※2018年06月23日追記
PyTorchを使用した最新版の内容を次の書籍にまとめました。
つくりながら学ぶ! 深層強化学習 ~PyTorchによる実践プログラミング~ 18年6月28日発売
強化学習DQNの発展編である「優先順位付き経験再生 prioritized experience replay」を実装・解説したので、紹介します。
概要
Open AI GymのCartPoleで、優先順位付き経験再生 prioritized experience replayにしたDQNの実装・解説をします。
プログラムが1ファイルで完結し、学習・理解しやすいようにしています。
【対象者】
・強化学習DQNの発展版に興味がある方
・速習 強化学習: 基礎理論とアルゴリズム(書籍)を読んで、Dueling Networkを知ったが、実装方法がよく分からない方
・実装例を見たほうが、アルゴリズムを理解しやすい方
【得られるもの】
ミニマム・シンプルなプログラムが実装例から、優先順位付き経験再生 prioritized experience replayを理解・使用できるようになります。
【注意】
本記事に入る前に、以下の記事で、「Open AI gymのCartPoleの使い方」と「DQNの理論と実装」をなんとなく理解しておいてください。
●CartPoleでDQN(deep Q-learning)、DDQNを実装・解説【Phythonで強化学習:第2回】
以下の記事で「優先順位付き経験再生」の概要をなんとなく感じておいてください。
●Introduction to Prioritized Experience Replay(日本語)
速習 強化学習: 基礎理論とアルゴリズム(書籍)の、優先順位付き経験再生を説明も読んでおくと、なお良いです。
優先順位付き経験再生について
prioritized experience replayは、DQNでメモリに保存していた状態(s(t), a(t), r(t), s(t+1), a(t+1) )をexperience Replayする際に、優先順位をつけましょうって方法です。
では、何で優先順位をつけるかというと、TD誤差の大きさです。
TD誤差の大きさとは、
[r(t) + γ × max[Q(s(t+1), a(t+1))] - Q(s(t), a(t))
のことです。
このTD誤差が大きいサンプルを優先的に学習して、DQNのネットワークの誤差が小さくなるようにしましょうって作戦になります。
やりたいことはとてもシンプルです。
優先順位付き経験再生の実装
実装には以下のサイトを参考にしました。
●LET’S MAKE A DQN: DOUBLE LEARNING AND PRIORITIZED EXPERIENCE REPLAY
Jaromiruさんのサイトでは、二分木でTD誤差を格納すると最も早いと説明されていますが、分かりづらくなるので、今回はシンプルなリスト(deque)で実装しています。
まずは、全コードを紹介して、その後、重要な部分を解説します。
# coding:utf-8
# [0]必要なライブラリのインポート
import gym # 倒立振子(cartpole)の実行環境
import numpy as np
import time
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import Adam
from keras.utils import plot_model
from collections import deque
from gym import wrappers # gymの画像保存
from keras import backend as K
import tensorflow as tf
# [1]損失関数の定義
# 損失関数にhuber関数を使用します 参考https://github.com/jaara/AI-blog/blob/master/CartPole-DQN.py
def huberloss(y_true, y_pred):
err = y_true - y_pred
cond = K.abs(err) < 1.0
L2 = 0.5 * K.square(err)
L1 = (K.abs(err) - 0.5)
loss = tf.where(cond, L2, L1) # Keras does not cover where function in tensorflow :-(
return K.mean(loss)
# [2]Q関数をディープラーニングのネットワークをクラスとして定義
class QNetwork:
def __init__(self, learning_rate=0.01, state_size=4, action_size=2, hidden_size=10):
self.model = Sequential()
self.model.add(Dense(hidden_size, activation='relu', input_dim=state_size))
self.model.add(Dense(hidden_size, activation='relu'))
self.model.add(Dense(action_size, activation='linear'))
self.optimizer = Adam(lr=learning_rate) # 誤差を減らす学習方法はAdamとし、勾配は最大1にクリップする
# self.model.compile(loss='mse', optimizer=self.optimizer)
self.model.compile(loss=huberloss, optimizer=self.optimizer)
# 重みの学習
def replay(self, memory, batch_size, gamma, targetQN):
inputs = np.zeros((batch_size, 4))
targets = np.zeros((batch_size, 2))
mini_batch = memory.sample(batch_size)
for i, (state_b, action_b, reward_b, next_state_b) in enumerate(mini_batch):
inputs[i:i + 1] = state_b
target = reward_b
if not (next_state_b == np.zeros(state_b.shape)).all(axis=1):
# 価値計算(DDQNにも対応できるように、行動決定のQネットワークと価値観数のQネットワークは分離)
retmainQs = self.model.predict(next_state_b)[0]
next_action = np.argmax(retmainQs) # 最大の報酬を返す行動を選択する
target = reward_b + gamma * targetQN.model.predict(next_state_b)[0][next_action]
targets[i] = self.model.predict(state_b) # Qネットワークの出力
targets[i][action_b] = target # 教師信号
self.model.fit(inputs, targets, epochs=1, verbose=0) # epochsは訓練データの反復回数、verbose=0は表示なしの設定
# [※p1] 優先順位付き経験再生で重みの学習
def pioritized_experience_replay(self, memory, batch_size, gamma, targetQN, memory_TDerror):
# 0からTD誤差の絶対値和までの一様乱数を作成(昇順にしておく)
sum_absolute_TDerror = memory_TDerror.get_sum_absolute_TDerror()
generatedrand_list = np.random.uniform(0, sum_absolute_TDerror,batch_size)
generatedrand_list = np.sort(generatedrand_list)
# [※p2]作成した乱数で串刺しにして、バッチを作成する
batch_memory = Memory(max_size=batch_size)
idx = 0
tmp_sum_absolute_TDerror = 0
for (i,randnum) in enumerate(generatedrand_list):
while tmp_sum_absolute_TDerror < randnum:
tmp_sum_absolute_TDerror += abs(memory_TDerror.buffer[idx]) + 0.0001
idx += 1
batch_memory.add(memory.buffer[idx])
# あとはこのバッチで学習する
inputs = np.zeros((batch_size, 4))
targets = np.zeros((batch_size, 2))
for i, (state_b, action_b, reward_b, next_state_b) in enumerate(batch_memory.buffer):
inputs[i:i + 1] = state_b
target = reward_b
if not (next_state_b == np.zeros(state_b.shape)).all(axis=1):
# 価値計算(DDQNにも対応できるように、行動決定のQネットワークと価値観数のQネットワークは分離)
retmainQs = self.model.predict(next_state_b)[0]
next_action = np.argmax(retmainQs) # 最大の報酬を返す行動を選択する
target = reward_b + gamma * targetQN.model.predict(next_state_b)[0][next_action]
targets[i] = self.model.predict(state_b) # Qネットワークの出力
targets[i][action_b] = target # 教師信号
self.model.fit(inputs, targets, epochs=1, verbose=0) # epochsは訓練データの反復回数、verbose=0は表示なしの設定
# [2]Experience ReplayとFixed Target Q-Networkを実現するメモリクラス
class Memory:
def __init__(self, max_size=1000):
self.buffer = deque(maxlen=max_size)
def add(self, experience):
self.buffer.append(experience)
def sample(self, batch_size):
idx = np.random.choice(np.arange(len(self.buffer)), size=batch_size, replace=False)
return [self.buffer[ii] for ii in idx]
def len(self):
return len(self.buffer)
# [※p3] Memoryクラスを継承した、TD誤差を格納するクラスです
class Memory_TDerror(Memory):
def __init__(self, max_size=1000):
super().__init__(max_size)
# add, sample, len は継承されているので定義不要
# TD誤差を取得
def get_TDerror(self, memory, gamma, mainQN, targetQN):
(state, action, reward, next_state) = memory.buffer[memory.len() - 1] #最新の状態データを取り出す
# 価値計算(DDQNにも対応できるように、行動決定のQネットワークと価値観数のQネットワークは分離)
next_action = np.argmax(mainQN.model.predict(next_state)[0]) # 最大の報酬を返す行動を選択する
target = reward + gamma * targetQN.model.predict(next_state)[0][next_action]
TDerror = target - targetQN.model.predict(state)[0][action]
return TDerror
# TD誤差をすべて更新
def update_TDerror(self, memory, gamma, mainQN, targetQN):
for i in range(0, (self.len() - 1)):
(state, action, reward, next_state) = memory.buffer[i] # 最新の状態データを取り出す
# 価値計算(DDQNにも対応できるように、行動決定のQネットワークと価値観数のQネットワークは分離)
next_action = np.argmax(mainQN.model.predict(next_state)[0]) # 最大の報酬を返す行動を選択する
target = reward + gamma * targetQN.model.predict(next_state)[0][next_action]
TDerror = target - targetQN.model.predict(state)[0][action]
self.buffer[i] = TDerror
# TD誤差の絶対値和を取得
def get_sum_absolute_TDerror(self):
sum_absolute_TDerror = 0
for i in range(0, (self.len() - 1)):
sum_absolute_TDerror += abs(self.buffer[i]) + 0.0001 # 最新の状態データを取り出す
return sum_absolute_TDerror
# [3]カートの状態に応じて、行動を決定するクラス
class Actor:
def get_action(self, state, episode, targetQN): # [C]t+1での行動を返す
# 徐々に最適行動のみをとる、ε-greedy法
epsilon = 0.001 + 0.9 / (1.0 + episode)
if epsilon <= np.random.uniform(0, 1):
retTargetQs = targetQN.model.predict(state)[0]
action = np.argmax(retTargetQs) # 最大の報酬を返す行動を選択する
else:
action = np.random.choice([0, 1]) # ランダムに行動する
return action
# [4] メイン関数開始----------------------------------------------------
# [4.1] 初期設定--------------------------------------------------------
DQN_MODE = 1 # 1がDQN、0がDDQNです
LENDER_MODE = 1 # 0は学習後も描画なし、1は学習終了後に描画する
env = gym.make('CartPole-v0')
num_episodes = 299 # 総試行回数
max_number_of_steps = 200 # 1試行のstep数
goal_average_reward = 195 # この報酬を超えると学習終了
num_consecutive_iterations = 10 # 学習完了評価の平均計算を行う試行回数
total_reward_vec = np.zeros(num_consecutive_iterations) # 各試行の報酬を格納
gamma = 0.99 # 割引係数
islearned = 0 # 学習が終わったフラグ
isrender = 0 # 描画フラグ
# ---
hidden_size = 16 # Q-networkの隠れ層のニューロンの数
learning_rate = 0.00001 # Q-networkの学習係数
memory_size = 1000 # バッファーメモリの大きさ
batch_size = 32 # Q-networkを更新するバッチの大記載
# [4.2]Qネットワークとメモリ、Actorの生成--------------------------------------------------------
mainQN = QNetwork(hidden_size=hidden_size, learning_rate=learning_rate) # メインのQネットワーク
targetQN = QNetwork(hidden_size=hidden_size, learning_rate=learning_rate) # 価値を計算するQネットワーク
# plot_model(mainQN.model, to_file='Qnetwork.png', show_shapes=True) # Qネットワークの可視化
memory = Memory(max_size=memory_size)
memory_TDerror = Memory_TDerror(max_size=memory_size)
actor = Actor()
# [4.3]メインルーチン--------------------------------------------------------
for episode in range(num_episodes): # 試行数分繰り返す
env.reset() # cartPoleの環境初期化
state, reward, done, _ = env.step(env.action_space.sample()) # 1step目は適当な行動をとる
state = np.reshape(state, [1, 4]) # list型のstateを、1行4列の行列に変換
episode_reward = 0
for t in range(max_number_of_steps + 1): # 1試行のループ
if (islearned == 1) and LENDER_MODE: # 学習終了したらcartPoleを描画する
env.render()
time.sleep(0.1)
print(state[0, 0]) # カートのx位置を出力するならコメントはずす
action = actor.get_action(state, episode, mainQN) # 時刻tでの行動を決定する
next_state, reward, done, info = env.step(action) # 行動a_tの実行による、s_{t+1}, _R{t}を計算する
next_state = np.reshape(next_state, [1, 4]) # list型のstateを、1行4列の行列に変換
# 報酬を設定し、与える
if done:
next_state = np.zeros(state.shape) # 次の状態s_{t+1}はない
if t < 195:
reward = -1 # 報酬クリッピング、報酬は1, 0, -1に固定
else:
reward = 1 # 立ったまま195step超えて終了時は報酬
else:
reward = 0 # 各ステップで立ってたら報酬追加(はじめからrewardに1が入っているが、明示的に表す)
episode_reward += 1 # reward # 合計報酬を更新
memory.add((state, action, reward, next_state)) # メモリの更新する
# [※p4]TD誤差を格納する
TDerror = memory_TDerror.get_TDerror(memory, gamma, mainQN, targetQN)
memory_TDerror.add(TDerror)
state = next_state # 状態更新
# [※p5]Qネットワークの重みを学習・更新する replay
if (memory.len() > batch_size) and not islearned:
if total_reward_vec.mean() < 20:
mainQN.replay(memory, batch_size, gamma, targetQN)
else:
mainQN.pioritized_experience_replay(memory, batch_size, gamma, targetQN, memory_TDerror)
if DQN_MODE:
targetQN = mainQN # 行動決定と価値計算のQネットワークをおなじにする
# 1施行終了時の処理
if done:
# [※p6]TD誤差のメモリを最新に計算しなおす
targetQN = mainQN # 行動決定と価値計算のQネットワークをおなじにする
memory_TDerror.update_TDerror(memory, gamma, mainQN, targetQN)
total_reward_vec = np.hstack((total_reward_vec[1:], episode_reward)) # 報酬を記録
print('%d Episode finished after %f time steps / mean %f' % (episode, t + 1, total_reward_vec.mean()))
break
# 複数施行の平均報酬で終了を判断
if total_reward_vec.mean() >= goal_average_reward:
print('Episode %d train agent successfuly!' % episode)
islearned = 1
if isrender == 0: # 学習済みフラグを更新
isrender = 1
env = wrappers.Monitor(env, './movie/cartpole_prioritized') # 動画保存する場合
およそ70試行と、DQNよりちょっと早く学習できます。
実行結果の一例は以下の通りです。
コードの中で重要な部分を解説します。
コードの解説
DQNから変化している部分は[※p]でコメントしています。
DQNはこちら●CartPoleでDQN(deep Q-learning)、DDQNを実装・解説
まず、※p1の優先順位付き経験再生で重みの学習の部分です。
コードをピックアップすると次の通りです。
今回はdequeに状態(s(t), a(t), r(t), s(t+1), a(t+1) )を格納するのに加えて、別のメモリmemory_TDerrorを用意して、そのときのTD誤差も保存しています。
# [※p1] 優先順位付き経験再生で重みの学習
def pioritized_experience_replay(self, memory, batch_size, gamma, targetQN, memory_TDerror):
# 0からTD誤差の絶対値和までの一様乱数を作成(昇順にしておく)
sum_absolute_TDerror = memory_TDerror.get_sum_absolute_TDerror()
generatedrand_list = np.random.uniform(0, sum_absolute_TDerror,batch_size)
generatedrand_list = np.sort(generatedrand_list)
# [※p2]作成した乱数で串刺しにして、バッチを作成する
batch_memory = Memory(max_size=batch_size)
idx = 0
tmp_sum_absolute_TDerror = 0
for (i,randnum) in enumerate(generatedrand_list):
while tmp_sum_absolute_TDerror < randnum:
tmp_sum_absolute_TDerror += abs(memory_TDerror.buffer[idx]) + 0.0001
idx += 1
batch_memory.add(memory.buffer[idx])
# あとはこのバッチで学習する
inputs = np.zeros((batch_size, 4))
targets = np.zeros((batch_size, 2))
for i, (state_b, action_b, reward_b, next_state_b) in enumerate(batch_memory.buffer):
inputs[i:i + 1] = state_b
target = reward_b
if not (next_state_b == np.zeros(state_b.shape)).all(axis=1):
# 価値計算(DDQNにも対応できるように、行動決定のQネットワークと価値観数のQネットワークは分離)
retmainQs = self.model.predict(next_state_b)[0]
next_action = np.argmax(retmainQs) # 最大の報酬を返す行動を選択する
target = reward_b + gamma * targetQN.model.predict(next_state_b)[0][next_action]
targets[i] = self.model.predict(state_b) # Qネットワークの出力
targets[i][action_b] = target # 教師信号
self.model.fit(inputs, targets, epochs=1, verbose=0) # epochsは訓練データの反復回数、verbose=0は表示なしの設定
上では、最初に、メモリのTD誤差の絶対値和を求めて、その範囲内でバッチ処理分の一様乱数を生成しています。
そして、その一様乱数に当てはまる状態(s(t), a(t), r(t), s(t+1), a(t+1) )をバッチ処理に利用するものとして、ピックアップしています。
図示すると以下の通りです。
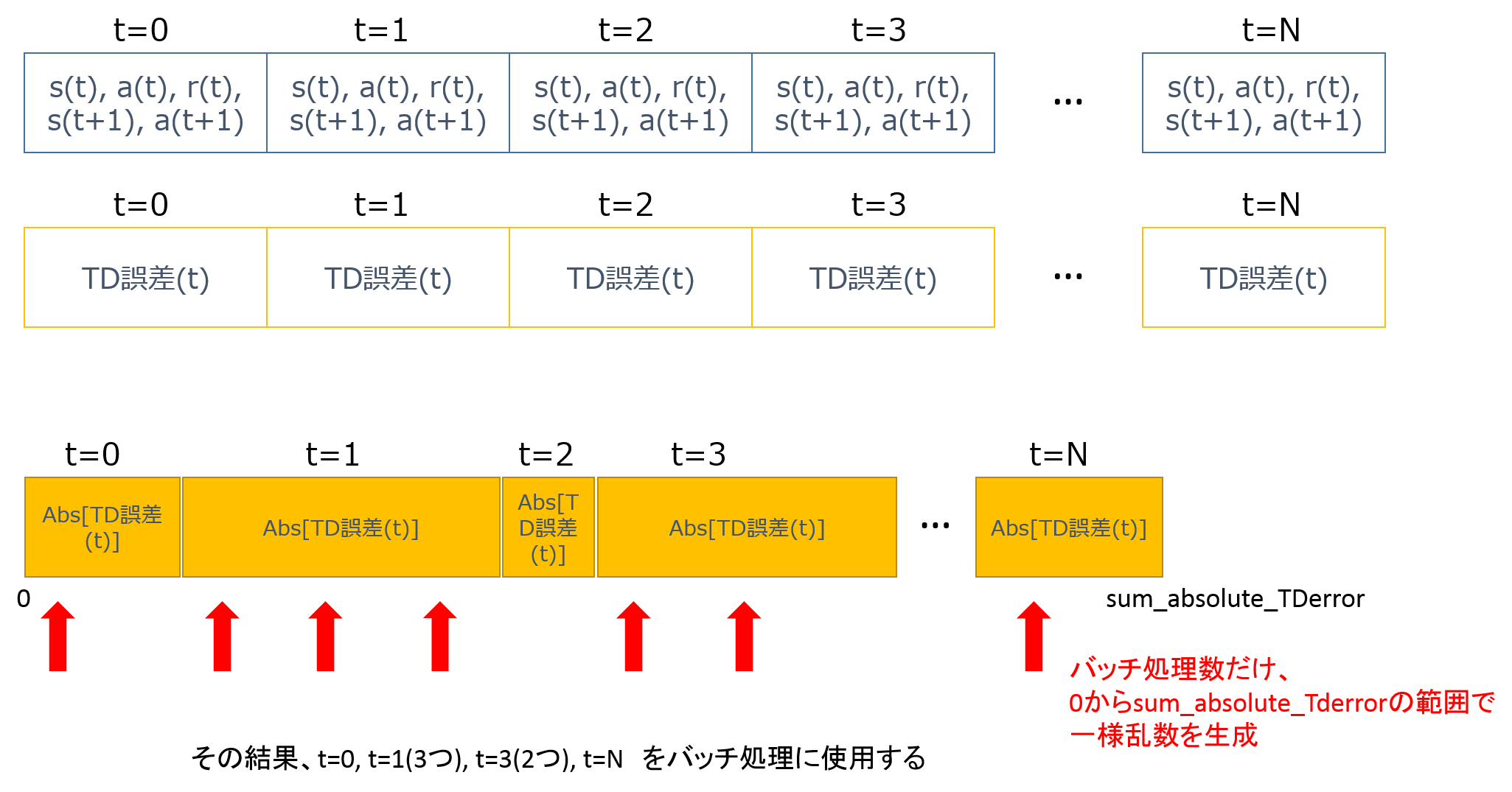
上の図ですが、2つのメモリがあります。
まず、TD誤差のメモリの誤差の絶対値の和=sum_absolute_TDerrorを求めます。
次に、0からsum_absolute_TDerrorの範囲で、バッチ処理数分の一様乱数を生成します。
そしてその乱数が突き刺さる部分の (s(t), a(t), r(t), s(t+1), a(t+1))をバッチ処理に使用します。
なお絶対値の和を求めていくときに、0.0001を毎回足して、あまりに誤差が小さいものが無視されるのを防いでいます(※割り算しないので、なくても良いですが、ある方が安定する気がする)。
優先順位付き経験再生を実装する工夫は、ほぼ以上となります。
次に、※p3では、Memoryクラスを継承した、TD誤差を格納するクラスを定義しています。
# [※p3] Memoryクラスを継承した、TD誤差を格納するクラスです
class Memory_TDerror(Memory):
このクラスでは3つメソッドを新たに定義しています。
・最新の(s(t), a(t), r(t), s(t+1), a(t+1))のTD誤差を計算し、格納
・メモリ内の全てのTD誤差を更新
・TD誤差の絶対値和=sum_absolute_TDerrorを取得
そしてメインルーチンのなかでは、※p4でTD誤差を格納しています。
TDerror = memory_TDerror.get_TDerror(memory, gamma, mainQN, targetQN)
memory_TDerror.add(TDerror)
またメインルーチンでは、※p5でQネットワークの重みを学習・更新するexperience replayを行いますが、最初は普通のDQNにし、少しQ関数の更新が進んでから、優先順位付き経験再生を使用しています。
# [※p5]Qネットワークの重みを学習・更新する replay
if (memory.len() > batch_size) and not islearned:
if total_reward_vec.mean() < 20:
mainQN.replay(memory, batch_size, gamma, targetQN)
else:
mainQN.pioritized_experience_replay(memory, batch_size, gamma, targetQN, memory_TDerror)
Q関数が全然更新されていない状態で、優先順位付き経験再生をすると、そもそものQ(s,a)が、あまりにめちゃくちゃなので、不安定になるのを防ぐ工夫です。
最後に1試行が終わったときには、 ※p6でTD誤差のメモリを最新に計算しなおしています。
# 1施行終了時の処理
if done:
# [※p6]TD誤差のメモリを最新に計算しなおす
targetQN = mainQN # 行動決定と価値計算のQネットワークをおなじにする
memory_TDerror.update_TDerror(memory, gamma, mainQN, targetQN)
これは1試行が終わってQ関数の精度が高くなると、格納していたTD誤差が実態と合わなくなるので、最新のQ関数でTD誤差を計算し直しています。
まとめ
以上、CartPoleで優先順位付き経験再生 prioritized experience replay DQN を実装・解説しました。
次回はディープラーニングを用いた強化学習である
A3Cを実装する予定です。
以上、ご一読いただき、ありがとうございました。