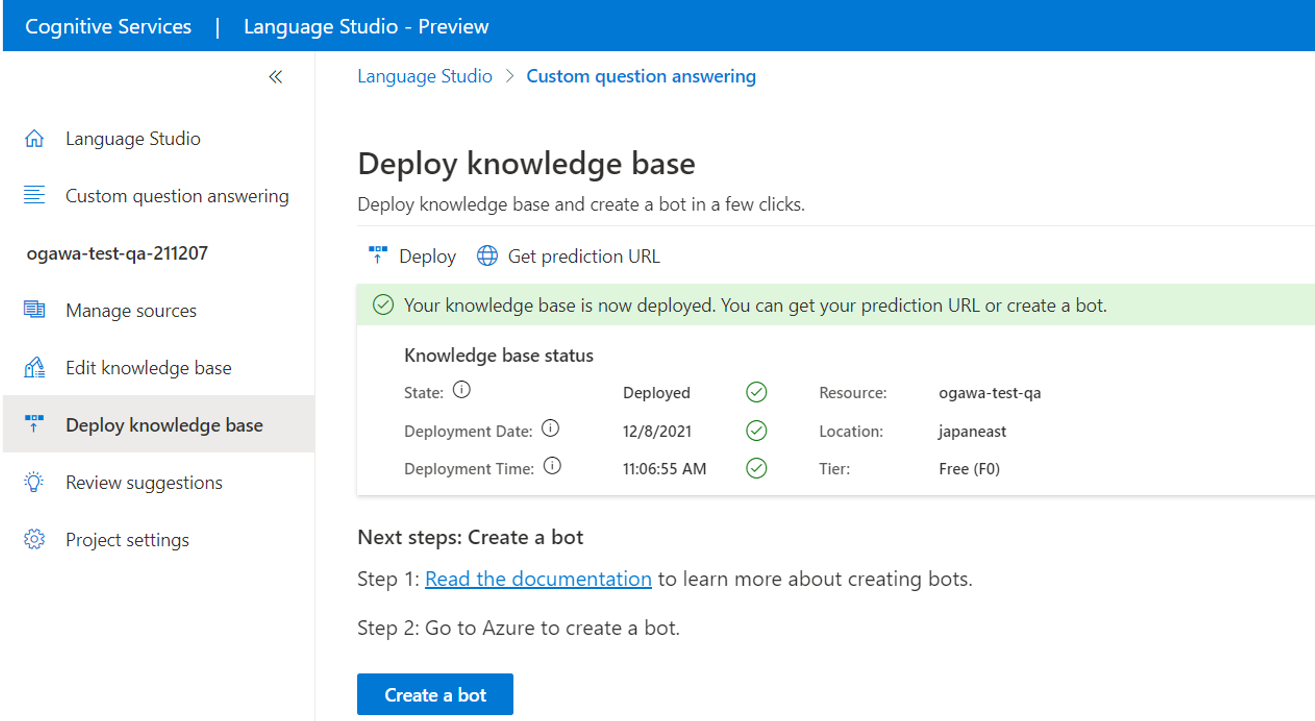
(1)左側メニューの「Deploy knowledge base」をクリックします
(2)下図の赤矢印で示す、上側メニューの「Deploy」をクリックします
(3)「Deploy this project?」と尋ねられるので、「Deploy」をクリックします
(4)1-2分でDeployが完了し、以下の図のような画面になります。この画面の「Create a bot」ボタンからチャットボットの作成も可能です(本記事ではチャットボット作成は省略します)
6. Python SDKを使用し、質問応答を行う
(1)「Language Studio」でDeployしたサービスの情報を取得します。
必要な情報は、endpoint(叩き先のURL)、credential(key)、knowledge_base_project(質問応答プロジェクトの名前)です
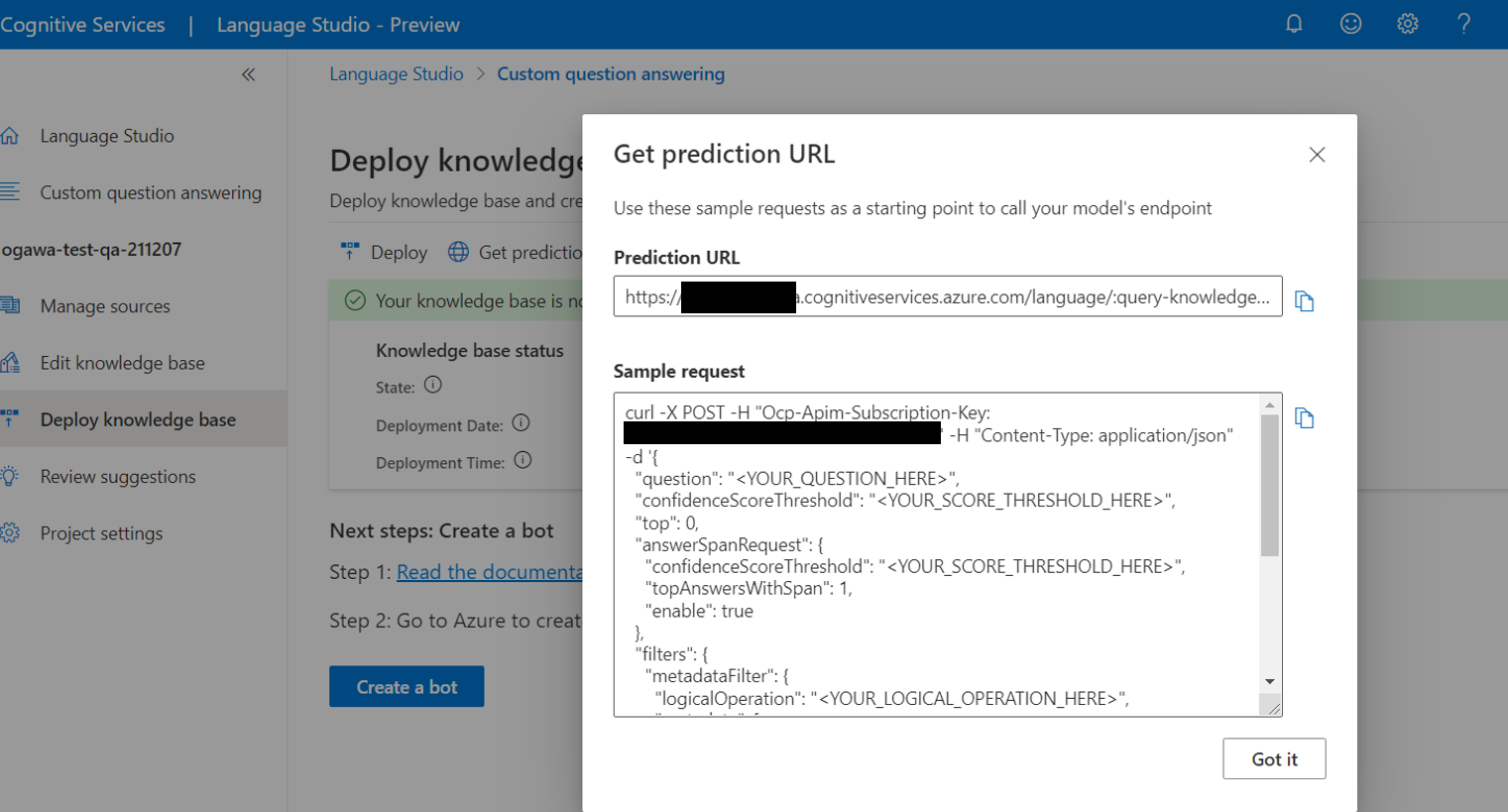
(2)先ほどのDeploy完了画面の上側メニューにある「Get prediction URL」をクリックします
(3)すると以下の図のように、curlで叩く例が表示されるので、ここからendpointのURLとcredentialのkey(Ocp-Apim-Subscription-Key)、そしてprojectNameをコピーしておきます
(4)以下、Google ColabでPythonを使用し、質問を投げて、回答を得るプログラムを実装します。Jupyter Notebookのプログラム本体はGitHubにも置いております。
実装プログラムのGitHubリポジトリ:
https://github.com/YutaroOgawa/Japanese_example_of_azure_question-answering
プログラム名
japanese_example_of_azure_question answering.ipynb
(5)まずAzureの質問応答(question answering)のライブラリをインストールします
!pip install azure-ai-language-questionanswering
(6)設定値を代入します(今回はセキュリテイを無視して直接代入していますが、本番環境では重要情報なのでご注意を)
# 参考
# https://docs.microsoft.com/ja-jp/azure/cognitive-services/language-service/question-answering/quickstart/sdk?pivots=programming-language-python
from azure.core.credentials import AzureKeyCredential
from azure.ai.language.questionanswering import QuestionAnsweringClient
endpoint = "https://ogawa-test-qa.cognitiveservices.azure.com/" # みたいな、endpointのURL
credential = AzureKeyCredential("{YOUR-LANGUAGE-RESOURCE-KEY}")
knowledge_base_project = "{YOUR-PROJECT-NAME}"
deployment = "production"
(7)質問を投げ、応答を取得します
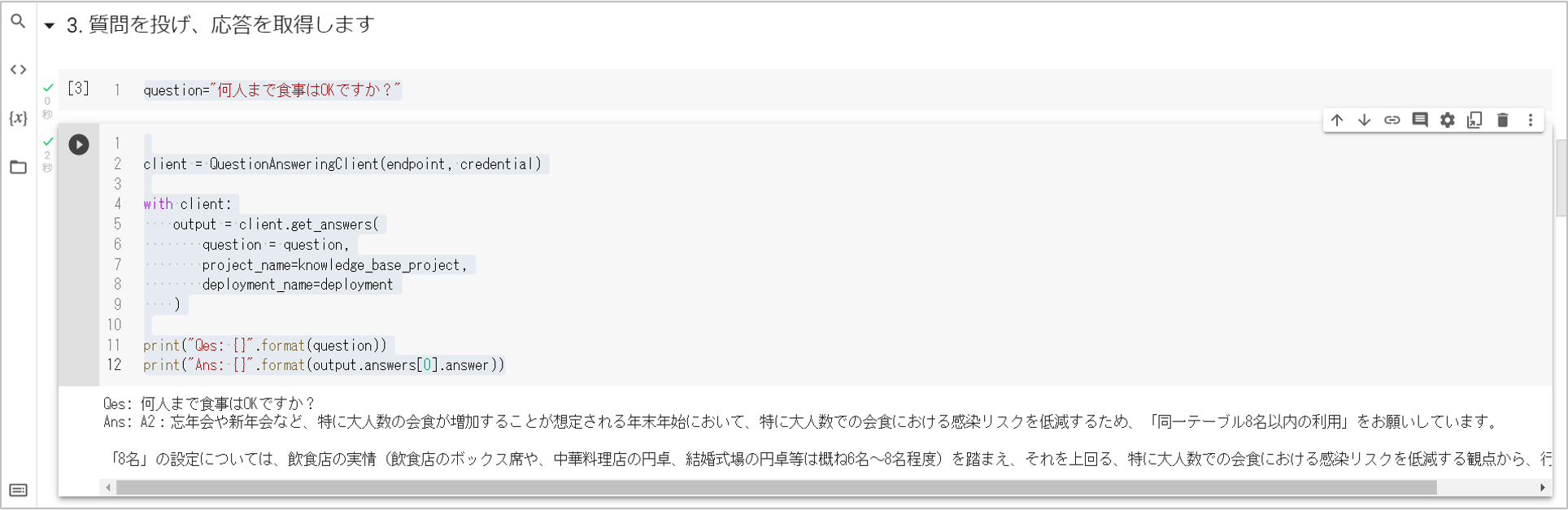
question="何人まで食事はOKですか?"
client = QuestionAnsweringClient(endpoint, credential)
with client:
output = client.get_answers(
question = question,
project_name=knowledge_base_project,
deployment_name=deployment
)
print("Qes: {}".format(question))
print("Ans: {}".format(output.answers[0].answer))
すると、以下のように回答が得られます。「Language Studio」で試していたときと同様です。
(8)続いて、SDKの解説から引数などを確認し、short answerを返すようにします。
実装としては、まずshort answerクラスの設定オブジェクトを作成します。
# short answerの設定
# https://azuresdkdocs.blob.core.windows.net/$web/python/azure-ai-language-questionanswering/1.0.0/azure.ai.language.questionanswering.models.html#azure.ai.language.questionanswering.models.ShortAnswerOptions
from azure.ai.language.questionanswering.models import ShortAnswerOptions
short_answer_options = ShortAnswerOptions()
short_answer_options.enable = True
そして作成した設定オブジェクトを設定として与えます。
question="何人まで食事はOKですか?"
client = QuestionAnsweringClient(endpoint, credential)
with client:
output = client.get_answers(
question = question,
project_name=knowledge_base_project,
deployment_name=deployment,
short_answer_options = short_answer_options # 追加しました
)
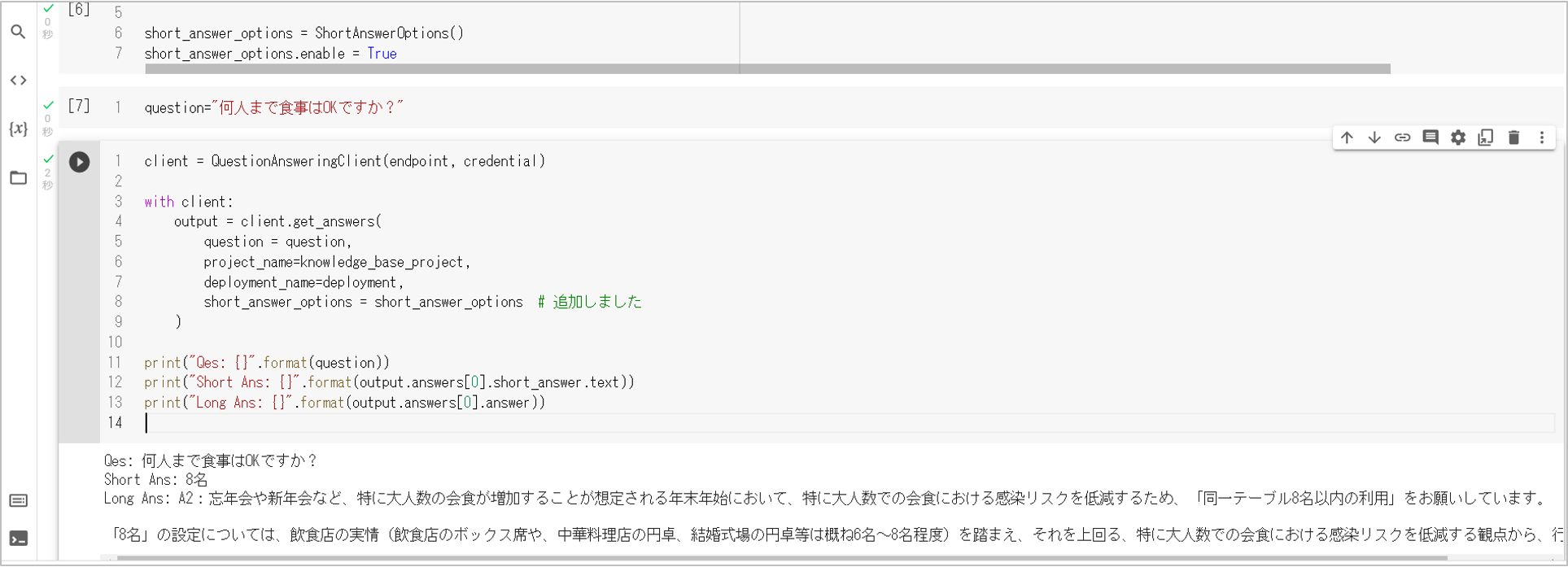
print("Qes: {}".format(question))
print("Short Ans: {}".format(output.answers[0].short_answer.text))
print("Long Ans: {}".format(output.answers[0].answer))
すると、以下のように回答が得られます。「Language Studio」で試していたときと同様です。
7. ナレッジベースを使用せず、文章も入力して、質問応答を行う
さいごにPython SDKから、ナレッジベースのソース文書を使用せず、文書も質問と同様に与え、回答を取得する方法を解説します。
(1)まずは与える文章を用意します。
# 与える文章を用意します。こちらの富士見高原スキー場のサイトから文章をお借りします
# https://fujimikogen-ski.jp/guide/beautifulscenery.html
text_documents = ('第一リフト頂上から徒歩3分。'
'創造の森・望郷の丘展望台は、富士山や南アルプス、北アルプスを望む絶景ポイントで、日本の高い山 1位~3位 を見ることができます。'
'創造の森は、長靴で散策ができます。寒い冬は空気が澄み、特に眺望が楽しめます。'
'日本の高い山トップ3を一度に見られるチャンスはそうそうあるものではありません。富士見高原スキー場でぜひご覧ください。'
'日本の高い山 トップ3'
'1位 富士山 '
'2位 北岳(南アルプス)'
'3位 奥穂高岳(北アルプス)'
'「関東の富士見百景色」にも 選ばれている絶景スポットです。')
(2)叩くURLは先ほどまでと同じです。
※Question answeringのプロジェクトのソース文書を使用しないのですが、Question answeringのプロジェクトをdeployして、URLのエンドポイントを用意しておく必要があります。
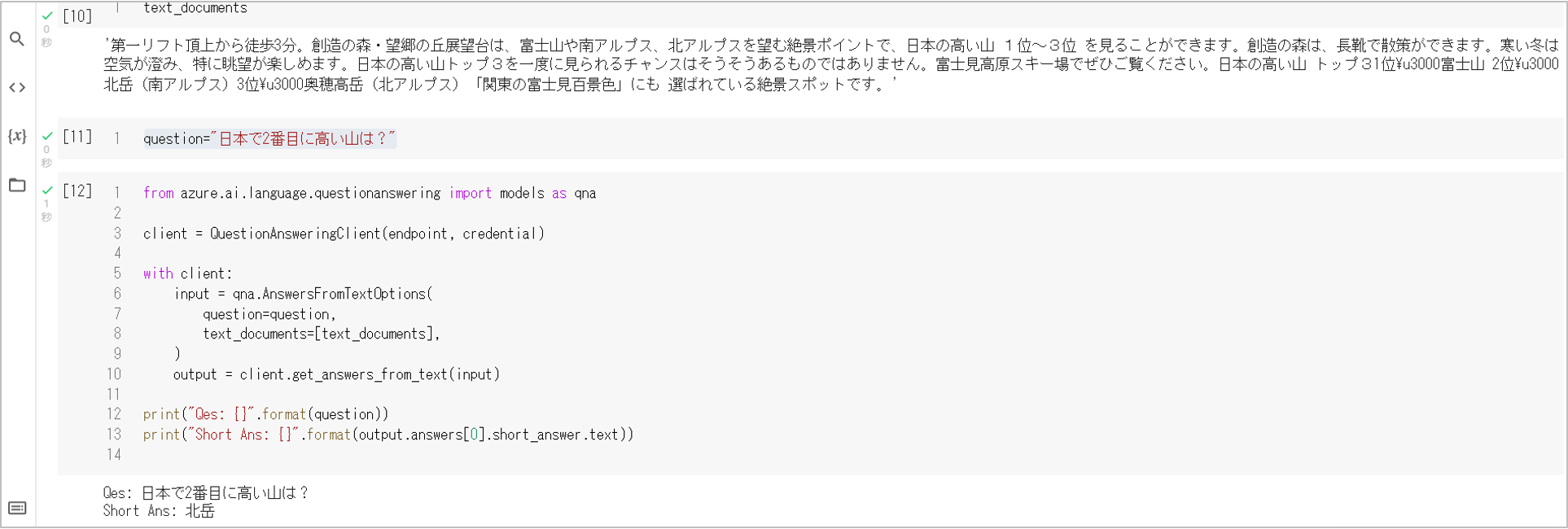
上記の文章と一緒に質問を与えます。質問は「日本で2番目に高い山は?」としてみます。
from azure.ai.language.questionanswering import models as qna
question="日本で2番目に高い山は?"
client = QuestionAnsweringClient(endpoint, credential)
with client:
input = qna.AnswersFromTextOptions(
question=question,
text_documents=[text_documents],
)
output = client.get_answers_from_text(input)
print("Qes: {}".format(question))
print("Short Ans: {}".format(output.answers[0].short_answer.text))
結果は以下の図の通りです。「北岳」と答えがきちんと返ってきました。
8. さいごに
以上、プロジェクトを作成し、ソース文書をアップロードしておけば、質問を投げると自動で回答を返すAzure Question answeringについて、日本語で使用する方法を実装解説しました。
このサービスは非常に便利な面もありますが、回答として返却されるものがナレッジベースの際と異なり、コントロールが効かないので、運用には非常に気をつける必要があります。
とくに個人や社会に影響を及ぼす内容のQndAに使うのは、非常に気をつける必要があります。
本記事で例に出したCOVID-19の対策に関するQAなども、今回の例で正解が8名なのは、”「感染防止徹底点検済証」の交付を受け、かつ、これを店頭に掲示している店舗”であり、そうでない店舗の場合は「4名」が正解です。
回答は「文書ソースからの抽出型」で作成されるので、自動文章生成で回答を作られるよりは安全ですが、それでも誤答を返し、ユーザーが勘違いして行動するのは避けたいところです。
一方で、製品カタログや製品の説明書、社内ルールの文書から自動で回答を返すなど、回答が誤っていてもその影響が小さそうな場面では、本サービスは非常に有用かと思います。
(今後、もっとたくさんのデータと質問で日本語での性能は確認する必要はありますが)
また、ナレッジベースを作って運用する作戦でも、本サービスを使用して一気にナレッジベースの原型を作り、その後で人手でブラッシュアップする方法も考えられます。
その他、wikipediaの全ページをソースとしてアップしておけば、情報を「検索」するのではなく、情報から「答えを尋ねる」という、セマンティックサーチの進化版みたいなことも可能かもしれません。
「だんだんと凄い世界になってきたな~。ノーコードでここまでとは」と、この分野にいる私も驚きです。
Azure Question answeringは使い方、運用に気を付ければ、素晴らしいサービスになりそうです。
以上、長文をご一読いただき、ありがとうございました。
【記事執筆者】
電通国際情報サービス(ISID)AIトランスフォーメーションセンター 製品開発Gr
小川 雄太郎
主書「つくりながら学ぶ! PyTorchによる発展ディープラーニング」
自己紹介(詳細はこちら)
【情報発信】
Twitterアカウント:小川雄太郎@ISID_AI_team
IT・AIやビジネス・経営系情報で、面白いと感じた記事やサイトを、Twitterで発信しています。
【免責】
本記事の内容そのものは執筆者の意見/発信であり、執筆者が属する企業等の公式見解ではございません