PyTorchでBERTをはじめとした、各種ディープラーニングモデルを、実際に実装しながら学ぶ書籍を執筆しました。

つくりながら学ぶ! PyTorchによる発展ディープラーニング(小川雄太郎、マイナビ出版)
https://www.amazon.co.jp/dp/4839970254/
Amazonでは7月29日が発売予定となっています。
ディープラーニングの基礎的な内容(畳み込みニューラルネットワークを用いた画像分類など)を実装してみて、さらに発展的な内容を学びたい方や、PyTorchを使いたい方に向けて執筆いたしました。
本書がお役に立てそうであれば、ご活用いただければ幸いです。
本記事では、
・書籍の概要
・各章の詳細
を紹介いたします。
本書の概要
本書はディープラーニングの応用手法を、実装しながら学習していただく書籍です。
ディープラーニングの基礎的な内容(畳み込みニューラルネットワークを用いた画像分類など)の実装経験がある方を読者に想定しています。
実装にはPyTorchを使用します。
本書で扱うタスク内容とディープラーニングモデルは以下の通りです。
・第1章 画像分類と転移学習(VGG)
・第2章 物体認識(SSD)
・第3章 セマンティックセグメンテーション(PSPNet)
・第4章 姿勢推定(OpenPose)
・第5章 GANによる画像生成(DCGAN、Self-Attention GAN)
・第6章 GANによる異常検知(AnoGAN、Efficient GAN)
・第7章 自然言語処理による感情分析(Transformer)
・第8章 自然言語処理による感情分析(BERT)
・第9章 動画分類(3DCNN、ECO)
上記のタスクは、「ビジネスの現場でディープラーニングを活用するためにも実装経験を積んでおきたいタスク」という観点で選定しました。
本書で解説・実装するディープラーニングモデルは執筆時点で各タスクのState-of-the-Art(最高性能モデル)の土台となっており、本書で取り扱うモデルを理解すれば、その後のディープラーニングの学習や研究・開発に役立つ、という観点で選定しました。
書籍の雰囲気は以下のような感じです。


各ディープラーニングモデルを、大きなモジュール単位、各モジュールのネットワーク単位で、それぞれ概観を図解し、それらを実際に実装・解説していきます。
また、各ディープラーニングモデルがどのような原理で動作しているのかを、ひとつずつ実装して動かしてみて、確認・解説を行います。
実装コードにはコメントを多めに書き込み、各コードが何をしているのか、可能な限りスムーズに学んでいただけるように心がけました。
書籍内での解説・実装コードはこちらのGitHubリポジトリで公開しています。
各章の概要
※以下、掲載している犬や乗馬、野球の画像は、全てpixabayより、(画像権利情報:商用利用無料、帰属表示は必要ありません)を、使用しています。
第1章 画像分類と転移学習(VGG)
1.1 学習済みのVGGモデルを使用する方法
1.2 PyTorchによるディープラーニング実装の流れ
1.3 転移学習の実装
1.4 Amazon AWSのクラウドGPUマシンを使用する方法
1.5 ファインチューニングの実装
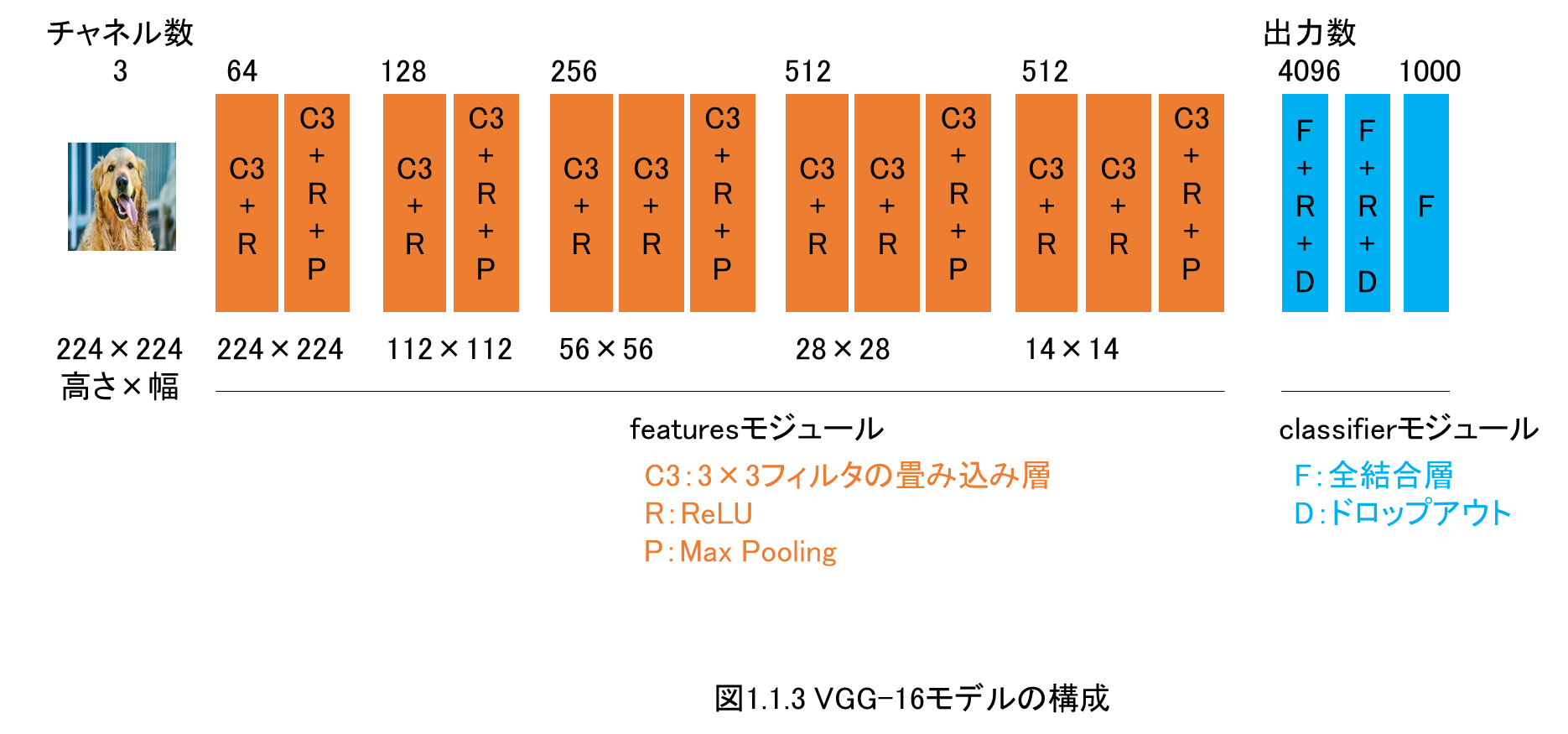
第1章では、画像分類の転移学習とファインチューニングを解説します。
VGGモデルを扱います。
また、本書ではAWSのGPUマシンを使用するので、AWSのGPUマシンでのディープラーニングの仕方を解説します。

第2章 物体検出(SSD)
2.1 物体検出とは
2.2 Datasetの実装
2.3 DataLoaderの実装
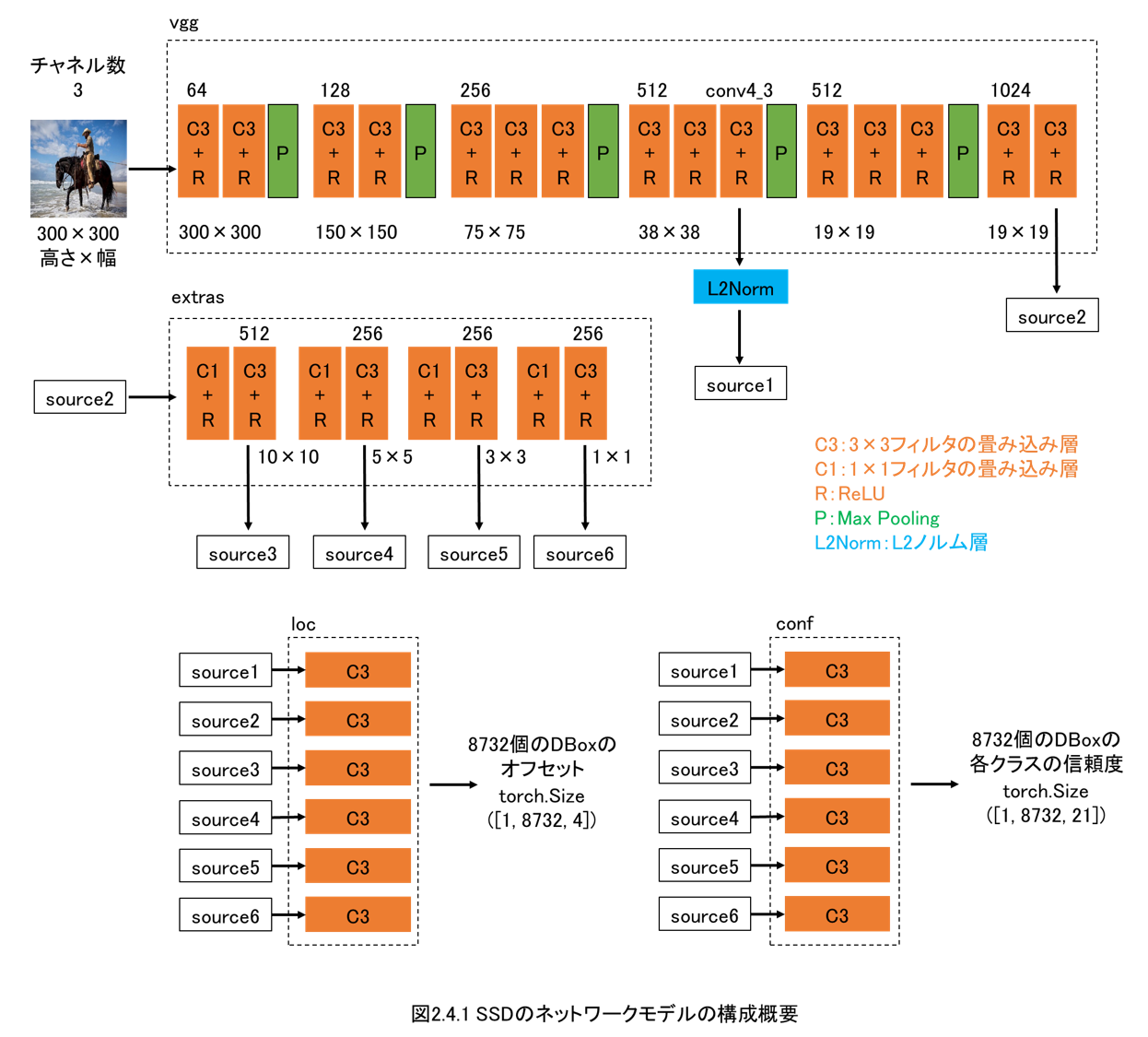
2.4 ネットワークモデルの実装
2.5 順伝搬関数の実装
2.6 損失関数の実装
2.7 学習と検証の実施
2.8 推論の実施
第2章では、物体検出を行います。
ディープラーニングモデルとしてはSSDを実装します。
本章ではPyTorchで発展的なディープラーニングモデルを作成する流れをしっかりと解説します。
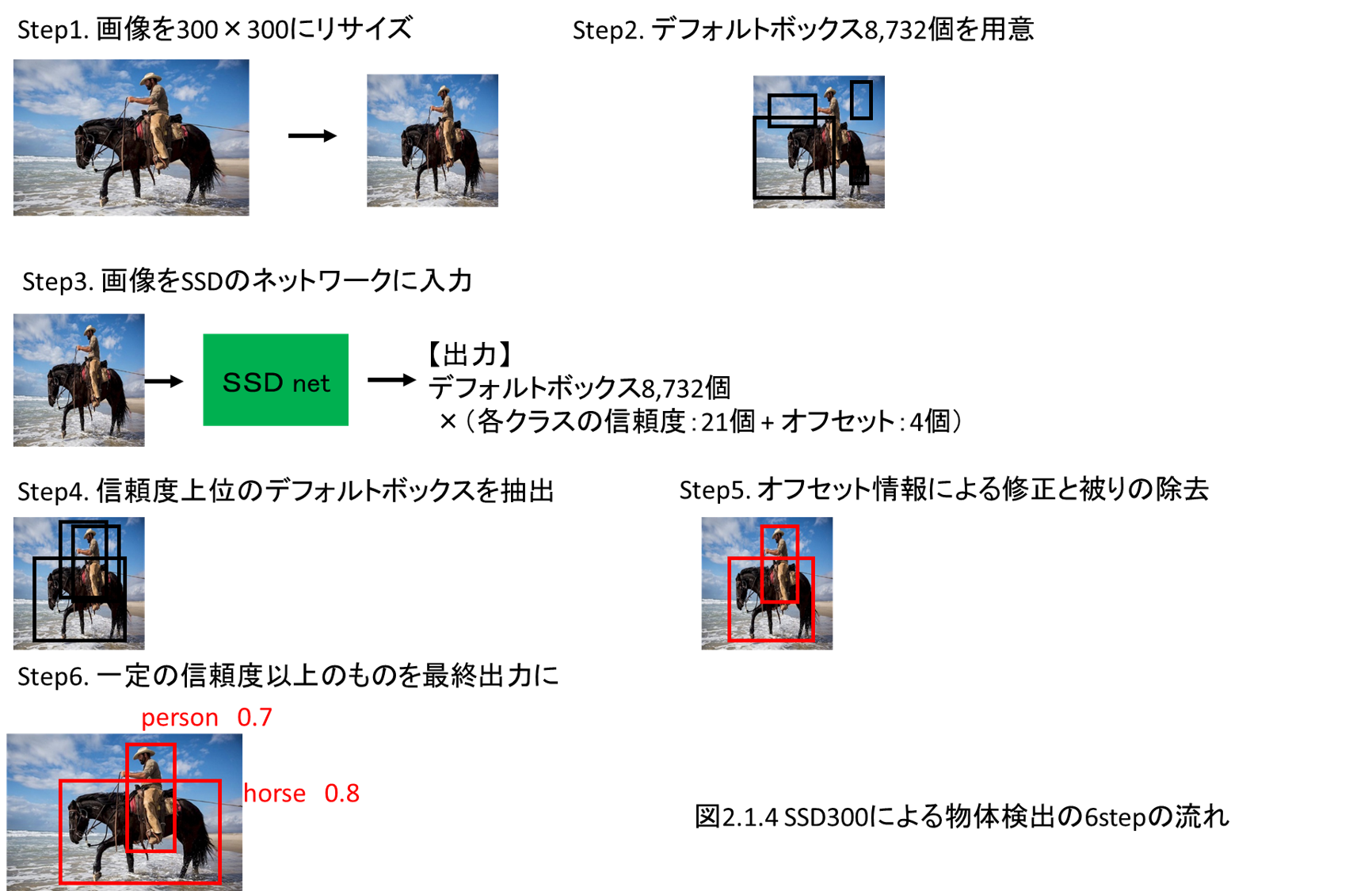

上の図はバウンディングボックスが微妙に感じますが、これはAWSのGPUマシンでの学習を数時間に留めているためです。
本書では何十時間とAWSを回すことはせず、GPU1枚のp2.xlarge(1時間約100円)で、長くても半日以内に終わる程度しか計算は行いません。
第3章 セマンティックセグメンテーション(PSPNet)
3.1 セマンティックセグメンテーションとは
3.2 DatasetとDataLoaderの実装
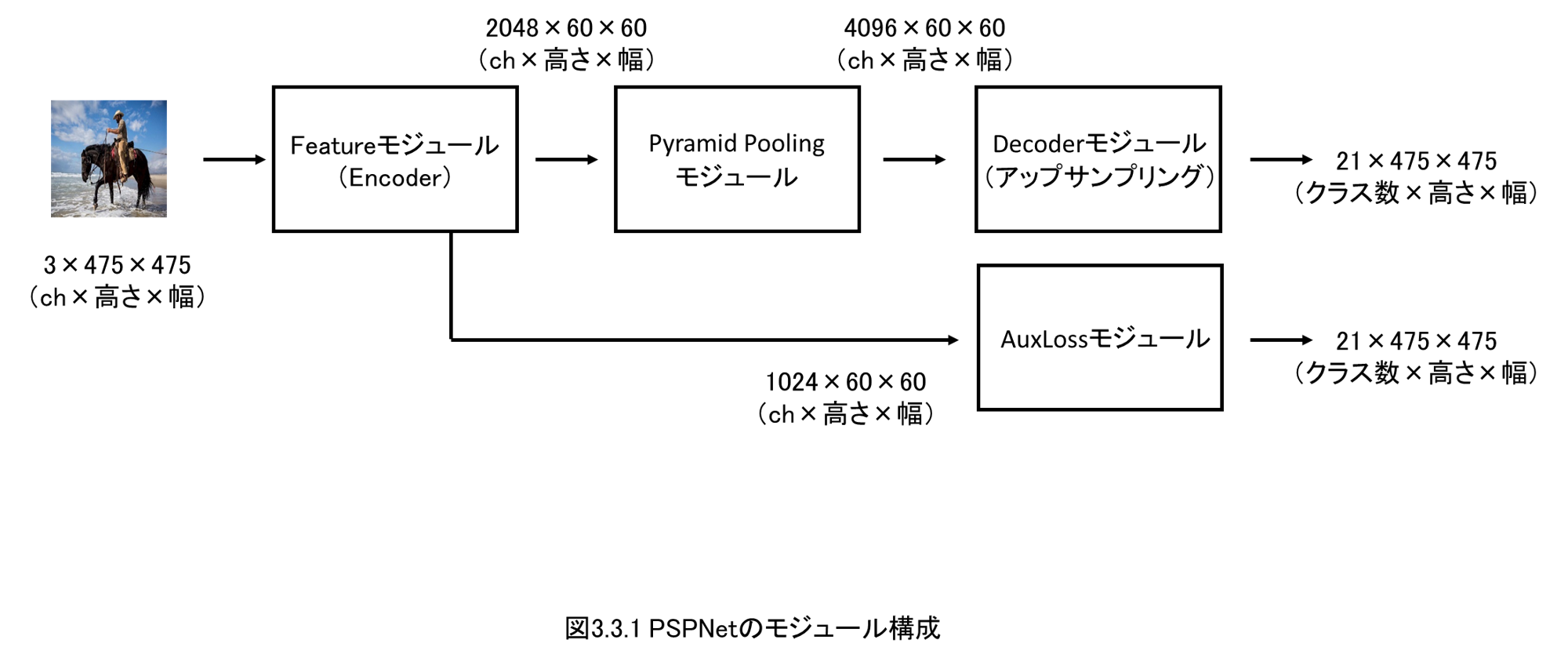
3.3 PSPNetのネットワーク構成と実装
3.4 Featureモジュールの解説と実装
3.5 Pyramid Poolingモジュールの解説と実装
3.6 Decoder、AuxLossモジュールの解説と実装
3.7 ファインチューニングによる学習と検証の実施
3.8 セマンティックセグメンテーションの推論
第3章では、ピクセルレベルで物体を分類するセマンティックセグメンテーションを実装・解説します。
ディープラーニングモデルとしては、PSPNetを扱います。
どのようにしてピクセルレベルで物体を分類できるのか、その仕組みを実装・解説します。


第4章 姿勢推定(OpenPose)
4.1 姿勢推定とOpenPoseの概要
4.2 DatasetとDataLoaderの実装
4.3 OpenPoseのネットワーク構成と実装
4.4 Feature、Stageモジュールの解説と実装
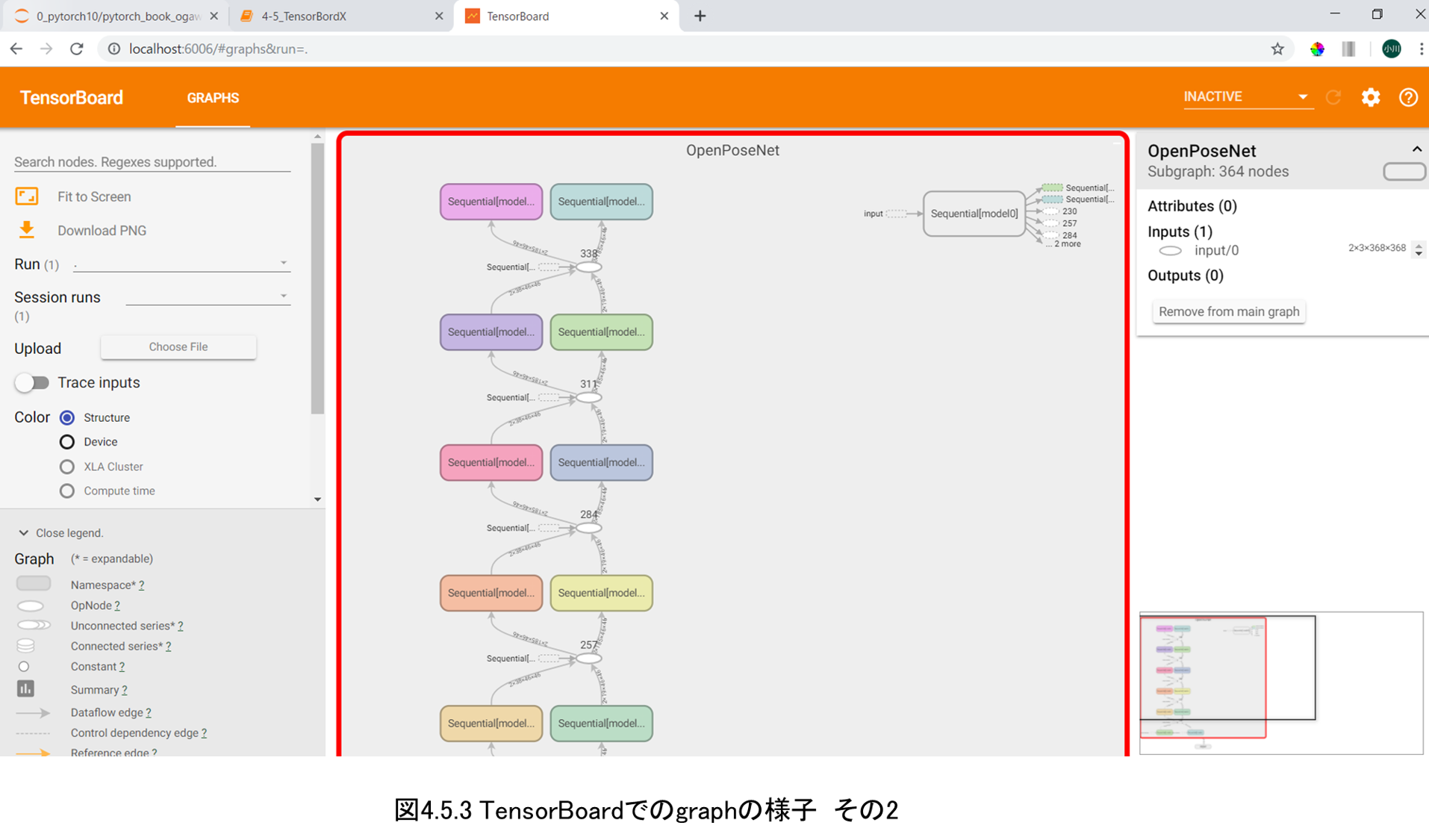
4.5 TensorBoardXを使用したネットワークの可視化手法
4.6 OpenPoseの学習
4.7 OpenPoseの推論
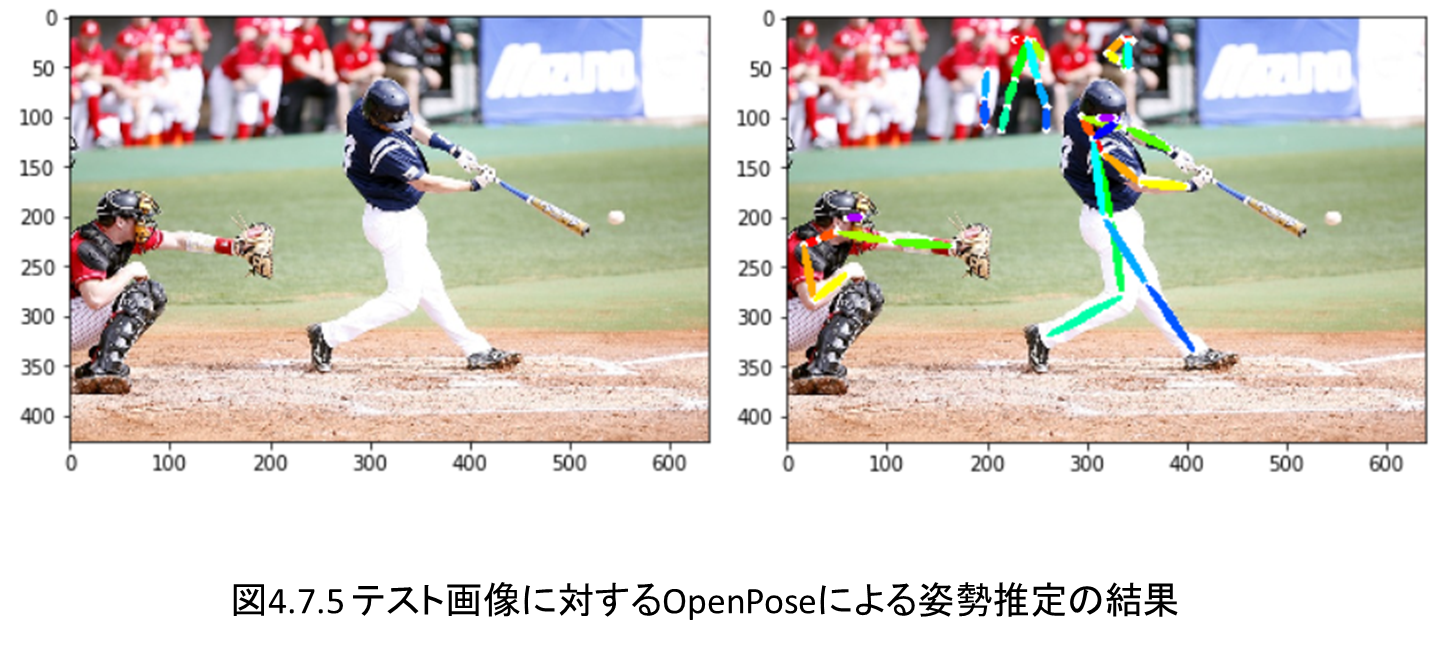
第4章では姿勢推定としてOpenPoseを実装します。
OpenPoseがいかに人物の各部位を検出し、さらに部位同士を接続しているのか、実装しながらその仕組みを確認します。
OpenPoseの学習は時間がかかり大変なので、学習は雰囲気を確認するに留め、学習済みのパラメータをロードして、推論部分を作成し、実行します。
また本章ではモデルのネットワーク構造の確認手法としてtesorbordXの使用方法を解説します。

第5章 GANによる画像生成(DCGAN、Self-Attention GAN)
5.1 GANによる画像生成のメカニズムとDCGANの実装
5.2 DCGANの損失関数、学習、生成の実装
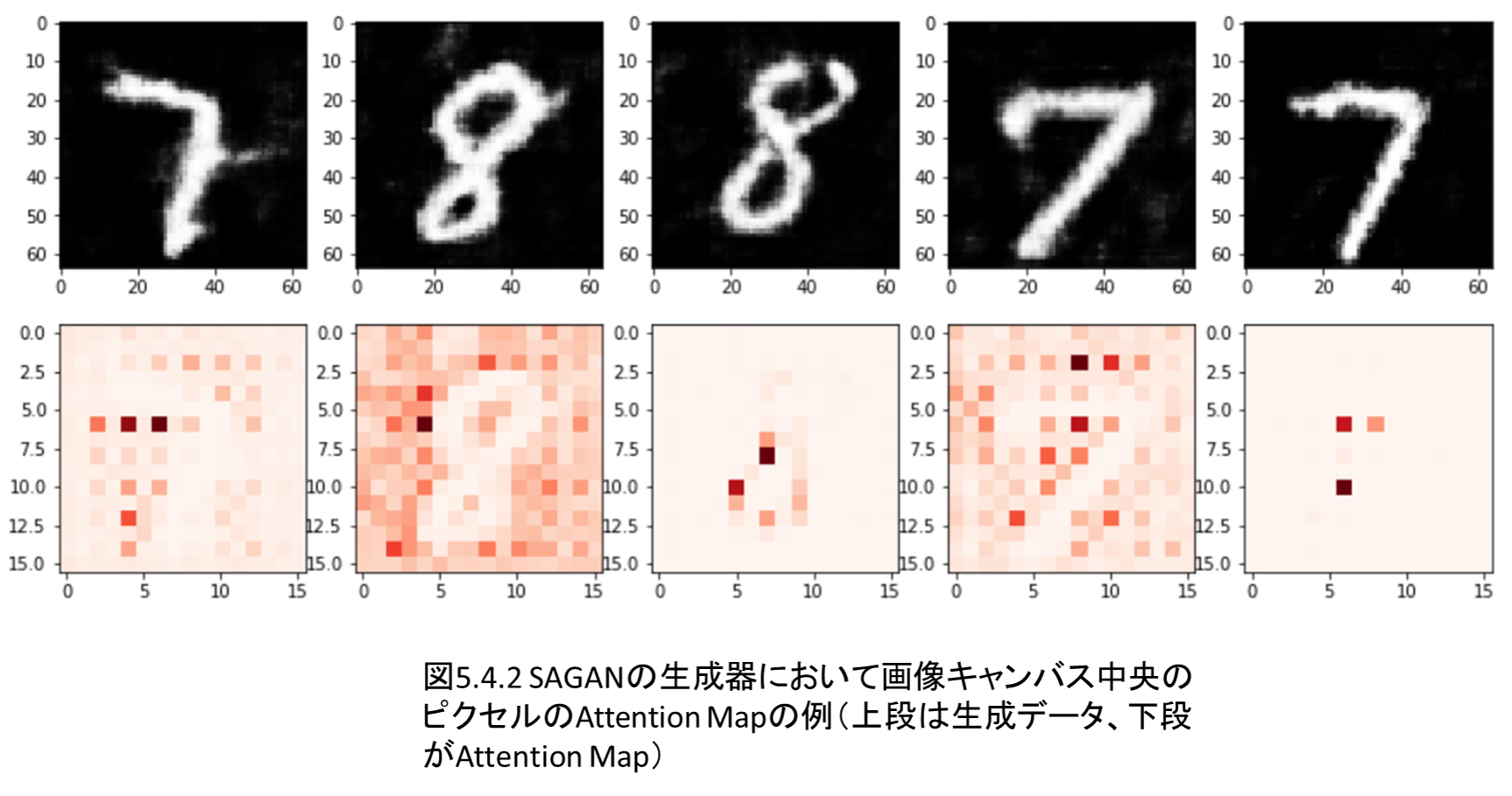
5.3 Self-Attention GANの概要
5.4 Self-Attention GANの学習、生成の実装
第5章ではGANによる画像生成を行います。
DCGANとSelf-Attention GANを実装・解説します。
Self-Attentionは自然言語処理のTransformerやBERTのカギになるのですが、理解が難しいので、まずは画像系でSelf-Attentionを実装し、雰囲気をつかむことを目指します。

第6章 GANによる異常検知(AnoGAN、Efficient GAN)
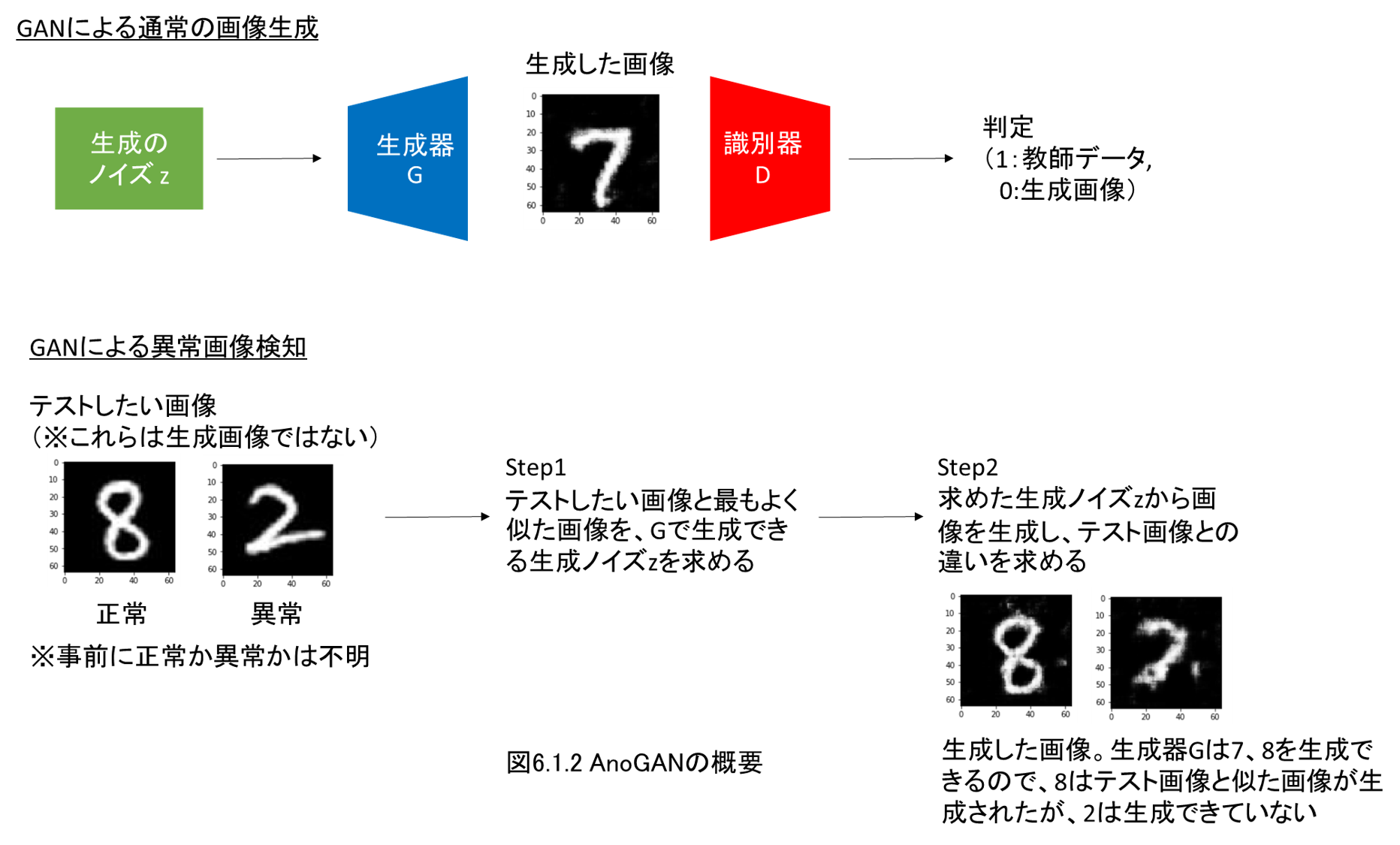
6.1 GANによる異常画像検知のメカニズム
6.2 AnoGANの実装と異常検知の実施
6.3 Efficinet GANの概要
6.4 Efficinet GANの実装と異常検知の実施
第6章ではGANによる異常画像の検出を実装・解説します。
異常画像の検出タスクでは、十分な量の異常画像を用意することが難しいです。
このような場合に正常画像のみから、GANを応用して異常画像を検出するモデルを作成します。
少しずつ実装しながら、その仕組みを解説し、異常画像検知を行います。
基本であるAnoGANを実装し、その後高速に検出ができるEfficientGANの実装・解説をします。


第7章 自然言語処理による感情分析(Transformer)
7.1形態素解析の実装(Janome、MeCab+NEologd)
7.2 torchtextを用いたDataset、DataLoaderの実装
7.3単語のベクトル表現の仕組み(word2vec、fastText)
7.4 word2vec、fastTextで日本語学習済みモデルを使用する方法
7.5 IMDb(Internet Movie Database)のDataLoaderを実装
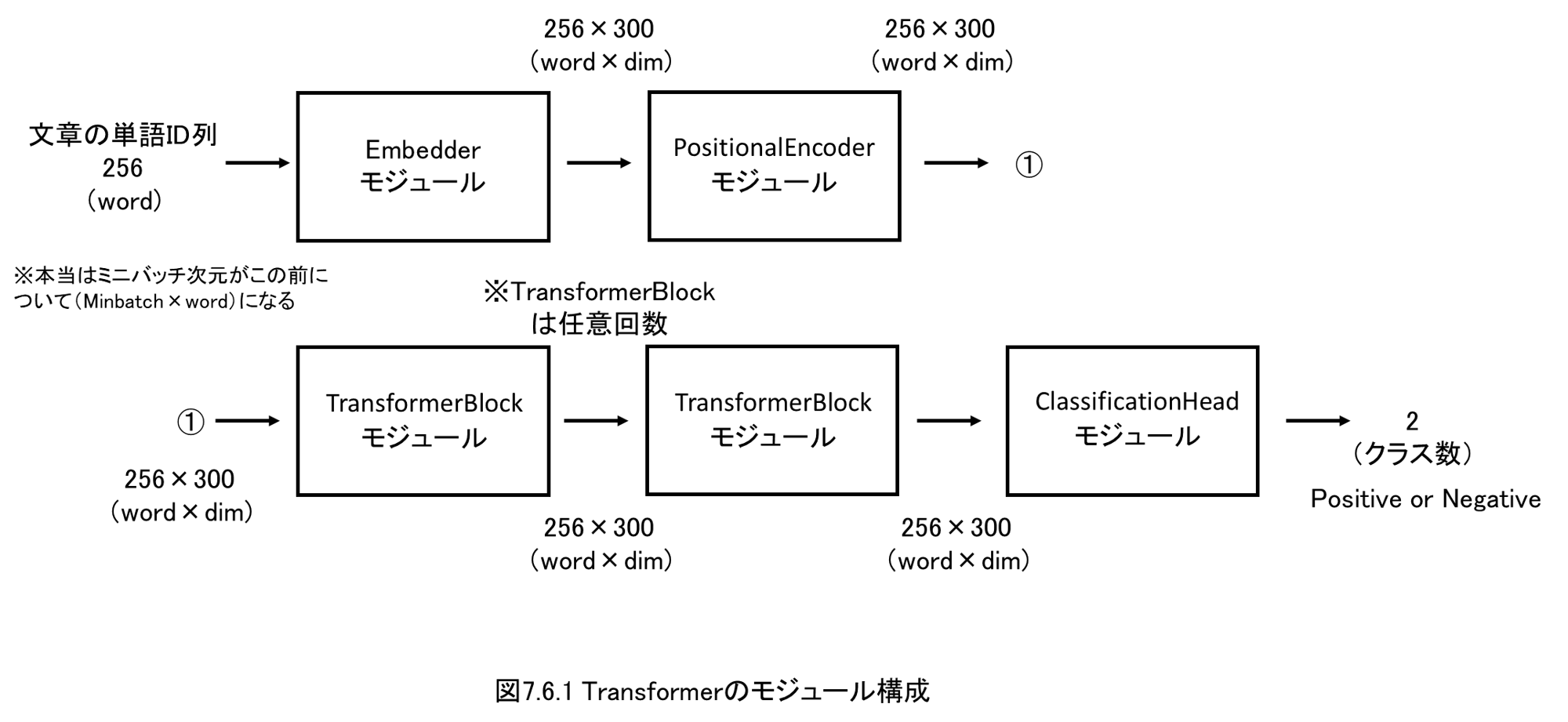
7.6 Transformerの実装(分類タスク用)
7.7 Transformerの学習・推論、判定根拠の可視化を実装
第7章、第8章では自然言語処理(NLP)に取り組みます。
はじめにJanomeおよびMeCab+NEologdを利用し、日本語の文章を単語に分割する形態素解析を実装します。
続いて、word2vecおよびfastTextを利用し、日本語の単語をベクトル表現する手法を実装します。
ここでは「姫 - 女性 + 男性」のベクトル表現が「王子」になるのか、確かめてみます。
その後、Self-AttentionをベースとしたTransformerを実装・解説します。
タスクとしては、書籍「PythonとKerasによるディープラーニング」(通称ショレ本)
https://www.amazon.co.jp/dp/4839964262/
でも使用されている、映画レビューのデータセットIMDb(Internet Movie Database)を使用し、レビュー内容の文章が、ポジorネガを判定する感情分析(分類タスク)を実施します。
最後にTransformerで文章をポジ・ネガ分類する際に、各単語位置にどのようにSelf-Attentionがかかっているのかを可視化して確認します。

第8章 自然言語処理による感情分析(BERT)
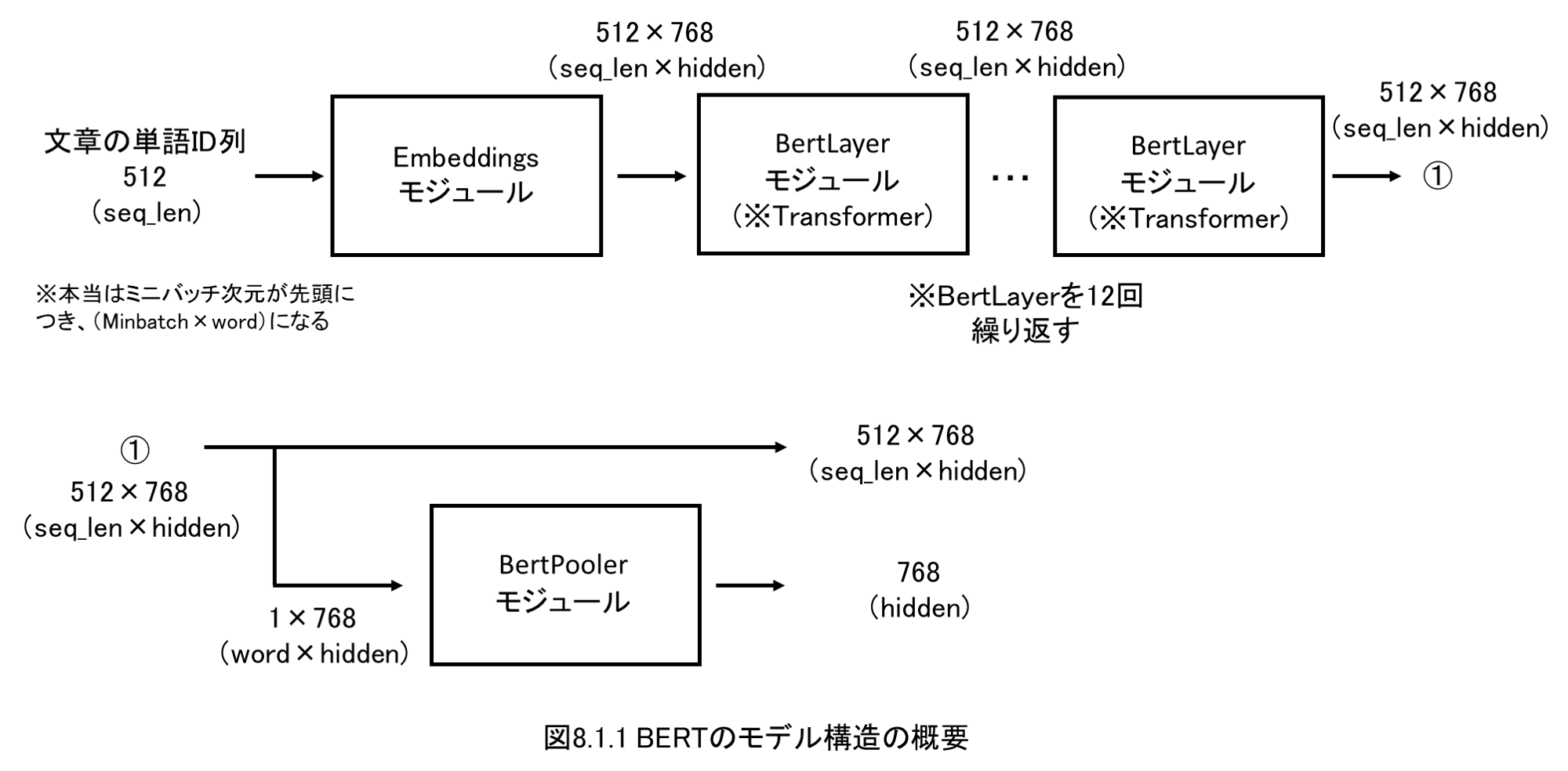
8.1 BERTのメカニズム
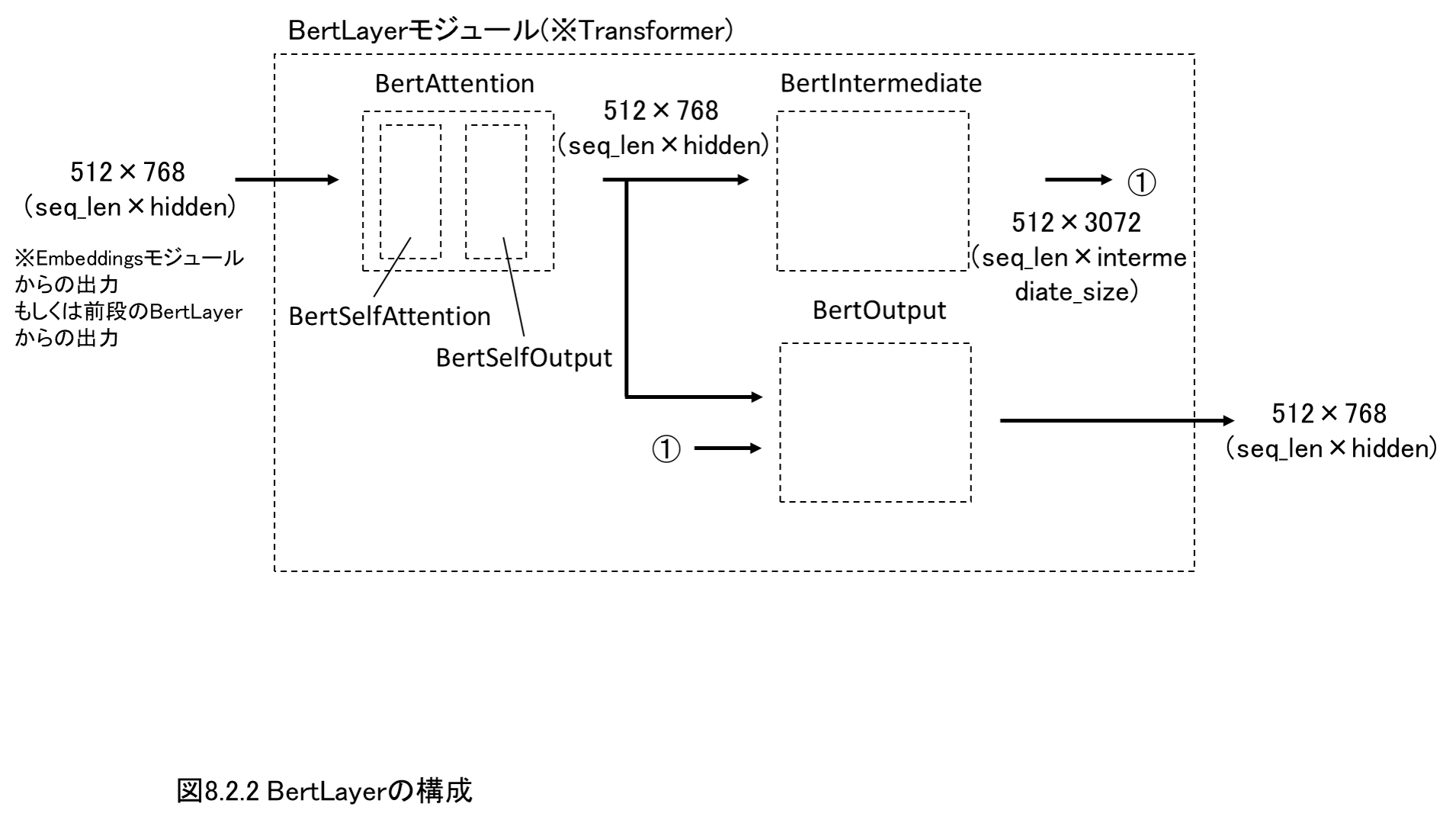
8.2 BERTの実装
8.3 BERTを用いたベクトル表現の比較(bank:銀行とbank:土手)
8.4 BERTの学習・推論、判定根拠の可視化を実装
第8章でも引き続き自然言語処理(NLP)に取り組みます。
2018年10月に発表され、注目を浴びているBERTを実装・解説します。
まずは、なぜBERTが注目されているのか、その理由を解説しながら、BERTの特徴である文脈に応じて単語ベクトルが変化する様子を確認します。
単語のbankが、銀行という意味で使用されている場合と、土手という意味で使用されている場合、それぞれの文章でbankの単語ベクトルの表現がどのように変化するのかを実装・確認します。
その後、第7章と同じく、映画レビューのデータセットIMDb(Internet Movie Database)の感情分析(ポジ・ネガ分類)を実施します。
最後にBERTのSelf-Attentionを可視化する部分を実装します。
第7章のTransformerではうまく処理できなかった、2重否定の表現などがうまく処理できることを確認します。

第9章 動画分類(3DCNN、ECO)
9.1 動画データに対するディープラーニングとECOの概要
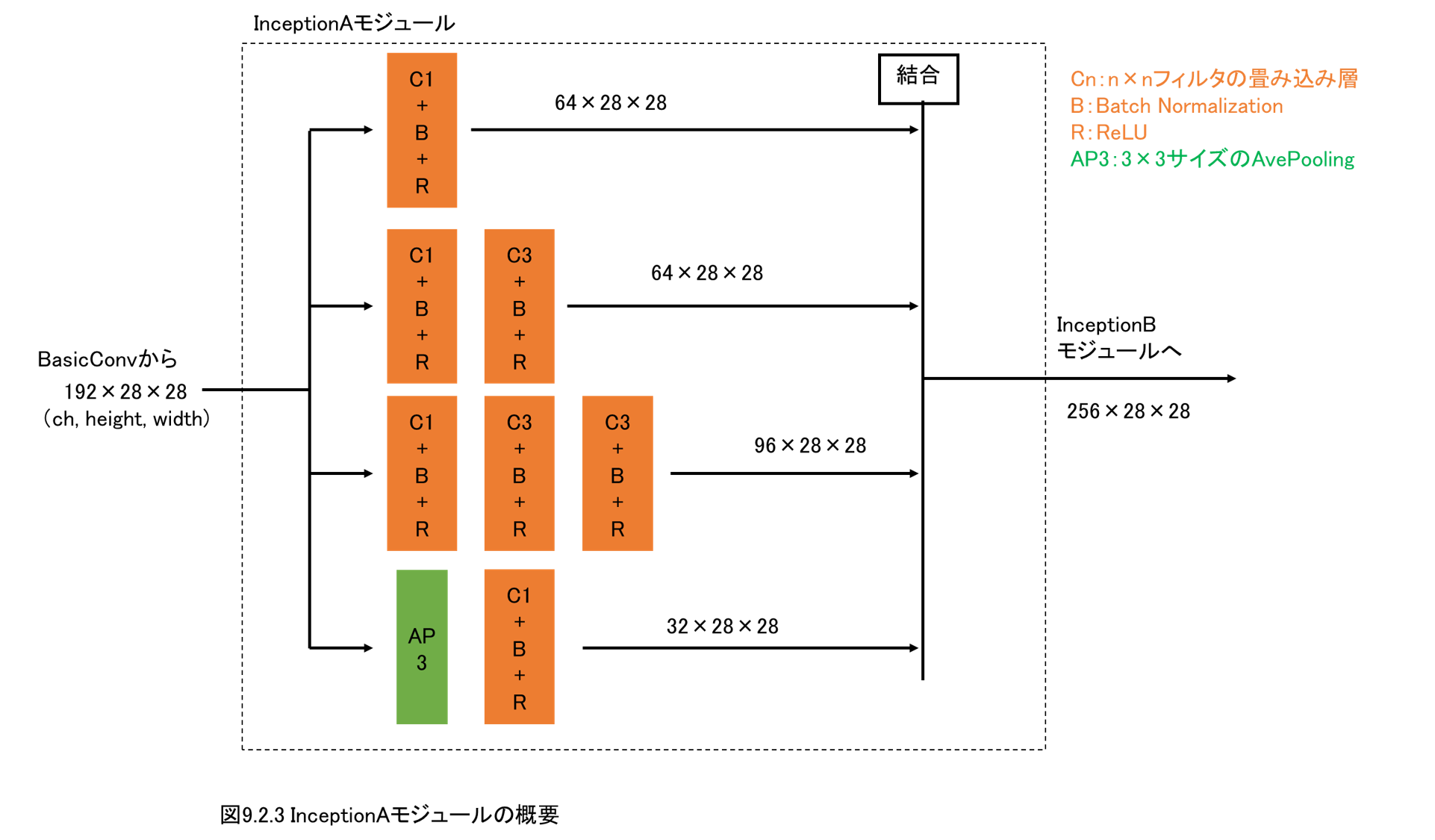
9.2 2D Netモジュール(Inception-v2)の実装
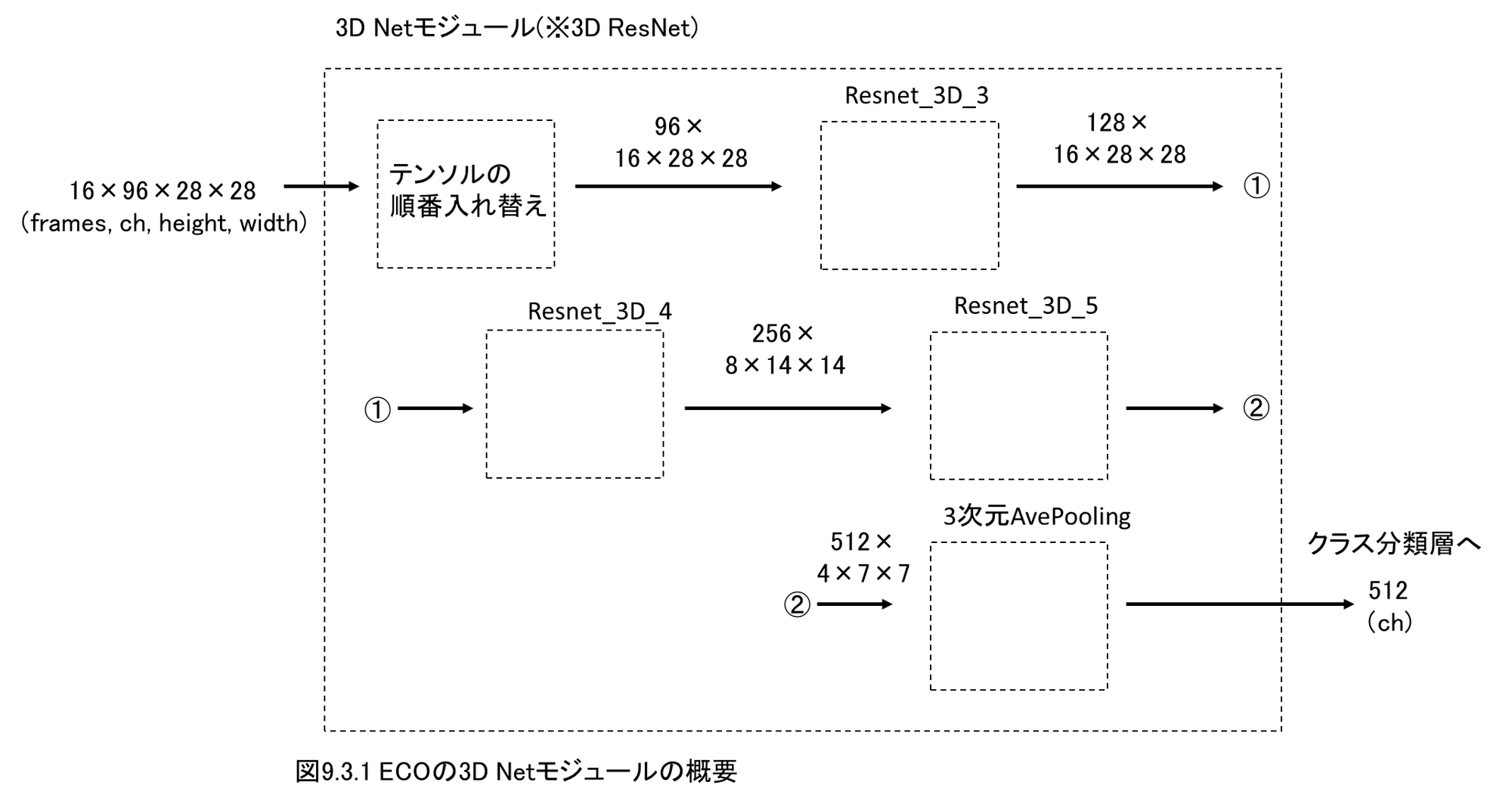
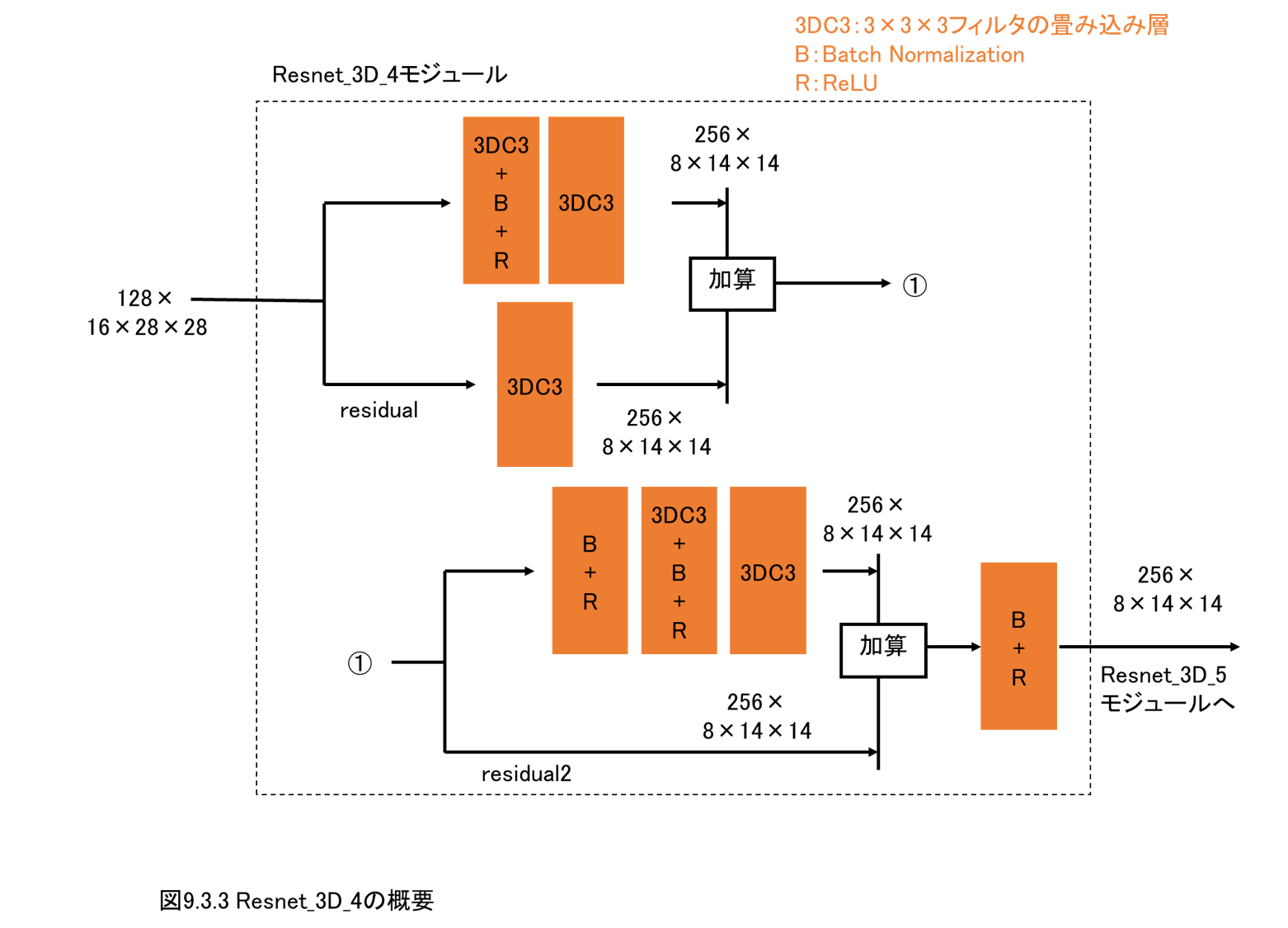
9.3 3D Netモジュール(3DCNN)の実装
9.4 Kinetics動画データセットをDataLoaderに実装
9.5 ECOモデルの実装と動画分類の推論実施
第9章が本書のラストとなります。
最後に動画の分類を扱います。
ディープラーニングモデルとしては、Inceptionと3DCNNを組み合わせたECO(Efficient Convolutional Network for Online Video Understanding)を実装します。
画像の分類と動画の分類の違いに着目しながら、どのように動画をディープラーニングで扱うのか、実装・解説します。
ECOは学習時間が長くなりすぎて大変なので、本書では学習済みモデルをロードし、推論を実施します。
動画にはKinetics動画データセットを使用し、検証用のMP4動画データをダウンロードし、ディープラーニングで使用できるように画像に変換して、推論を実施します。
バンジージャンプや腕相撲をしている動画を推論させ、きちんと動作を推定できるのか確認します。
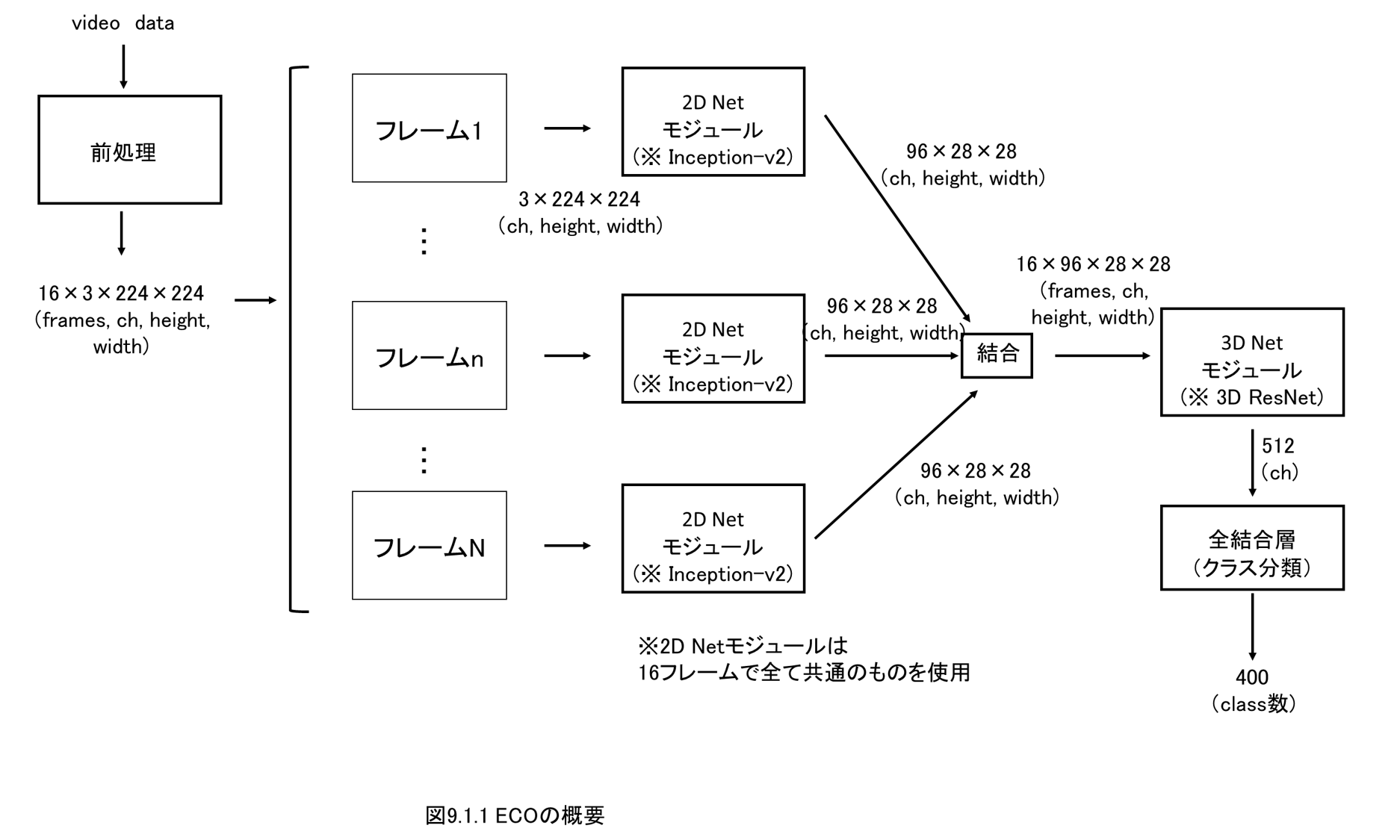
まとめ
以上、最近執筆しました書籍の紹介となります。
つくりながら学ぶ! PyTorchによる発展ディープラーニング(小川雄太郎、マイナビ出版)
https://www.amazon.co.jp/dp/4839970254/
書籍内での解説・実装コードはこちらのGitHubリポジトリで公開しています。
https://github.com/YutaroOgawa/pytorch_advanced
本書の目次は以下から確認できます
Amazonの目次ページへ
ディープラーニングの基礎的な内容(畳み込みニューラルネットワークを用いた画像分類など)を実装してみて、さらに発展的な内容を学びたい方や、PyTorchを使いたい方に向けて執筆いたしました。
本書がお役に立てそうであれば、ご活用いただければ幸いです。
以上、ご一読いただき、ありがとうございました。