本記事では英語の発音に関して自動で評価を行う、Azure Cognitive Services Speech SDKの「発音評価(Pronunciation assessment)」の使用方法と実装を解説します。
本記事の内容
0. Azureの「発音評価(Pronunciation assessment)」とは
1. リソース「Speech service」の作成
2. SDKを利用した開発環境の用意(Python)
3. まずは音声認識からはじめてみましょう
4. 発音評価を実施する
5. さいごに
0. Azureの「発音評価(Pronunciation assessment)」とは
Azureの「発音評価(Pronunciation assessment)」はAzure Cognitive ServicesのSpeechサービスの一機能です [link1] , [link2] 。
Speechサービスでは音声認識(文字起こし)や音声翻訳などの機能が用意されています。
「発音評価(Pronunciation assessment)」機能の公式ドキュメント(日本語)はこちらになります [link]。
発音評価ではスピーチの発音を評価し、話された音声の正確性と流暢性に関するフィードバックを話者に提供します。 言語学習者は、発音評価を使用して練習を行い、即座にフィードバックを得て、発音を改善することができます。そのため、自信を持って話し、発表することができます。 教師がこの機能を使用すれば、複数の話者の発音をリアルタイムに評価することができます。
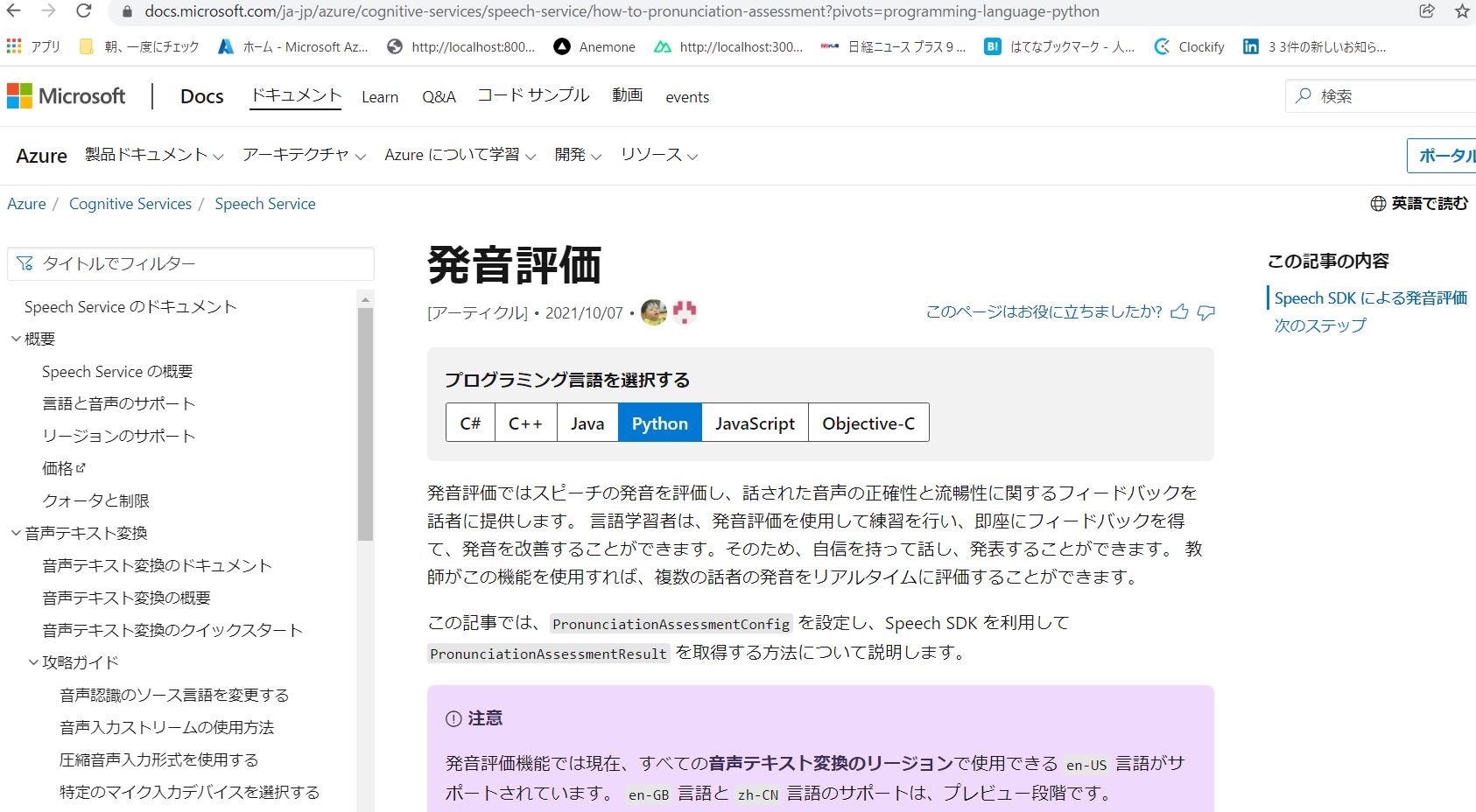
評価される主な指標を上記のサイトより引用紹介します。
| 出力パラメータ | 説明 |
|---|---|
| AccuracyScore | 音声の発音精度。 精度は、音素がネイティブ スピーカーの発音とどれだけ厳密に一致しているかを示します。 単語およびフル テキスト レベルの精度スコアは、音素レベルの精度スコアから集計されます。 |
| FluencyScore | 音声の流暢性。 流暢性は、音声がネイティブ スピーカーによる単語間の間の取り方にどれだけ厳密に一致しているかを示します。 |
| CompletenessScore | 音声の完全性。テキスト入力を参照するために発音された単語の比率を算出することで判断されます。(※小川注釈:入力文の単語のうち、何単語をきちんと発音したかを示します) |
| PronunciationScore | 音声の発音品質の良さを表す総合スコア。これは、重み付きの AccuracyScore、FluencyScore、および CompletenessScore から集計されます。 |
1. リソース「Speech service」の作成
AzureのCognitive ServicesではSpeechやTextなどを包括的にまとめて扱えるリソースと、そこからSpeech関連だけなど、特定機能のCognitive Serviceだけを取り出したリソースを作ることができます。
今回は、Cognitive Services リソースを作成(=プロビジョニング)することにします。
(1)Auzreポータルにサインインします
(2)+「リソースの作成」 ボタンを選択し、Cognitive Services と検索し、Cognitive Services リソースを作成します(価格レベルはStandard S0とします。その他は自由に。)
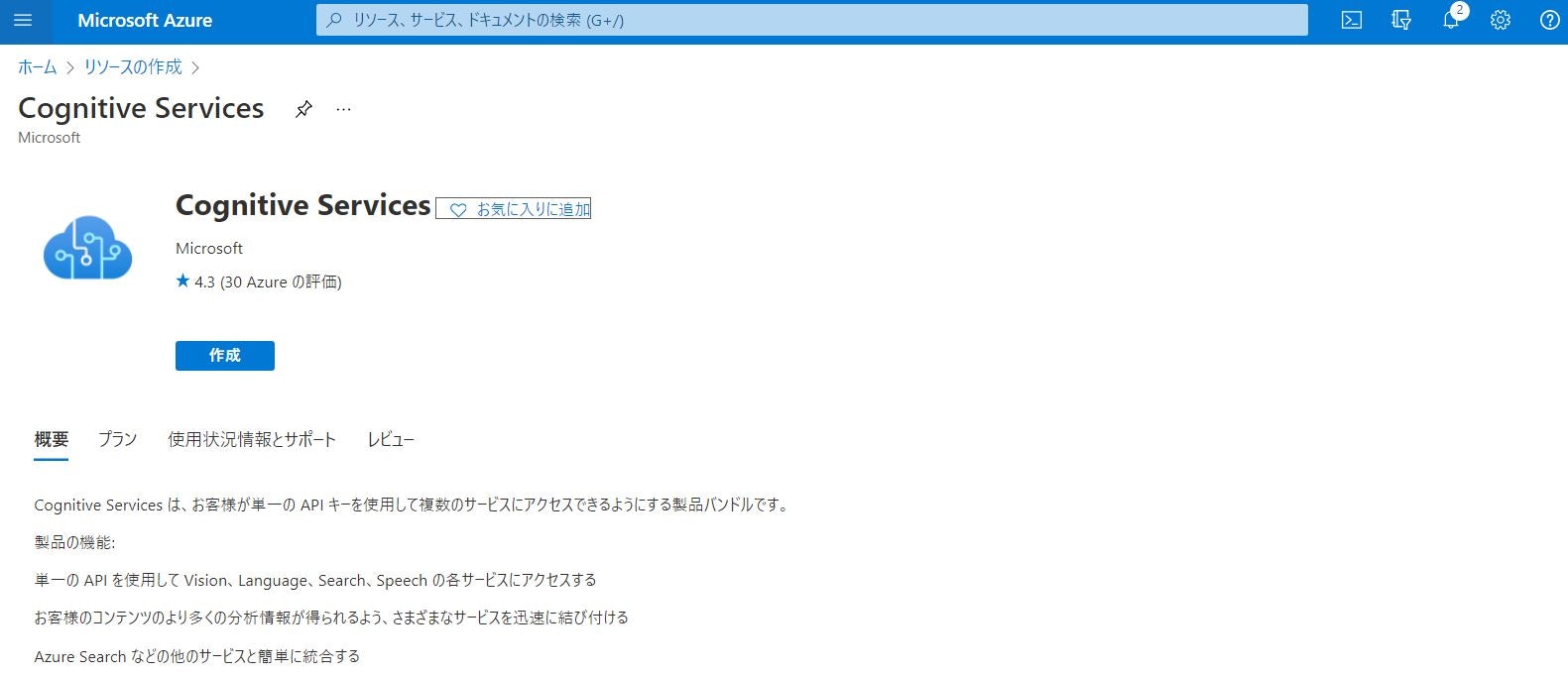
(3)Cognitive Services リソースのデプロイが完了したら、リソースに移動し、左側メニューから「キーとエンドポイント」をクリックします。このページに表示されている「キー 1」、「場所/地域」、「エンドポイント」の値をそれぞれどこかにコピーして記録しておきます(後ほど使用します)。
2. SDKを利用した開発環境の用意(Python)
続いて、Azure Cognitive ServicesをSDKで開発する環境を用意します。
SDKは様々なプログラミング言語で開発できますが、今回はPythonを使用することにします。
(1)開発環境は自分のローカルPCに用意しても良いのですが、さくっと試すだけであれば、AzureのVMのAI用のイメージである「Data Science VM(DSVM)のWindows版」を立ち上げてしまうのがおススメです [link]。
AI系の必要なライブラリやVS codeやその拡張機能などが全部用意済みなので、RDPで入って、すぐに開発を始められます(マシンはNC6かNC6 promoあたりにし、GPUも必要に応じて使えるようにしておくと便利です)。
本記事ではさらに簡便に済ませるために、Google Claboを使用します。
なお実装プログラムはGitHubにも置いております。
実装プログラムのGitHubリポジトリ:
https://github.com/YutaroOgawa/example_of_azure_pronunciation_assessment
(2)PythonのSpeech用のSDKをpip installします。
pip install azure-cognitiveservices-speech
Installing collected packages: azure-cognitiveservices-speech
Successfully installed azure-cognitiveservices-speech-1.19.0
記事執筆時の最新の1.19.0がインストールされました [link pypi]
3. まずは音声認識からはじめてみましょう
英語の発音評価に向けて、まずは簡単なところからスタートするのが良いです。
そこで音声認識を実施してみるところからはじめましょう。
その後、その音声の発音評価へと進化させていきます。
(1)まず音声認識の対象ファイルを用意します。
マイク入力ももちろん可能ですが、ローカル環境ではなく、仮想マシンやGoogle Colabの場合はファイルの方が扱いやすいため、本記事では音声入力には.wav形式のファイルを使用します。
音声ファイルには、
に用意されている、time.wavというファイルを使用します。
このファイルでは「what time is it?」という文章が発音されています。
まずはこの音声ファイルから”what time is it?”を文字起こし(音声認識)できるかを試します。
(2)以下、Google ColabでPythonを使用し、アップロードしたtime.wavファイルを読み込ませて、音声認識をします。なおJupyter Notebookのプログラム本体はGitHubにも置いております。
実装プログラムのGitHubリポジトリ:
https://github.com/YutaroOgawa/example_of_azure_pronunciation_assessment
(3)以下のようにGoogle Colabでtime.wavファイルをアップロードしておきます。
それではGoogle Colabでの実装に移ります。
[3-1] AzureのCognitive Servicesのspeech SDKをインストールします。
# [1] AzureのCognitive Servicesのspeechのインストール
!pip install azure-cognitiveservices-speech
[3-2] 使用するパッケージをimportします
# [2] 使用するパッケージなどのimport
import json
import azure.cognitiveservices.speech as speech_sdk
[3-3] Azure Cognitive Servicesのリソースを作成(プロビジョニング)した際に、リソースに用意された「キー 1」、「場所/地域」の値を設定します。
今回はプログラム内に直書き(ハードコーディング)しており、セキュリテイ面を無視しているので、その点はご注意ください。
以下のyour_hogehogeをご自身のリソースの値に書き換えてください。
# [3] keyとregionの設定
# 今回はセキュリテイを無視していますが、本番環境では重要情報なのでご注意を
COG_SERVICE_KEY="your_cognitive_services_key"
COG_SERVICE_REGION="your_cognitive_services_location"
[3-4] SpeechConfigを設定します。この設定により、Azure Cognitive ServicesのSpeech機能が使えるようになります。speech_config.regionをprintしてみて、きちんと設定できているか確かめておきます。
# [4] SpeechConfigの設定
# 今回はセキュリテイを無視していますが、本番環境では重要情報なのでご注意を
speech_config = speech_sdk.SpeechConfig(COG_SERVICE_KEY, COG_SERVICE_REGION)
print('speech serviceのregionはこちらに設定しました:', speech_config.region)
[3-5] 使用する音声ファイルのパスを設定します。Google Colabに左側のメニューからtime.wav(さきほど説明したファイルです)をアップロードしておき、それを使用します。
# [5] 使用するファイルの設定
audioFile = '/content/time.wav'
[3-6] 続いてAudioConfigを設定します。このAudioConfigがSpeech SDKで使用する音声関連の設定となります。ここでは単に[5]で指定した音声ファイルをAudioとして使用してください、と設定しているのみです。
# [6] AudioConfigの設定
audio_config = speech_sdk.AudioConfig(filename=audioFile)
[3-7] SpeechRecognizerを作成します。SpeechRecognizerは先ほど作成したSpeechConfigとAudioConfigに従い、音声処理をするためのオブジェクト、元となる要素です。
# [7] SpeechRecognizerの設定(SpeechConfigとAudioConfigを設定時に使用します)
speech_recognizer = speech_sdk.SpeechRecognizer(speech_config, audio_config)
[3-8] 作成したSpeechRecognizerで音声処理(音声認識=文字起こし)を実施します。
音声ファイルの内容通り、**What time is it?**と認識してくれました。
# [8] SpeechRecognizerで音声処理(音声認識)
speech_result = speech_recognizer.recognize_once_async().get()
print("次の音声と認識しました:", speech_result.text)
結果
次の音声と認識しました: What time is it?

以上で音声ファイルに対する音声認識は完了です。
続いてはここに発音評価の要素を付け加えていきます。
4. 発音評価を実施する
[4-1] まずは発音しているスクリプトを用意します。今回は音声ファイルがネイティブスピーカーの方の短い文章なので、スクリプトを変更しないと(当然ですが)満点が出てしまうので、実際の音声とスクリプトを少し異なるものにします。
音声はWhat time is it?ですが、**'What time is it now in Japan ?'**と発音していることにしましょう。
# [1] 発音している単語のスクリプトを用意します
script = 'What time is it now in Japan ?'
[4-2] PronunciationAssessmentConfigを設定します。
以下、設定の詳細説明のリンクを掲載します。
・参考記事
・SDK解説:azure-cognitiveservices-speech Package
・SDK解説2
・プログラム参考
# [2] AudioConfigの設定
pronunciation_config = speech_sdk.PronunciationAssessmentConfig(reference_text=script,
grading_system=speech_sdk.PronunciationAssessmentGradingSystem.HundredMark,
granularity=speech_sdk.PronunciationAssessmentGranularity.Word)
[4-3] SpeechRecognizerを設定します。さきほど[3-7]で設定したものと同じ内容です。
# [3] SpeechRecognizerの設定(SpeechConfigとAudioConfigを設定時に使用します)
speech_recognizer = speech_sdk.SpeechRecognizer(speech_config, audio_config)
# 先ほど[7]で設定したものと同じ内容です
[4-4] 発音評価を実施します。[4-1]で設定したPronunciationAssessmentConfigにSpeechRecognizerを適用します。そしてSpeechRecognizerで音声処理を実施して結果resultを取得します。
# [4] 発音評価:Pronunciation Assessmentの実施
pronunciation_config.apply_to(speech_recognizer)
result = speech_recognizer.recognize_once()
[4-5] 発音評価の結果を扱いやすいようにオブジェクト化するPronunciationAssessmentResultクラスに変更します。
# [5] 発音評価:Pronunciation Assessmentの結果をまとめたオブジェクトを作成
pronunciation_result = speech_sdk.PronunciationAssessmentResult(result)
[4-6] スクリプト全文に対する発音評価の結果を出力します。
# [6] 発音評価の結果を表示(全文での)
print('Accuracy score: {}, fluency score: {}, completeness score : {}, pronunciation score: {}'.format(
pronunciation_result.accuracy_score, pronunciation_result.fluency_score,
pronunciation_result.completeness_score, pronunciation_result.pronunciation_score
))
結果
Accuracy score: 69.0, fluency score: 53.0, completeness score : 86.0, pronunciation score: 62.8

得点は100点満点です。Scriptが「What time is it now in Japan ?」に対して、「What time is it ?」という音声ファイルを評価させているので当然点数が低くなっています。
[4-7] スクリプトの各単語に対する発音評価の結果を出力します。
# [7] 発音評価の結果を表示(単語ごとに)
for word_result in pronunciation_result.words:
print('単語:{}, Accuracy score:{}'.format(word_result.word, word_result.accuracy_score))
結果
単語:What, Accuracy score:100.0
単語:time, Accuracy score:100.0
単語:is, Accuracy score:100.0
単語:it, Accuracy score:100.0
単語:now, Accuracy score:40.0
単語:in, Accuracy score:40.0
単語:Japan, Accuracy score:0.0

あとから勝手にScriptに付け足した、発音していない部分(now in Japan)の単語で点数が低いことが分かります。
[4-8] 最後に異なる結果取得の方法、JSONで全ての情報を取得する方法を解説します。
resultに対して、以下のように実行します。
# [8] まとめてJsonで取得・表示
json_result = result.properties.get(speech_sdk.PropertyId.SpeechServiceResponse_JsonResult)
jo = json.loads(json_result)
print(json.dumps(jo, indent=2))
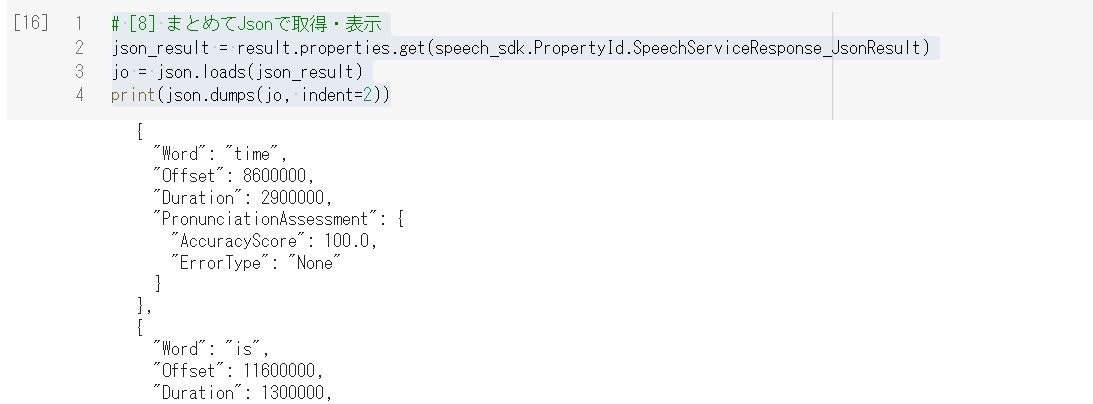
結果のJSONは以下のような構造です。
{
"Id": "b19370d415794e5bb53919f179ffa1df",
"RecognitionStatus": "Success",
"Offset": 5000000,
"Duration": 23500000,
"DisplayText": "What time is it now in Japan?",
"SNR": 27.69381,
"NBest": [
{
"Confidence": 0.9015003,
"Lexical": "What time is it now in Japan",
"ITN": "What time is it now in Japan",
"MaskedITN": "what time is it now in japan",
"Display": "What time is it now in Japan?",
"PronunciationAssessment": {
"AccuracyScore": 69.0,
"FluencyScore": 53.0,
"CompletenessScore": 86.0,
"PronScore": 62.8
},
"Words": [
{
"Word": "What",
"Offset": 5000000,
"Duration": 3500000,
"PronunciationAssessment": {
"AccuracyScore": 100.0,
"ErrorType": "None"
}
},
{
"Word": "time",
"Offset": 8600000,
"Duration": 2900000,
"PronunciationAssessment": {
"AccuracyScore": 100.0,
"ErrorType": "None"
}
},
{
"Word": "is",
"Offset": 11600000,
"Duration": 1300000,
"PronunciationAssessment": {
"AccuracyScore": 100.0,
"ErrorType": "None"
}
},
{
"Word": "it",
"Offset": 13000000,
"Duration": 3100000,
"PronunciationAssessment": {
"AccuracyScore": 100.0,
"ErrorType": "None"
}
},
{
"Word": "now",
"Offset": 25900000,
"Duration": 500000,
"PronunciationAssessment": {
"AccuracyScore": 40.0,
"ErrorType": "None"
}
},
{
"Word": "in",
"Offset": 26500000,
"Duration": 500000,
"PronunciationAssessment": {
"AccuracyScore": 40.0,
"ErrorType": "None"
}
},
{
"Word": "Japan",
"Offset": 27100000,
"Duration": 1400000,
"PronunciationAssessment": {
"AccuracyScore": 0.0,
"ErrorType": "Mispronunciation"
}
}
]
}
]
}
以上で発音評価を行うことができました。
8. さいごに
以上、本記事では英語の発音に関して自動で評価を行う、Azure Cognitive Services Speech SDKの「発音評価(Pronunciation assessment)」の使用方法と実装を解説しました。
英語の発音練習やそのアプリ作成ぐらいしか使い道が私には思い浮かばないのですが、なかなか面白い機能です。
本記事のJupyter Notebookのプログラム本体はGitHubにも置いております。
実装プログラムのGitHubリポジトリ:
https://github.com/YutaroOgawa/example_of_azure_pronunciation_assessment
以上、ご一読いただき、ありがとうございました。
【記事執筆者】
電通国際情報サービス(ISID)AIトランスフォーメーションセンター 製品開発Gr
小川 雄太郎
主書「つくりながら学ぶ! PyTorchによる発展ディープラーニング」
自己紹介(詳細はこちら)
【情報発信】
Twitterアカウント:小川雄太郎@ISID_AI_team
IT・AIやビジネス・経営系情報で、面白いと感じた記事やサイトを、Twitterで発信しています。
【免責】
本記事の内容そのものは執筆者の意見/発信であり、執筆者が属する企業等の公式見解ではございません